机器学习数据预处理----分类型文字数据的处理
文章目录
- 概述
- 示例1
-
- 数据准备
- LabelEncoder的使用
- OrdinalEncoder的使用
- 对示例1的思考
-
- 三种不同性质的分类变量
- 哑变量
- 示例2
-
- 使用OneHotEncoder处理名义变量sex
- 总结
概述
现实生活中我们收集到的数据大多数都是文字类型的,然而我们sklearn要求的数据却基本上是数值型,这里就要求我们将文字数据转化为数值数据,这一过程叫做编码
示例1
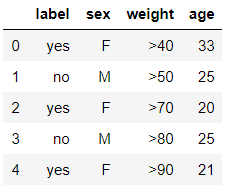
数据准备
对pandas不熟悉的可用看我前面的博文,pandas笔记,numpy笔记
# 生成测试数据
d = {
'label' : [np.random.choice(['yes', 'no']) for _ in range(10)],
'sex' : ['F', 'M'] * 5,
'weight' : ['>40', '>50', '>70', '>80', '>90'] * 2,
'age' : np.random.randint(20, 40, size=(10,))
}
df = pd.DataFrame(data=d)
df
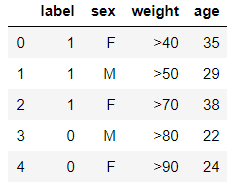
LabelEncoder的使用
# 使用LabelEncoder,将标签转化为数值类型
le = LabelEncoder()
df.loc[:, 'label'] = le.fit_transform(df.loc[:, 'label'])
通过classes_属性可以查看标签中有多少给类别
le.classes_
# array(['no', 'yes'], dtype=object)
结果如下:
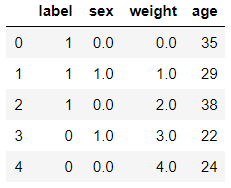
OrdinalEncoder的使用
ordinalEncoder专门用于类目型特征的数值化,还是使用上面的数据代码如下
# 为了不修改原数据,特地创建原数据的副本df1
df1 = df.copy()
oe = OrdinalEncoder()
# 这里需要注意的是fit_transform传入的参数必须是二维的shape=(nsamples, nfeatures)
df1[['sex', 'weight']] = oe.fit_transform(df1[['sex', 'weight']])
df1.head()
通过categories_属性查看每一个特征对应的分类
在这里插入代码片
'''
[array(['F', 'M'], dtype=object),
array(['>40', '>50', '>70', '>80', '>90'], dtype=object)]
'''
对示例1的思考
示例1中将sex数值化为[0, 1], 将weight数值化为[0, 1, 2, 3, 4],现实生活中,数值化后的数据明显是可以进行彼此之间运算的,这些数据之间存在的某些关系。然而在现实生活中,性别是不相干的,所以将其简单的数值化为0,1是不合理的。所以就需要另外的编码方式----独热编码
三种不同性质的分类变量
- 名义变量:彼此之间完全没有联系,比如上面的sex属性
- 有序变量:彼此之间不完全独立,有一定联系,但是不能通过数值运算相互转化,例如我们的学历,小学,初中,高中等
- 有距变量:可以通过数学计算相互转化,比如上面的weight属性,两个类别之间可以通过加减某个数互相转化。
哑变量
也叫做虚拟变量,本来原始数据不存在的特征,我们人为创造的。
示例2
数据还是示例1的数据
使用OneHotEncoder处理名义变量sex
df['label'] = LabelEncoder().fit_transform(df['label'])
# 标签编码
df['weight'] = OrdinalEncoder().fit_transform(df['weight'].values.reshape(-1,1))
# 体重编码
ohe = OneHotEncoder(categories='auto')
# fit_transform传入的参数也必须是二维的
res = ohe.fit_transform(df[['sex']]).toarray()
获取每一列对应的类别
ohe.get_feature_names()
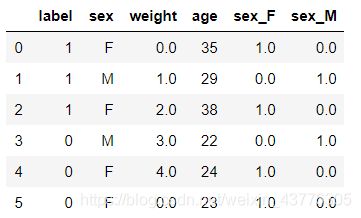
将编码结果与原数据拼接
# 将编码结果转换为dataframe,后面好与原数据连接
d = pd.DataFrame(res, columns=['sex_F', 'sex_M'])
# 新的编码结果拼接在原数据后面
new_df = pd.concat([df, d], axis=1)
new_df
总结
处理文字型特征时,需要注意特征的各个类别之间的关系,选择合适的编码方式。最后需要注意的是,对特征的编码中fit_transform参数传入的数据必须是二维的。