Numpy实现一个简单的机器学习模型
Numpy实现一个简单的机器学习模型
本实例使用numpy实现机器学习,相对于pytorch这类包而言需要花费的代码多一点,但是每一步都是透明的,有利于理解每一步工作原理.
首先我们应该明确基本步骤:
- 基于函数式y = 3x ^ 2 + 2 得到一些数据,另外加上一些噪音数据到达另一组数据y。
- 构建一个机器学习模型来学习表达式y = wx^2 + b 的两个参数w 、b .利用数组x, y的数据为训练数据。
- 采用梯度下降法来通过多次迭代学习到w、b的值。
导入必要库
import numpy as np
%matplotlib inline
from matplotlib import pyplot as plt
代码分析:
%matplotlib inline是一个魔法函数(Magic Functions)。使用%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中,或者使用指定的界面库显示图表,它有一个参数指定matplotlib图表的显示方式。 inline表示将图表嵌入到Notebook中。
生成数据
np.random.seed(100)
x = np.linspace(-1, 1, 100).reshape(100, 1)
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
代码分析:
生成输入数据x及目标数据y,np.random.seed(100)时设置随机数种子。reshape函数将矩阵形状改为合适的形状方便操作。而后np.random.rand是为了加一些噪点。
查看x、y数据分布情况
plt.scatter(x, y, s=20, c='red')
plt.show()
运行结果:

随机初始化参数
w1 = np.random.rand(1, 1)
b1 = np.random.rand(1, 1)
代码分析:
随机初始化参数w1、b1,后面会计算梯度逐渐接近最优解。
训练模型
lr = 0.001 # 学习率
for i in range(800):
# 前向传播
y_pred = np.power(x, 2) * w1 + b1
# 定义损失函数
loss = 0.5*(y_pred - y) ** 2
loss = loss.sum()
# 计算梯度
grad_w = np.sum((y_pred - y) * np.power(x, 2))
grad_b = np.sum((y_pred - y))
# 使用梯度下降法,使loss最小
w1 -= lr * grad_w
b1 -= lr * grad_b
代码分析:
这是我们代码最核心的一部分了。 一个简单的前向传播,y_pred是预测值,y是实际值。loss是均方损失函数,这里均方损失函数乘以0.5是为了求导的时候平方项正好消去,方便后续整理,实际上也可以不乘,梯度下降算法最重要的是方向,大小是次要的。sum函数对损失进行求和同时把loss函数变为标量,实际上这里面由于我们直接后续计算梯度直接求出了loss函数的导数,所以这里loss函数实际上没有在代码上没有很大的作用,写出来是为了方便我们去观看。而这里我们接下来就是计算的grad_w、grad_b就是来进行梯度的计算,然后更新权重w1和参数b1。
可视化结果
我们训练结果如何呢?其实际拟合程度如何呢?我们画图来验证一下拟合的效果。
plt.plot(x, y_pred, "r-", label='predict')
plt.scatter(x, y, color='blue', marker='o', label='true') # true data
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.show()
print(w1, b1)
训练结果:
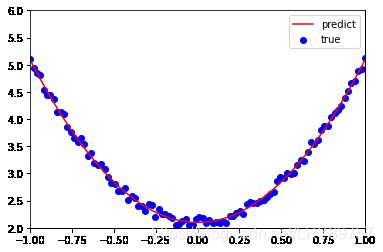
[[2.98941611]] [[2.09813123]]
代码分析:
事实证明,经过800次训练之后,我们训练出的模型的拟合效果还是相当不错的,w是2.9894左右,b是2.0981左右。和我们初始时设定的3、2相差很小。
总结
这是博主一个月之前编写的代码,因为刚开始入门学了很多东西感觉眼花缭乱的,又是理论又是代码的,让我感觉不是特别适应,听了学长的建议后。决定把学习的一些东西记录下来 ,这样方便了解 一下自己究竟干了些什么,以及规划一下要去干什么。
事实上整个代码写下来并不是很难,不需要很复杂的思想,分步骤按部就班的就能完成。