keras多元线性回归手把手教程
keras多元线性回归手把手教程
前情提要:最近看了李宏毅的深度学习课程,查找了很多代码,发现csdn上面只有一元线性回归的代码,而多元线性回归真的好少。于是为了方便大家的学习,有了这篇文章。
- 准备数据
# 创建数据集
# 在[0,100]的区间内等间隔创建200个二元数组
X = np.random.randint(0, 100, (200, 2))
#建立系数数组
a = [[0.7], [0.5]]
# np.random.normal(0, 0.05, (200, ))为输出服从均值为0,标准方差为0.05的200个正太分布数据
# 假设我们真实模型为:Y=0.7X(0)+0.5X(1)+2
Y = np.mat(X) * np.mat(a).getA() + 2 + np.random.normal(0, 0.05, (200, 1))
X_train, Y_train = X[:160], Y[:160] # 把前160个数据放到训练集
X_test, Y_test = X[160:], Y[160:] # 把后40个点放到测试集
- 模型构建
model = Sequential() # Keras有两种类型的模型,序贯模型(Sequential)和函数式模型
# 比较常用的是Sequential,它是单输入单输出的
model.add(Dense(output_dim=1, input_dim=2)) # 通过add()方法一层层添加模型
# Dense是全连接层,第一层需要定义输入,
# 第二层无需指定输入,一般第二层把第一层的输出作为输入
# 定义完模型就需要训练了,不过训练之前我们需要指定一些训练参数
# 通过compile()方法选择损失函数和优化器
# 这里我们用均方误差作为损失函数,随机梯度下降作为优化方法
# model.compile(loss='mse')
# 用的是adam这个优化器
adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam, loss='mse')
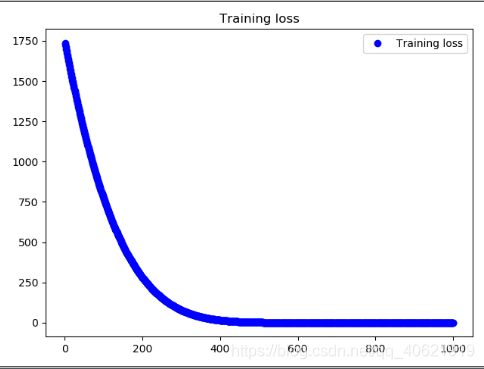
- loss图像打印
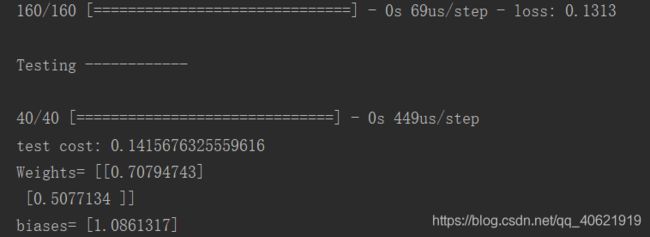
history = model.fit(X_train, Y_train, 40, 1000)
print('\nTesting ------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
W, b = model.layers[0].get_weights() # 查看训练出的网络参数
# 由于我们网络只有一层,且每次训练的输入只有一个,输出只有一个
# 因此第一层训练出Y=W1X1+W2X2+B这个模型,其中W,b为训练出的参数
print('Weights=', W, '\nbiases=', b)
print(history.history)
loss = history.history['loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.title('Training loss')
plt.legend()
plt.figure()
plt.show()
- 实验结果
- 全部代码
import numpy as np
from keras.optimizers import Adam
np.random.seed(1337)
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
import matplotlib.pyplot as plt
X = np.random.randint(0, 100, (200, 2))
a = [[0.7], [0.5]]
Y = np.mat(X) * np.mat(a).getA() + 2 + np.random.normal(0, 0.05, (200, 1))
X_train, Y_train = X[:160], Y[:160]
X_test, Y_test = X[160:], Y[160:]
model = Sequential()
model.add(Dense(output_dim=1, input_dim=2))
adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam, loss='mse')
history = model.fit(X_train, Y_train, 40, 1000)
print('\nTesting ------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
W, b = model.layers[0].get_weights()
print('Weights=', W, '\nbiases=', b)
print(history.history)
loss = history.history['loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.title('Training loss')
plt.legend()
plt.figure()
plt.show()