1.java中数据存储(内存中)的容器:①数组 ②集合
2.数组在数据存储方面的不足:
①数组一旦初始化,其长度就不可变
②如何获取真正初始化元素的个数,不方便。没有直接的方法可以使用。
③在数组中插入、删除某个元素时,比较繁琐
一.java中的集合框架
java.util.Collection
其中定义的方法:
①add(Object obj) addAll(Collection coll) size() clear() isEmpty()
②remove(Object obj) removeAll(Collection coll) retainAll(Collection coll) constains(Object obj) constainsAll(Collectionc coll) equals(Object obj)
③hashCode() toArray() iterator()
|------List:用于存储有序的、可以重复的数据 ---"动态"数组
|------ ArrayList:主要实现类,线程不安全的,效率高,底层使用数组实现。
|------ LinkedList:对于频繁的删除和插入操作,效率较高,底层使用链表实现
|------ Vector:古老的实现类,线程安全的,效率低,底层使用数组实现。
>要求向List中添加的元素所在的类,必须重写equals()方法。原则:比较两个对象的属性值是否完全相同
>常用方法:添加:add(Object obj) 删除:remove(Object obj) / remove(int index)
修改:set(int index,Object obj) 查询:get(int index)
插入:add(int index,Object obj) 长度:size()
遍历:iterator() / 增强for循环/一般的for循环
|-----Set:用于存储无序的、不可重复的数据---高中讲的"集合"
|----HashSet:是Set的主要实现类
|----LinkedHashSet:是HashSet的子类,对于频繁的遍历操作,建议使用此类。遍历时,可以按照添加元素的顺序实现遍历。
|----TreeSet:涉及到给Set中添加的元素排序的问题(难点)
>要求添加到TreeSet中的元素必须是由同一个类所创建的对象
>自然排序:----Comparable接口 (抽象方法:int compareTo(Object obj))
1)要求自定义类实现java.util.Comparable接口
2)重写接口的compareTo(Object obj)方法,指明按照对象的哪个属性进行排序
3)直接向TreeSet中添加自定义类的对象即可
>定制排序:----Comparator接口(抽象方法:int compare(Object obj1,Object obj2)
1)创建一个实现Comparator接口的实现类:MyComparator
2)重写其compare(Object o1, Object o2)方法,指明按照对象的哪个属性进行排序
3)创建一个实现类的对象,作为实参传递给TreeSet的构造器中: new TreeSet(Comparator com);
4)直接向TreeSet中添加compare方法中指明的类的对象即可
>要求:重写的compareTo()或compare()与hashCode()、equals()要保持一致!
>要求向Set中添加的元素所在的类,必须重写equals()方法和hashCode()。
原则:hashCode()方法和equals()方法必须保持一致!
>Set中定义的方法与Collection中的方法是一致的。
>了解:Set中的元素是如何存储的?哈希算法!
向Set中添加元素a,首先调用a所在类的hashCode()方法,此方法的返回值决定了元素a的存储位置。如果此位置上没有元素,则元素a添加成功。若此位置上已有元素b,那么继续调用a所在类的equals()方法,判断a与b是否相同。若相同,则元素a添加不成功。若equals()方法返回false,则元素a添加成功。
关于Collection的遍历:Iterator接口
Collection coll = new ArrayList();
coll.add(。。。);
Iterator iterator = coll.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}

增强for循环:for(要遍历的结构的元素的类型 局部变量:要遍历的结构的引用名)
for(Object obj : coll){
System.out.println(obj);
}
int[] arr = new int[]{1,2,3,4,5];
for(int i : arr){
System.out.println(arr[i]);
}
java.util.Map:存储的是一对一对的数据:键值对。(key-value)
特点:Map中的所有的key使用Set存放==>要求key所在的类要重写hashCode()和equals()
所有的value使用Collection存放==>要求value所在的类要重写equals()
Map中的一个key-value对构成一个Entry。所有的Map中的Entry,使用Set存放。
>Map中的key彼此不相同。
>不同的key可以对应相同的value值
>Map中的entry也是不相同的。
>Map中的entry如何存储?根据Map中Entry的key来存储。根据key所在类的hashCode()方法,决定key(或entry)所在的位置,若此位置上没有值,则key(或entry)直接保存。若此位置上有值,则调用key所在类的equals()方法进行判断。若返回true,则将新的value值替换掉旧的value值。若返回false,则两个entry都保存成功。
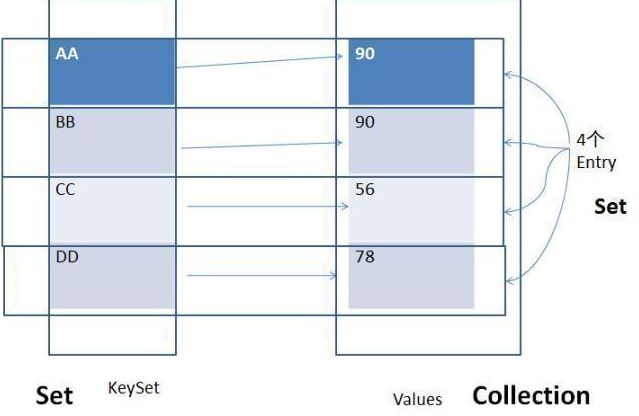
|----HashMap:Map主要实现类,线程不安全的,可以存储null的key和null的value
|---LinkedHashMap:HashMap的子类,可以按照添加的元素的顺序实现遍历
|----TreeMap:可以按照key指定的属性的指定顺序排序:自然排序或定制排序
|----Hashtable:Map的古老实现类,现在基本不用了。线程安全的,不可以存储null的key和null的value
|----Properties:常用来处理属性文件。key和value都是String型
常用的方法:添加/修改: put(Object key,Object value) 删除:remove(Object key) 查询:get(Object key) 长度:size()
遍历:keySet() values() entrySet()
操作集合的工具类:Collections