11.1 基础正则表达式
1、正则表达式(对应字符串)与通配符(对应文件名)
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式。
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
2、基础正则表达式
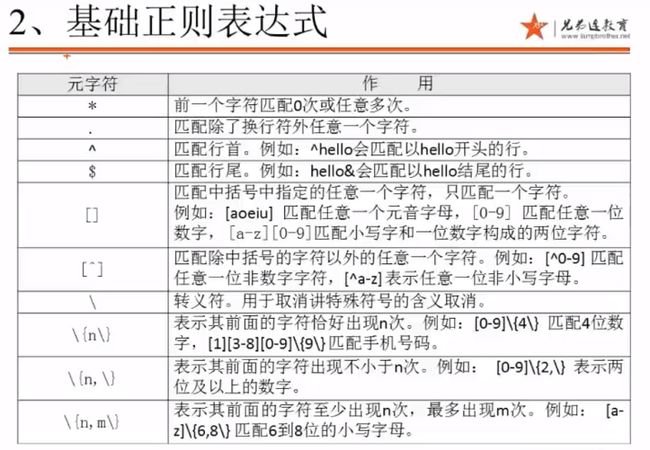
“*”前一个字符匹配0次,或任意多次
grep "a*" test_rule.txt
#匹配所有内容,包括空白行
grep "aa*" test_rule.txt
#匹配至少包含有一个a的行
grep "aaa*" test_rule.txt
#匹配最少包含两个连续a的字符串
grep "aaaaa*" test_rule.txt
#则会匹配最少包含四个个连续a的字符串
“.” 匹配除了换行符外任意一个字符
grep "s..d" test_rule.txt
#“s..d”会匹配在s和d这两个字母之间一定有两个字符的单词
grep "s.*d" test_rule.txt
#匹配在s和d字母之间有任意字符
grep ".*" test_rule.txt
#匹配所有内容
“^”匹配行首,“$”匹配行尾
grep "^M" test_rule.txt
#匹配以大写“M”开头的行
grep "n$" test_rule.txt
#匹配以小写“n”结尾的行
grep -n "^$" test_rule.txt
#会匹配空白行 (列出空白行的行数)-n 表示显示行号
grep "^[0-9]*$" rule.txt
#匹配任意以以数字开头和结尾(即纯数字)的行
“[]” 匹配中括号中指定的任意一个字符,只匹配一个字符
grep "s[ao]id" test_rule.txt
#匹配s和i字母中,要么是a、要么是o
grep "[0-9]" test_rule.txt
#匹配任意一个只要包含数字0-9的行,不管是数字是在哪里
grep "^[0-9]" test_rule.txt
#匹配任意一个数字开头的行
grep "^[a-z]" test_rule.txt
#匹配用小写字母开头的行
“[^]” 匹配除中括号的字符以外的任意一个字符
grep "^[^a-z]" test_rule.txt
#匹配不以小写字母开头的行
grep "^[^a-zA-Z]" test_rule.txt
#匹配不用字母开头的行 “\” 转义符
grep "\.$" test_rule.txt
#匹配使用“.”结尾的行
“\{n\}”表示其前面的字符恰好出现n次
grep "a\{3\}" test_rule.txt
#匹配a字母连续出现三次的字符串
grep "[0-9]\{3\}" test_rule.txt
#匹配包含连续的三个数字的字符串
“\{n,\}”表示其前面的字符出现不小于n次
grep "^[0-9]\{3,\}[a-z]" test_rule.txt
#匹配最少用连续三个数字开头的行
“\{n,m\}”匹配其前面的字符至少出现n次,最多出现m次
grep "sa\{1,3\}i" test_rule.txt
#匹配在字母s和字母i之间有最少一个a,最多三个a
11.2 字符截取命令
11.2.1 cut字段提取命令
[root@localhost ~]# cut [选项] 文件名
如:cut -d "分隔符" -f 第几列 文件名
选项:
-f 列号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
表示以“符号”作为分隔符,提取第几列
[root@localhost ~]# vi student.txt
ID Name gender Mark
1 Liming M 86
2 Sc M 90
3 Gao M 83
[root@localhost ~]# cut -f 2 student.txt
#提取第二列
[root@localhost ~]# cut -f 2,3 student.txt
#提取第二第三列
[root@localhost ~]# cut -d ":" -f 1,3 /etc/passwd
#以:为分隔符提取第一第三列
[root@localhost ~]# cat /etc/passwd | grep /bin/bash | grep -v root | cut -d ":" -f 1
liming
aclUser3
aclUser1
aclUser2
st
aclUser4
lisi
wangwu
#提取所有普通用户所在的列(由于所有普通用户的shell脚本都是在 /bin/bash ,所以 grep /bin/bash。 但是root也包含了,所以用-v取反,排除root用户。之后用cut命令,以冒号进行分割,提取第一列 )
cut命令的局限
[root@localhost ~]# df -h | cut -d " " -f 1,3
#有空格时提取会出问题
11.2.2 printf命令
[root@localhost ~]# printf '输出类型输出格式' 输出内容
输出类型:
%ns : 输出字符串。n是数字指代输出几个字符 (%s就代表1个字符)
%ni : 输出整数。n是数字指代输出几个数字
%m.nf : 输出浮点数。m和n是数字,指代输出的整数 位数和小数位数。如%8.2f代表共输出8位数, 其中2位是小数,6位是整数。
输出格式:
\a : 输出警告声音
\b : 输出退格键,也就是Backspace键
\f : 清除屏幕
\n : 换行
\r : 回车,也就是Enter键
\t : 水平输出退格键,也就是Tab键
\v : 垂直输出退格键,也就是Tab键
[root@localhost ~]# printf %s 1 2 3 4 5 6
[root@localhost ~]# printf %s %s %s 1 2 3 4 5 6
[root@localhost ~]# printf '%s %s %s' 1 2 3 4 5 6
[root@localhost ~]# printf '%s %s %s\n' 1 2 3 4 5 6
tips:printf '%s %s %s\n' 1 2 3 4 5 6
三个看成一个整体所以123是一个整体,456是另一个。所以在3后面换行
[root@localhost ~]# printf "%s%s%s\n" 1 2 3 4 5 6
123
456
[root@localhost ~]# printf "%s %s %s\n" 1 2 3 4 5 6
1 2 3
4 5 6
默认以空格作为分割符。
[root@localhost ~]# vi student.txt
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
printf '%s' $(cat student.txt)
#不调整输出格式
printf '%s\t %s\t %s\t %s\t %s\t %s\t \n' $(cat student.txt)
#调整格式输出
在awk命令的输出中支持print和printf命令
print:print会在每个输出之后自动加入一个换行符(Linux默认没有print命
printf:printf是标准格式输出命令,并不会自动加入换行符,如果需要换行,需要手工加入换行符
11.2.3 命令(其本质是先读入第一行数据)
[root@localhost ~]# awk ‘条件1{动作1} 条件2{动作2}…’ 文件名
表示如果条件1符合,就执行动作1,条件2符合就执行动作2等等
条件(Pattern):
一般使用关系表达式作为条件
x > 10 判断变量 x是否大于10
x>=10 大于等于
x<=10 小于等于
动作(Action):
格式化输出
流程控制语句
[root@localhost ~]# vi student.txt
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
[root@localhost ~]#awk '{printf $2 "\t" $6 "\n"}' student.txt
输出文件的第2列($2)和第6列($6),中间以tab键作为分割
[root@localhost ~]# df -h | awk '{printf $1 "\t" $3 "\t" "\n"}'
Filesystem Used
/dev/sda5 2.7G
tmpfs 0
/dev/sda1 65M
/dev/sda2 3.2M
/dev/sdb5 3.1M
[root@localhost ~]# df -h | awk '{print $1 "\t" $3 "\t" }'
Filesystem Used
/dev/sda5 2.7G
tmpfs 0
/dev/sda1 65M
/dev/sda2 3.2M
/dev/sdb5 3.1M
提取已用百分比。可以发现print是会自动加入换行符的,printf要手动添加
[root@localhost ~]# df -h | grep "sda5" | awk '{printf $5}' | cut -d "%" -f 1
18
[root@localhost ~]# df -h | grep "sda5"
/dev/sda5 16G 2.7G 13G 18% /
[root@localhost ~]# df -h | grep "sda5" | awk '{print $5}'
18%
[root@localhost ~]# df -h | grep "sda5" | awk '{print $5}' | cut -d "%" -f 1
18
[root@localhost ~]#
BEGIN :在所有命令执行前,先执行
#awk 'BEGIN{printf "This is a transcript \n" } {printf $2 "\t" $6 "\n"}' student.txt
先打印提示语,再执行后面的操作
[root@localhost ~]# awk '{FS=":"} {print $1 "\t" $3}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin 1
daemon 2
adm 3
lp 4
sync 5
由于awk是先读取第一行,再执行后面的语句,因此第一行没有处理
[root@localhost ~]# awk 'BEGIN {FS=":"} {print $1 "\t" $3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
让awk在执行第一条语句前,先写上分隔符,再执行
END :在所有命令执行完之后执行
# awk 'END{printf "The End \n" }
{printf $2 "\t" $6 "\n"}' student.txt
[root@localhost ~]# awk 'BEGIN {FS="\t"} END {print "Complete"} {print $1 "\t" $3}' student.txt
ID gender
1 M
2 M
3 M
Complete
FS内置变量 :可以用于指定分隔符
#cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN {FS=":"} {printf $1 "\t" $3 "\n"}'
关系运算符
#cat student.txt | grep -v Name | awk '$6 >= 87 {printf $2 "\n" }'
[root@localhost ~]# cat student.txt | grep -v 'Name' | awk '$4 >=85 {print $2 "\t" $4}'
Liming 86
Sc 90
注意:grep中取反的字符串,如果包含空格可以加单引号,如果没有,不加引号也可以。
11.2.4 sed命令
sed命令
sed 是一种几乎包括在所有 UNIX 平台(包括 Linux)的轻量级流编辑器。sed主要是用来将数据进行选取、替换、删除、新增的命令。
[root@localhost ~]# sed [选项] ‘[动作]’ 文件名
选项:
-n: 一般sed命令会把所有数据都输出到屏幕 , 如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。
-e: 允许对输入数据应用多条sed命令编辑
-i: 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出。不加此选项时,只是输出sed执行的结果,而不会修改原文件。用分号作为分割
动作:
a \: 追加,在当前行后添加一行或多行。添加多行时,除最后 一行 外,每行末尾需要用“\”代表数据未完结。
c \: 行替换,用c后面的字符串替换原数据行,替换多行时,除最 后一行外,每行末尾需“\”代 表数据未完结。
i \: 插入,在当期行前插入一行或多行。插入多行时,除最后 一行 外,每行末尾需要“\”代表数据未完结。
d: 删除,删除指定的行。
p: 打印,输出指定的行。
s: 字串替换,用一个字符串替换另外一个字符串。格式为“行范 围s/旧字串/新字串/g”(和vim中的替换格式类似)。
学生成绩表
[root@localhost ~]# vi student.txt
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
行数据操作
[root@localhost ~]# sed '2p' student.txt
#查看文件的第二行
[root@localhost ~]# sed -n '2p' student.txt
[root@localhost ~]# sed '2,4d' student.txt
#删除第二行到第四行的数据,但不修改文件本身
[root@localhost ~]# sed '2a hello' student.txt
#在第二行后追加hello
[root@localhost ~]# sed '2i hello \ world' student.txt
#在第二行前插入两行数据
# sed '2c No such person‘ student.txt
#数据替换
字符串替换
# sed ‘s/旧字串/新字串/g’ 文件名
# sed '3s/74/99/g' student.txt
#在第三行中,把74换成99
#sed -i '3s/74/99/g' student.txt
#sed操作的数据直接写入文件
# sed -e 's/Liming//g ; s/Gao//g' student.txt
#同时把“Liming”和“Gao”替换为空
11.3 字符处理命令
1、 排序命令sort
[root@localhost ~]# sort [选项] 文件名
选项:
-f: 忽略大小写
-n: 以数值型进行排序,默认使用字符串型排序
-r: 反向排序
-t: 指定分隔符,默认是分隔符是制表符
-k n[,m]: 按照指定的字段范围排序。从第n字段开始, m字段结束(默认到行尾)
[root@localhost ~]# sort /etc/passwd
#排序用户信息文件
[root@localhost ~]# sort -r /etc/passwd
#反向排序
[root@localhost ~]# sort -t ":" -k 3,3 /etc/passwd
#指定分隔符是“:”,用第三字段开头,第三字段结尾排序,就是只用第三字段(即用户ID号排序)排序
[root@localhost ~]# sort -n -t ":" -k 3,3 /etc/passwd
2、 统计命令wc
[root@localhost ~]# wc [选项] 文件名
选项:
-l: 只统计行数
-w: 只统计单词数
-m: 只统计字符数
11.4 条件判断
1、 按照文件类型进行判断
两种判断格式
[root@localhost ~]# test -e /root/install.log
然后用下面这条命令(表示上一条命令执行的结果),查看结果。
[root@localhost ~]# echo $?
[root@localhost ~]# [ -e /root/install.log ]
通过管道符连接命令
[root@localhost ~]# [ -d /root ] && echo "yes" || echo "no"
#第一个判断命令如果正确执行,则打印“yes”,否则打印“no”
2、按照文件权限进行判断
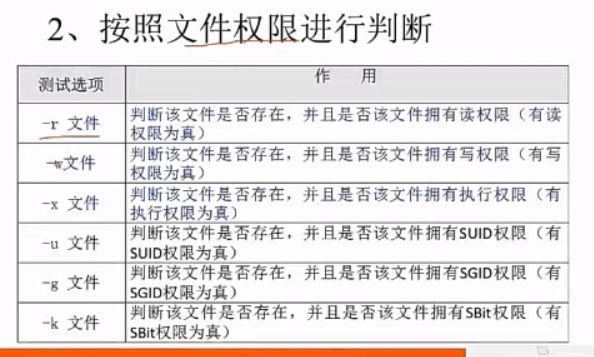
[ -w student.txt ] && echo "yes" || echo "no"
#判断文件是拥有写权限的
3、 两个文件之间进行比较
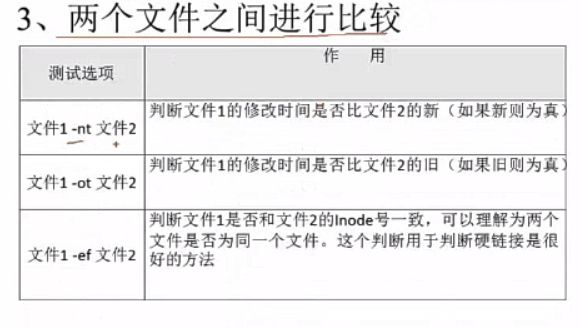
ln /root/student.txt /tmp/stu.txt
#创建个硬链接吧
[ /root/student.txt -ef /tmp/stu.txt ] && echo "yes" || echo "no" yes
#用test测试下,果然很有用
4、 两个整数之间比较
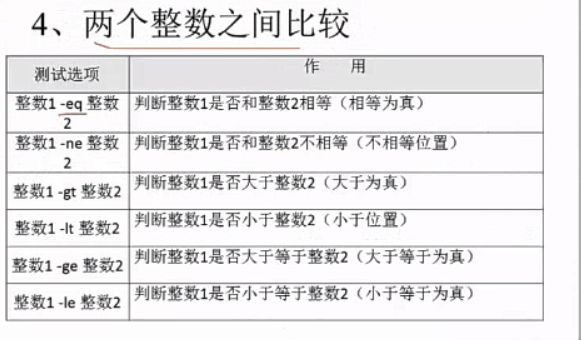
[ 23 -ge 22 ] && echo "yes" || echo "no" yes
#判断23是否大于等于22,当然是了
[ 23 -le 22 ] && echo "yes" || echo "no" no
#判断23是否小于等于22,当然不是了
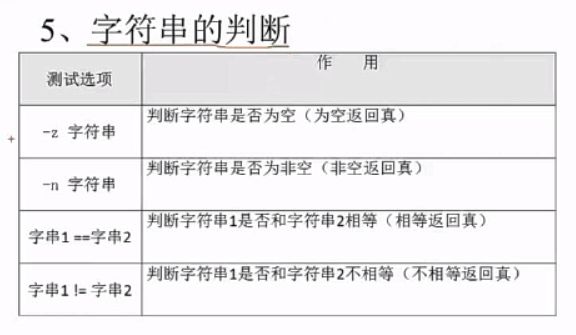
5、字符串的判断
name=sc
#给name变量赋值
[ -z "$name" ] && echo "yes" || echo "no"
no
#判断name变量是否为空,因为不为空,所以返回no
aa=11
bb=22
#给变量aa和变量bb赋值
[ "$aa" == "bb" ] && echo "yes" || echo "no"
no
#判断两个变量的值是否相等,明显不相等,所以返回no
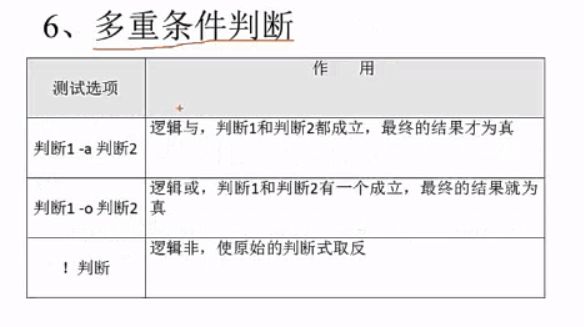
6、多重条件判断
aa=11
[ -n "$aa" -a "$aa" -gt 23 ] && echo "yes" || echo "no"
no
#判断变量aa是否有值,同时判断变量aa的是否大于23
#因为变量aa的值不大于23,所以虽然第一个判断值为真,返回的结果也是假
aa=24
[ -n "$aa" -a "$aa" -gt 23 ] && echo "yes" || echo "no" yes
11.5 流程控制
11.5.1 if语句
1、 单分支if条件语句
if [ 条件判断式 ] ; then
程序
fi
#或者
if [ 条件判断式 ]
then
程序
fi
单分支条件语句需要注意几个点
if语句使用fi结尾,和一般语言使用大括号结尾不同
[ 条件判断式 ]就是使用test命令判断,所以中括号和条件判断式之间必须有空格
then后面跟符合条件之后执行的程序,可以放在[]之后,用“;”分割。也可以换行写入,就不需要“;”了
例子:判断分区使用率
#!/bin/basn
# 统计根分区使用率
# Author: shenchao (E-mail: [email protected])
rate=$(df -h | grep "/dev/sda3" | awk '{print $5}' | cut -d "%" -f 1)
# 把根分区使用率作为变量值赋予变量rate
if [ $rate -ge 80]
then
echo "Warning! /dev/sda3 is full!"
fi
2、 双分支if条件语句
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的另一个程序
fi
例子1:备份mysql数据库
#!/bin/bash
#备份mysql数据库。
# Author:shenchao(E-mail:[email protected])
ntpdateasia.pool.ntp.org&>/dev/null
#同步系统时间
date=$(date+%y%m%d)
#把当前系统时间按照“年月日”格式赋予变量
datesize=$(du-sh /var/lib/mysql)
#统计mysql数据库的大小,并把大小赋予size变量
if [ -d /tmp/dbbak ] #如果这个目录存在
then
echo"Date:$date!" > /tmp/dbbak/dbinfo.txt
echo"Data size:$size">>/tmp/dbbak/dbinfo.txt
cd /tmp/dbbak
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &>/dev/null
rm -rf /tmp/dbbak/dbinfo.txt
else
mkdir /tmp/dbbak
echo"Date:date!">/tmp/dbbak/dbinfo.txt
echo"Datasize:size">>/tmp/dbbak/dbinfo.txt
cd /tmp/dbbak
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql
dbinfo.txt &> /dev/null
rm -rf /tmp/dbbak/dbinfo.txt
fi
例子2:判断apache是否启动
#!/bin/bash
#Author:shenchao(E-mail:[email protected])
port=$(nmap -sT 192.168.1.16 | grep tcp | grep http |awk '{print$2}')
#使用nmap命令扫描服务器,并截取apache服务的状态,赋予变量port
if [ "$port"=="open" ]
then
echo“$(date)httpdisok!” >> /tmp/autostart-acc.log
else
/etc/rc.d/init.d/httpdstart &> /dev/null
echo"$(date)restarthttpd!!" >> /tmp/autostart-err.log
fi
3、 多分支if条件语句
if [ 条件判断式1 ]
then
当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]
then
当条件判断式2成立时,执行程序2
„省略更多条件…
else
当所有条件都不成立时,最后执行此程序
fi
例子
#!/bin/bash
#判断用户输入的是什么文件
#Author:shenchao(E-mail:[email protected])
read-p"Pleaseinputafilename:"file
#接收键盘的输入,并赋予变量file
if [ -z "$file" ]
#判断file变量是否为空
then
echo "Error,pleaseinputafilename"
exit 1
elif [ ! -e "$file" ]
#判断file的值是否存在
then
echo "Yourinputisnotafile!"
exit 2
elif [ -f "$file" ]
#判断file的值是否为普通文件
then
echo "$fileisaregularefile!"
elif [ -d "$file" ]
#判断file的值是否为目录文件
then
echo "$fileisadirectory!"
else
echo"$fileisanotherfile!"
fi
11.5.2 case语句
多分支case条件语句
case语句和if…elif…else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
case $ 变量名 in
" 值1")
如果变量的值等于值1,则执行程序1
; ;
" 值2")
如果变量的值等于值2,则执行程序2
; ;
…省略其他分支…
* )
如果变量的值都不是以上的值,则执行此程序
; ;
esac
#!/bin/bash
#判断用户输入
#Author:shenchao(E-mail:[email protected])
read -p"Pleasechooseyes/no:" -t 30 cho
case $cho in
"yes")
echo"Yourchooseisyes!"
;;
"no")
echo"Yourchooseisno!"
;;
*)
echo"Yourchooseiserror!"
;;
esac
11.5.3 for循环
匹配任意数字: sed 's/^[0-9]*$//g'把纯数字替换为空
例子:批量添加用户
#!/bin/bash
read -t 30 -p "input name: " name
read -t 30 -p "input num: " num
read -t 30 -p "input password: " pass
if [ ! -z "$name" -a ! -z "$num" -a ! -z "$pass" ]
then
y=$( echo "$num" | sed 's/^[0-9]*$'//g )
if [ -z "$y" ]
then
for (( i=1;i<=$num;i=i+1 ))
do
/usr/sbin/useradd $name$i &> /dev/null
echo $pass | /usr/sbin/passwd --stdin $name$i &> /dev/null
done
fi
fi
语法一(以空格区分有几个值)
for 变量 in 值1 值2 值3
do
程序
done
#!/bin/bash
for city in beijing nanjing shanghai
do
echo "this city is $city "
done
输出:
this city is beijing
this city is nanjing
this city is shanghai
#!/bin/bash
#批量解压缩脚本
cd /sh
ls *.tar.gz >ls.log
for i in $(cat ls.log)
do
tar -zxf $i &> /dev/null
done
rm -rf /sh/ls.log
语法二
for((初始值;循环控制条件;变量变化))
do
程序
done
#!/bin/bash
#从1加到100
#Author
num=0
for((i=1;i<=100;i++))
do
num=$(($num+$i))
done
echo "this sum of 1+2+...+100 is: $num"
11.5.4 while循环与until循环
1、 while循环
while循环是不定循环,也称作条件循环。只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才会停止。这就和for的固定循环不太一样了。
while [ 条件判断式 ]
do
程序
done
#!/bin/bash
#从1加到100
#Author:shenchao(E-mail:[email protected])
i=1
s=0
while [ $i -le 100 ]
#如果变量i的值小于等于100,则执行循环
do
s=$(($s+$i))
i=$(($i+1))
done
echo"Thesumis:$s"
2、 until循环
until循环,和while循环相反,until循环时只要条件判断式不成立则进行循环,并执行循环程序。一旦循环条件成立,则终止循环。
until [ 条件判断式 ]
do
程序
done
#!/bin/bash
#从1加到100
#Author:shenchao(E-mail:[email protected])
i=1
s=0
until [ $i -gt 100 ]
#循环直到变量i的值大于100,就停止循环
do
s=$(($s+$i))i=$(($i+1))
done
echo"Thesumis:$s"
11.6 函数
语法:
[ function ] funname [()]{
action;
[return int;]
}
[] -> 表示可以省略
tips:在以上的函数语法中,前面的funcation 表示声明一个函数!!! 可以不写 return -n 是指退出函数
参考:https://www.cnblogs.com/YankaiJY/p/8832436.html
#!/bin/bash
funWithReturn(){
echo "这个函数会对输入的两个数字进行相加运算..."
echo "输入第一个数字: "
read aNum
echo "输入第二个数字: "
read anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"return $(($aNum+$anotherNum))}
funWithReturn
echo "输入的两个数字之和为 $? !"
输出:
[timo@local1 sh]$ sh function.sh
这个函数会对输入的两个数字进行相加运算...
输入第一个数字:
12
输入第二个数字:
22
两个数字分别为 12 和 22 !
输入的两个数字之和为 34 !