需求
有班主任需要给每个学生生成成绩报告,班主任有成绩数据了,需要根据成绩生成雷达图并插入到word生成成绩报告,有的还需要把每个学生的插入到ppt家长会的时候用,这种工作机械重复,但是很多班主任不得不做,给班主任带来大量的负担。
同时集团也要求上报学生成绩对比分析,所以批量生成就很重要了。
解决办法
python批量生成
用python写脚本批量生成
编写成绩查询网站
钉钉已经有校园宝可以发送单次成绩并可以查看雷达图,多次成绩对比不能做。且不能导出和生成每个学生的成绩报告,这个属于收费功能。
针对小学部的需求,采用了PHP+MySQL搭建了网站,用PHP的phpoffice生成word,不过PHP的图标模块JpGraph用起来比较繁琐。其实网页端用echarts比较方便。
市面上成绩分析系统已经非常成熟,但是不是所有的学校都有采购,问为什么不用系统就有点何不食肉糜的感觉了。
代码
网站不是很方便,加上我对python的熟悉程度超过PHP,用python写的代码后期简单修改结合flask之类的数据库很容易生成。
用到的库
- 读取excel文件用到了
xlrd库,当然处理excel最好是用numpy库,但是我还不熟悉,用起来不如xlrd直观 - 利用python生成word用到了
docxtpl库,这个根据word模板,只需要填充数据就可以了,一定程度上可以减轻工作量,前提是熟悉模板的语法,不然还是直接生成更加方便 - 利用pptx库生成ppt,也是基于模板生成,不过模板语法跟docxtpl不同,是jinja的语法。
- 生成图表用
matplotlib库
第一版代码
import xlrd
import xlrd
from docxtpl import DocxTemplate, InlineImage
from docx.shared import Mm
import pyecharts
import numpy as np
from random import random
import matplotlib.pyplot as plt
import matplotlib
from docxtpl import DocxTemplate, InlineImage
from docx.shared import Mm
workbook12 = xlrd.open_workbook('mon12.xlsx')
sht12 = workbook12.sheet_by_name('Sheet3')
wbqimo = xlrd.open_workbook('qimo.xlsx')
shtqimo = wbqimo.sheet_by_name('Sheet3')
print(sht12.row_values(1, 2, 10))
print(sht12.nrows)
rank12data = {}
mon12data = {}
for i in range(sht12.nrows):
if i == 0:
continue
scores = sht12.row_values(i, 0, 17)[1:15:][::2]
# mon12data.append({sht12.cell_value(i,0):scores})
# mon12data.append(sht12.row_values(i, 0, 17))
mon12data[sht12.cell_value(i,0)] = scores
# mon12data['rank'] = sht12.cell_value(i, 16)
# print(sht12.cell_value(i,16))
rank12data[sht12.cell_value(i,0)] = sht12.cell_value(i, 16)
qimorank = {}
qimodata = {}
for i in range(shtqimo.nrows):
if i == 0:
continue
scores = shtqimo.row_values(i, 0, 17)[1:15:][::2]
# qimodata.append({shtqimo.cell_value(i,0):scores})
qimodata[shtqimo.cell_value(i,0)] = scores
# qimodata['rank'] = shtqimo.cell_value(i, 16)
# print(shtqimo.cell_value(i,16))
qimorank[shtqimo.cell_value(i,0)] = shtqimo.cell_value(i, 16)
labels = shtqimo.row_values(0,1,15)[::2]
# print(labels)
# print('!!!@@',labels)
# print(qimodata)
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
for stuName, scores in mon12data.items():
# plt.cla()
# plt.title('hello')
# 数据找不到的情况
# 某次考试没成绩
data1 = scores
data2 = qimodata[stuName]
# print('#',len(d1),len(d2))
# print(stuName, d1, d2)
labels = np.array(labels) # 标签
dataLenth = len(labels) # 数据长度
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) # 分割圆周长
d1 = np.concatenate((data1, [data1[0]])) # 闭合
d2 = np.concatenate((data2, [data2[0]])) # 闭合
angles = np.concatenate((angles, [angles[0]])) # 闭合
# plt.title('期末考试')
p1, = plt.polar(angles, d1, 'o-', linewidth=1) #做极坐标系
plt.fill(angles, d1)# 填充
p2, = plt.polar(angles, d2, 'o-', linewidth=1) #做极坐标系
plt.fill(angles, d2)# 填充
plt.legend([p1, p2], ['期中', '期末'],prop={'family':'SimHei'})
plt.thetagrids(angles * 180/np.pi, labels, fontproperties='SimHei') # 设置网格、标签
plt.ylim(0,100) # polar的极值设置为ylim
plt.savefig('radar/{}radar.png'.format(stuName))
# plt.close()
plt.clf()
A = labels
B = data1
print(stuName)
fig, ax1 = plt.subplots(figsize=(12,9))
ax1.plot(A,B,label="期中")
ax1.plot(A,data2,label="期末")
plt.title("{}期中期末成绩折线图".format(stuName),fontproperties='SimHei')
ax1.legend()
ax1.grid(axis="y",color="grey",linestyle="--",alpha=0.5)
ax1.tick_params(axis="x",labelsize=30)
ax1.tick_params(axis="y",labelsize=20)
ax1.set_ylabel("Y",fontsize = 18)
ax1.set_xlabel("X",fontsize = 20)
ax1.set_ylim(0,100)
# ax1.set_yticks(np.linspace(0,15,16))
for tl in ax1.get_yticklabels():
tl.set_color('r')
ax1.spines['top'].set_visible(False)
# fig.text(0.1,0.02,"Author:MingYan",fontproperties='SimHei')
plt.savefig('line/{}line.png'.format(stuName))
plt.close()
doc = DocxTemplate(r"./temp.docx")
context = { 'stuName' : stuName,
'chinese': data1[0],
'maths': data1[1],
'english': data1[2],
'politic': data1[3],
'history': data1[4],
'physical': data1[5],
'hx': data1[6],
'avg':sum(data1),
'chinese1': data2[0],
'maths1': data2[1],
'english1': data2[2],
'politic1': data2[3],
'history1': data2[4],
'physical1': data2[5],
'hx1': data2[6],
'avg1': sum(data2),
'rank': rank12data[stuName],
'rank1':qimorank[stuName],
'linechart':InlineImage(doc, 'line/{}line.png'.format(stuName), width=Mm(100)),
'radarchart':InlineImage(doc, 'radar/{}radar.png'.format(stuName), width=Mm(100)),
}
doc.render(context)
doc.save(r"./doc/{}.docx".format(stuName))
# save_docx([r3,result1[0]])
这个是根据学生的成绩,生成学生4次成绩对比折线图,和4次考试成绩雷达图的对比。

image.png
表头如下
表头
word模板
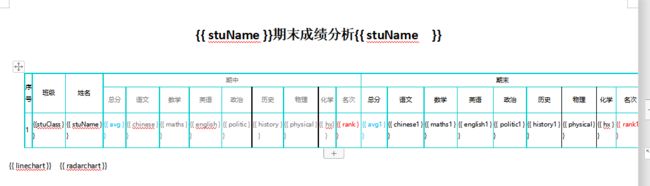
word模板
上面的代码处于试验阶段很原始,后来重构了一下,可以配置文件名,学科字段,并生成成绩雷达图,历次考试成绩对比图,等等
import xlrd
import xlrd
from docxtpl import DocxTemplate, InlineImage
from docx.shared import Mm
import pyecharts
import numpy as np
from random import random
import matplotlib.pyplot as plt
import matplotlib
import os
from docxtpl import DocxTemplate, InlineImage
from docx.shared import Mm
from pptx import Presentation
from pptx.util import Pt, Cm
from pptx.util import Inches
#===================开始设置中文字体=================
font = {
'family' : 'SimHei',
'size' : 12
}
matplotlib.rc('font', **font)
#===================结束设置中文字体=================
class GenerateReport:
def __init__(self, files, stuClass='1.1'):
if not files:
return None
else:
self.files = files
self.radarIndex = 0
# TODO:这种字符串可以用字符串分割方法生成数组
# 反之用数字拼接字符串可以降低拼写的效率
# 怪不得校园宝要设置学科
self.subjects = ['语文','数学','英语','历史','道法','地理','生物','物理']
self.subjects_en = ['chinese','maths','english','history','tao','geography','bio','physical']
self.ranks = []
self.root = stuClass
def mkdir(path):
if not os.path.isdir(path):
mkdir(os.path.split(path)[0],'/')
else:
return
os.mkdir(path)
if not os.path.exists(self.root):
os.mkdir(self.root)
os.mkdir("/{}/doc".format(self.root))
os.mkdir("/{}/line".format(self.root))
os.mkdir("/{}/radar".format(self.root))
self.dataset = self.processFiles(files)
def setTemplate(self, file):
self.template = file
def drawTotalLine(stuName):
pass
def paraXls(self, filename):
# TODO:要添加异常处理
# {
# 'stuName': 'langxm',
# 'scores': [
# {
# 'chinese': 80,
# 'math' : 90
# },
# ],
# 'grades': [
# {
# 'chinese': A,
# 'math' : B
# },
# ],
# 'sum': 20,
# 'rank': 20,
# 'total': 20
# }
dataset = {}
wb = xlrd.open_workbook(filename)
sht = wb.sheet_by_index(0)
rows = sht.nrows
cols = sht.ncols
header = sht.row_values(0, 0, cols)
self.students = sht.col_values(0, 1, rows)
# 查询index的代码有待优化
def getIndex(value, valuelist):
# TODO:重名的情况
return valuelist.index(value)
subjectIndexes = [getIndex(subject, header) for subject in self.subjects]
# TODO:numpy的数组加载xls处理效率更高,可以用numpy的np数组改写
for i in range(1, rows):
line = sht.row_values(i, 0, cols)
stuName = line[0]
scores = [line[index] for index in subjectIndexes]
grades = [line[index + 1] for index in subjectIndexes]
examData = {}
item = {}
item['scores'] = scores
item['grades'] = grades # 这些项目都是可以做成可以配置的
# 可以用工厂模式改写
item['total'] = sum(scores)
item['avg'] = sum(scores) / len(subjectIndexes)
examData[stuName] = item
dataset[stuName] = examData
return dataset
def processFiles(self, files):
d = {}
def setValue(key, value):
d[key] = value
[setValue(file, self.paraXls(file)) for file in files]
return d
def drawRadar(self, stuName, index=0):
labels = np.array(self.subjects) # 标签
dataLenth = len(labels) # 数据长度
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) # 分割圆周长
angles = np.concatenate((angles, [angles[0]])) # 闭合
dataset = []
# stuName = '徐文清'
for file in self.files[index:]:
dataset.append(self.dataset[file][stuName][stuName]['scores'])
polars = []
for ds in dataset:
ds = np.concatenate((ds, [ds[0]]))
p1, = plt.polar(angles, ds, 'o-', linewidth=1) #做极坐标系
polars.append(p1)
plt.legend(polars,[file[0:-5] for file in self.files] ,prop={'family':'SimHei'})
plt.thetagrids(angles * 180/np.pi, labels, fontproperties='SimHei') # 设置网格、标签
plt.ylim(0,100) # polar的极值设置为ylim
plt.savefig(self.root + '/radar/{}radar.png'.format(stuName))
plt.close()
def drawLevelRadar(self, stuName, index=0):
labels = np.array(self.subjects) # 标签
dataLenth = len(labels) # 数据长度
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) # 分割圆周长
angles = np.concatenate((angles, [angles[0]])) # 闭合
dataset = []
# stuName = '徐文清'
levelscore = {'A':1,'B':2,'C':3,'D':4,'E':5}
for file in self.files[index:]:
levels = self.dataset[file][stuName][stuName]['grades']
levels = [levelscore[level] for level in levels]
dataset.append(levels)
polars = []
for ds in dataset:
ds = np.concatenate((ds, [ds[0]]))
p1, = plt.polar(angles, ds, 'o-', linewidth=1) #做极坐标系
polars.append(p1)
plt.legend(polars,[file[0:-4] for file in self.files] ,prop={'family':'SimHei'})
plt.thetagrids(angles * 180/np.pi, labels, fontproperties='SimHei') # 设置网格、标签
plt.ylim(0,5) # polar的极值设置为ylim最大值可配置
plt.savefig(self.root + '/radar/{}radar.png'.format(stuName))
plt.close()
def getRankData(self):
pass
wb = xlrd.open_workbook('812fuck.xlsx')
sht = wb.sheet_by_name('Sheet1')
# print(sht.cell_value(1,2))
rows = sht.nrows
cols = sht.ncols
ddd = {}
for i in range(1, rows):
# fuck[stuName] = [sht.cell_value(i,1),sht.cell_value(1,2),sht.cell_value(1,3),sht.cell_value(1,4)]
# print(sht.row_values(i,0,cols))
fuck[sht.cell_value(i,0)]=sht.row_values(i,1,cols)
self.ddd = ddd
self.randtitles=sht.row_values(0,1,cols)
# print(fuck)
def drawRankLine(self, stuName):
pass
labels = np.array(self.randtitles) # 标签
fig, ax1 = plt.subplots(figsize=(12,9))
# stuName = '徐文清'
ax1.plot(labels, self.ddd[stuName],label='成绩变化图')
plt.title("{}成绩编号图".format(stuName),fontproperties='SimHei',fontsize=30)
ax1.legend()
ax1.grid(axis="y",color="grey",linestyle="--",alpha=0.5)
ax1.tick_params(axis="x",labelsize=16)
ax1.tick_params(axis="y",labelsize=16)
ax1.set_ylabel("成绩",fontsize = 16)
ax1.set_xlabel("学科",fontsize = 16)
ax1.set_ylim(0,400)
for tl in ax1.get_yticklabels():
tl.set_color('r')
ax1.spines['top'].set_visible(True)
plt.savefig(self.root + '/line/{}rank.png'.format(stuName))
plt.close()
def generatePPT(self, stuName, rankpath, radarpath):
pass
prs = Presentation('./812ppt.pptx')
# blank_slide_layout = prs.slide_layouts[6]
# slide = prs.slides.add_slide(blank_slide_layout)
# textbox = slide.shapes.add_textbox(Cm(0.8), Cm(0.8), Cm(4), Cm(1.03)) # left,top为相对位置,width,height为文本框大小
# textbox.text = '水温,PH'.center(10) # 文本框中文字
# prs = Presentation()
title_slide_layout = prs.slide_layouts[4]
# print(len(prs.slide_layouts))
# for x in prs.slide_layouts:
# print(dir(x.placeholders),)
slide = prs.slides.add_slide(title_slide_layout)
title = slide.shapes.title
# linechart = slide.placeholders[0]
# radarchat = slide.placeholders[1]
title.text = "{}同学成绩分析".format(stuName)
# rankpath = 'foo.png'
left = top = Inches(2)
left = Inches(1)
width = height = Inches(6)
linecart = slide.shapes.add_picture(rankpath, left, top, width=width)
# rankpath = 'foo.png'
left = Inches(7)
radar = slide.shapes.add_picture(radarpath, left, top, width=width)
# subtitle.text = "python-pptx was here!"
prs.save('./812ppt.pptx')
def drawLine(self, stuName):
labels = np.array(self.subjects) # 标签
fig, ax1 = plt.subplots(figsize=(12,9))
# stuName = '徐文清'
for file in self.files:
ax1.plot(labels, self.dataset[file][stuName][stuName]['scores'], label=file[0:-5])
plt.title("{}期中期末成绩折线图".format(stuName),fontproperties='SimHei',fontsize=30)
ax1.legend()
ax1.grid(axis="y",color="grey",linestyle="--",alpha=0.5)
ax1.tick_params(axis="x",labelsize=16)
ax1.tick_params(axis="y",labelsize=16)
ax1.set_ylabel("成绩",fontsize = 16)
ax1.set_xlabel("学科",fontsize = 16)
ax1.set_ylim(0,100)
for tl in ax1.get_yticklabels():
tl.set_color('r')
ax1.spines['top'].set_visible(True)
plt.savefig(self.root + '/line/{}line.png'.format(stuName))
plt.close()
def saveDoc(self, stuName):
# plt.clear()
pass
# TODO:模板生成word虽然方便但是写模板变量太烦了
# 后面改成直接生成
doc = DocxTemplate(r"./{}".format(self.template))
dataset = []
# stuName = '徐文清'
context = {}
for file in self.files:
dataset.append(self.dataset[file][stuName][stuName])
context['stuName'] = stuName
for key, ds in enumerate(dataset):
context['file'+str(key)] = self.files[key]
scores = ds["scores"]
for i in range(len(scores)):
context[self.subjects_en[i]+str(key)] = scores[i]
context['total' + str(key)] = sum(scores)
# context['linechart'] = InlineImage(doc, self.root + '/line/{}line.png'.format(stuName), width=Mm(100))
context['radarchart'] = InlineImage(doc, self.root + '/radar/{}radar.png'.format(stuName).format(stuName), width=Mm(100))
doc.render(context)
doc.save(r"./{}/doc/{}.docx".format(self.root, stuName))
def genDocs(self):
self.getRankData()
print(self.ddd)
print(self.ddd['付晶晶'])
for stuName in self.students:
self.drawRankLine(stuName)
self.drawLevelRadar(stuName,index=self.radarIndex)
self.drawRankLine(stuName)
# TODO:文件名应该是可以配置的包括路径
self.saveDoc(stuName)
print('{}的文档已经生成,位于./{}/doc/{}.docx'.format(stuName, self.root, stuName))
if __name__ == "__main__":
pass
gr = GenerateReport(['初二12班期末考试.xls'])
# gr = GenerateReport([])
# gr.radarIndex = 2
gr.setTemplate('86temp.docx')
# gr.drawLine('徐文清')
# print(len(gr.students))
# gr.genDocs()
# gr.generatePPT()
print(gr.students)
for stuName in gr.students:
gr.generatePPT(stuName,gr.root + '/line/{}rank.png'.format(stuName),gr.root + '/radar/{}radar.png'.format(stuName))
# print(gr.dataset)
需要的表格格式与上面相同
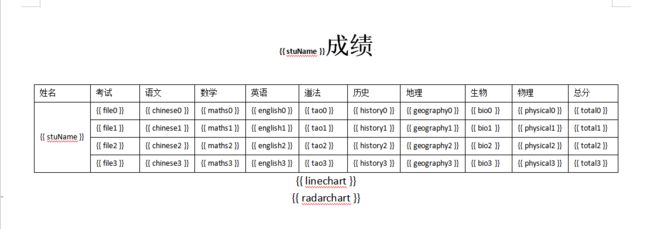
模板