
前言
上回说到垃圾收集机制和内存分配,这回咱们来了解下虚拟机类加载机制。
“代码编译的结果从本地机器码转变为字节码,是存储格式发展的一小步,却是编程语言发展的一大步”
基本概念
类加载周期
加载、验证、准备、解析、初始化、使用、卸载
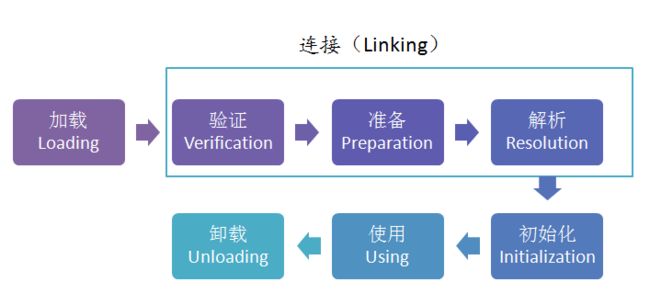
虚拟机规范中规定有且只有5种情况必须立即对类进行初始化。
1). 遇到new,getstatic,putstatic,invokestatic这4条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。
2). 使用java.lang.reflect包的方法对类进行反射调用
3). 当初始化一个类式,发现其父类还没有初始化,先初始化其父类
4). 虚拟机启动时,用户需要制定一个主类(main),虚拟机会先初始化这个主类
5). 当使用JDK1.7动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果是REF_getStatic、REF_putStatic、REF_invokeStatic的方法句柄,则这个方法句柄对应的类需要初始化。
我们通过代码来验证下相关信息
a. 被动使用类字段演示
子类调用父类静态变量时
public class SuperClass {
static{
System.out.println("SuperClass init ...");
}
public static int value=123;
}
public class SubClass extends SuperClass{
static{
System.out.println("SubClass init ...");
}
}
public class NoInitialization {
/**
* -XX:+TraceClassLoading 查看类加载过程
* @param args
*/
public static void main(String[] args) {
System.out.println(SubClass.value);
}
}
运行结果
SuperClass init ...
123
发现,父类初始化了,至于要不要初始化子类,就要看虚拟机了。
b.通过定义数组引用类
public class NoInitialization {
/**
* -XX:+TraceClassLoading 查看类加载过程
* @param args
*/
public static void main(String[] args) {
SuperClass[] sc = new SuperClass[10];
}
}
发现父类,子类均不初始化
c.访问常量不会导致类初始化
public class SuperClass {
static{
System.out.println("SuperClass init ...");
}
public static int value=123;
public final static String hello="hello,world";
}
public class NoInitialization {
/**
* -XX:+TraceClassLoading 查看类加载过程
* @param args
*/
public static void main(String[] args) {
System.out.println(SubClass.hello);
}
}
运行结果
hello,world
原因是常量会在编译阶段存入调用类的常量池中,本质上没有直接引用到定义常量的类
类的加载过程
加载
类加载干了什么呢?通过类的全名来获取定义该类的二进制字节流,将字节流代表的静态存储结构转化为方法区的运行时数据结构,在内存中生成代表这个类的java.lang.Class对象作为这个类各种数据的访问入口,这三步。-
验证
验证是连接阶段的第一步。
java语言之所以是相对安全的语言,是因为使用纯粹的java代码无法实现如访问数组边界以外的数据、将一个对象转型为它并未实现的类型、跳转到不存在的代码行之类的,编译器会帮我们拒绝编译。然而,Class文件并不仅仅是java编译而来的,可以通过别的途径也能实现,如果虚拟机运行时不验证的话,所谓的安全就要打折扣了,因此,虚拟机有了验证作为连接的第一步。- 文件格式验证
验证字节流是否符合Class文件格式的规范,并能被当前版本虚拟机处理。 - 元数据验证
对字节码描述的信息进行语义分析,以保证其描述的信息符合java语言规范的要求,如,这个类是否有父类,这个类是否继承了不允许被继承的类,如果不是抽象类,是否实现其父类或接口中要求实现的所有方法等 - 字节码验证
最复杂的一个阶段,通过数据流和控制流分析,确定程序语义是合法的符合逻辑的。 - 符号引用验证
- 文件格式验证
准备
准备阶段就是正式为类变量分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。这个时候进行的内存分配仅包括类变量即静态变量,而我们的实例变量时分配在堆中。初始值除了final修饰的外,一般是数据类型的零值。如果是final修饰的将直接赋结果值。解析
解析阶段就是虚拟机将常量池内的符号引用替换为直接引用的一个过程。先理解下符号引用和直接引用的概率。
符号引用:使用一组符号来描述所引用的目标,与虚拟机内存布局无关,引用的目标不一定已经加载到内存,明确定义在java虚拟机规范的Class文件中。
直接引用:直接指向目标的指针、相对偏移量或者一个能间接定位到目标的句柄。与内存布局相关,一个引用在不同的虚拟机实例翻译过来一般也不同,引用的目标已经在内存中存在。-
初始化
加载类的最后一步。前面的类加载过程除了加载阶段用户通过自定义类加载器参与外,完全是虚拟机主导的,到了初始化阶段才是真正执行类中定义的java代码。
初始过程是执行类构造器()方法的过程。 ()的特点如下 ()方法是由编译器自动收集类中的所有类变量的复制动作和静态代码块中的语句合并产生。语句是有先后顺序的,如定义在静态代码块之后的变量,静态代码块可以进行赋值,但是不能访问。代码如下
public class FieldResolution {
static{
i=8;
System.out.println(i);
}
static int i;
}
这段代码编译时会报Cannot reference a field before it is defined,非法向前引用。而去掉打印语句,发现程序不会报错,编译源码显示static int i=8; 我们可以认为编辑器会第一时间寻找到int j 的变量,在静态代码块中赋值,如果静态代码块后面初始化过的话,会第二次赋值,这样以程序在后面的为准。
- 由于父类的
()方法会先执行,这就意味着父类中定义的静态代码块要优先于子类的变量赋值操作。 ()对于类或者接口来说不是必需的,如果一个类没有静态代码块也没有对变量的赋值操作,那么编译器可以不为这个类生成 ()方法。 ()会被多线程环境下加锁,同步。
public class DeadLoopClass {
static{
//如果没有if会报Initializer does not complete normally
if(true){
System.out.println(Thread.currentThread().getName()+"init...");
while(true){
}
}
}
}
class TestDemo{
public static void main(String[] args) {
Runnable run = new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println(Thread.currentThread()+"--start");
DeadLoopClass deap = new DeadLoopClass();
System.out.println(Thread.currentThread()+"--over");
}
};
Thread t1 = new Thread(run);
Thread t2 = new Thread(run);
t1.start();
t2.start();
}
}
运行结果
Thread[Thread-0,5,main]--start
Thread[Thread-1,5,main]--start
Thread-0init...
类加载器
通过一个类的全限定名来获取描述此类的二进制字节流,这个动作放到java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。
public class ClassLoaderTest {
public static void main(String[] args) throws ClassNotFoundException {
ClassLoader myLoader = new ClassLoader() {
@Override
public Class loadClass(String name)
throws ClassNotFoundException {
try {
String fileName = name.substring(name.lastIndexOf(".")+1)+".class";
InputStream is = getClass().getResourceAsStream(fileName);
if(is == null){
return super.loadClass(name);
}
byte[] b = new byte[is.available()];
is.read(b);
return defineClass(name, b,0,b.length);
} catch (Exception e) {
throw new ClassNotFoundException(name);
}
}
};
Object obj = myLoader.loadClass("com.classloading.ClassLoaderTest");
System.out.println(obj.getClass());
System.out.println(obj instanceof com.classloading.ClassLoaderTest);
}
}
运行结果
class java.lang.Class
false
我们构造了一个简单的类加载器,加载同一个路径下的Class文件,然后和系统应用程序类加载器的去比较,发现是两个独立的类,因此,类加载器不同,类也不同。
- 双亲委托模型
从java虚拟机角度来讲,只存在两种类加载器:启动类加载器(Bootstrap ClassLoader),其他类加载器,独立于虚拟机外部,且全部继承自java.lang.ClassLoader。
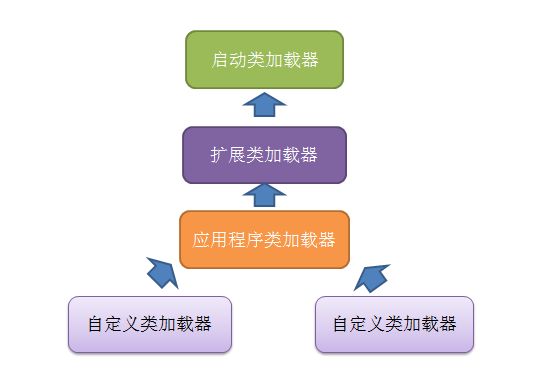
双亲委托模型除了顶部的启动类加载器,其他的都有自己的父加载器。这里类加载器之间的父子关系一般不会以继承的关系来实现,而都是使用组合关系来复用父加载器的代码。
双亲委托模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每个层次的类加载器都是如此,最终传递到了启动类加载器,只有当父加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去加载。
使用双亲委托机制的好处在于,Java类随着它的类加载器一起具备优先级的层次关系,如Object类,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委托给最顶级的类加载器去加载,这样就不会造成系统中存在多个Object类。
- 破坏双亲委托模型
到目前为止出现过三次大规模的被破坏情况
a. 双亲委托模型是在JDK1.2之后引入的,ClassLoader在JDK1.0就存在了,为了向前兼容,在JDK1.2后加入了一个findClass()方法,之前用户继承ClassLoader类唯一目的是重写loadClass方法,后来推荐把自己的类加载逻辑放到findClass方法中。
b. 模型自身缺陷,双亲委托很好的解决了各个类加载器的基础类的统一问题,如果基础类又要调用回用户的代码,这个时候就有问题了。如JNDI服务,JNDI的目的是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath的JNDI接口提供者的代码,但启动类加载器不可能认识这些,为了处理这个问题,引入了线程上下文加载器
c. 用户对程序动态性的追求而导致。比如热部署啊,代码热替换。