蒙特卡洛法详解
蒙特卡洛法详解
- 1. 蒙特卡洛法的理论基础和基本方法
- 2. MCM方法实施流程
- 3. MCM常用函数一览表
- 4. 输入量的概率分布
-
- 4.1 均匀分布
- 4.2 曲线梯形分布
- 4.3 梯形分布
- 4.4 三角分布
- 4.5 反正弦分布
- 4.6 正态分布
- 4.7 多元正态分布
- 4.8 指数分布
- 4.9 伽马分布
- 5. 简单案例实现
蒙特卡洛法可称为计算机随机模拟方法,是一种基于随机数的计算方法。
1. 蒙特卡洛法的理论基础和基本方法
概率论中的大数定理和中心极限定理是蒙特卡洛法的理论基础。大数定理反映了大量随机数之和的性质,即随机数的均值收敛于函数的期望值。中心极限定理是指,无论单个随机变量的分布如何,多个独立随机变量之和服从正态分布。以这两个定理为基础,蒙特卡洛法表述如下,假定函数
![]()
其中,输入变量的概率分布已知,蒙特卡洛法利用随机数发生器抽样获得M组输入变量的值,然后按上述函数关系确定M个输出变量值,当M足够大时,便可给出与实际情况相近的输出变量的数字特征。基本方法:首先,确立一个与求解有关的统计模型,使解为所构建模型的数学期望和概率分布;其次,对模型进行随机抽样,产生随机变量;最后,用算术平均数作为所求解的近似平均值,给出所求解的统计估计值和标准差,即解的精度。
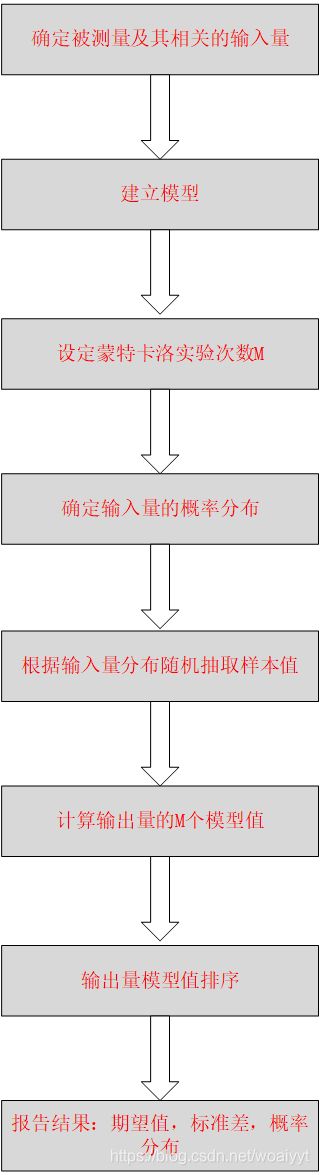
2. MCM方法实施流程
3. MCM常用函数一览表
| 函数 | 说明 |
|---|---|
| unifrnd(a,b,m,n) | 均匀分布(连续)随机数 |
| unidrnd(N,m,n) | 均匀分布(离散)随机数 |
| exprnd(lambda,m,n) | 指数分布随机数 |
| normrnd(mu,sigma,m,n) | 正态分布随机数 |
| trnd(N,m,n) | t分布随机数 |
| gamrnd(a,b,m,n) | 伽马分布随机数 |
| binornd(N,P,m,n) | 二项分布随机数 |
| poissrnd(lambda,m,n) | 泊松分布随机数 |
| std | 标准差 |
| var | 方差 |
| prctile | 百分位数 |
| 概率密度函数 |
4. 输入量的概率分布
4.1 均匀分布
如果了解X的信息只有下限a和上限b,根据最大熵原理,该量在区间 [ a , b ] [a,b] [a,b]服从均匀分布。它的概率密度函数为
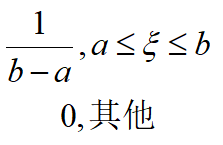
期望和方差为
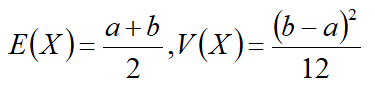
举个例子
x=unifrnd(1,3,1,1000000);
[f,xi]=ksdensity(x);
plot(xi,f);
xlabel('随机抽样值');
ylabel('概率密度');

4.2 曲线梯形分布
已知X位于下限A和上限B之间,且A位于区间 [ a − d , a + d ] [a-d,a+d] [a−d,a+d],B位于区间 [ b − d , b + d ] [b-d,b+d] [b−d,b+d],它的概率密度函数为
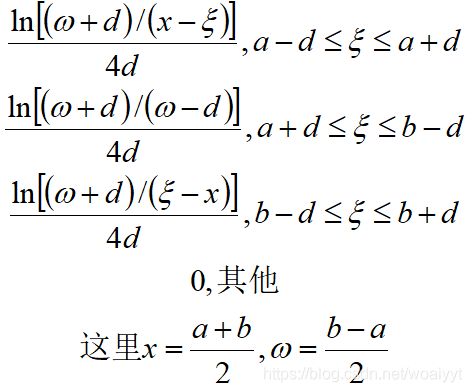
期望和方差为
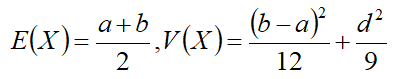
MATLAB没有提供曲线梯形分布函数,利用函数变换法,得如下公式

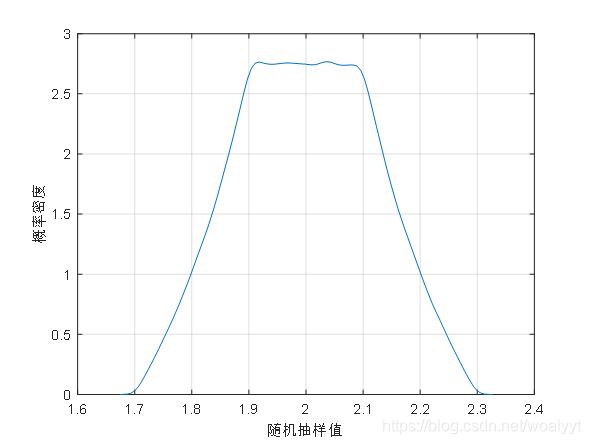
举个例子
r1=rand(1,1000000);
r2=rand(1,1000000);
as=1.8-0.1+2*0.1*r1;
bs=1.8+2.2-as;
x=as+(bs-as).*r2;
[f,xi]=ksdensity(x);
plot(xi,f);
grid on;
xlabel('随机抽样值');
ylabel('概率密度');
4.3 梯形分布
已知X为两个独立量之和,这两个独立量服从均匀分布,那么X服从下限a上限b,上底半宽度与下底半宽度比值为 β \beta β的梯形分布。

它的概率密度函数为
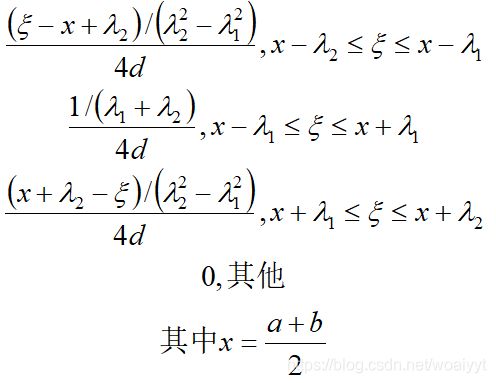
期望和方差为
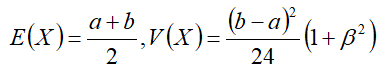
MATLAB没有提供梯形分布函数,利用函数变换法,得如下公式
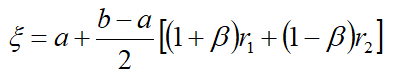
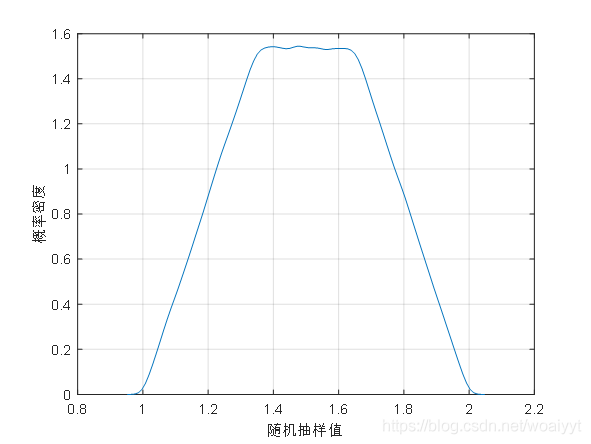
举个例子
r1=rand(1,1000000);
r2=rand(1,1000000);
x=1+(2-1)/2*((1+0.3)*r1+(1-0.3)*r2);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on;
xlabel('随机抽样值');
ylabel('概率密度');
4.4 三角分布
已知X为两个独立量之和,这两个独立量服从均匀分布,且 b 1 − a 1 = b 2 − a 2 b_1-a_1=b_2-a_2 b1−a1=b2−a2,那么X服从下限a上限b的三角分布,它的概率密度函数为
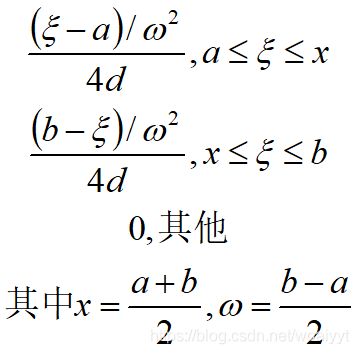
期望和方差为

MATLAB没有提供三角分布函数,利用函数变换法得
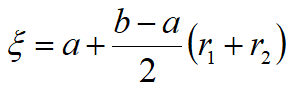
举个例子
r1=rand(1,1000000);
r2=rand(1,1000000);
x=1+(2-1)/2*(r1+r2);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on;
xlabel('随机抽样值');
ylabel('概率密度');
4.5 反正弦分布
已知X在下限a与上限b之间以未知相位正弦周期变化,且相位服从 [ 0 , 2 π ] [0,2\pi] [0,2π]均匀分布,那么X服从反正弦分布,它的概率密度函数为
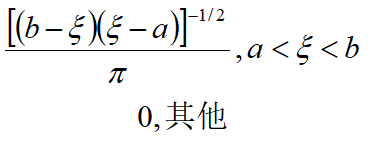
期望和方差为
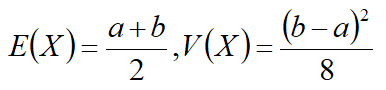
MATLAB没有提供反正弦分布函数,利用函数变换法得
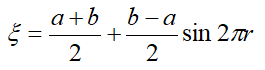
举个例子
r=rand(1,1000000);
x=(1+2)/2+(2-1)/2*sin(2*pi*r);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on;
xlabel('随机抽样值');
ylabel('概率密度');

4.6 正态分布
已知X的期望值和标准差,那么X服从高斯分布,它的概率密度函数为
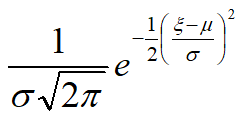
期望和方差已知,举个例子
x=normrnd(1,0.01,1,1000000);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on
xlabel('随机抽样值');
ylabel('概率密度');

4.7 多元正态分布
如果向量X中的N个量都服从正态分布,那么X服从N维多元正态分布,它的概率密度函数为

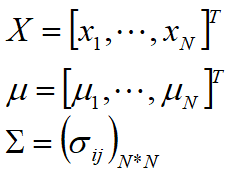
涉及到多元就会出现协方差,这儿不再细说。举个例子
mu=[10;20];
sigma=[1 3;3 16];
x=mvnrnd(mu,sigma,100);
plot(x(:,1),x(:,2));
grid on
xlabel('第一个输入量取值');
ylabel('第二个输入量取值');

4.8 指数分布
仅仅知道非负量X的最佳估计值,那么服从指数分布,它的概率密度函数为
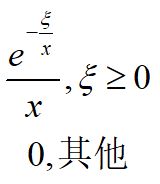
期望和方差为
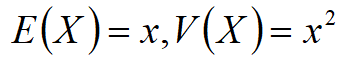
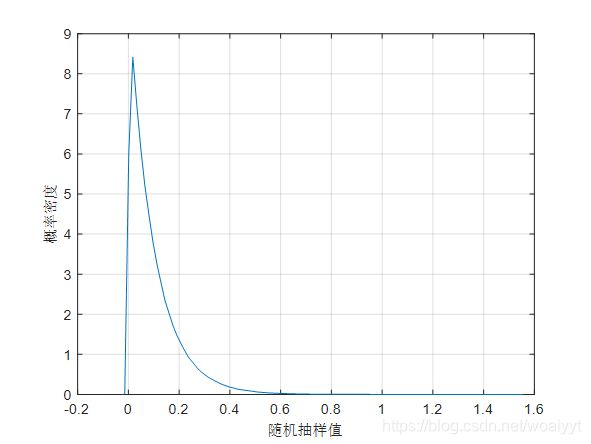
举个例子
x=exprnd(0.1,1,1000000);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on
xlabel('随机抽样值');
ylabel('概率密度');
4.9 伽马分布
已知X是来自固定样本大小的平均数,q是样本计数,这个数符合期望未知的泊松分布,那么根据贝叶斯定理,X服从伽马分布,它的概率密度函数为
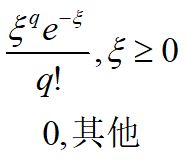
期望和方差为
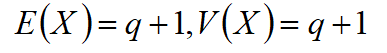
举个例子
x=gamrnd(5,1,1,1000000);
[f,xi]=ksdensity(x);
plot(xi,f);
grid on
xlabel('随机抽样值');
ylabel('概率密度');
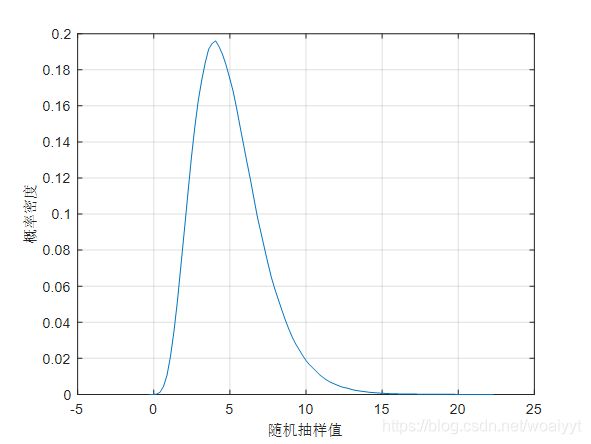
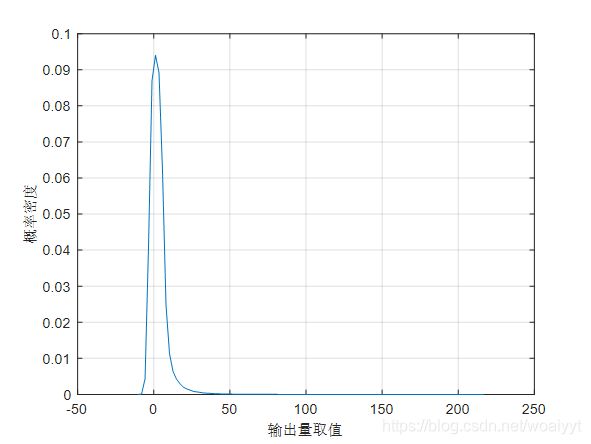
5. 简单案例实现
假设有一个函数关系式为
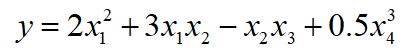
已知这四个输入变量分别服从 [ 0 , 1 ] [0,1] [0,1]均匀分布, [ 2 , 3 ] [2,3] [2,3]均匀分布,正态分布和指数分布,实现代码如下
M=1000000;
x1=unifrnd(0,1,1,M);
x2=unifrnd(2,3,1,M);
x3=normrnd(1.5,0.5,1,M);
x4=exprnd(1.5,1,M);
y=2.*x1.*x1+3.*x1.*x2-x2.*x3+0.5.*x4.*x4;
biaozhuncha=std(y);
junzhi=mean(y);
[f,y]=ksdensity(y);
plot(y,f);
grid on
xlabel('输出量取值');
ylabel('概率密度');
biaozhuncha =
5.8602
junzhi =
2.9168