NOSQL介绍
一、NQSQL概述
1.1 什么是NOSQL
首先需要说的是,NoSql并不表示NO SQL"没有SQL"的意思。实际上,它是"Not Only SQL"的缩写。它的意义是:适用关系型数据库的时候就使用关系型数据库,不适用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。为弥补关系型数据库的不足,各种各样的NoSQL数据库应运而生。
1.2数据库分类
数据库根据不同的数据模型(数据的表现形式)主要分成阶层型,网络型和关系型3种。
(1) 阶层型数据库
早期的数据库称为阶层型数据库,数据的关系都是以简单的树形结构来定义的。程序也通过树形结构对数据进行访问。这种结构,父记录(上层的记录)同时拥有多个子记录(下层记录),子记录只有唯一的父记录。正因为如此,这种非常简单的构造在碰到复杂数据的时候往往会造成数据的重复(同一数据在数据库内重复出现),出现数据冗余的问题。阶层型数据库如下图所示:
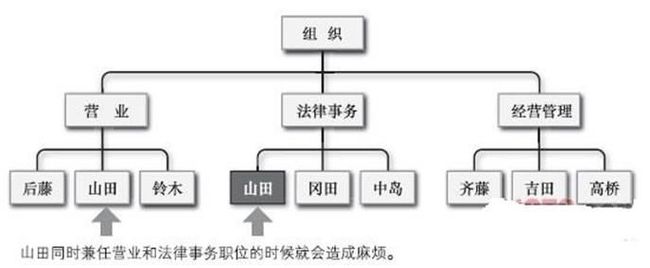
阶层型数据库把数据通过阶层结构的方式表现出来,虽然这样的结构有利于提高查询效率,但与此相对应的是,不理解数据结构就无法进行高效的查询。当然,在阶层结构发生变更的时候,程序也需要进行相应的变更。
(2) 网络型数据库
前所述,阶层型数据库会带来数据重复的问题。为了解决这个问题,就出现了网络型数据库。它拥有同阶层型数据库相近的数据结构,同时各种数据又如同网状交织在一起,因此而得名。阶层型数据库只能通过父子关系来表现数据之间的关系。针对这一不足,网络型数据库可以使子记录同时拥有多个父记录,从而解决了数据冗余的问题。下图所示为网络型数据库。
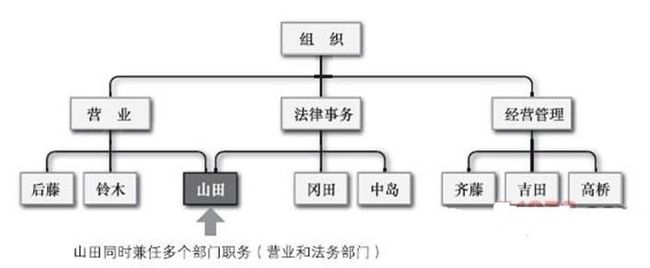
但是,在网络型数据库中,数据间比较复杂的网络关系使得数据结构的更新变得比较困难。另外,与阶层型数据库一样,网络型数据库对数据结构有很强的依赖性,不理解数据结构就无法进行相应的数据访问。
(3) 关系型数据库
最后要向大家介绍的是以科德提出的关系数据模型为基础的关系型数据库。关系型数据库把所有的数据都通过行和列的二元表现形式表示出来,给人更容易理解的直观感受。网络型数据库存在着数据结构变更困难的问题,而关系型数据库可以使多条数据根据值来进行关联,这样就使数据可以独立存在,使得数据结构的变更变得简单易行。对于阶层型数据库和网络型数据库,如果不理解相应的数据结构,就无法对数据进行读取,它们对数据结构的依赖性很强。因此,它们往往需要专业的工程师使用特定的计算机程序进行操作处理。相反,关系型数据库将作为操作对象的数据和操作方法(数据之间的关联)分离开来,消除了对数据结构的依赖性,让数据和程序的分离成为可能。这使得数据库可以广泛应用于各个不同领域,进一步扩大了数据库的应用范围。
1.3 关系型数据库优势
(1) 通用性及高性能
关系型数据库的性能绝对不低,它具有非常好的通用性和非常高的性能"。毫无疑问,对于绝大多数的应用来说它都是最有效的解决方案。
(2) 突出的优势
关系型数据库作为应用广泛的通用型数据库,它的突出优势主要有以下几点:
■保持数据的一致性(事务处理)
■由于以标准化为前提,数据更新的开销很小(相同的字段基本上都只有一处)
■可以进行JOIN等复杂查询
■存在很多实际成果和专业技术信息(成熟的技术)。
这其中,能够保持数据的一致性是关系型数据库的最大优势。在需要严格保证数据一致性和处理完整性的情况下,用关系型数据库是肯定没有错的。但是有些情况不需要JOIN,对上述关系型数据库的优点也没有什么特别需要,这时似乎也就没有必要拘泥于关系型数据库了。
1.4 关系型数据库的不足
(1) 不擅长的处理
就像之前提到的那样,关系型数据库的性能非常高。但是它毕竟是一个通用型的数据库,并不能完全适应所有的用途。具体来说它并不擅长以下处理:
■大量数据的写入处理
■为有数据更新的表做索引或表结构(schema)变更
■字段不固定时应用
■对简单查询需要快速返回结果的处理
下面逐一进行详细的说明。
(2) 大量数据的写入处理
在数据读入方面,由复制产生的主从模式(数据的写入由主数据库负责,数据的读入由从数据库负责),可以比较简单地通过增加从数据库来实现规模化。但是,在数据的写入方面却完全没有简单的方法来解决规模化问题,读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来实现读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为了这个时候的网站标配。
例如,要想将数据的写入规模化,可以考虑把主数据库从一台增加到两台,作为互相关联复制的二元主数据库来使用。确实这样似乎可以把每台主数据库的负荷减少一半,但是更新处理会发生冲突(同样的数据在两台服务器同时更新成其他值),可能会造成数据的不一致。为了避免这样的问题,就需要把对每个表的请求分别分配给合适的主数据库来处理,这就不那么简单了。下图所示为两台主机问题和二元主数据库问题的解决办法。
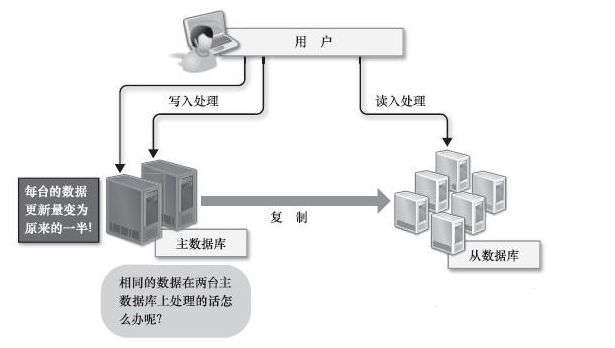
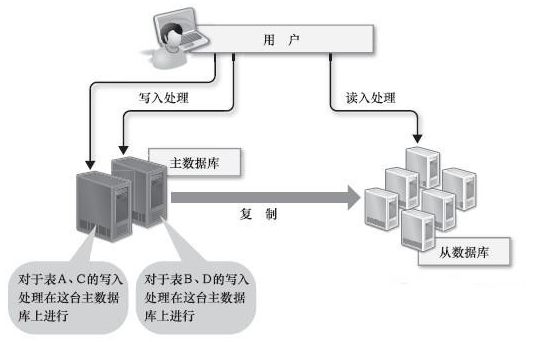
另外也可以考虑把数据库分割开来,分别放在不同的数据库服务器上,比如将这个表放在这个数据库服务器上,那个表放在那个数据库服务器上。数据库分割可以减少每台数据库服务器上的数据量,以便减少硬盘I/O(输入/输出)处理,实现内存上的高速处理,效果非常显著。但是,由于分别存储在不同服务器上的表之间无法进行JOIN处理,数据库分割的时候就需要预先考虑这些问题。数据库分割之后,如果一定要进行JOIN处理,就必须要在程序中进行关联,这是非常困难的。下图所示为数据库分割。
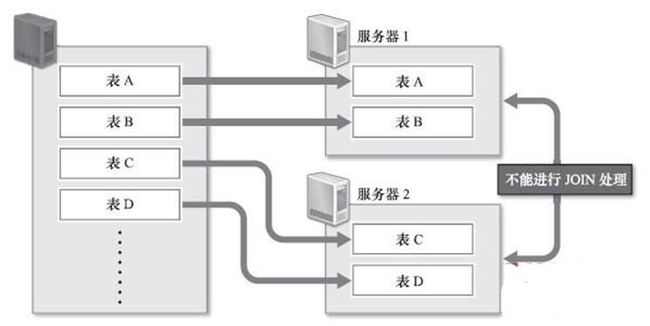
(3) 为有数据更新的表做索引或表结构(schema)变更
在使用关系型数据库时,为了加快查询速度需要创建索引,为了增加必要的字段就一定需要改变表结构。为了进行这些处理,需要对表进行共享锁定,这期间数据变更(更新、插入、删除等)是无法进行的。如果需要进行一些耗时操作(例如为数据量比较大的表创建索引或者是变更其表结构),就需要特别注意:长时间内数据可能无法进行更新。下表所示为共享锁和排他锁。
| 名称 |
锁的影响范围 |
别名 |
| 共享锁 |
其他连接可以对数据进行读取但是不能修改数据 |
读锁 |
| 排它锁 |
其他连接无法对数据进行读取和修改操作 |
写锁 |
(4) 字段不固定时的应用
如果字段不固定,利用关系型数据库也是比较困难的。有人会说"需要的时候,加个字段就可以了",这样的方法也不是不可以,但在实际运用中每次都进行反复的表结构变更是非常痛苦的。你也可以预先设定大量的预备字段,但这样的话,时间一长很容易弄不清楚字段和数据的对应状态(即哪个字段保存哪些数据),所以并不推荐使用。下图所示为使用预备字段的情况。

(5) 对简单查询需要快速返回结果的处理
最后还有一点,这点似乎称不上是缺点,但不管怎样,关系型数据库并不擅长对简单这里所说的"简单"指的是没有复杂的查询条件,而不是用JOIN的意思。的查询快速返回结果。因为关系型数据库是使用专门的SQL语言进行数据读取的,它需要对SQL语言进行解析,同时还有对表的锁定和解锁这样的额外开销。这里并不是说关系型数据库的速度太慢,而只是想告诉大家若希望对简单查询进行高速处理,则没有必要非用关系型数据库不可。
在这种情况下,我想推荐大家使用NoSQL数据库。但是像MySQL提供了利用HandlerSocket这样的变通方法,也是可行的。虽然使用的是关系型数据库MySQL,但并没有利用SQL而是直接进行数据访问。这样的方法是非常快速的。下图所示为HandlerSocket的概要。
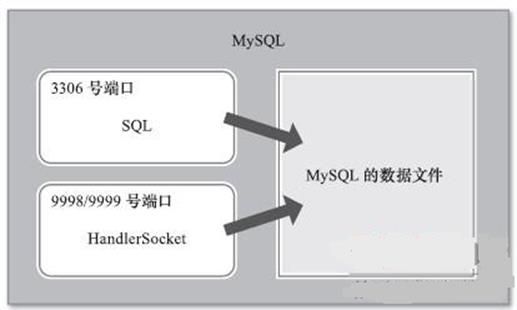
二、NoSQL数据库
上节介绍了关系型数据库的不足之处。为了弥补这些不足(特别是最近几年),NoSQL数据库出现了。关系型数据库应用广泛,能进行事务处理和JOIN等复杂处理。相对地,NoSQL数据库只应用在特定领域,基本上不进行复杂的处理,但它恰恰弥补了之前所列举的关系型数据库的不足之处。
2.1 易于数据的分散
如前所述,关系型数据库并不擅长大量数据的写入处理。原本关系型数据库就是以JOIN为前提的,就是说,各个数据之间存在关联是关系型数据库得名的主要原因。为了进行JOIN处理,关系型数据库不得不把数据存储在同一个服务器内,这不利于数据的分散。相反,NoSQL数据库原本就不支持JOIN处理,各个数据都是独立设计的,很容易把数据分散到多个服务器上。由于数据被分散到了多个服务器上,减少了每个服务器上的数据量,即使要进行大量数据的写入操作,处理起来也更加容易。同理,数据的读入操作当然也同样容易。
2.2 提升性能和增大规模
下面说一点题外话,如果想要使服务器能够轻松地处理更大量的数据,那么只有两个选择:一是提升性能,二是增大规模。下面我们来整理一下这两者的不同。
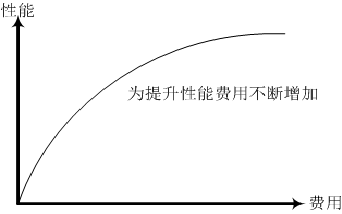
首先,提升性能指的就是通过提升现行服务器自身的性能来提高处理能力。这是非常简单的方法,程序方面也不需要进行变更,但需要一些费用。若要购买性能翻倍的服务器,需要花费的资金往往不只是原来的2倍,可能需要多达5~10倍。这种方法虽然简单,但是成本较高。下图所示为提升性能的费用与性能曲线。
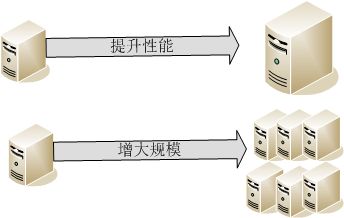
另一方面,增大规模指的是使用多台廉价的服务器来提高处理能力。它需要对程序进行变更,但由于使用廉价的服务器,可以控制成本。另外,以后只要依葫芦画瓢增加廉价服务器的数量就可以了。下图所示为提升性能和增大规模。
2.3 不对大量数据进行处理的话就没有使用的必要吗
NoSQL数据库基本上来说为了"使大量数据的写入处理更加容易(让增加服务器数量更容易)"而设计的。但如果不是对大量数据进行操作的话,NoSQL数据库的应用就没有意义吗?
答案是否定的。的确,它在处理大量数据方面很有优势。但实际上NoSQL数据库还有各种各样的特点,如果能够恰当地利用这些特点,它就会非常有用。具体的,这些用途将会让你感受到利用NoSQL的好处。
■希望顺畅地对数据进行缓存(Cache)处理
■希望对数组类型的数据进行高速处理
■希望进行全部保存
三、多样的NoSQL数据库
NoSQL说起来简单,但实际上到底有多少种呢?在官方网站上确认了一下,竟然已经有122种了。另外官方网站上也介绍了图形数据库和对象数据库等各个类别。目前,常见的NoSQL数据库分为"键值存储库"、"文档型数据库"、"列存储数据库"等各种各样的种类,每种数据库又包含各自的特点。具有代表性的Nosor数据库如下图所示:
| 临时性键值存储 |
永久性键值存储 |
面向文档的数据库 |
面向列的数据库 |
| memcached |
Tokyo Tyrant |
MongoDB |
Cassandra |
| (Redis) |
Flare |
CouchDB |
Hbase |
| ROMA |
HyperTable |
||
| (Redis) |
3.1 键值存储
这是最常见的NoSQL数据库,它的数据是以键值的形式存储的。虽然它的处理速度非常快,但是基本上只能通过键的完全一致查询获取数据。根据数据的保存方式可以分为临时性、永久性和两者兼具3种。
(1) 临时性
所谓临时性就是"数据有可能丢失"的意思。memcached把所有数据都保存在内存中,这样保存和读取的速度非常快,但是当memcached停止的时候,数据就不存在了。由于数据保存在内存中,所以无法操作超出内存容量的数据(旧数据会丢失)。
■ 在内存中保存数据
■ 可以进行非常快速的保存和读取处理
■ 数据有可能丢失
(2) 永久性
Tokyo Tyrant、Flare、ROMA等属于这种类型。和临时性相反,所谓永久性就是"数据不会丢失"的意思。这里的键值存储不像memcached那样在内存中保存数据,而是把数据保存在硬盘上。与memcached在内存中处理数据比起来,由于必然要发生对硬盘的IO操作,所以性能上还是有差距的。但数据不会丢失是它最大的优势。
■ 在硬盘上保存数据
■ 可以进行非常快速的保存和读取处理(但无法与memcached相比)
■ 数据不会丢失
(3) 两者兼具
Redis属于这种类型。Redis有些特殊,临时性和永久性兼具,且集合了临时性键值存储和永久性键值存储的优点键值。Redis首先把数据保存到内存中,在满足特定条件(默认是1 5分钟一次以上,5分钟内10个以上,1分钟内10 000个以上的键发生变更)的时候将数据写入到硬盘中。这样既确保了内存中数据的处理速度,又可以通过写入硬盘来保证数据的永久性。这种类型的数据库特别适合于处理数组类型的数据。
■ 同时在内存和硬盘上保存数据
■ 可以进行非常快速的保存和读取处理
■ 保存在硬盘上的数据不会消失(可以恢复)
■ 适合于处理数组类型的数据
3.2面向文档的数据库
MongoDB、CouchDB属于这种类型。它们属于NoSQL数据库,但与键值存储相异。
(1) 不定义表结构
面向文档的数据库具有以下特征:即使不定义表结构,也可以像定义了表结构一样使用。关系型数据库在变更表结构时比较费事,而且为了保持一致性还需修改程序。然而NoSQL数据库则可省去这些麻烦(通常程序都是正确的),确实是方便快捷。
(2) 可以使用复杂的查询条件
跟键值存储不同的是,面向文档的数据库可以通过复杂的查询条件来获取数据。虽然不具备事务处理和JOIN这些关系型数据库所具有的处理能力,但除此以外的其他处理基本上都能实现。这是非常容易使用的NoSQL数据库。
■ 不需要定义表结构
■ 可以利用复杂的查询条件
3.3 面向列的数据库
Cassandra、Hbase、HyperTable属于这种类型。由于近年来数据量出现爆发性增长,这种类型的NoSQL数据库尤其引人注目。
(1) 面向行的数据库和面向列的数据库
普通的关系型数据库都是以行为单位来存储数据的,擅长进行以行为单位的读入处理,比如特定条件数据的获取。因此,关系型数据库也被称为面向行的数据库。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据。面向行的数据库和面向列的数据库比较如下表所示:
| 数据类型 |
数据存储方式 |
优势 |
| 面向行的数据库 |
以行为单位 |
对少量行进行读取和更新 |
| 面向列的数据库 |
以列为单位 |
对大量行少数列进行读取,对所有行的特定列同时进行更新 |
(2) 高扩展性
面向列的数据库具有高扩展性,即使数据增加也不会降低相应的处理速度特别是写入速度,所以它主要应用于需要处理大量数据的情况。另外。利用面向列的数据库的优势,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的。但由于面向列的数据库跟现行数据库存储的思维方式有很大不同,应用起来十分困难。
■ 高扩展性{特别是写入处理)
■ 应用十分困难
最近,像Twitter和Facebook这样需要对大量数据进行更新和查询的网络服务不断增加,面向列的数据库的优势对其中一些服务是非常有用的,大家有兴趣可以自己研究一下。
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【Sunddenly】。本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。