本人纯手工码字哦,请耐心看完,有信心可以带你完整学会这个实战案例
一、需求分析:
1、下载 http://www.win4000.com/wallpaper.html 下指定分类 指定尺寸 的图片
2、本地保存,单个文件夹的形势保存对应图片
二、技术点分析:
使用 python 3.6
1、 爬虫requests
2、 多线程threading
3、文件io读写操作
4、xpath 提取url
5、 正则
三、实战
1、分析url :搞清楚各个url 的关联
http://www.win4000.com/wallpaper_205_0_10_1.html
URL中与分类的关系:
wallpaper : 桌面壁纸
205 :壁纸分类 对应 大陆明星
10 : 图片尺寸 对应 1920*1080
分析到这一部,我们知道 ,如果要需要其他类型的壁纸,只需要更改网站 分类 代码 就可以了
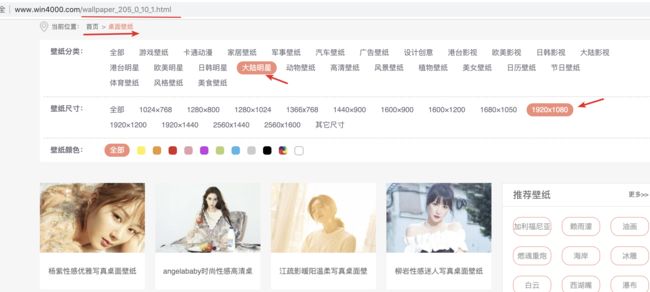
2、谷歌 charme ,通过右键检查
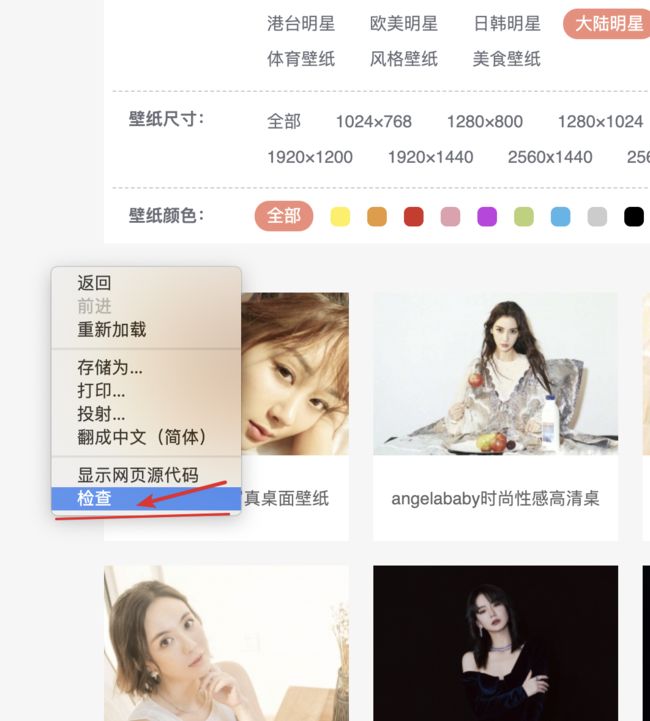
通过查看,我们发现 中间展示 的图片是由一个ul 标签包裹的 多个Li
我们所要跳转的链接 就在 Li 标签中, 这时就需要使用xpath进行数据的提取
到此,我们第一层url 的分析就完成了。可以写出以下 代码段
# url
base_url = "http://www.win4000.com/wallpaper_205_0_10_1.html"
# 自定义请求头
headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
}
# 利用request 发出请求
resp= requests.get(url=base_url,headers=headers)
“”“
数据提取之lxml:安装方式:pip install lxml
1 导入lxml 的 etree 库 (导入没有提示不代表不能用) `from lxml import etree` 2 利用etree.HTML,将字符串转化为Element对象,Element对象具有xpath的方法,返回结果的列表,能够接受bytes类型的数据和str类型的数据 示例:html = etree.HTML(text) ret_list = html.xpath("xpath字符串")
”“”
resp_html = etree.HTML(resp.text) # resp的text 取得页面数据
#关键步骤,提取当前页面的子级 url ,也是 图三 中 第3步标注的位置。 此次使用xpath 相关知识点
li_list = resp_html.xpath('.//div[@class="Left_bar"]//ul[@class="clearfix"]') # 获取到 页面中的ul
此时 通过xpath 获到当前页面中的 ul 中所有li 标签 了
那单个明星的跳转链接只需要再次xpath 进行提取就Ok了。
# xpath 获取到 单个Li中的 url 和标题 并打印
for li in li_list:
star_url = li.xpath('.//a/@href')
star_name = li.xpath('.//a/@title')
print(star_url, star_name) # 打印查看
print(len(star_url), len(star_name)) # 通过数据也能检查出,匹配的正确与否
完成到这里,你的代码 运行结果应该如下:是两个列表list
['http://www.win4000.com/wallpaper_detail_112165.html','http://www.win4000.com/wallpaper_detail_112023.html'] ['张卫健高清电脑桌面壁纸图片', '陈伟霆《一笔江湖》MV图片壁纸']
2、准备下载 图片
到这,完成第一步,你已经成功获到 每个明星的跳转链接 :
url: http://www.win4000.com/wallpaper_detail_153895.html
我再次进行url 的分析:
通过图5的分析,可以找到 这张图,是我们要 1080规格的。
但很可惜,一共9张,现在只能找到一张图片的url,
选其中两张图片地址对比:
http://pic1.win4000.com/wallpaper/2018-12-26/5c22eb195abe8.jpg
http://pic1.win4000.com/wallpaper/2018-12-26/5c22eb1c722dc.jpg
好像就是后面 文件名不同。如果一张张取是不是很麻烦?
不信你自己去试一下。哈哈
我点再分析一下页面,有个 【查看原图】 选项,点一下试试呢?
点完发现了 url 的变化
注意看之前的Url 是
http://www.win4000.com/wallpaper_detail_153895.html
点了【查看原图】之后 url 的变化
http://www.win4000.com/wallpaper_big_153895.html
发现没有, 只是地址栏 的detail 变成了 big 而已。
再看看有没有惊喜的地方 :
通过图7的分析 ,我们发现原来 这个 big 页面 有我们想要的所有 1080P的图片,
而且,全是用ul 包裹,放到单个Li 标签中 。
那简单了,用之前的办法 再提取一次,就出来了。
代码如下:
# 还记得 前面的代码 运行结果么,是不是一个地址列表
“”“
star_url 里面 'http://www.win4000.com/wallpaper_detail_147191.html'
这样的url 我们第二步分析得出 把 detail 换成 big 就行
具体的代码操作如下:
”“”
for url in star_url:
new_url = re.sub("detail", "big", url) # 替换连接
# 得到了 新的url 再次 发送请求 (发现是不是和之前第一步做的还有点像)
resp = requests.get(url=new_url, headers=headers)
resp_html = etree.HTML(resp.text)
li_list = resp_html.xpath('//*[@id="picBox"]/ul[@class="cf"]') # 取到ul 标签下的所有内容
# 遍历li取出所有图片的地址
for li in li_list:
star_img_url = li.xpath('.//a/@href') # 获得名星1080图片
star_img_name = li.xpath('.//a/img/@title') # 获得名星名字,用来后面设置为文件夹的名字
print(star_img_url) # 打印看看
到这里,我们第一步就完成了一页 24个明星 图片的地址url的爬取。第二步,完成了单个明星的1080图片地址url的爬取。
下一步,我们把图片保存到本地就顺利结束,
3、图片保存
按需求,要单独到一个文件夹内。
那我们就需要 在本地路径内 创建对应的文件夹。 此处使用 star_img_name 列表中的值
需要使用到i/o读写操作
# 创建文件夹
ospath = star_img_name[0] # 取列表中的 标题做为文件夹名字
if not os.path.exists(ospath):
os.makedirs(ospath)
# 遍历图片链接 ,并输出到 本地文件夹内
for url in star_img_url:
resp_context = requests.get(url=url, headers=headers)
index = star_img_url.index(url) # 用下标做为图片的标题
path = ospath + "/" + str(index) + ".jpg" # 构建图片保存路径
with open(path, 'wb+') as f:
f.write(resp_context.content)
顺利完成 这个需求:

代码运行结果与我不同,那看一眼我的源码:
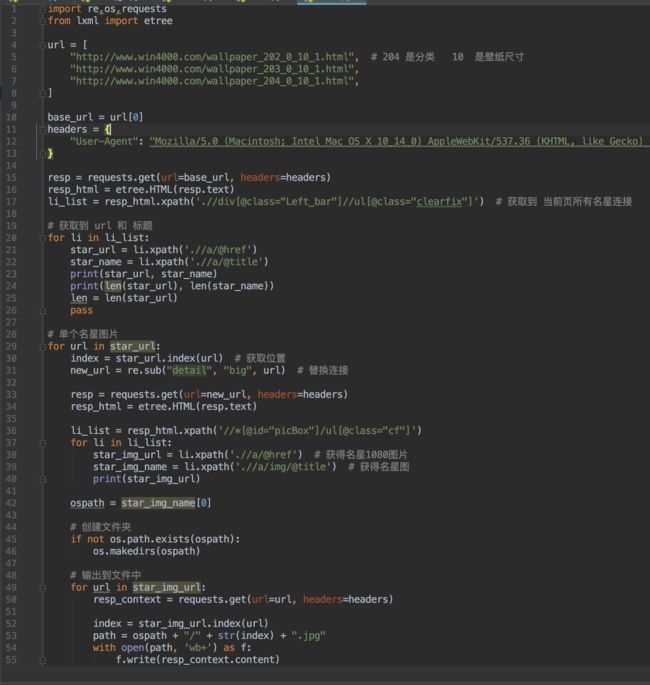
运行起来是不是很慢(完善版使用多线程),而且这样看代码,是不是有种:干干巴巴的,麻麻咧咧的,一点都不圆润,盘他!!
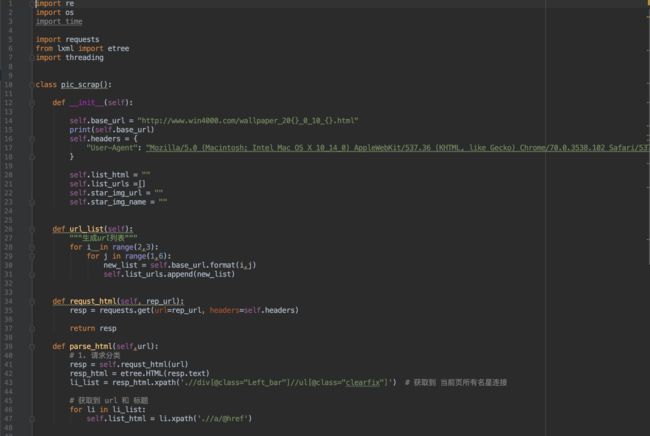
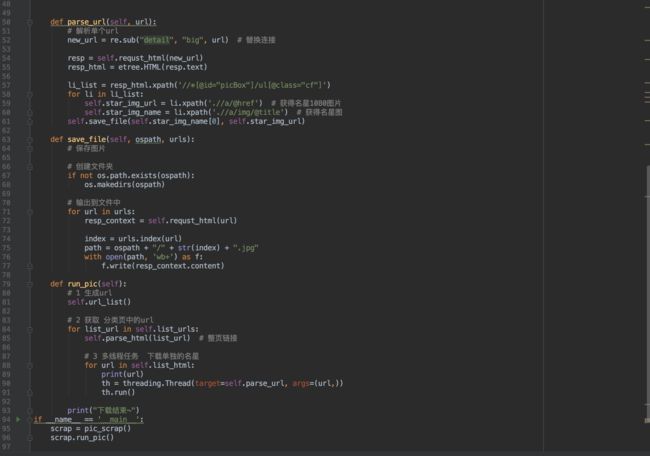
完善版 是 可以完成可选分类,可选规格 ,多线程版。
希望这个小实战案例可以帮到大伙。
喜欢的话,多多点赞哈