python scrapy介绍+豆瓣案列
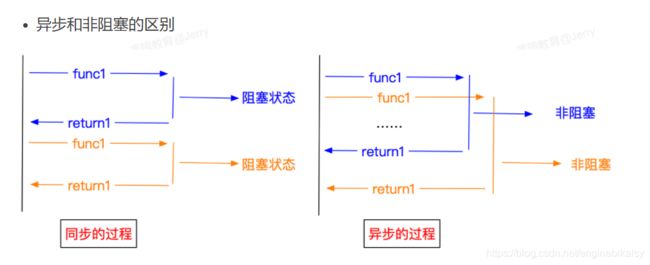
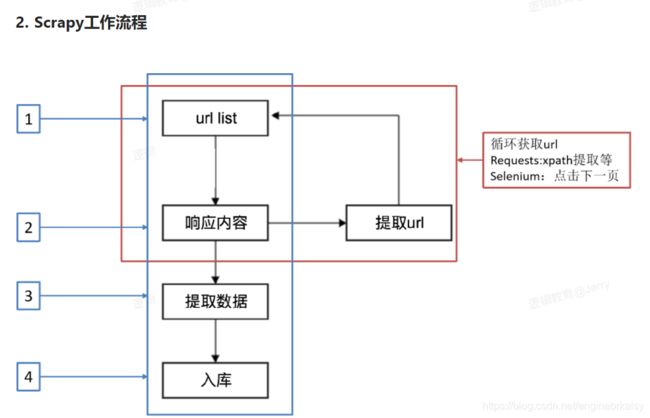
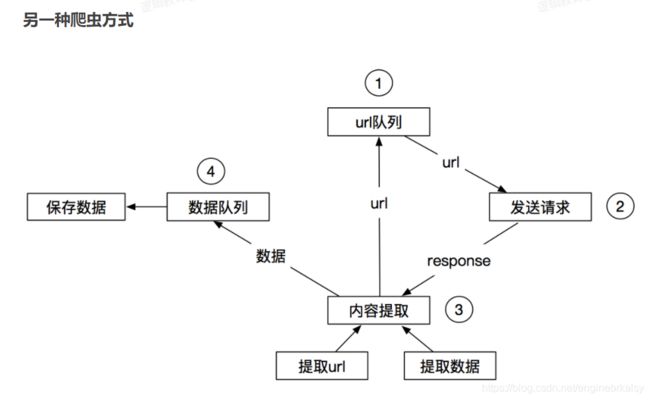
python scrapy介绍


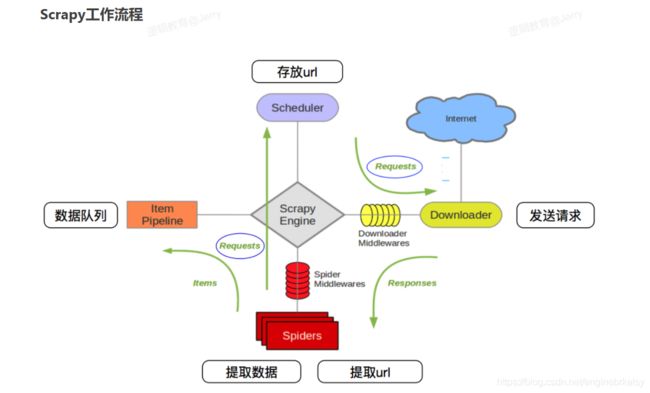
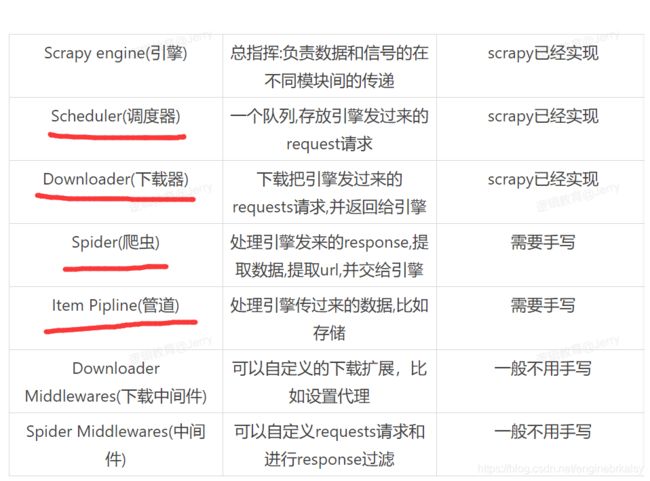
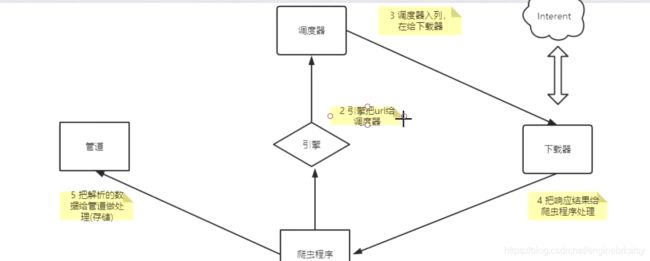

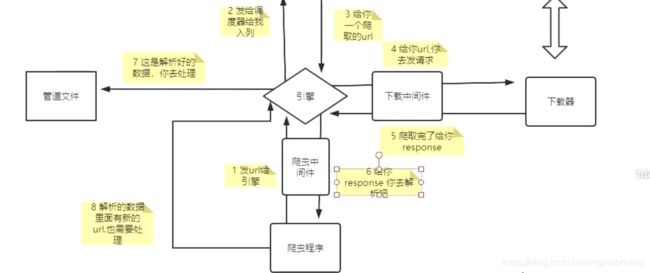
scrapy命令
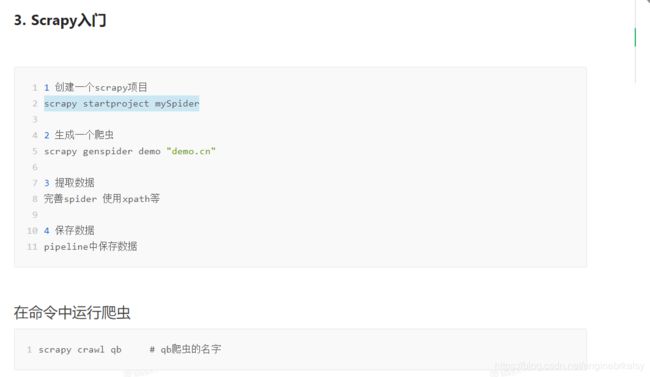
cd路径下,scrapy startproject 命名

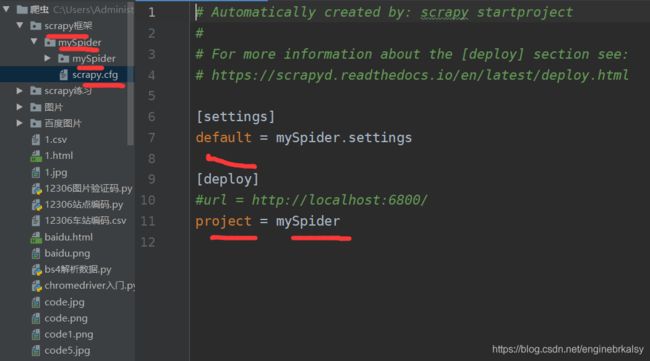



命名的doubanspider.py:
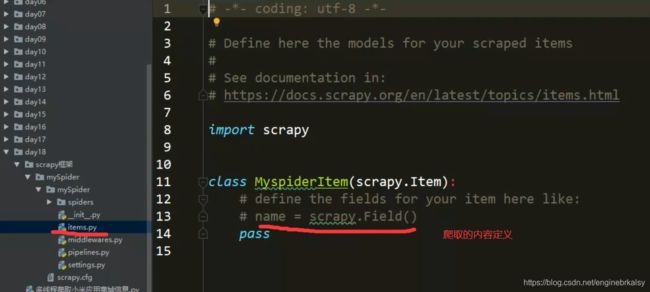
item文件:
middlewaves:


pipline:
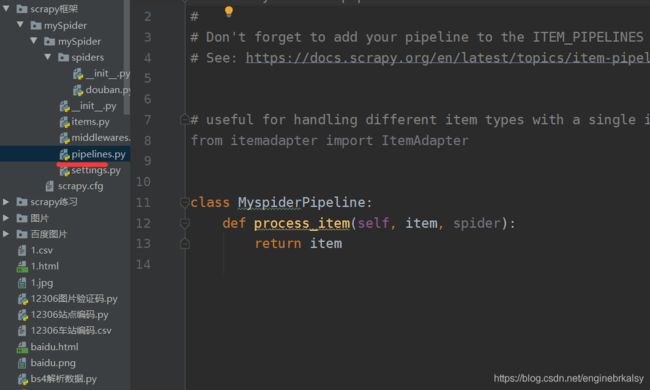
setting:
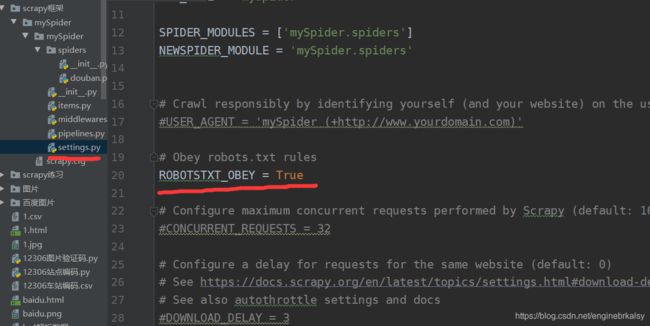
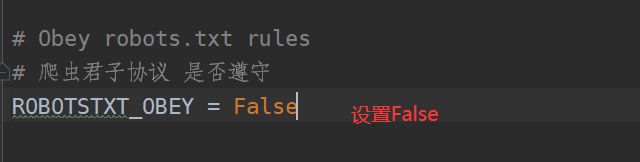


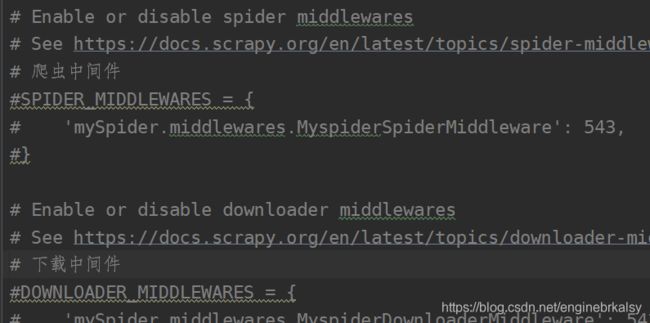
scarpy执行命令1——终端输入scrapy crawl 名字

![]()
运行结果
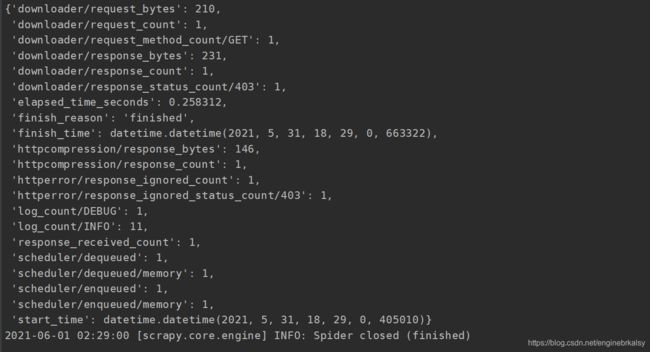


解决:复制一个headers放在setting的请求头处

加了请求头后
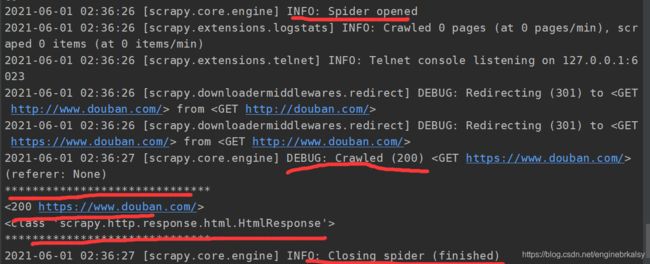
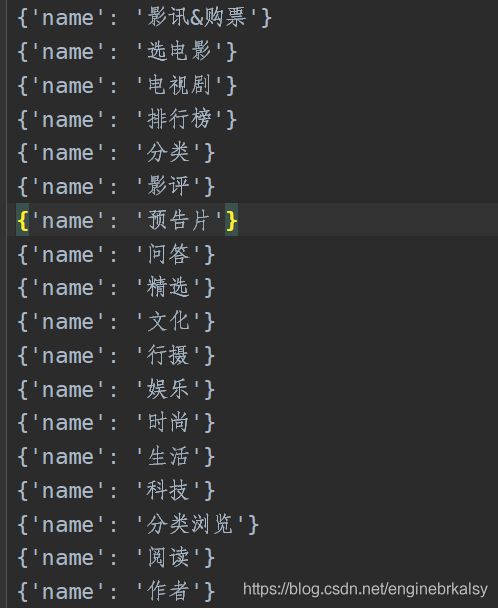
爬取豆瓣的标题
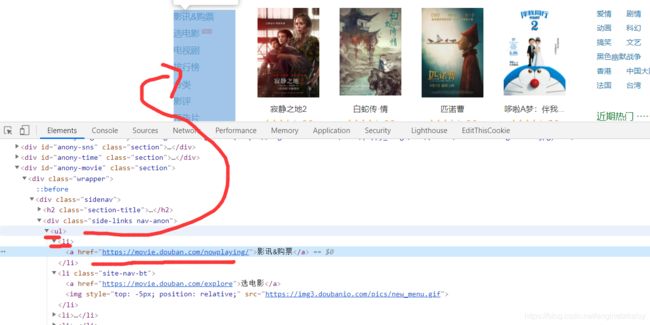

用xpath,之前用的是from lxml import etree,而在scrapy有xpath封装
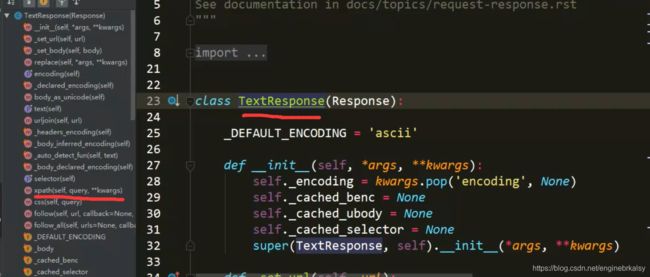
现在的导入命令:from scrapy.http.response.html import HtmlResponse


在setting中添加这一句,可以只呈现所要的结果


结果多了selectors,解决方式是用extract()【多条数据】,或者getall()【多条数据】,extract_first()【一条数据】,get()【一条数据】
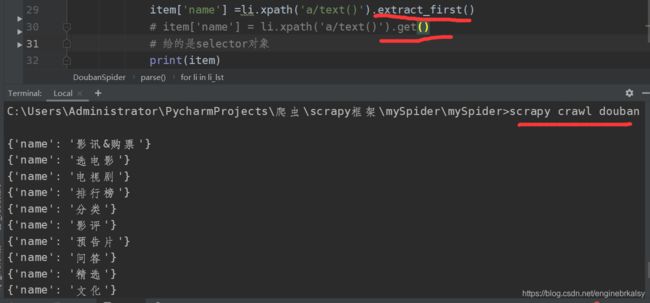
在书和音乐中多了一个\n,原因是这里多了一个em标签
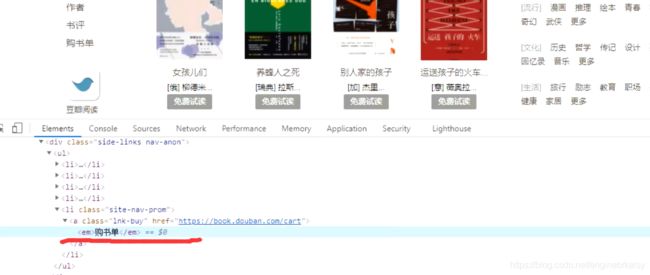
解决方式,先获取这个em标签,再用其他的代替他(有的标签没有em,就是空了,因此,空的就执行以下语句)
运行scrapy的第二个方式,在文件夹中创建一个新的py文件运行
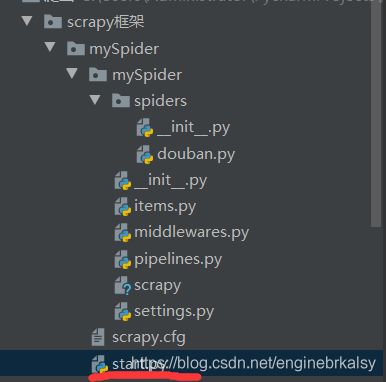
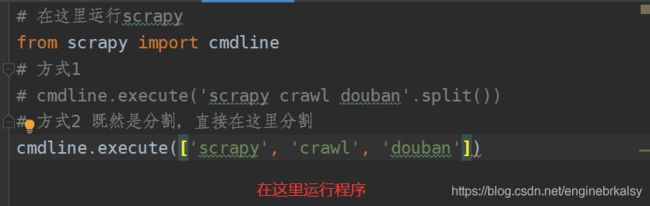
方式1:from scrapy import cmdline,然后执行cmdline.execute('scrapy.crawl 文件名’).split()
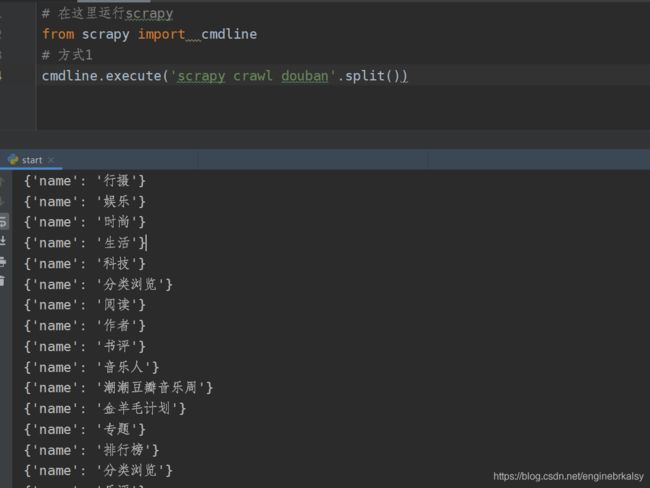
方式2 ——既然是分割,直接在这里分割:from scrapy import cmdline,然后执行cmdline.execute([‘scrapy’, ‘crawl’, ‘douban’])

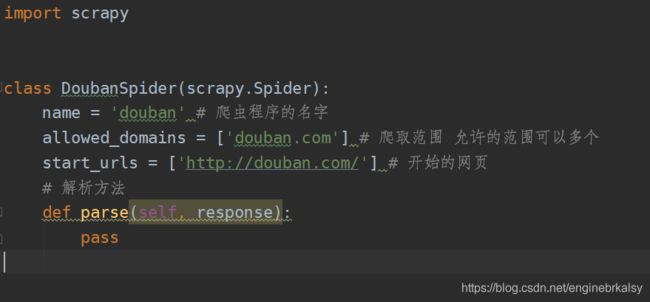
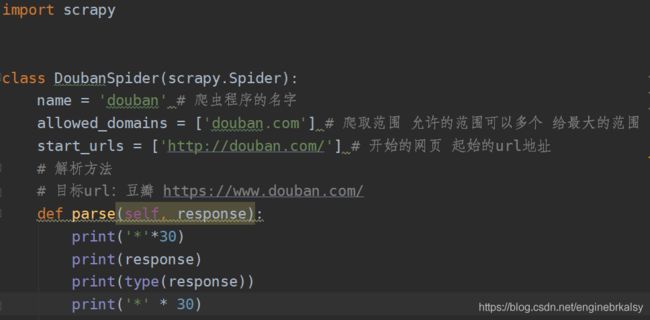
import scrapy
# from lxml import etree 之前用xpath的导入
# 现在导入的命令
from scrapy.http.response.html import HtmlResponse
class DoubanSpider(scrapy.Spider):
name = 'douban' # 爬虫程序的名字
allowed_domains = ['douban.com'] # 爬取范围 允许的范围可以多个 给最大的范围
start_urls = ['http://douban.com/'] # 开始的网页 起始的url地址
# 解析方法
# 目标url:豆瓣 https://www.douban.com/
def parse(self, response):
# print('*'*30)
# print(response)
# print(type(response))
# print('*' * 30)
# 用xpath找到所需数据 //*[@id="anony-movie"]/div[1]/div[1]/div[1]/ul/li
li_lst =response.xpath('.//div[@class="side-links nav-anon"]/ul/li')
item ={
}
# 要的是li的a标签的文本
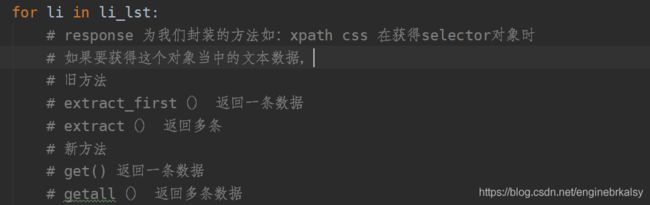
for li in li_lst:
# response 为我们封装的方法如:xpath css 在获得selector对象时
# 如果要获得这个对象当中的文本数据,
# 旧方法
# extract_first() 返回一条数据
# extract() 返回多条
# 新方法
# get() 返回一条数据
# getall() 返回多条数据
# 先获取em标签的内容
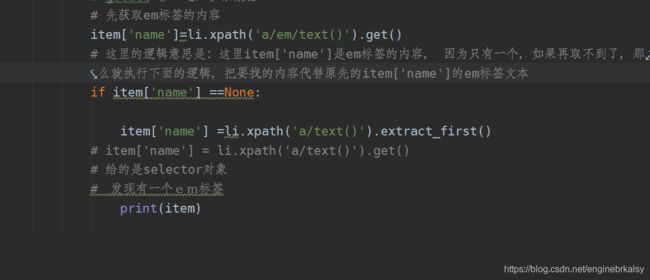
item['name']=li.xpath('a/em/text()').get()
# 这里的逻辑意思是:这里item['name']是em标签的内容, 因为只有一个,如果再取不到了,那么就执行下面的逻辑,把要找的内容代替原先的item['name']的em标签文本
# 有的标签没有em,就是空了,因此,空的就执行以下语句
if item['name'] ==None:
item['name'] =li.xpath('a/text()').extract_first()
# item['name'] = li.xpath('a/text()').get()
# 给的是selector对象
# 发现有一个em标签
print(item)
# 在这里运行scrapy
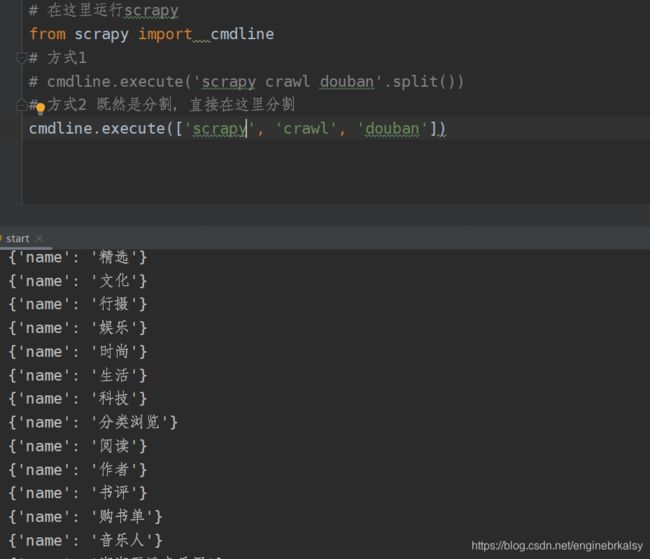
from scrapy import cmdline
# 方式1
# cmdline.execute('scrapy crawl douban'.split())
# 方式2 既然是分割,直接在这里分割
cmdline.execute(['scrapy', 'crawl', 'douban'])

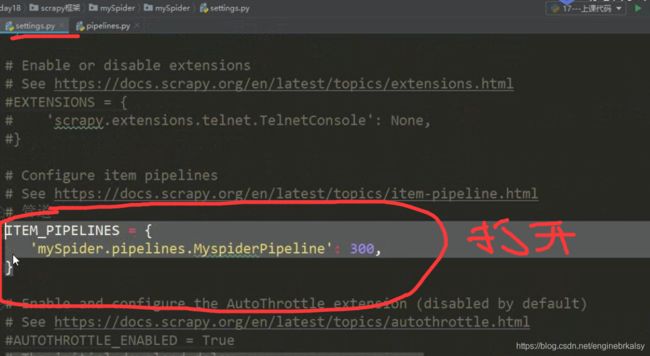
把数据给管道
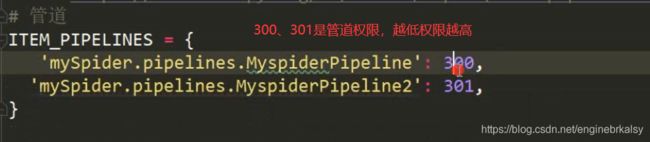
scrapy爬虫程序:

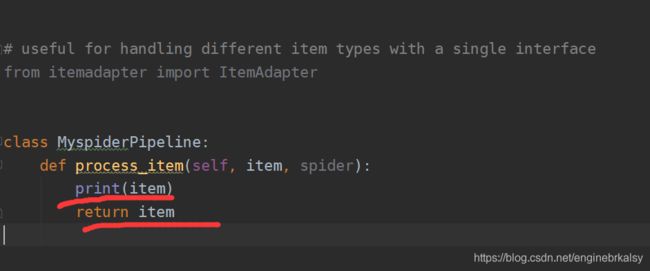
pipline文件:
start文件


pipline管道文件:

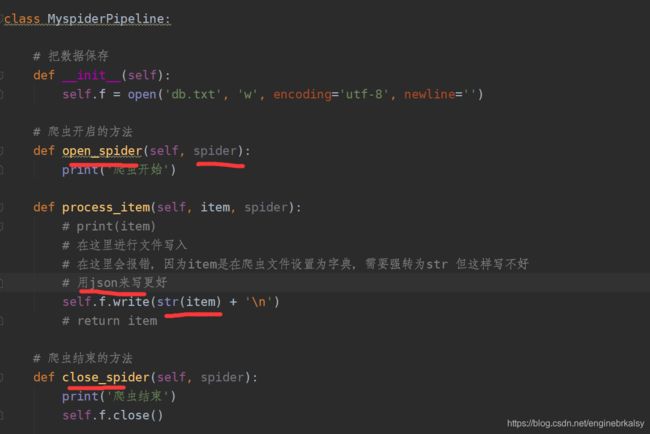
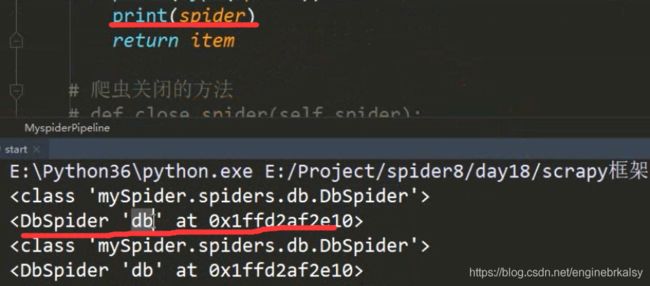
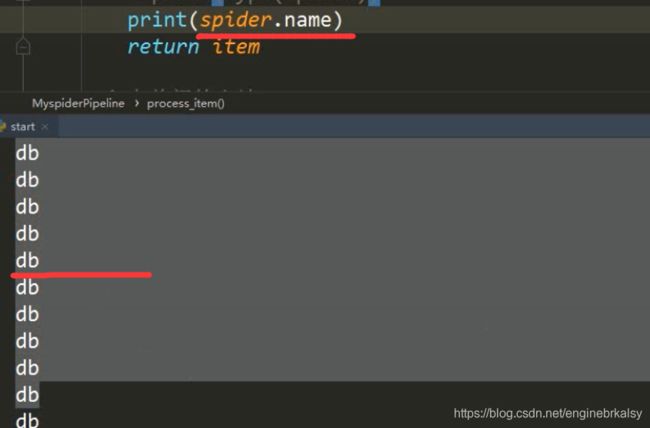
结果: