redis系列,redis6.0多线程解密!
文章目录
- 前言
-
- io 多线程初识
-
- io多线程的读:
- io多线程的写:
- 多线程io的配置详细注释
- io 多线程深入
-
- io多线程的初始化
- io多线程的处理
- io多线程的触发和停止
- 总结
前言
redis 6.0推出,听大家谈论得最多就是redis 变成多线程了,这到底是怎么回事,本文会给你全网最详细的多线程讲解,从多线程初始化,到多线程是如何应用,以及你该如何去配置多线程,本文会给出最详细的讲解。
io 多线程初识
redis 多线程指的是redis 6.0的io 多线程特性,为了避免歧义,首先得说在redis6.0之前并不是没有其它子线程的运行,(比如4.0的link 异步删除空间就是子线程在处理,具体代码在bio.c,这个文件),而6.0的io 多线程指的是,我们可以通过配置文件,打开io 多线程的读或者写。
io多线程的读:
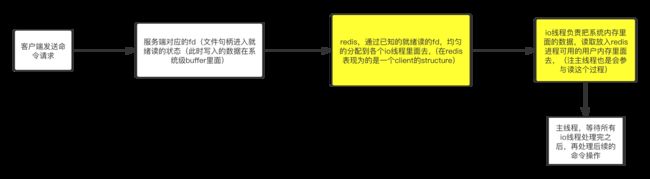
上图标黄的部分为redis io多线程读的部分也就是说,io线程读的部分仅仅就是从通道里面的数据读到redis的用户内存,为主线程下一步执行命令做好准备。
io多线程的写:

上图标黄的部分为redis io多线程写的部分也就是说,io线程写的部分也仅仅就是从redis内存里面将需要返回给客户端的数据写入到通道并清除相关用户内存。
多线程io的配置详细注释
################################ THREADED I/O #################################
# Redis is mostly single threaded, however there are certain threaded
# operations such as UNLINK, slow I/O accesses and other things that are
# performed on side threads.
# reids 几乎是一个单线程的应用,尽管,在某些情况下是异步操作,像 unlink, 慢的io 接口。
# Now it is also possible to handle Redis clients socket reads and writes
# in different I/O threads. Since especially writing is so slow, normally
# Redis users use pipelining in order to speedup the Redis performances per
# core, and spawn multiple instances in order to scale more. Using I/O
# threads it is possible to easily speedup two times Redis without resorting
# to pipelining nor sharding of the instance.
# 上文大体的意思在没有多线程io之前我们为了应付io处理慢的情况下我们会使用pipeline 或者集群来分散io的写入
# 现在可以多一个选择,就是打开多线程io ,当我们没有使用pipeline 的情况下,整体性能比以前提高2倍(注redis-cluster(集群) 客户端不支持pipeline)
# By default threading is disabled, we suggest enabling it only in machines
# that have at least 4 or more cores, leaving at least one spare core.
# Using more than 8 threads is unlikely to help much. We also recommend using
# threaded I/O only if you actually have performance problems, with Redis
# instances being able to use a quite big percentage of CPU time, otherwise
# there is no point in using this feature.
# 默认情况下多线程io是关闭的,建议至少机器要4个核或者更多的时候开启,至少留一个核给核心主线程,建议不要超过8个线程,
# 当整个redis 确实cpu 的占用特别高 ,一般来说我们看到cpu用到70到80左右(项目经验),不然这个feature是没必要开启的
# So for instance if you have a four cores boxes, try to use 2 or 3 I/O
# threads, if you have a 8 cores, try to use 6 threads. In order to
# enable I/O threads use the following configuration directive:
# 4核的时候建议 io-threads 设置成2或者3,8核的时候建议设置为6,通常情况下设置为4。
# io-threads 为1的时候就代表只有主线程再运行,默认也为1.
# io-threads 4
#
# Setting io-threads to 1 will just use the main thread as usually.
# When I/O threads are enabled, we only use threads for writes, that is
# to thread the write(2) syscall and transfer the client buffers to the
# socket. However it is also possible to enable threading of reads and
# protocol parsing using the following configuration directive, by setting
# it to yes:
# 这个变量意思,是否开启多线程读,当开启多线程io的时候,默认情况下只会负责多线程写,而写的内容就是将客户端的buffer写到socket里面去。
# 如果下面这个变量是yes的话,那么多线程io 同样也会负责读
# io-threads-do-reads no
# 多线程io读能带来性能提升会比较小
# Usually threading reads doesn't help much.
# 以下几种情况上面的设置没有用,1,在运行阶段开启这个变量,2 使用ssl的时候
# NOTE 1: This configuration directive cannot be changed at runtime via
# CONFIG SET. Aso this feature currently does not work when SSL is
# enabled.
#
# NOTE 2: If you want to test the Redis speedup using redis-benchmark, make
# sure you also run the benchmark itself in threaded mode, using the
# --threads option to match the number of Redis theads, otherwise you'll not
# be able to notice the improvements.
# 这里的建议如果要测试redis 的提升性能 建议使用redis-benchmark这个工具,且需要和io线程能匹配起来不然,难看到性能上面的提升
############################ KERNEL OOM CONTROL ##############################
redis 作者给出了非常详细建议用法,我们可以总结以下关键信息
- 默认io多线程是关闭,因为比起性能的提升,需要的资源更多。
- 在cpu资源充足的情况下,建议开启io多线程,但也只是会在,有很多客户端同时操作redis 的时候才会有比较明显的性能提升,(网上有人做过具体的测试,可参考,百度搜redis 多线程io 测试
- 如果同时需要开启多线程读,需要同时把下面io-threads-do-reads 设置为yes,但是可以看到多线程读提升的性能有限。(主要redis也是一个读大于写的系统),所以io多线程写能提升redis 性能比多线程读更好一点,但整体的性能并不是成几何数的增长,性能最多有两倍的提升
io 多线程深入
下面的环节是源码解读的环节,将把从io多线程的初始化,触发,处理,和关闭四个环节分别深入讲解。
io多线程的初始化
首先redis 主程序的开始就是从server.c 的main 方法开始,而io线程的初始化也在server.c这里
/* Some steps in server initialization need to be done last (after modules
* are loaded).
* Specifically, creation of threads due to a race bug in ld.so, in which
* Thread Local Storage initialization collides with dlopen call.
* see: https://sourceware.org/bugzilla/show_bug.cgi?id=19329 */
void InitServerLast() {
bioInit();
//io多线程初始化
initThreadedIO();
set_jemalloc_bg_thread(server.jemalloc_bg_thread);
server.initial_memory_usage = zmalloc_used_memory();
}
/* Initialize the data structures needed for threaded I/O. */
//启动io多线程
void initThreadedIO(void) {
//初始化的时候设置线程为不活跃,这里很重要因为涉及到io多线程触发
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
//如果配置io线程为1就代表,只有主线程处理io事件,则返回
if (server.io_threads_num == 1) return;
//设置的io线程数不能超过最大线程数,最大为128,超过会导致redis 无法启动
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
//开始初始化
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
//初始化io线程的链表,这里主要是io线程存读写任务的地方
io_threads_list[i] = listCreate();
//i=0的时候是主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
//子线程初始化
pthread_t tid;
//互斥锁分id初始化
//i 为子线程的编号
//给每个io线程分配为一个锁
pthread_mutex_init(&io_threads_mutex[i],NULL);
//初始化等待被处理的事件(读事件或者写时间都会在这里设置值),这是一个整型数组,i为线程的编号,数组项的value为等待处理的个数
io_threads_pending[i] = 0;
// 这里调用lock的目的是在于没有调用startThreadedIO 这个方法之前,每个子线程,会因为锁的关系进入休眠状态,那为什么不用sleep了,其实也很简单,即我要用到iothread的时候,会立马进入使用状态,这是非常巧妙的涉及,请在这个地方多想想。
// 有以下几种情况,1,长时间没有更多的客户端信息要处理,2,即本来连接到redis 客户端比较少的时候后
//线程会进入休眠状态, 直到有更多的客户端事件需要处理
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
//创建线程,开启线程
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
//
io_threads[i] = tid;
}
}
_Atomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM];
/* This is the list of clients each thread will serve when threaded I/O is
* used. We spawn io_threads_num-1 threads, since one is the main thread
* itself. */
list *io_threads_list[IO_THREADS_MAX_NUM];
上图主要关注几个全局变量,
1,io_threads_list 是一个链表数组,即为下图的结构
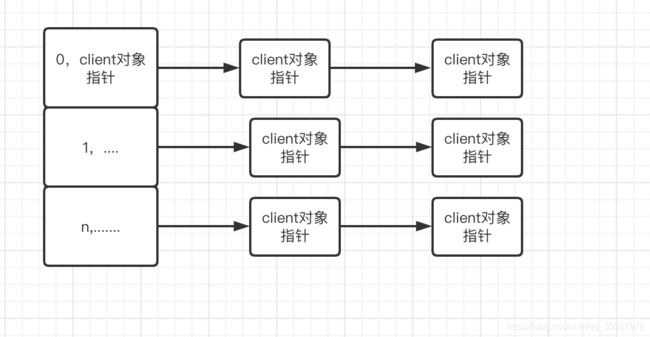
存放的value,是等待读或者写的客户端。
2, io_threads_pending是记录处理事件个数的数组,使用到的数组长度为io线程的个数,但是数组的长度初始化是128
3, 给每个线程分配一个锁,是为了当整个redis 处于很小的读写的状态的时候为了让这些io线程休眠。
4, 上图锁我认为是非常巧妙的设计,这个还请认真看文章的读者,认真多思考。
io多线程的处理
//异步线程是如何处理的
//默认io线程最大数128个,每个io线程都会服务于一个
//这个是io线程执行的主流程
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
//这个id 就是线程id 跟 每个正在操作的客户端关联起来
long id = (unsigned long)myid;
char thdname[16];
//打印线程名
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
//设置线程title
redis_set_thread_title(thdname);
//设置cpu 亲和性 那io线程绑定在逻辑cpu上面
//这样的话能提升最大cpu使用效率,亲和性处理,redis.conf可以自行配置。
redisSetCpuAffinity(server.server_cpulist);
while(1) {
/* Wait for start */
for (int j = 0; j < 1000000; j++) {
//等待线程被开启
if (io_threads_pending[id] != 0) break;
}
/* Give the main thread a chance to stop this thread. */
//这里应该是一个勾子来停止该线程的运行,
//有以下几种情况会进入,
if (io_threads_pending[id] == 0) {
//可以看到前面初始化有调用lock,所以在没有调用startThreadIo 这个方法之前,会在这里给锁住,当有更多写任务的时候就会调用startThreadIo来开启这里
pthread_mutex_lock(&io_threads_mutex[id]);
//至于这里为什么unlock 也很简单,这个不是叠加锁,即unlock一次就会把锁全部解放掉,放在这里就是为了防止stopThreadIo()方法里面的锁形成一个死锁,导致卡死主线程。
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
/* Process: note that the main thread will never touch our list
* before we drop the pending count to 0. */
//保证主线程用不会触及到这个list,直到等待数降为0
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
//写事件返回数据到客户端
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
//读取客户端数据到querybuffer 里面
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
//清空具体的事件等待下一轮的开始
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}
上图的代码的主线分为几步, 循环等待事件发生-> 如果长时间没有读写事件产生,则进入休眠状态,等待主线程的唤醒 有读写事件->负责具体的读或者写但不参与其它逻辑操作-> 清空相关数组等待下次事件的呼唤。
io多线程的触发和停止
读事件的触发:
/* When threaded I/O is also enabled for the reading + parsing side, the
* readable handler will just put normal clients into a queue of clients to
* process (instead of serving them synchronously). This function runs
* the queue using the I/O threads, and process them in order to accumulate
* the reads in the buffers, and also parse the first command available
* rendering it in the client structures. */
/**
* 下面的方法是一个读响应事件,如果我们开启了io 多线程,那么我会将事件均匀分配到我们的io 线程里面去
* 然后客户端的命令值转化成我们客户端命令结构
* @return
*/
int handleClientsWithPendingReadsUsingThreads(void) {
//判断io线程是否就绪,是否开启io线程读
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
//客户端负责就绪
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
/* Distribute the clients across N different lists. */
// 遍历client_pending_read 这个链表
listIter li;
listNode *ln;
//li 可以看为list里面的元素,第二这是一个链表,将li设置为head
//为了遍历链表,首先我们得设置一个头节点
listRewind(server.clients_pending_read,&li);
int item_id = 0;
//轮询分配数据到各个链表里面,
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the
* start condition atomic var. */
io_threads_op = IO_THREADS_OP_READ;
//给予等待io线程一个信号,让他们能够开始运行起来
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
/* Also use the main thread to process a slice of clients. */
//主线程也参与读取value
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
//清空数据列表
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
//等待所有io线程处理完毕
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
/* Run the list of clients again to process the new buffers. */
//这里会再运行一次,来客户端产生的新buffer 并清除掉clients_pending_read的数据
while(listLength(server.clients_pending_read)) {
//获取头节点
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
//flags 取反求交集代表 ,消除client 等待读的状态。
//注: flags 是一个多状态并存的
c->flags &= ~CLIENT_PENDING_READ;
//删除节点
listDelNode(server.clients_pending_read,ln);
if (c->flags & CLIENT_PENDING_COMMAND) {
//表示现在客户端已经到了可以执行命令的阶段
// 消除客户端等待执行命令的阶段
c->flags &= ~CLIENT_PENDING_COMMAND;
//如果执行命令错误,就会跳过下个阶段。
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
}
processInputBuffer(c);
}
/* Update processed count on server */
//统计线程的处理数
server.stat_io_reads_processed += processed;
return processed;
}
上面的方法在beforesleep 方法被调用具体后面我们会讲redis的主线大循环里面被调用到
上面代码有几个信息点
1,所有的读事件分配都是由主线程分配。
2,主线程会等待这一轮所有io线程处理完操作,然后才会进行下面的流程,所有的状态扭转也都是主线程在处理,这样的好处是避免线程间的资源同步竞争,将无状态的事交给其它io子线程。
写事件的触发
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
/* If I/O threads are disabled or we have few clients to serve, don't
* use I/O threads, but thejboring synchronous code. */
// 有足够的pending的客户端才会开启线程
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
/* Start threads if needed. */
//在这里才会开启io多线程,也就是说当有足够写的客户端才会开启
if (!server.io_threads_active) startThreadedIO();
if (tio_debug) printf("%d TOTAL WRITE pending clients\n", processed);
/* Distribute the clients across N different lists. */
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the
* start condition atomic var. */
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
/* Also use the main thread to process a slice of clients. */
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O WRITE All threads finshed\n");
/* Run the list of clients again to install the write handler where
* needed. */
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
/* Install the write handler if there are pending writes in some
* of the clients. */
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}
int stopThreadedIOIfNeeded(void) {
int pending = listLength(server.clients_pending_write);
/* Return ASAP if IO threads are disabled (single threaded mode). */
if (server.io_threads_num == 1) return 1;
//等待的客户端是io线程数两倍以上
if (pending < (server.io_threads_num*2)) {
if (server.io_threads_active) stopThreadedIO();
return 1;
} else {
return 0;
}
}
void startThreadedIO(void) {
if (tio_debug) {
printf("S"); fflush(stdout); }
if (tio_debug) printf("--- STARTING THREADED IO ---\n");
serverAssert(server.io_threads_active == 0);
for (int j = 1; j < server.io_threads_num; j++)
//这里释放锁才能然后io线程主流程继续循环起来
pthread_mutex_unlock(&io_threads_mutex[j]);
//状态的标示位
server.io_threads_active = 1;
}
以上代码几个要素,
1, io多线程不是一直处于活跃状态,当pending中的客户端比较少,即并发较少的时候,io多线程会从活跃状态进入休眠状态,而达到的目的就是通过mutex这个锁来实现。
2, 而一旦并发起来后超过了redis,设定的条件那么多线程io又会开启。
总结
以上代码大多数都是在network.c里面,可以看到io多线程主要还是跟网络的读和写挂钩(通俗的讲),具体的网络部分将会在另外一个章节单独去说,这一部分主要讲了io多线程是如何协同工作,其精彩的代码部分就是redis 如何用锁巧妙的唤醒和停止多线程的处理,以及一些状态上变更操作都值得我们好好去学习。
具体redis源代码地址:
https://github.com/redis/redis