走马观花AutoML
1 前言
在上一篇文章中,我们提到了几个算法深入方向,包括AutoML,模型解释。正好这两个话题之前也在公司有做过一些内部分享,接下来会逐渐整理成文,与大家探讨交流。这篇文章会主要以《Automated Machine Learning: Methods, Systems, Challenges》这本书为主要参考,结合一些其它论文,工具框架对这个领域进行介绍。
2 背景
我们先来看什么是AutoML。顾名思义,AutoML就是自动化的机器学习,我们先从机器学习中最常被自动化的一个任务,超参数优化来举例。比如我们在做人工调整超参数时,经常会采用以下的方法:
- 把模型的学习率参数设为0.01,训练模型,获取评估指标的得分,比如准确率为0.7。
- 把模型学习率设为0.1,训练模型,再次获取评估指标,比如下降到了0.65。
- 根据上述的观察结果,接下来我们可能尝试一个比0.01更小的值,以此类推。
从上面这几个步骤,我们不难看出我们在人工解决这个参数优化问题时,其实在不自觉中已经引入了一些优化方法。我们扩大了学习率参数,但发现准确率降低了,所以接下来我们会往相反的方向调整学习率来继续尝试,这是建立在准确率 = f(超参) 是一个平滑的凸函数的基础上,模拟梯度下降的做法来进行尝试。 所以如果只有这一个参数,这个自动化的过程还是挺容易建立的,比如应用经典的二分法。
在这个想法的基础上,我们可以把这个想法在各个维度上进行扩展:
- 实际的任务的超参个数比较多,而且往往会有相互影响,导致搜索空间很复杂。而且超参跟预测指标之间的关系,往往也不是理想的平滑凸函数。所以我们如何通过已有尝试,去选择下一个探索点,需要引入更复杂的方法。
- 除了预测指标外,我们往往还会有其它连带需要优化的目标,比如希望训练/预测的时间尽可能短,消耗的计算资源尽可能少,这就会变成一个多目标的优化问题。
- 人类专家在做算法调优时,不会每次都从头开始,而往往会考虑历史上碰到过的类似问题,把过去的经验带入到新问题中,最典型的比如选取之前有效的参数作为初始尝试点,使用之前表现好的模型来做fine-tune等。这背后是一个多任务优化问题,而我们收集的数据,也多了一个层面,就是任务本身的信息。
- 同样,我们在做调优时会有大量的时间在等待模型训练,但很多模型是可以在训练过程中输出验证集指标的,对于不靠谱的超参数,我们可能盯着训练过程一阵子之后就提前停止了。这个思想也可以融入到自动化优化过程中去,提升搜索效率。
- 超参数本身只是整个建模过程中的一个优化部分,其它的例如前期的数据获取,实验设计,建模过程中的数据处理,特征工程,特征选择,模型选择与设计,模型融合,包括后续的模型解释,误差分析,监控/异常检测等环节,也都有机会使用智能算法来自动化提效。
- 另外还有模型学习本身的自动优化,例如人类能从几张图片中就学会识别一个新物体,随着年龄经验的增长,学习掌握新知识的能力会逐渐增强。如何能让机器学习算法也拥有类似的自动化的“经验增长”能力,而不依靠使用者的经验积累,也是一个重要的话题。
下文中我们会详细介绍这些技术点上的各类技术和前沿探索成果。
3 超参数优化(HPO)
3.1 定义
超参数优化是最早利用自动化技术来进行机器学习的领域,目前在市面上看到的大多数AutoML系统与产品都还主要集中在这个方面。自动化的HPO技术对于降低机器学习的项目门槛,缓解数据科学人才短缺方面会有很大帮助。Gartner在之前的AI平台报告中也指出,对于专业数据科学家,AutoML能够提高他们的工作效率,减少在手动调参方面的时间投入。对于平民数据科学家,或者说更擅长业务领域知识的数据分析人员,AutoML能帮助他们快速应用机器学习的能力,不需要再掌握机器学习的复杂技术细节,就能达到业界数据科学家的平均水平。在此基础上,很多之前没有机会应用机器学习的项目也开始可能出现正向的ROI回报,推动各行各业的AI应用落地,而不只是集中在头部场景和high tech公司中。
现阶段自动HPO面临的挑战还很大,例如模型评估一般都非常消耗计算资源,导致参数搜索优化的运行需要大量的时间和资源成本。算法pipeline的参数空间非常复杂,超参数维度高,相互依赖,且搜索空间本身都需要一定的经验来进行设计。自动HPO技术中很多也基于机器学习方法,本身的稳定性,泛化能力也是一大难点。
前面一节中我们举的例子就是一个超参数优化问题,其正式的定义如下:

这里面超参数λ的类型会有很多种:
- 连续型,例如前面提到的learning rate
- 整数型,例如决策树的深度,CNN中的channel数
- 类别型,例如优化目标函数,神经网络中的激活函数等
在此基础上,还会有条件参数的概念。例如当优化器选择为Adam时,又会衍生出beta1,beta2,epsilon等参数。这种情况可以推广到模型选择加参数优化问题,例如选择哪个模型可以作为一个类别型超参数,而选择了这个模型之后,会有一系列的衍生条件参数需要联合搜索优化。这就是所谓的Combined Algorithm Selection and Hyperparameter Optimization(CASH)。而且这里的搜索和优化,也完全可以不局限在模型这块:
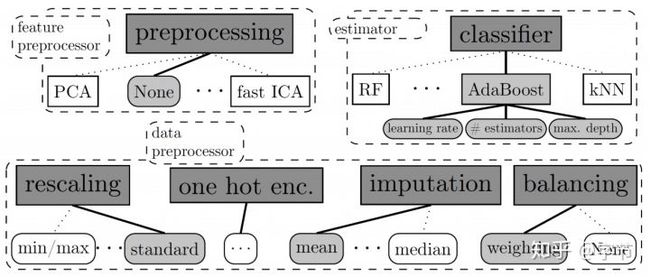
顺带一提像现在比较火的NAS,其实也可以把它的搜索空间转化为一个HPO的搜索空间,比如Google Brain的这篇18年的文章就有类似的方法:Zoph et al., 2018。
3.2 Model-free Optimization
大家一开始玩超参优化,最先接触到的就是这块的技术手段了,那就是大名鼎鼎的网格搜索和随机搜索!
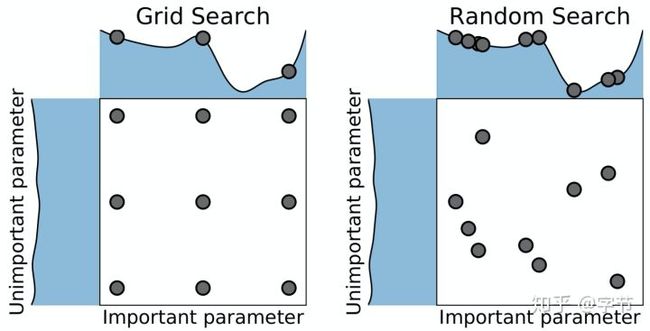
相信大家当年应该都用过sklearn里的GridSearchCV和RandomizedSearchCV吧。上面这张图对比了这两种搜索方法,体现出随机搜索的一个优势:在各个参数的变化对最终模型效果的影响度不一样时,随机搜索往往能在同样的尝试次数中探索各个参数更多不同的取值,进而取得更好的结果。另一方面,随机搜索的并行化实现也更加简单,如果有模型评估的任务跑挂了也不要紧,触发一个新的评估就可以。反之在网格搜索中,如果有任务挂了,就会导致网格中“空洞”的出现,需要进行重试处理。综上所述,在大多数情况下都会更推荐使用随机搜索来进行model-free optimization,且很多其它model-based optimization在初始化阶段也会使用随机搜索方法来探索起始点。
3.3 Population-base
还有一类启发式的群体算法也经常被应用在HPO问题中,例如遗传算法,粒子群算法等。他们一般的思想是维护一个参数组合的群体,评估他们的fitness function(这里就是模型评估的表现),然后使用个体选择,变异,及相互交叉的做法,不断衍生出下一代整体表现更好的群体。这些方法过程较为简单,有一定并行性,收敛性也不错。但从实际效果来看可能需要较大量级的模型评估才能达到比较好的结果。
这个类型中最著名的算法当属CMA-ES。其背后的思想是,根据群体中的优胜者们的分布,来更新均值和协方差,然后再进行下一轮的采样。当优胜者们距离比较远时,下一轮搜索采样的范围会扩大,而当优胜者们的分布比较集中时,下一轮的采样搜索范围会减小。这个算法的论文Hansen, 2016有些复杂,作者也维护了一个Python库来实现CMA-ES算法。有兴趣了解这方面信息的同学更推荐看这个blog。
值得一提的是在BBOB(Black-Box Optimization Benchmarking)挑战中,CMA-ES算法基本属于一个统治者的地位。
3.4 贝叶斯优化
终于到了大家熟知的贝叶斯优化了!回到我们之前尝试调优learning rate的例子,我们通过两次尝试得到的参数,评估效果分别是(0.01, 0.7)和(0.1, 0.65),这就可以构成HPO的输入数据集。在这个数据集上,我们可以构建一个模型,来预测我们选取别的learning rate时会达到什么样的模型准确率。接下来通过这个模型,我们希望能选出下一轮应该评估的learning rate是多少,后续就可以持续迭代起来。这就是贝叶斯优化的大致过程。
从上面的描述中,我们可以看出贝叶斯优化的两个核心组件:
- Surrogate model,我们希望能有一个模型学习到现在已知数据形成的分布情况,尤其是在已知点附近,我们对结果输出的信心会比较高,在没有被探索过的区域,我们对结果输出的分布会有很大的不确定性。
- Acquisition function,利用模型输出的预测值及不确定性,我们希望平衡探索未知区域与利用已知区域信息,选择接下来的探索点。直观点说就是一方面想看看我没有尝试过的区域情况会如何,另一方面也不是完全瞎找,要综合我们的已知信息,比如我们尝试过学习率大于1的那些区域明显效果都比较差,应该在效果较好的0.01附近找更有可能的点。
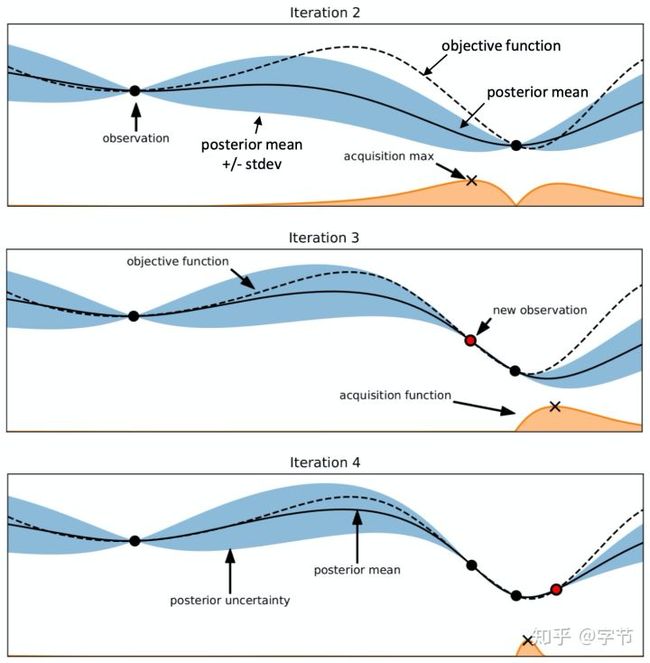
经典的贝叶斯优化示意图,通过高斯过程来拟合已有的observation,然后使用acquisition function来找到下一个评估点。
Surrogate model方面,最常见的选择是高斯过程。例如BayesianOptimization库中就使用了sklearn中的GaussianProcessRegressor:
# Internal GP regressor
self._gp = GaussianProcessRegressor(
kernel=Matern(nu=2.5),
alpha=1e-6,
normalize_y=True,
n_restarts_optimizer=5,
random_state=self._random_state,
)高斯过程本身又是一个大话题,有一篇非常好的tutorial可以参考。对于高斯过程,kernel的先验选择非常关键,例如应用到超参数优化中,这个kernel应该能输出符合我们预期的不那么平滑的sample function,因而Matern kernel成为了高斯过程应用在HPO中的一个常见选择,而且大多用的都是Matern 5/2。具体可以参考这篇Snoek et al., 2012,以及GPflow中对kernel的一些实验讲解,可以看到不同的Matern kernel的参数选择也会导致sample结果不一样的平滑度表现。
在有了可以输出后验分布的模型后,再结合acquisition function来进行建议评估点的获取:
suggestion = acq_max(
ac=utility_function.utility,
gp=self._gp,
y_max=self._space.target.max(),
bounds=self._space.bounds,
random_state=self._random_state
)最常见的acquisition function有3种,分别是:
- EI(expected improvement)
- UCB(upper confidence bound)
- ES(entropy search)
以EI为例,其大致的代码形式如下:
def _ei(x, gp, y_max, xi):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
mean, std = gp.predict(x, return_std=True)
a = (mean - y_max - xi)
z = a / std
return a * norm.cdf(z) + std * norm.pdf(z)在这篇知乎文章中,作者对这三种function做了非常详细的解释。上述代码跟文中的公式有一些小小的区别,就是多了一个参数xi,这个参数可以用来控制Exploitation和Exploration的trade-off,具体效果可以参考这个notebook。总体上看EI在各类常规贝叶斯优化中使用最多。UCB的概念和计算更加简单,而且从一些实验结果来看基本可以达到跟EI同样的效果。ES相对来说计算复杂度会高很多,但个人感觉这个形式在信息的exploration方面的能力应该是最强的,尤其在一些多任务设定的优化问题中会经常见到。
上面就是贝叶斯优化的主要流程,先用高斯过程拟合已知数据,再用一些策略(acquisition function)来根据模型选取下一步要评估的超参数。这里也贴一篇很好的tutorial来更详细的解释贝叶斯优化背后的机理。
3.4.1 GP和kernel的改进
在实际应用中,surrogate model这块会有很多挑战,例如高斯过程本身有一系列的限制和问题:
- 模型overhead:GP的fit过程的复杂度是$O(n^3)$,predict的复杂度是$O(n^2)$,当搜索的量级较大时,模型的overhead会较为明显。
- Kernal scalability:GP的标准kernel在高维空间中的很容易失效,除非把评估数量也以指数级增加,但这明显是不可行的。
- 参数限制:标准的GP只能处理连续型参数,如果是整数型,类别型,需要做额外的处理。
为了缓解这些问题,从模型和kernel两个方面,研究者们提出了各种替代和改进方案。
沿着使用GP的路线,在模型方面一个思路是改进GP本身的性能,比如使用sparse GP来做近似:Hutter, Frank, et al., 2010。而Wang, Ziyu, et al., 2016中提出了一种random embedding的方法,把高维参数随机投射到低维空间中。其背后的主要假设是参数的effective space是相对比较小的。
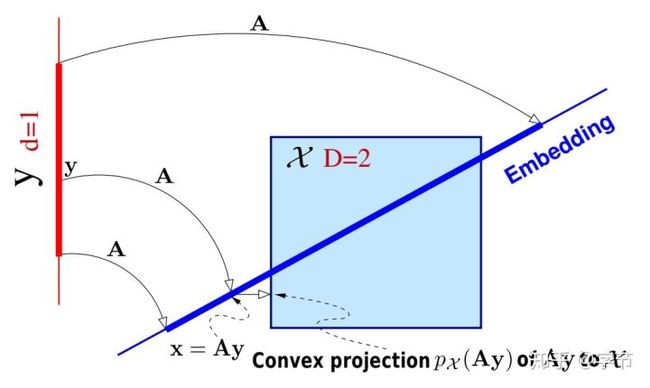
在Wang, Zi, et al., 2018中,则采用了把input space做分割,在多个子空间中运行GP算法,最后再进行整合。想法听起来挺直观,不过实现细节上还是蛮复杂的,涉及到如何分割input space,使用Gibbs sampling训练TileGP等。
还有在Lu, Xiaoyu, et al., 2018中,作者使用VAE来转换参数的input,然后后续就可以使用常规的GP来进行贝叶斯优化,本质上也是一种降维的思路。
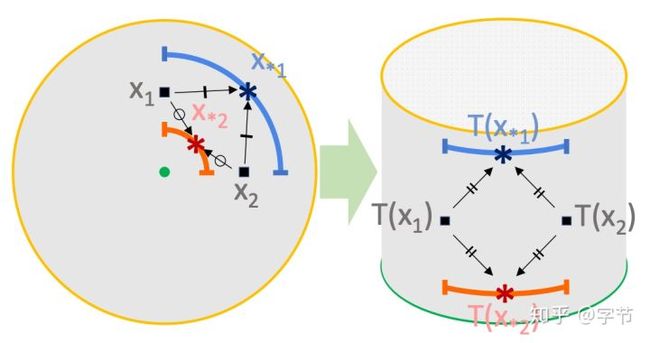
也有不少对kernel做改进的工作,例如Oh, ChangYong, et al., 2018使用cylindrical kernels把球形空间投射到了圆柱体空间中,使得球心附近包含的空间与球壳附近包含的空间基本等价,而不是原本的在维度较高情况下,大多数的搜索空间都集中在球壳附近。其背后的假设是一般较好的参数candidate应该在球心附近分布更多。其它还有比如Gardner, Jacob, et al., 2017等additive kernels方法。
3.4.2 其它surrogate model
另外一个方向的思路是使用其它模型来替代GP。
例如利用神经网络来充当surrogate model,Springenberg et al., 2016中采用的是贝叶斯神经网络,通过SGHMC(
@陈天奇
大佬的工作)来sample from network获取mean and variance,进而计算acquisition function。还可以计算出EI相对于x的gradient,进行优化求解。这个方法在RoBO中有具体实现。事实上BNN也有多种采样方法,这里为什么用SGHMC,也是通过一系列的实验尝试得出的:
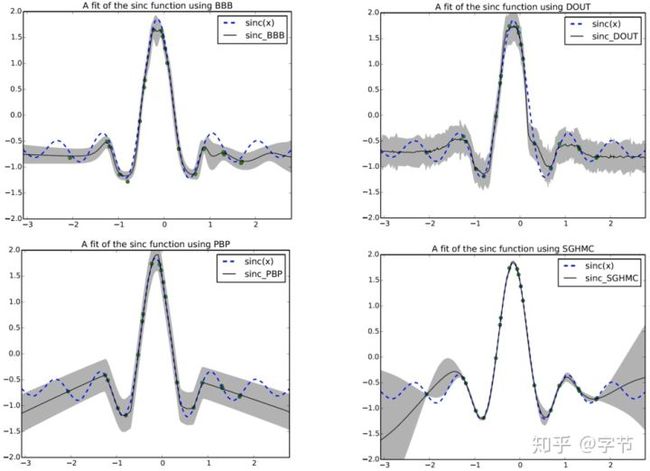
可以看出SGHMC给出的置信区间更符合超参搜索优化的直觉,与GP的效果很接近。
也有使用Factorized MLP的做法,参考Schilling et al., 2015。这里需要解决预测能够输出时的uncertainty的问题。通过对模型参数引入贝叶斯假设,最终可以通过hessian of loss on D以及gradient on x来计算出预测性的后验分布。
神经网络模型目前总体在较低维度和连续型变量任务上表现非常不错,在高维度和复杂参数空间问题中还没有很有力的实验验证支持。所以相对于GP来说,神经网络主要在模型overhead方面会有提升帮助,在实际工程应用中还不多见。
除了神经网络,还有不少工作采用了树模型。例如SMAC3,auto-sklearn中都有使用随机森林作为surrogate model。随机森林的处理特征能力更广泛,可以天然处理包括类别变量,conditional变量等。且RF模型的fit,predict复杂度在O(nlogn),明显比GP扩展性更好。对于输出uncertainty的需求,可以通过多棵树的结果来计算mean, variance。
另外比较常见的树模型选择是TPE: Bergstra et al., 2011,大致的思路是选取一个阈值,把尝试过的参数结果分成两块,好的参数集以及不好的参数集。接下来对这两个集合拟合两个分布(GMM),l(x)表示低于阈值(效果好的参数)的分布的density function,g(x)反之。然后根据EI的计算公式,选取l(x)/g(x)最大的x作为下一个评估点。这背后的想法也非常简单,就是希望接下来评估的点在效果好的参数集中的概率要比效果差的参数集中的概率越大越好。在hyperopt中,就主要使用TPE方法来做贝叶斯优化。
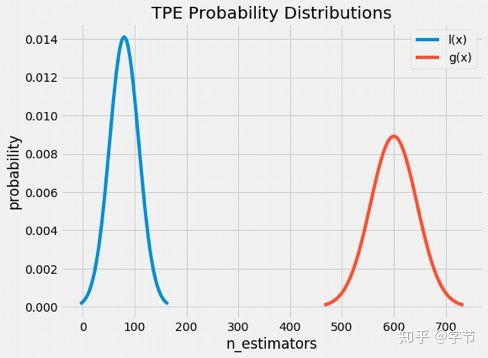
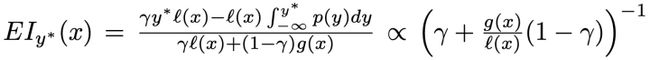
树模型相比GP的主要劣势是sample efficiency会略差一些,但是性能,稳定性,处理复杂参数空间等方面都有很大的优势。整体的实现也相对简单,所以实际应用也比较广泛。
另外书中还提到了deterministic RBF:Ilievski et al., 2016,compressed sensing:Hazan et al., 2017等方法,感觉比较小众,没有深入进行了解。
3.5 参数空间
前面有提到过在优化超参时,会有多种类型的参数,而在贝叶斯优化过程中,默认设计是对有范围限制的连续型参数进行搜索。因此对于不同的参数,我们需要进行不同的处理(Garrido-Merchán et al., 2018):
- 整数型参数,例如随机森林中树的数量,需要在优化过程中把连续变量round到整数形式。
- 类别型参数,可以使用one-hot等预处理方式。
- 条件参数,在RF这类surrogate model中,对在某些条件下不活跃的参数,可以用一个默认值代替,活跃的参数则正常输入。另外在Jenatton et al., 2017等工作中,为structured configuration spaces设计了各种特殊的kernels。
还有一系列参数搜索空间方面的问题。例如learning rate的search space是log space,也就是说learning rate从0.001变为0.01带来的变化,跟0.1到1带来的变化应该是类似的。所以也有一些研究希望能够自动探索出不同参数的搜索空间,例如Snoek et al., 2014中提出的input warping方法,通过将每个输入维度替换为Beta分布的两个参数并对其进行优化,可以在过程中自动学习此类转换。
另外一个限制是大多数优化问题都需要预先定义好搜索范围,如果最优解并不在这个范围内就会导致搜索优化的结果不理想。前面提到的TPE天然可以处理无限的搜索空间。另外也有各种动态扩展搜索空间的方法,例如Nguyen et al., 2018中,作者在优化过程中通过invasion set来考虑是否对当前的搜索空间进行扩充。而在Shahriari et al., 2016中,作者利用regularization替代掉了范围的限制。背后的intuition是对于距离当前最优点越远的空间中,必须有更大的EI才会被选中来进行评估。
3.6 带约束的优化
在现实中使用贝叶斯优化往往都会带入一些其它的限制条件,例如计算资源的使用,训练和预测所需要花费的时间,模型的精确度等等,包括很多AutoML challenge也在这方面设定了很严格的要求。一些简单的处理办法比如对于违反了约束的observation做penalty,例如虽然这个参数组合的模型效果不错,但因为运行超时了,我们会直接把它设置为效果最差的评估结果。更细致一些的做法例如Gelbart et al., 2014中,作者对违反一个或多个约束的可能性进行建模,在优化过程中搜索模型效果好且不太可能违反任何给定约束的参数。在Hernández-Lobato et al., 2016中,作者更是提出了一个通用的framework。一方面对于task与resource之间的关系,构建了一个二分图,并在后续优化过程中进行使用。另一方面,他们扩展了使用信息学理论的acquisition function Entropy Search,提出了Predictive Entropy Search with Constraints,可以很好的解耦objective和constraint的评估,从而很好的解决此类带约束的优化问题。
3.7 Multi-fidelity Optimization
前面介绍的model free,population based和model based一系列方法都是黑盒优化的思路。在前面背景介绍我们有提到过,人类专家在做超参数优化过程中,并不是完全把模型评估作为一个黑盒来看待,而是会采用观察学习曲线,使用少量数据等方式来对学习效果进行快速判断。沿着这个思路,我们可以得出此类multi-fidelity优化的几个方向,基于学习曲线的预测的early stopping,bandit based算法,以及更进一步的adaptive fidelities方法。
3.7.1 Multi-fidelity设定
除了前面讲到的学习曲线的观察,我们也可以采用其它的方法来形成不同fidelity下的observation,例如采用部分数据或特征进行训练,或者利用与当前数据集类似(相似度就可以做为fidelity的评估)的其它任务上的训练结果,具体到一些场景中,比如图像问题,可以尝试用低分辨率的图像来训练,而强化学习中可以减少trial的次数等。总结一下,主要就是3个维度,训练的时间,数据集的大小,以及相似任务的迁移。
3.7.2 Learning Curve-Based Prediction
看这个名字就基本能猜到这个方法了,实际上就是模拟我们人工来观察各类iterative学习算法的learning curve(一般用验证集上的评估结果),然后判断目前尝试的超参是不是一个靠谱的取值。如果明显没有向上提升的趋势,我们就可以选择提前终止训练。
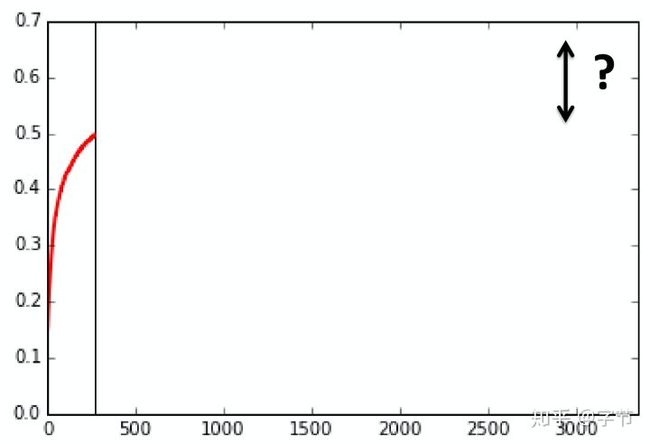
如何用模型来替代人工的判断呢?毕竟从几个epoch的曲线来判断长时间训练能达到的效果,还是挺有难度的。在Domhan et al., 2015中,作者选取了11个参数方程,这些方程的曲线都跟典型的learning curve长得比较像:
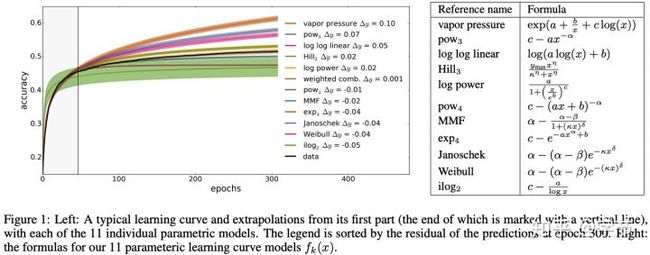
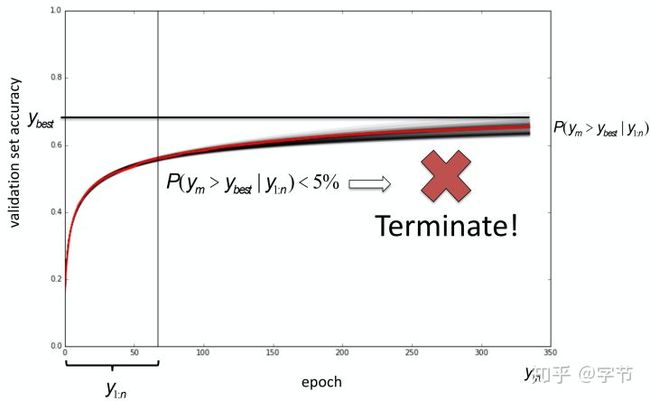
这11个参数方程的参数,以及它们的权重,会通过MCMC方法来拟合已知learning curve部分来得到。这样后续就可以输出当前的这个learning curve在未来能够达到的准确率的分布情况。然后我们就可以判断是否要继续进行训练了。这个方法可以跟贝叶斯优化结合起来一起使用,比如前面通过贝叶斯优化得到的当前最好的准确率是y_best,我们可以判断当前参数的训练结果是否能以超过5%的概率超过y_best,来决定是否提前终止。
这篇文章还提供了开源代码实现,automl.org的不少工作都是既有文章又有代码,非常贴心!
类似的工作还有Klein et al., 2017,他们在模型方面用BNN替代了之前的11个basis function,由于使用了表达能力更强的模型,不光可以输入已知的learning curve信息,连带还可以输入具体的超参数config信息。例如之前learning rate设置到10呈现出来的learning curve,换到另一个数据集上也可能会长得很像。此外还有Swersky et al., 2014提出的Freeze-Thaw,把learning curve的评估与选择与贝叶斯优化做了更深入的结合,不是预测是否停止训练,而是对多个learning curve做高斯过程拟合,通过entropy search来决定选取哪个继续训练。
3.7.3 Bandit-Based Selection
Multi-fidelity优化的问题与bandit算法也有着非常自然的联系,随着模型训练轮次的提升,我们对于当前参数设置的预期产出会越来越有确定性,所以我们也可以利用各类bandit算法来最大化我们优化过程中的预期产出。这方面目前在实际工作中应用比较多的是Jamieson and Talwalkar, 2016提出的successive having方法。
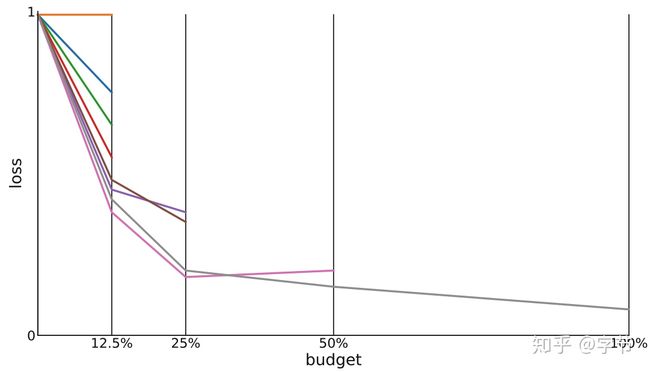
这个方法非常的简单有效,就是根据初始的budget,例如我们有8个小时的训练时间(只考虑时间并不是很严谨,只是举例),在第1小时中,把所有参数组合都进行训练,然后到结束时,我们把表现排名靠后的50%参数组合丢弃,选取剩下的继续训练,到了下1一个小时结束,再次评估并丢弃表现不好的组合,这样一直持续到budget用完。原作者用这个简单的方法跟其它比较常见的bandit算法例如UCB,EXP3等进行了比较,发现SH算法无论在迭代次数还是计算资源需求方面都有着更好的表现。在一些automl challenge中,不少获胜方案就采用了这个算法。
SH算法有一个需要权衡的问题在于评估的参数组合的数量。如果尝试的参数组合数量多,那么每个参数组合分配到的计算budget就相应会比较少,容易让一些后续表现好的参数被提前终止尝试。如果尝试的参数组合少,那么计算budget会比较宽裕,但是可能会导致更多的计算资源被浪费在了表现不好的参数组合上。所以Li et al., 2018提出了改进的Hyperband方法。主要的想法就是把budget分为多个组,在每个组里设置不同的参数评估数来运行SH算法,可以在SH的基础上进一步提升总体的搜索优化效果。
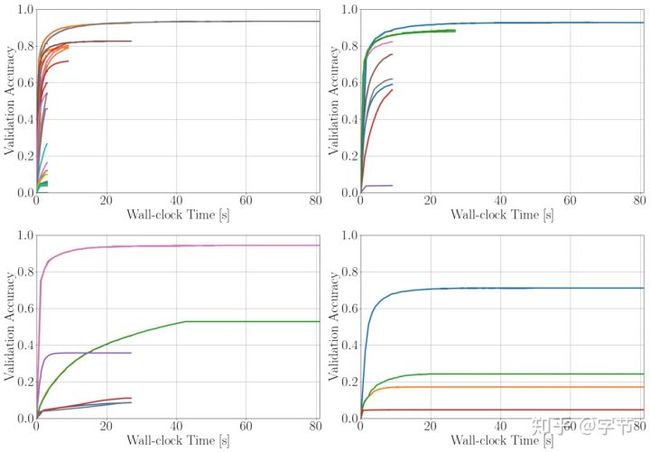
如上图中就是分了四组不同的评估数量来分别执行SH。
不过这类bandit算法有一个明显的缺陷,就是对于评估参数的具体选择上,并没有利用历史上的observations。所以有一个很自然的想法就是把Hyperband跟贝叶斯优化两者的优点结合起来:
Hyperband: 在observation较少的情况下,能够利用low fidelities的评估进行快速过滤,确保起始时选择的参数一定程度上能比随机选择有更好的总体表现。
BO: 使用贝叶斯优化替代Hyperband中的随机搜索,确保长时间优化运行的最终结果会更好。
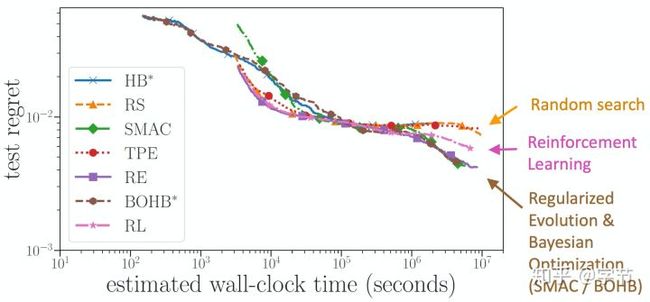
于是BOHB就这样诞生了!整体的结合方法也非常自然,可以参考这里的代码实现。从实验结果上来看,效果非常好:
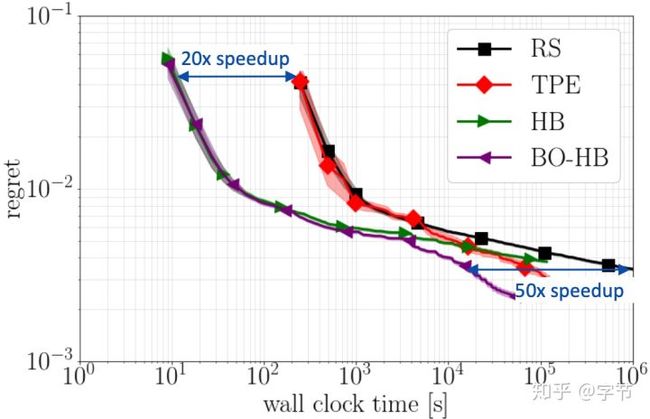
相比随机搜索,单独使用贝叶斯优化或Hyperband来说,在优化过程中的任意时间点,BOHB都得到了更优的结果。
还有一些其它的multi-fidelity优化思路,例如Wang et al., 2015中,作者提出了在较小数据集(low fidelity)中进行优化搜索,然后再作为更大数据集中优化搜索的初始点的想法。另外在Zeng et al., 2017中,也是类似的思路,只不过他们是从low fidelity的搜索结果中找出表现差的算法或者参数组合,在后续的搜索优化的参数空间中进行移除。
3.7.4 Adaptive Fidelities
前面描述的包括learning curve prediction和bandit based方法,都是基于一个预先定义好的fidelity增长过程,比如逐渐增加的训练轮次,或者逐渐增加数据集的subset size等。后续有不少研究方向希望能够在整个优化过程中自适应的去选择不同的fidelity进行评估。
一个较早的工作是Swersky et al., 2013提出的Multi-Task BO。他们提出了一个多任务的设定,可以利用相似的,但是训练评估代价更低的一些任务作为low fidelity tasks,与评估代价较高的优化目标task一起来做优化。利用multi-task GP,可以学习到这些任务之间的相关性,然后使用考虑了evaluation cost的entropy search作为acquisition function,来自动选择“性价比”更高的task进行评估。这个设定还可以利用之前已经做过的任务来做“经验”的transfer,感觉想法非常不错。
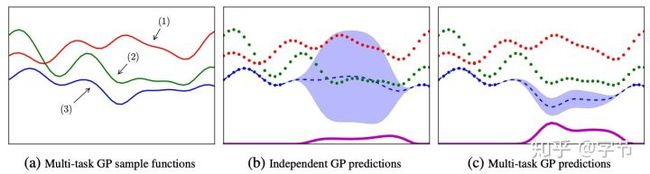
多任务高斯过程的示意,在利用到任务相似度时,蓝色这个main task能够学习到与它更相似的绿色task的表现,给出更合理的后验分布。
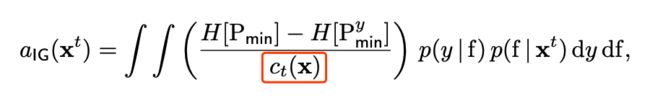
Acquisition function使用的是改进的ES,红框中的这个c(x)就是task的cost,这个值无法预先得知,作者提出也可以用GP来建模预测。
另外对于多task,文中也提出了2种构建利用方式,一是fast cross-validation,例如对于5-fold CV,在所有fold上评估就是一个high fidelity的任务,而只评估一个fold,就是相应的low fidelity任务。另一种是使用更少的数据来训练,比如取训练集的四分之一形成一个low fidelity任务。也可以找相似的任务,比如文中的几个实验就是拿SVHN作为CIFAR-10的相似任务,还有USPS作为MNIST数据集的相似任务等。从整体的结果上来看基本能在执行超参优化时节省大约一半的时间。
在Multi-Task BO中,fidelity作为多个不同任务的属性是一个离散变量,需要预先定义,一方面引入了fidelity定义不够好的风险,另一方面fidelity的取值数量也会相对比较有限。所以后续很多工作在fidelity的粒度定义上进行了改进。例如Klein et al., 2017的这篇FABOLAS(取名上也很努力呢)中,用连续的dataset size替代了离散的不同task。在具体做法上面,他们在之前的模型评估函数f(x)中加入了dataset size的变量,变成了f(x, s),另外也跟MTBO一样,加入了评估cost的函数c(x, s)。在优化过程中,会分别对这两个函数做高斯过程的拟合,同时在做参数评估时,也会同时输出模型性能和时间开销。最后在kernel方面,在Matern 5/2的基础上,分别为模型评估函数和cost评估函数加入了不同basis的covariance function。这篇文章也给出了代码实现,可以参考这里。
从实验效果来看,FABOLAS整体加速效果比MTBO要好上不少。

从图中使用SVM在MNIST数据集上做训练的例子中可以看出,在使用少量数据到使用全量数据,不同模型参数得出的模型效果分布基本是一致的。
前面的几个工作都是基于信息论的acquisition function(entropy search)的基础上做的拓展,也有一些工作在UCB的基础上做改进,如Kandasamy et al., 2016提出的MF-GP-UCB。而在Kandasamy et al., 2017提出的BOCA中,对于fidelity领域的建模更进了一步。他们把优化的空间分成了X space(即原先的参数搜索优化),和Z space(fidelity space)两部分,分别进行建模优化。由此带来的另一个好处是Z space中的fidelity的维度也像X space一样可以进行扩展,例如同时考虑dataset size和训练轮次两个变量的fidelity设定。
最后总结一下Multi-Fidelity优化的思路,总体上来说就是把之前简单的评估f(x)扩展到了更多fidelity的维度f(x, z)。而在这个z空间中,又可以引入dataset size,learning time step,other datasets几个维度的考量。不过adaptive fidelity的问题在于z空间引入的额外维度可能也比较大,会进一步凸显GP的性能问题,以及高维度情况下优化的难度。所以目前业界应用比较广的还是BOHB这类比较简单的Multi-Fidelity方法。
3.8 Ensemble
前面的HPO方法大多关注于选择出一个效果最好的参数组合,但是HPO过程中选择出来的表现较好的那些参数组合,也可以使用ensemble来获取进一步性能提升并最大程度利用搜索优化所花费的成本。除了简单的事后ensemble,也有一些工作把ensemble的思想融入到贝叶斯优化过程中去。例如Lévesque et al., 2016中,作者直接把BO的优化目标改成了寻找能够提升现有ensemble效果最多的参数组合。
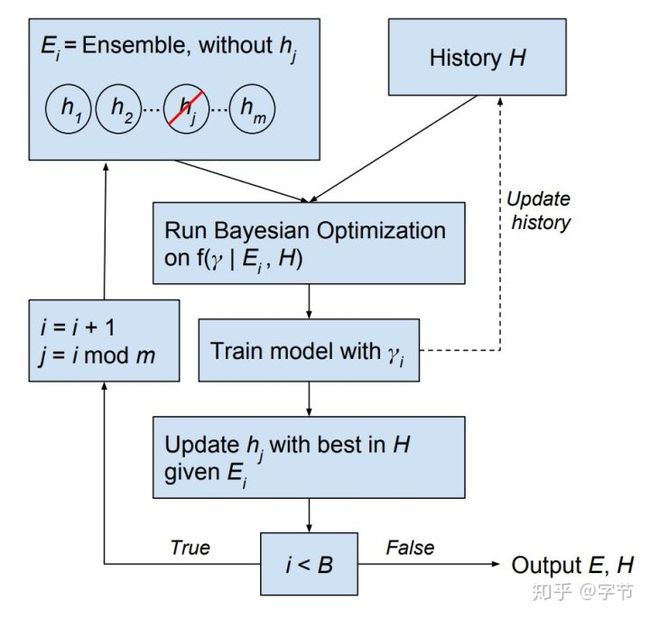
另外也有反过来,把HPO的想法应用到模型融合中去,例如在Wistuba et al., 2017中,作者先使用HPO来训练一系列base model,再进一步使用HPO来训练stacking模型,便于更好的融合提升。
3.9 多目标优化
前面有提到过对于带限制条件的优化问题的解决思路,对于更加广义的多目标优化问题,也有一些研究工作。例如以Horn et al., 2016,Shah et al., 2016为代表的一系列Pareto Frontier Learning工作。
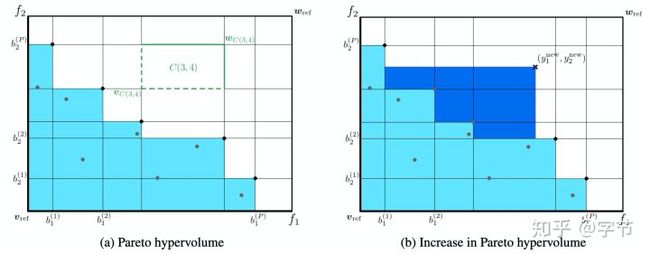
3.10 实际应用
HPO目前应该是AutoML领域应用最多的一个场景了,前面提到了很多方法,包括随机搜索,贝叶斯优化,CASH,Multi-Fidelity优化等。在实际应用中如何选择这些方法呢?这里给出一个大致的guideline:
- 当可以应用Multi-Fidelity来做模型评估时,选择BOHB,这是目前综合表现最好且效率最高的方法。
- 当无法应用Multi-Fidelity时:
- 连续型的参数组合,模型评估开销较大:使用基于GP的贝叶斯优化。
- 维度较高,且较为复杂的参数空间:使用基于随机森林或者TPE的SMAC方法。
- 连续型的参数空间,且模型评估开销低:使用CMA-ES方法。
3.11 开放问题
HPO方面目前还有很多开放问题亟待探索和解决:
- Benchmark方面还没有比较好的标准,从这么多论文来看大家用的评估方法都不太一致,通常也不会使用独立的测试集,带有代码实现的文章也不多,导致比较难判断到底哪个方法才是目前的SoTA。
- 灰盒优化方面的工作可以进一步深入,前面提到的Multi-Fidelity优化是一个方向,其它包括现在比较火的gradient based model如何更好的做HPO也有进一步探索提升的空间。另外config本身也有往动态化配置优化的趋势。
- Scalability,一方面来说,模型训练开销导致很多大型问题例如ImageNet的参数调优还比较难使用HPO里的各种技术。另一方面在目前大规模分布式集群算力日渐提升的情况下,如何利用这些算力做分布式的HPO,与MLSys相关研究结合,也是一个值得思考的方向。
- 泛化能力,由于需要在训练数据集上做多次训练和评估来进行参数调优,HPO算法比较容易在训练数据上过拟合,本身的泛化能力会更加受制于数据量或数据使用方式上的问题。有一些简单的方法例如在每次做模型评估时更换shuffle可以一定程度上缓解这个问题。也有一些研究例如Shilton et al., 2019也提出需要寻找stable optima而不是sharp optima的想法。另外在ensemble方面,应该也有不少挖掘空间。
- 整体pipeline的构建,目前HPO的应用大多数还是集中在单纯的模型参数优化方面,而对于整个pipeline空间的搜索与构建还没有比较有效的方法可以超过固定pipeline优化的效果。TPOT以及后续会提到的ML-Plan有做过一些这方面的尝试,不过整体可以提升的空间还很大。
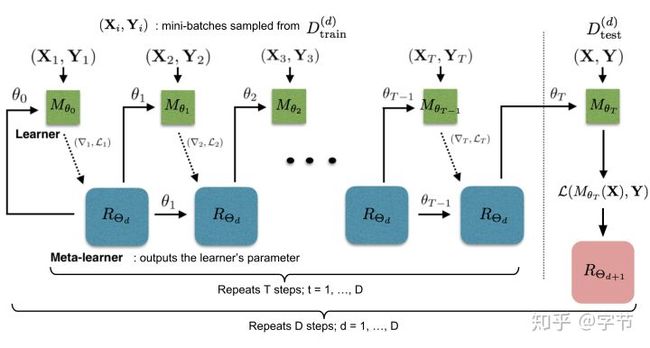
4 Meta Learning
人类学习新技能的时候,很少会从头开始,而是会借鉴之前类似任务的经验,重用一些技能手段,快速识别出新任务中的关键点进行快速学习。而目前的各种学习算法在这方面则普遍较弱,例如小孩子在看过一两次猫和狗的图片之后就能进行区分,而大多机器学习算法需要大量的训练数据才能完成类似的任务。虽然有迁移学习之类的想法,但在什么场景下使用,如何进行fine-tune等,都还是基于人工的经验来进行。理论上,我们也可以把这种从过去的经验进行学习的任务,使用系统化和数据驱动的手段来进行自动化。这就是元学习(Meta Learning)希望解决的问题。
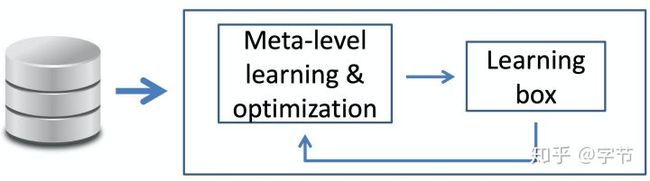
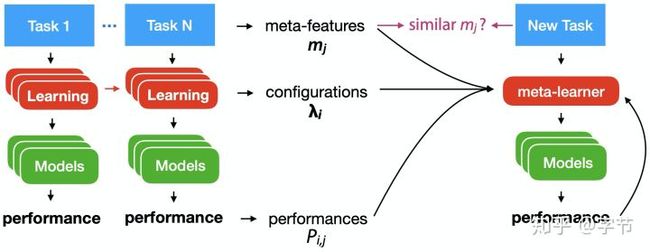
元学习的大致框架如下图所示:
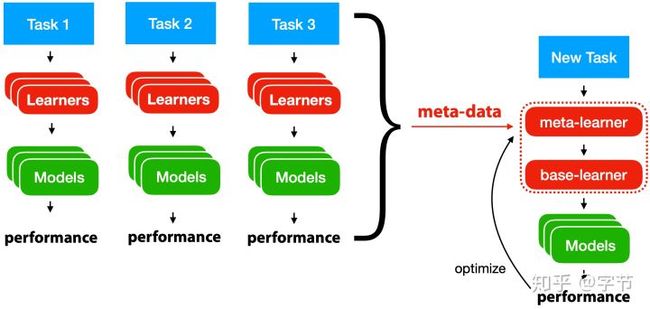
元学习的框架与机器学习比较接近。图中蓝色的task,指的就是机器学习任务,我们会从训练数据中,通过学习算法(learners)来构建出一个可以执行这个任务的函数f(models)。而元学习,则是通过过去的这一系列task,及他们的训练过程形成的各类元数据的基础上,去学习出一个能够自动构建出学习算法(右边的base-learner)的学习算法(meta-learner)。后续有了新task,我们就可以使用这个meta-learner来生成一个base-learner,省去了人工构建学习算法的过程,且能够更好更快的进行新task的学习。
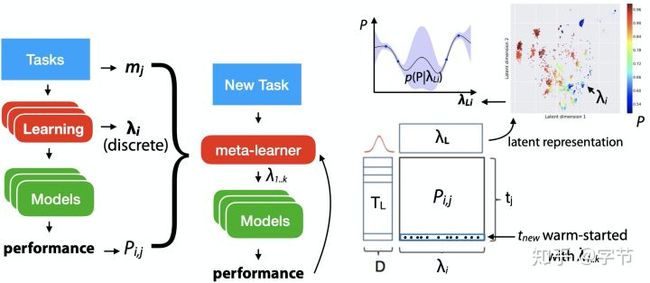
这里的元数据,包括过去任务的属性(meta-features),过去任务使用的算法的配置和参数,所得到的模型属性(如模型参数等),以及评估效果。元学习器的任务,就是需要从这些元数据中进行学习,产出特定的学习算法。跟机器学习一样,元学习器也需要通过特定的评估方式来判断效果好坏,并依据这个评判标准来不断迭代改进。后续我们看到很多few-shot learning中的例子就会对多任务元学习器的评估有一个直观的感受。
总体来说meta learning的方法随着任务之间相似度的提升,大致分3类:
- 对于通常效果较好的知识进行迁移,主要是模型配置方面的迁移。
- 跨任务的模型效果的评估,会引入task的meta feature来进行学习。
- 从类似任务构建的模型开始训练,例如很多few-shot learning里会用元学习器来设定初始化参数。
接下来我们会分别详细展开说明。
4.1 从模型评估中学习
4.1.1 任务无关的配置推荐
我们先不考虑任务的特性,直接从历史任务的模型评估中,去学习总体上表现较好的模型配置(包括算法选择,pipeline结构,网络结构,超参数等)。通常的做法是在一个数据集(任务)上运行各种模型配置,获取到评估指标,形成我们的元数据。鉴于在不同任务上,即使是相同的模型配置都可能产出非常不同的评估结果,为了便于后续的比较选择,我们一般会把绝对的评估指标转换成相对的ranking排序。然后在多个数据集上,都用类似的过程来进行构建,就能形成一个多任务,多配置的ranking矩阵。后续在选择模型配置时,我们可以选择整体表现较好的top-K个配置,作为后续优化任务的初始化集合,就能达到快速学习的效果。典型的工作例如这篇Xu et al., 2010。
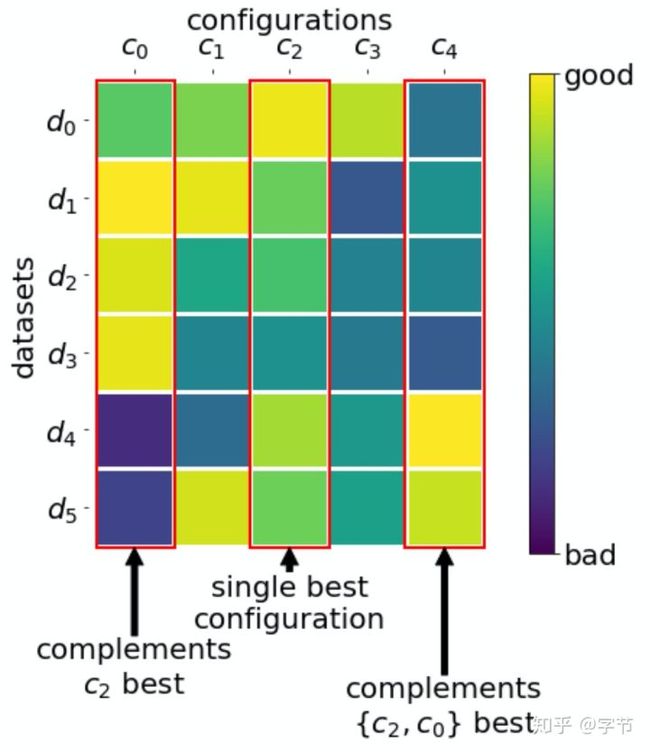
对于构建这个矩阵所选择的任务集合,很多研究者都会考虑采用OpenML上的公开数据集。而对于这个矩阵的构建过程和考虑因素,里面也有很多细节。例如Brazdil et al., 2003中提到,不但考虑模型评估的效果,还会考虑训练所花费的时间等。
4.1.2 配置空间设计
我们也可以根据历史模型评估,来学习更好的配置空间设计。一个直观的例子就是我们在做学习率参数的调优时,一般不会考虑大于1的参数设置,另外像有些参数在大多数情况下使用默认的就好,也可以直接在配置空间的设计中固定下来。在这篇Van Rijn et al., 2018中,作者使用functional ANOVA技术来评判在各个配置选项中,哪些配置最能够解释模型效果的variance,这些配置就会被作为重要的选项在配置空间中进行重点调优。
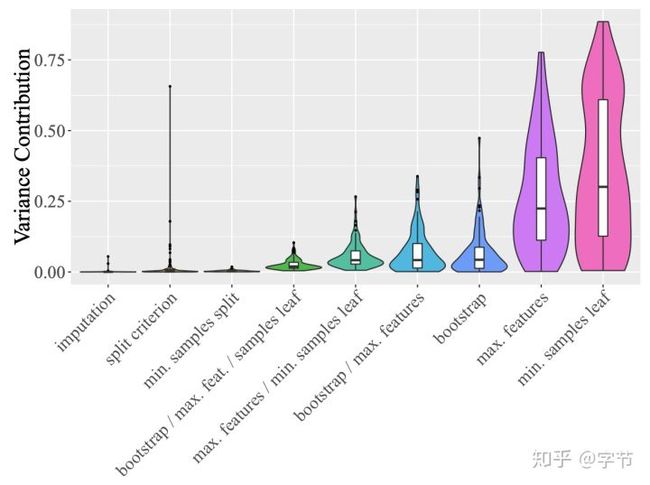
从图中随机森林参数尝试的这个例子中可以看出,对最终模型影响最大的两个特征是min samples leaf和max features,所以需要重点调整。
在Probst et al., 2018中,作者收集了调优特定参数与使用默认值相比,能获取的performance gain的元数据,然后建立了surrogate model来评估哪些参数调优能够获取更多的收益,也可以用以指导配置空间的设计。这篇文章有对应R代码开源实现。
最后,在Weerts et al., 2020中,作者通过寻找各个task的top-k配置中,最频繁出现的那些非默认参数选项,来确定哪些是最需要调整的参数。
4.1.3 配置迁移
前面提到的两种方法都没有考虑task之间的相关性。一个自然的想法是在全局推荐的基础上,再引入task之间的相似性信息,以更好的进行过往经验的利用和配置参数迁移。
在Leite et al., 2012中,作者通过relative landmarks的方式来评估task之间的相似性。这个landmark实际就是使用特定模型及参数配置得到的评估值,然后在两个不同task上用相同的模型配置来评估,计算差距就能得出这两个task的相似度了。具体到配置迁移上,他们提出先使用整体效果最好的几组参数(通过前面task无关的方法得出),然后根据task相似度来选择最有可能获胜的config进行评估,拿到结果后更新task相似度,再重复上面的流程。这个做法跟active testing的想法非常类似。
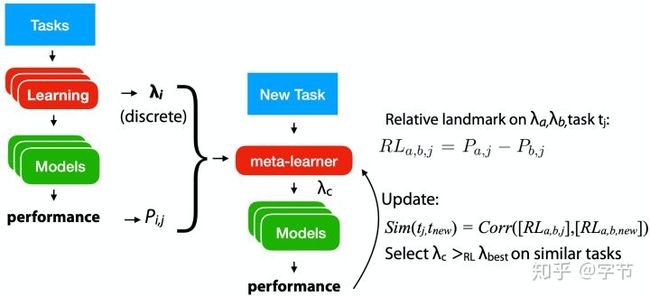
另外一个比较自然的想法跟贝叶斯优化类似,使用surrogate model结合acquisition function来选择下一个评估参数。这里主要的挑战在于引入多任务之间的相似性。Wistuba et al., 2018使用的方法是对每个task都做一个GP拟合,迁移到新task时通过relative landmarks的方式评估任务之间的相似度,形成加权系数,再把各个GP的预测输出加权求和起来作为最后的输出。Feurer et al., 2018中也是类似的思路,提出了一个ranking-weighted Gaussian process ensemble,也是对多个GP model进行融合。融合系数使用的是该GP模型在new task中拥有最低ranking loss的概率,换而言之就是表现越好,weight就越高。
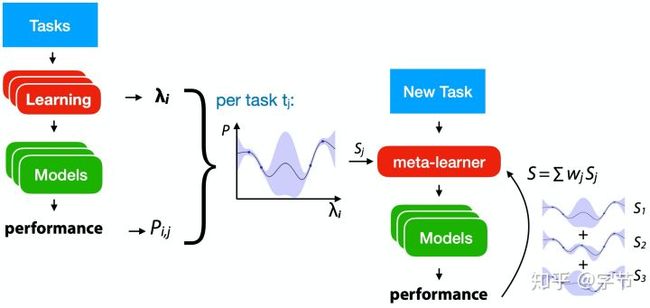
不难看出之前HPO中用到的multi-task BO理论上也可以应用在这个场景中,但有一个问题是联合训练多任务GP的可扩展性有点差。Perrone et al., 2017提出了一个很新颖的想法,利用NN+BLR来训练过去的task,NN部分是共享的,能够学习到task representation,而NN的输出会作为BLR的参数,在各个task上拟合不同的BLR去预测模型效果。这个方法能显著提升surrogate model的scalability,对于过去的observation来说复杂度是线性的。
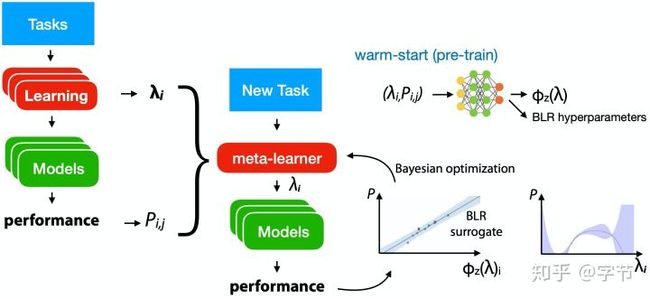
值得一提的是Google Vizier(Golovin et al., 2017)里也使用了multi-task的配置迁移方法。具体做法上他们假设任务是有先后顺序的,对于一个序列的任务,他们构建了一个GP stack,每个GP会建立在上一层GP的residual上。这个做法感觉有个假设是这一系列任务应该都是比较相似的才可以。
另外还有些其它的方案,例如之前有提到过的bandit based方法也可以应用在这里(Ramachandran et al., 2018)。前面提过的learning curve相关的预测,不但可以用在early stopping,也可以用在这里配置迁移推荐上(van Rijn et al., 2015)。最后从配置迁移的反面考虑,Wistuba et al., 2015提出了用类似task中提升可能性最小的参数区域来做搜索空间的剪枝。值得一提的是这篇文章在计算task的相关度时没有使用欧氏距离,而采用了Kendall tau rank correlation距离函数,值得参考学习。
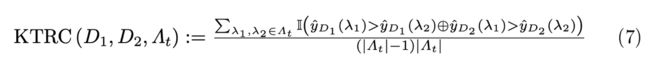
4.2 从任务属性中学习
在前面配置迁移的各类方法中,我们已经看到了relative landmarks这类对任务属性的描述。沿着这个思路,我们可以进一步拓宽对任务描述的元数据,称之为task meta-features。有了这些评估任务属性的特征,我们一方面可以从最相似的任务上来迁移经验,另一方面可以训练一些meta models来预测模型配置在新任务上的performance等。
4.2.1 Meta-Features
在Vanschoren, 2018中,作者总结了一系列人工设计的meta-features,例如:
- 数据集中的instance,特征,类别,缺失值,异常值的数量等
- 数据集中的各类统计信息,如skewness, kurtosis,correlation,covariance等
- 信息论中的各种指标,例如class entropy,mutual innformation,nuose-signal ratio等
- 模型指标,比如用决策树模型来拟合,获取到的叶节点数,树的深度等。
- Landmarks,使用一些简单模型来拟合数据,获取模型指标作为特征,例如单层神经网络,朴素贝叶斯,线性回归等。
对于一些特定的业务场景,也有一些特定的元特征可以使用。例如针对时间序列场景Prudêncio et al., 2004提出了一系列场景特定的元特征:

除了人工设计的meta-feature,我们也可以使用模型来学习生成meta-feature。例如Kim et al., 2017中,作者使用了Siamese network来生成meta-features:
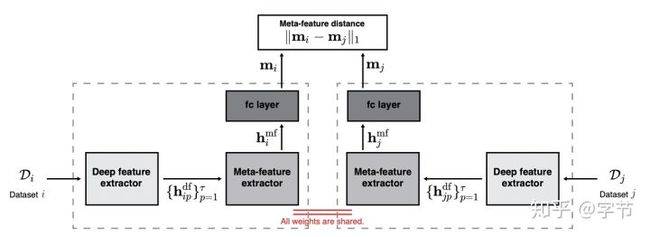
这里的学习目标是希望历史的验证集评估值的距离越接近真实距离越好。
值得一提的是,也有研究(Bilalli et al., 2017)表明,对于不同的任务,需要进行元特征的选择或降维,才能达到最优效果。
4.2.2 Warm-starting from Similar Tasks
在构建出meta-feature之后,一个比较自然的应用方式就是通过meta-feature来找到历史上尝试过的类似task,获取到相应的算法配置,来warm-start新的任务的优化。比如在Gomes et al., 2012和Feurer et al., 2015中,作者先通过meta-feature找到最接近的k个task,再用他们的最优参数来初始化PSO优化和贝叶斯优化过程。
还有一系列工作使用meta feature来建立surrogate models。比如Bardenet et al., 2013提出的SCoT,构建了一个ranking model来预测特定配置在特定task上的表现排名。后续再通过一个GP regression将ranks转化为probabilities,然后利用EI来找到下一个评估点,依此迭代。

在surrogate model方面,还有Schilling et al., 2015使用的MLP方法,以及Yogatama et al., 2014使用的joint GP。后者为了克服GP的scalability问题,在构建surrogate时只选取了跟目标task相似的若干个task。最后,值得一提的是Fusi et al., 2017等工作用了协同过滤模型,把task作为user,把config作为item,来做配置推荐。这里主要需要解决的问题是推荐的冷启动问题。在上面Fusi的工作中,他们采用了probabilistic matrix factorization方法,后续获取到的latent embeddings可以更高效的进行贝叶斯优化。
4.2.3 Meta-models
除了任务的warm-start,我们也可以直接构建一个从meta-feature到评估效果/最优参数的meta-model。我们根据model的预测目标的不同分为以下几类工作:
- 参数推荐:例如前面提到的使用kNN模型来找到最类似的任务,输出表现最好的参数。也有一些思路(Sanders et al., 2017)类似之前的tunability的工作,只不过用meta-model来预测模型参数是否需要进行搜索优化。
- 参数ranking:参考Sun, Pfahringer, 2013的ART forest,以及Pinto et al., 2017的autoBagging。两者用的meta-model都是集成树模型(后者用的是xgb),效率高且自带特征选择作用。
- 预测参数效果:例如早期的Guerra et al., 2008使用SVM regressor针对不同的分类算法分别构建meta-model,输入task的meta-feature来预测模型所能达到的预测准确率。Reif et al., 2014也使用了类似的方法,还把这部分的meta learning集成到了RapidMiner中进行应用(可惜没找到对应代码)。除了预测模型性能,也有同时考虑预测模型训练时间的一些工作,例如Yang et al., 2018,并把预测输出应用到后续模型选择中去。Eggensperger et al., 2017的想法更为大胆,针对一个具体的task来构建surrogate model预测参数的评估效果,这样就可以省去耗时的模型评估时间进行快速的参数搜索优化了。
4.2.4 To Tune or Not to Tune
思路上跟之前配置空间的设计类似,只不过这里给定任务属性及学习算法,我们可以用meta-model或数据统计来评估:
- 是否需要进行调优
- 在一定时间限制之内的搜索调优能够获得的提升度
- 如何进行调优
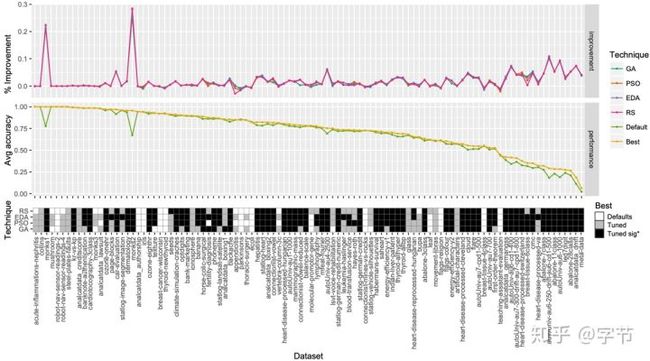
在Ridd et al., 2014中,作者在463个数据集上收集了不同算法使用默认参数和调优过的参数能获取到的性能提升量。这个元数据的结果也很有意思,以SVM算法为例,有50.31%的数据集使用最优参数相比默认参数获得的提升小于2.5%,有83.44%的数据集获得的提升小于5.0%。这个数据本身还是有点惊人的……后续他们训练了一个decision tree,来做调优提升是否会超过某个阈值的二分类预测。文中也提到了一些比较重要的meta-feature:kurtosis, normalized attribute entropy, joint entropy, NB and NN1(landmarks)。
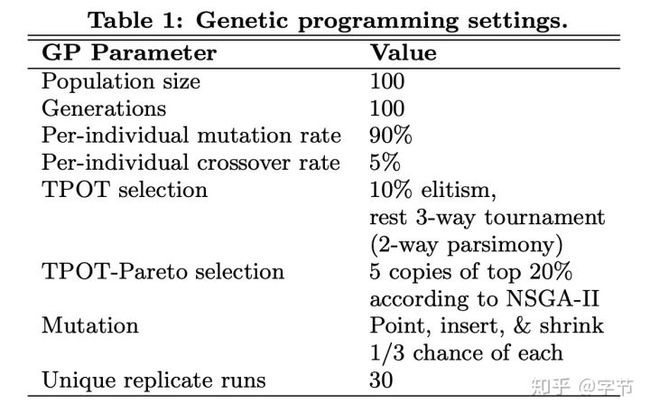
在Mantovani et al., 2016中,作者研究了各种HPO方法在决策树算法应用的表现效果,给出了他们的效果提升的统计显著度。总体来说调优会比默认参数的效果好,但是gap并不是很大。另外各类调优方法的表现总体也比较接近,EDA(Estimation of Distribution Algorithm)和PSO方法的表现最好。
4.2.5 Pipeline合成
在机器学习项目中,具体的learning box一般会是一个复杂的pipeline,这就导致了整个配置搜索空间变得更为庞大和复杂,如何利用之前的经验来为不同的task生成就显得更为重要。
比较直观的做法是通过预先设定一系列候选pipeline或固定pipeline的结构来控制整体的搜索空间大小,例如前面有提到过的Fusi et al., 2017和Feurer et al., 2015。或者针对pipeline中的某个步骤来做特定的优化建议,如数据预处理,特征选择等,后续可以应用到更大的全pipeline优化流程中去。例如Yu et al., 2003提出的针对特征选择部分的自动优化方法。
对于整个pipeline的搜索生成,有不少使用hierarchical task planning的方法。例如Nguyen et al., 2014的工作中,使用beam search来搜索生成pipeline,整体的系统结构如下:
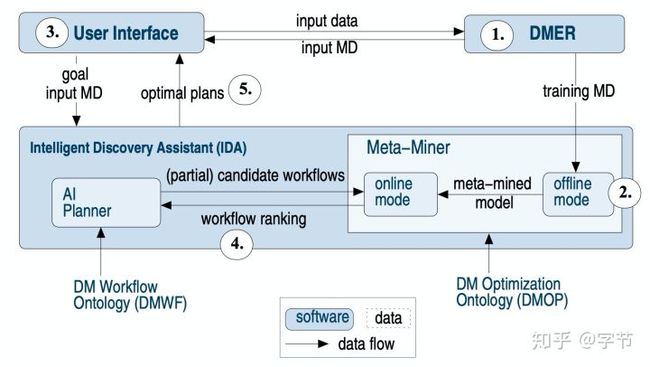
工作流程中1和2这两步是系统需要一系列的历史pipeline,任务及performance数据训练Meta-Miner模型。后续在使用时由用户输入具体任务的信息例如数据集,预测目标,top-k的数量等。接下来就进入了IDA的pipeline构建流程,AI Planner使用HTN方法根据目前的状态生成接下来所有可行的步骤,然后把这个partial pipeline输入到Meta-Miner中去,后者会根据task和pipeline的信息输出各个pipeline的ranking,依次往复,直到整个pipeline搜索完成,最后返回top-k ranking的完整pipeline给用户。这里的DMER指的是Data Mining Experiment Repository,里面存储了数据集,pipeline和performance results的元数据。对于数据集的属性,文中也是用了上面提到过的一系列meta-feature的构建方式来生成,包括属性,统计值,mutual information,landmarks等等。Pipeline的属性方面,文中使用了一套抽象定义(DMOP)来表达。具体到meta-model方面,文中采用了同构和异构两种方式来做similarity的学习和预测。前者是分别考虑数据集和pipeline的相似性,而后者通过矩阵分解手段把dataset和pipeline投影到一个共同的latent space,可以直接计算它们之间的相似度。文中的实验结果表明,第二种异构策略的效果会更好。
另外还有Wever et al., 2018提出的ML-Plan,同样用了HTN planning来生成pipeline,使用best-first graph search来选择具体的pipeline。具体的搜索评估方式与MCTS很类似,从节点开始做random completion,节点得分为random completion中效果最差的分数。这个评估方法的性能开销还是相当大的。另外他们的优化搜索分成了2个步骤,第一步先做pipeline生成,而不考虑pipeline中每个步骤的参数。第二步再在生成好的pipeline上做参数调优。
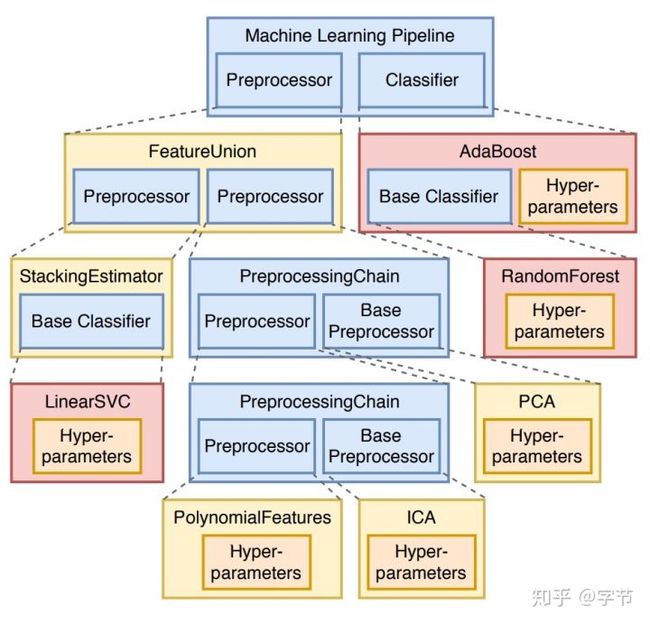
另外也有一系列使用遗传进化算法的pipeline生成尝试。比如著名的TPOT(Olson et al., 2017)和gama。从简单的pipeline开始,使用genetic programming的方法逐渐演化选择出表现更好的pipeline后代,具体的操作也是mutation,crossover这些。
最后还有使用强化学习方式来做pipeline生成的,例如Drori et al., 2017中,作者将pipeline目前的状态定义为state,把pipeline的修改操作定义为action,然后通过强化学习来逐步构建pipeline。在具体方法上,他们训练了一个LSTM,输入task的meta-feature和pipeline及evaluations,预测pipeline的performance和各个action的概率。再使用MCTS的方法来搜索生成pipeline。从实验结果看用上了GPU之后效率还比TPOT之类的更高,有点神奇。
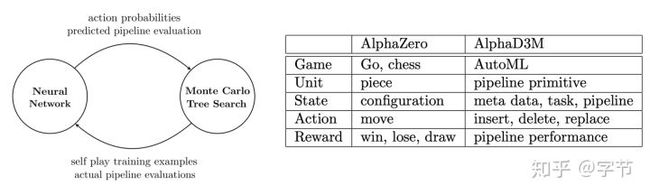
4.3 从之前的模型中学习
最后一块内容是从之前训练好的模型中来进行元学习,这也是大多meta learning课程和文章中主要涉及的方向,因为很多方法都比较适用在神经网络场景中,也是时下的热门方向。这方面有一篇非常好的Tutorial可以参考,肯定写的比我好,强烈安利一波 :)
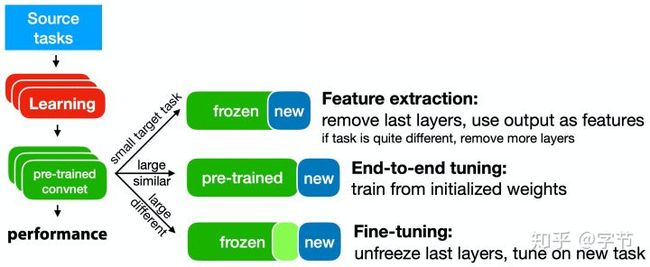
从之前的模型中学习,最自然的想法就是迁移学习。尤其在深度学习领域,预训练模型和fine-tune基本已经是人尽皆知的方法了。在应用过程中,我们也发现当任务相似度不高时,transfer learning的效果就不太理想(Yosinski et al., 2014)。是否可以通过一些meta-learner来更好的从历史模型中自动学习,加快后续模型的训练和学习能力呢?
4.3.1 Learning Update Rules
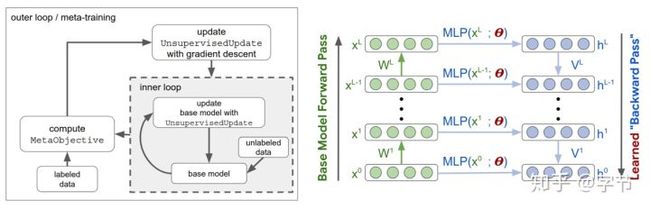
早在上个世纪,两位Bengio大佬就提出了替代反向传播的大胆想法(Bengio et al., 1995),后面衍生出一系列替代BP的meta-learner尝试。例如在Metz et al., 2019中,就使用了MLP(outer loop/meta learner)通过网络内部的各类中间值(例如神经元的输入,反馈信号等)的输入来计算生成更新参数,传入到具体执行学习任务的model来进行迭代更新。由于神经网络的结构会很不一样,为了具有一定的通用性,这里MLP对针对每个neuron来预测生成其update值。由于涉及到无监督学习的设定,这个meta-learner的训练及整体模型的结构还是相当复杂的。不过项目有提供代码实现,而且文章中的图也画的非常漂亮:
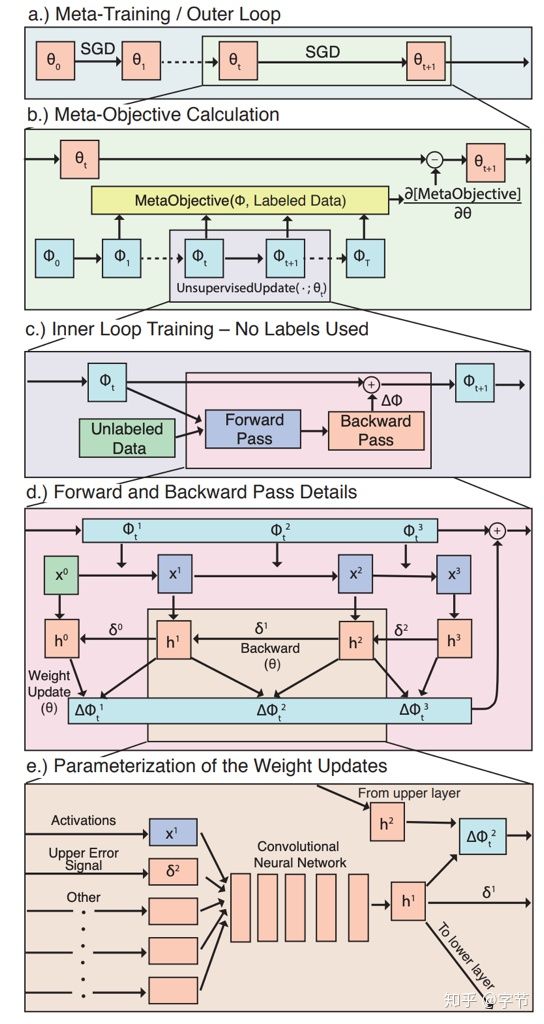
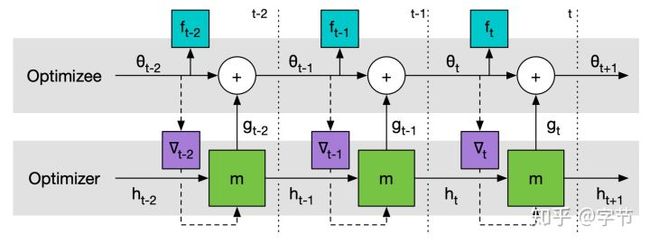
在此基础上,为了让meta-learner能有更好的对于过往task优化任务的记忆能力,能够让后续的优化更新更加高效,逐渐出现了一系列使用更复杂的meta-learner的工作。例如有两篇使用RNN作为meta-learner的文章,标题也非常经典:Learning to learn by gradient descent by gradient descent(Andrychowicz et al., 2016)和Learning to Learn without Gradient Descent by Gradient Descent(Chen et al., 2017)。这里设计的meta-learner获取到base learner的gradient作为输入,结合hidden state输出base learner的参数更新量,从而替代掉传统的BP更新方式。Meta-learner在训练时会使用base learner unroll多步的loss之和作为优化目标,一方面可以模拟base learner应用了gradient update之后loss逐渐下降的过程,另一方面也让loss不容易非常稀疏。在使用这个meta-learner时同样有被更新网络(base learner)参数特别多的问题,文中用了coordinate wise的方法,对每个参数来跑一个RNN,hidden state不同,但参数是共享的。这样对于meta-learner的size也能控制的比较好。具体还可以参考代码实现。后面这篇文章进一步把前作扩展到无法获取base learner的gradient的黑盒优化情况,还提出了一些并行function evaluation的手段来优化总体性能。
4.3.2 Few-shot Learning
从各种参考文献的相关解读文章的数量来看,这个方向绝对是目前元学习的大热门。所以我这边就简短的介绍一下各个比较有代表性的工作。
我们首先来看下few-shot learning的设定。普通的机器学习一般会分train data和test data,而这里要介绍的元学习方法,同样也有train/test概念,容易混淆,所以在术语上做了一些区分。首先在模型上,我们分为base learner(optimizee)和meta learner(optimizer)两块,base就是真正执行具体任务的,而meta是为了跨任务学习,好自动生成/控制base learner的learner,不过后面也会看到并不是所有方法都能严格区分成这两块。因为是few-shot设定,所以base learner的train data一般都很少,1-5个数据点比较常见,这部分在大多数文献中会被称为support set,而test data一般也是5个以内比较常见,被称为query set。另外还经常见到N-way k-shot的说法,这一般指的是一个few-shot的多分类问题,N表示有多少个类别,k表示每个类别有多少个training sample。具体到meta-learner的训练上,通常的做法是会把一个support set的训练加query set的评估作为一个task(episode)。然后我们可以从整体的train data中分别sample出多个task,然后再在整体的test data中sample出多个task,分别作为meta learning的training set和test set。
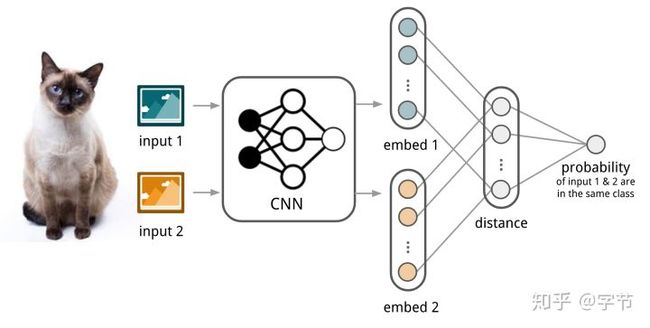
在One-shot learning方面,个人了解的最早的一个方法是Koch et al., 2015提出的用Siamese network来做。Deeplearning.ai的课程里也有提到这个经典的例子。
接下来两个比较常见的后续经常被作为baseline的工作是Santoro et al., 2016的MANN和Vinyals et al., 2016的Matching Network。前者这类带memory的NN貌似流行度并不高,我也没有深入研究这篇文章。后者的文章Andrej Karpathy也写了篇读文笔记。总体上看,Matching Network的核心思想,就是训练一个端到端的类似于nearest neighbor的分类器。
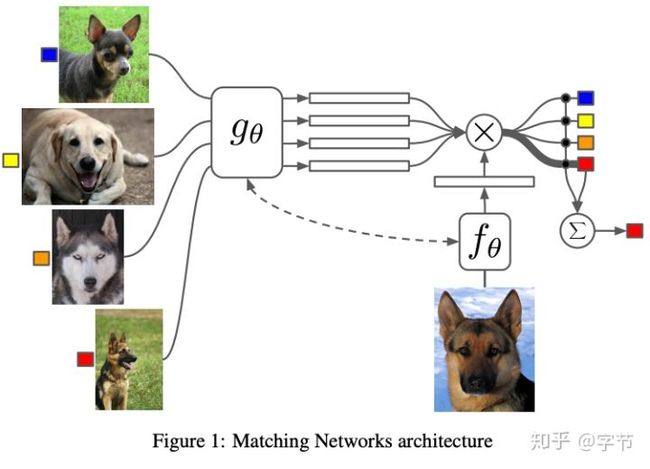
训练过程中,模拟测试流程,使用小样本构造minibatch,跟前面类似的episode的设定。例如图中就是support set size为4,query set size为1。
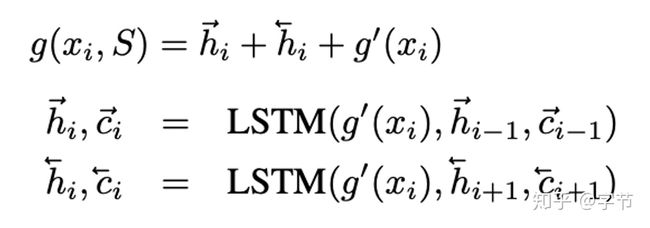
详细来看结构图里的各部分处理,这个g特征提取器是一个双向lstm(样本可能是随机顺序),式子中的g'是基础的图像特征提取器,比如inception, vgg之类。
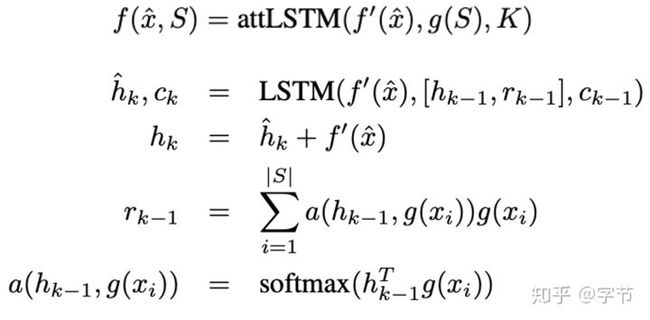
f特征提取器是一个带attention的lstm,迭代k步。每一步的输入都是f’(x)(基础图像特征提取),hidden state是上一步的hidden state与attention的读数(也是示意图中虚线部分)再concat一下,最后一步的读数即为f的输出。
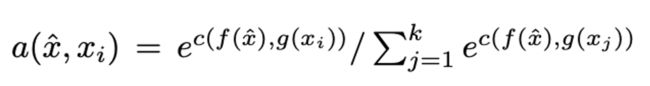
这个是最后输出前的处理,计算f embedding跟各个support sample g embedding后的相似度,最后再softmax一下。
从实验效果来看挺不错,结构设计也很有意思,说不定可以用在其它的kNN场景中 :)
接下来是Snell et al., 2017的Prototypical Network,设计上相对Matching Network来说更为简单,直接把各个类别的embedding平均一下,求出prototype特征,然后再通过相似度来分类即可。
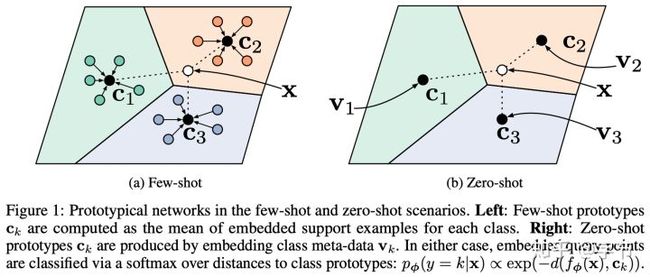
这篇Ravi et al., 2017,类似之前的learning update rules里的RNN meta-learner,用在了few-shot设定中。
Finn et al., 2017的这篇MAML可谓是这个领域的一个重量级工作,后续引出了FOMAML,Reptile(Nichol et al., 2018)等。李宏毅老师的meta learning讲座基本也是主要在介绍这几个工作。背后的核心想法是找到一组模型的初始参数,能够让这个参数后续能通过少数几个sample的训练之后快速达到一个比较好的模型效果。具体的做法也很简单,对于每一个task,假设模型的初始参数为θ,先用task的support set在模型上训练一波,得出了一个新模型参数θ',然后再在query set上用θ'的模型参数back prop更新初始参数θ。这样在多个task训练后,这个逐渐学习出来的θ逐渐就会拥有快速适应task的学习更新能力!
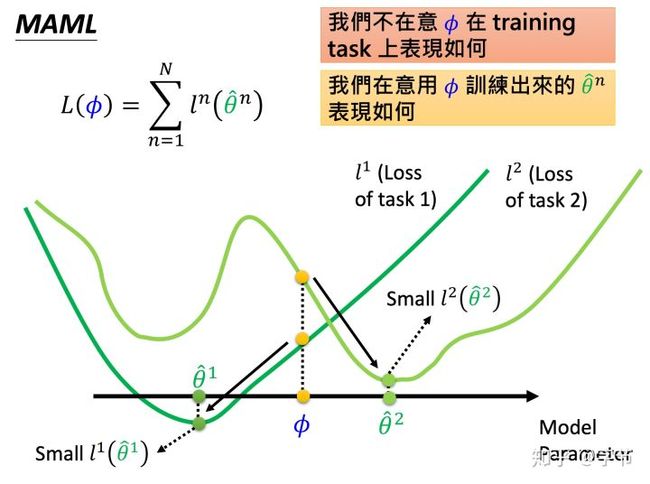
原作上在外层的meta update过程中会涉及到二阶导,后面的FOMAML和Reptile进一步简化了这方面的计算。可以参考OpenAI放出的源码实现。

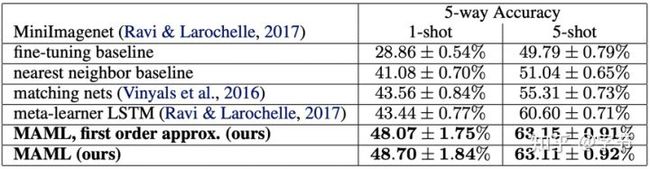
从结果上看比之前的几个工作效果都好不少,而且非常简单优雅!
最后来看下Mishra et al., 2018,把few-shot learning的过程直接做成了网络结构,通过attention block来学习过去task的信息,感觉也挺直观。
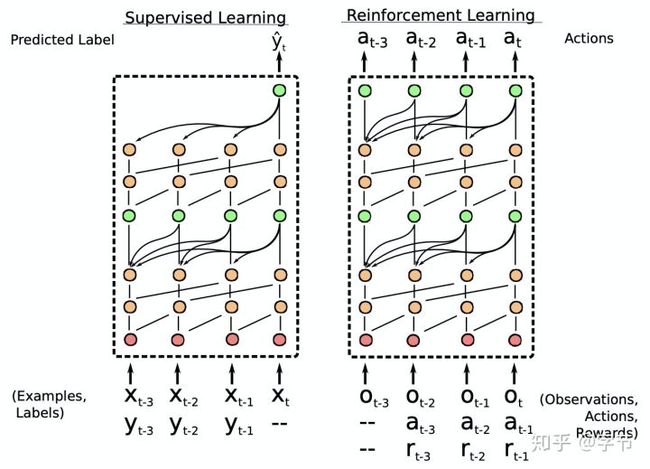
4.3.3 Beyond Supervised Learning
Meta learning也可以应用在非监督学习方面的问题。
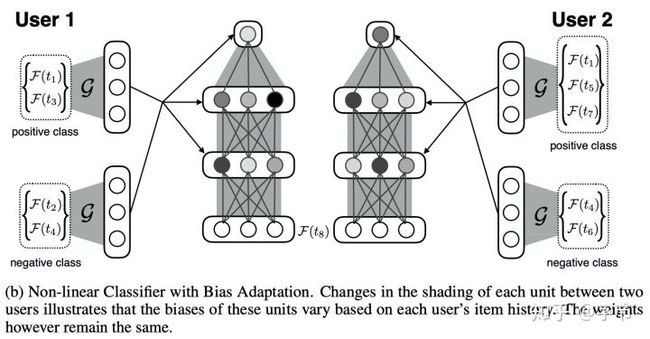
例如在Vartak et al., 2017中,为了解决基于矩阵分解的推荐模型冷启动问题,作者提出了使用神经网络架构,来根据用户行为快速调整网络的bias参数,做出相应的推荐变化。
而在Duan et al., 2016中,作者通过强化学习来构建meta RL learner。通过在多个任务上训练一个RNN,后续就能利用它在新task中快速实现一个RL agent。
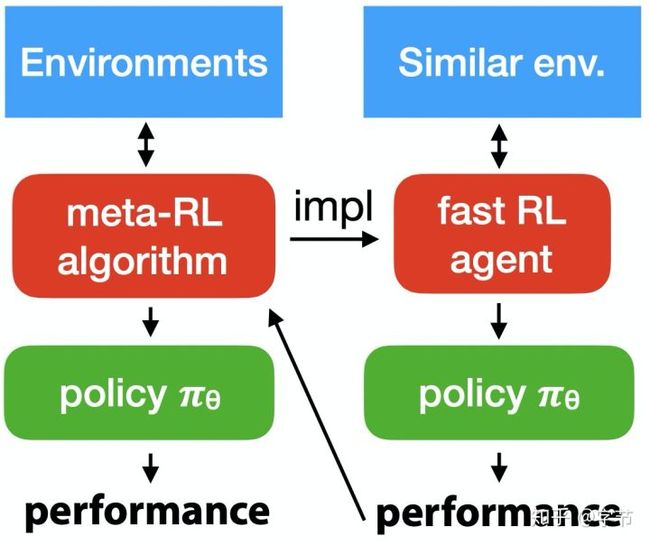
最后,在Pang et al., 2018中,作者设计了一个基于deep RL network的meta-learner,能够根据当前的数据状态(labeled,unlabeled,base classifier),和reward(base classifier的performance),输出一个query probability,达到active learning的效果。
4.4 总结
Meta learning这块前沿的研究和新奇的想法非常多,而且潜力巨大,毕竟设计出一个能自动学习如何学习的算法其通用性会比特定任务的自动学习大得多。当然各种未知和挑战也很大,从上面的研究看很多方面我们也只处于一个刚刚起步的状态,还有很长的路要走。如何构建出能够不断学习的模型,而不是需要每个任务从头来训练?如何让模型也有类似记忆的能力,甚至像world models那样,具备一些常识能力?如何发挥出active learning的潜力?等等问题,都等待着我们去开拓探索。从业界落地来说,目前看到的场景还比较有限,后面在讲到AutoML Systems和Challenges时会有一些涉及。
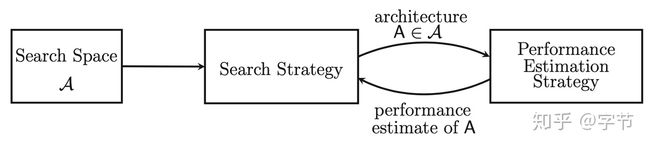
5 NAS
这块也是目前的一个热门领域,网上有非常多的文章来阐述这方面的各种最新进展。在这篇文章里,我就不展开做详细的讨论了,就做的概览,有兴趣的同学可以再去找相应的文章来学习参考。
5.1 搜索空间
目前看神经网络的结构搜索空间基本还是由人为设计的网络结构,从简单的基础网络层到复杂的skip-connection,多分支网络等。后续也有提出的cell结构来降低搜索空间的复杂度。
5.2 黑盒优化
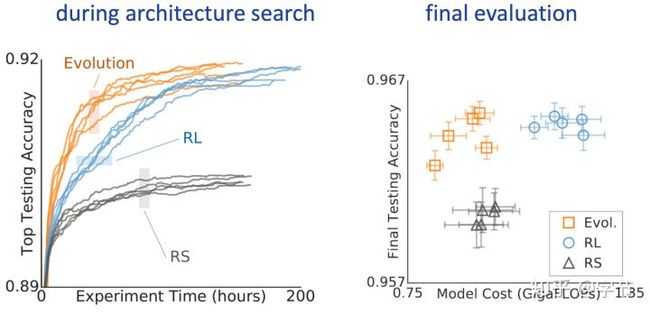
前面提到的一系列搜索优化策略都可以使用,例如随机搜索,贝叶斯优化,遗传算法,强化学习(RNN controller)等。比较不同之前的是对于神经网络,可以用基于gradient的方法来做(Liu et al., 2018)。从效果对比来看,遗传算法和BOHB这类方法表现最好。
5.3 超越黑盒优化
为了提升搜索优化效率,研究者们也提出了很多方法。比如之前有提过的multi-fidelity方法,包括Hyperband的提早淘汰,基于learning curve的预测等。使用meta learning来从之前的经验中学习,提升搜索效率(Wong et al., 2018)。在神经网络领域,一些比较特别的做法是weight inheritance & network morphisms(如Cai et al., 2018),不需要每次都从头训练。还有类似的weight sharing & one-shot models(如著名的ENAS),训练一个super-graph模型,从其中抽取子图来形成网络,不再做训练,直接评估效果。
5.4 前沿方向
2020年有一些新的工作发表,对NAS感兴趣的同学可以关注一下。一个是前面截图中的NAS-Bench-101(Ying et al., 2019),是19年提出的对于这个方向Benchmark标准化的一些尝试。但目前看起来这类Benchmark设计的搜索空间复杂度还非常有限,在White et al., 2020中的结果显示,local search就能打败所有的SoTA方法……但在更大的搜索空间上,这个方法表现显然是不足以成为SoTA的。在Elsken et al., 2020中,作者提出了meta learning与NAS结合的方式来做few-shot learning,效果比之前的reptile和AutoMeta更好。还有之前提过的自动ensemble优化技术也可以与NAS的结合,进一步提升模型输出的整体稳定性和效果,可以参考这篇:Zaidi et al., 2020。
从NAS的SoTA,paperswithcode上目前被Lu et al., 2020的Neural Architecture Transfer霸榜了,包括后面几名的NSGANet也是他们的工作,有点厉害。
最后,在工具框架方面,Auto-PyTorch(Zimmer et al., 2020)采用了NAS联合HPO,并利用了multi-fidelity和meta learning初始化来加速优化搜索,值得学习关注。
6 全pipeline自动化
在最开始的背景中我们介绍过,整个机器学习的pipeline的各个部分都有使用AutoML来提效的可能性。在实际项目中,往往跟数据处理,数据质量相关花费的时间非常多,但是相关的研究却明显少了很多。
6.1 数据准备
- van den Burg et al., 2018中设计了自动检测csv文件类型的方法
- Valera and Ghahramani, 2017提出了自动分类数据类型的方法
- Sutton et al., 2018希望能够实现数据收集过程中错误的自动检测发现
6.2 特征工程
- Featuretools,比较知名的自动化特征工程库,几乎成了自动化特征工程代名词……
- Luo et al., 2019第四范式去年发表的一篇自动化特征工程的文章,要是有开源就更好了 :)
- tsfresh比较知名的时间序列领域的自动化特征工程库
总体来说这几个方面比较突出的工作很少,包括后续模型debugging和评估方面,几乎没有看到相关的研究。大家如果有看到过这些方面比较impressive的研究欢迎推荐和补充。
7 AutoML Systems
这一节我们来看下业界的一些AutoML工具及相关系统。
从工具方面来说,超参数优化方面比较常用的工具主要是hyperopt和SMAC,FB也有开源一个BoTorch,在PyTorch中实现了贝叶斯优化。
从AutoML的框架来看,比较有名的有auto-sklearn,TPOT,nni,auto-gluon,H2O.ai,transmogrif等。
7.1 Auto-sklearn
基于sklearn和SMAC技术,预先定义了42个有效的超参数的搜索维度,为了优化搜索效率,仅考虑支持multi-fidelity的算法。使用了successive halving结合BO来做参数的搜索优化,效率非常高。另外通过最基础的meta-learning,预先定义了一组整体期望效果最好的超参portfolio(与前面的ensemble learning有点类似),进一步提升搜索效率。这里比较有意思的是auto-sklearn的第一版用了更复杂的meta-learning策略,还考虑了数据集的meta-features来做超参推荐,2.0版本里进行了简化。最后在验证策略方面,auto-sklearn也会根据问题的复杂度与资源budget进行动态的选择,比如在资源充足的情况下选择10-fold CV,而在资源缺乏的情况下只做一组train-valid的验证。
7.2 TPOT
前面也有介绍,是一个基于遗传算法来做优化的AutoML框架,且能够进行整个pipeline的搜索生成。只能处理分类问题。由于其他性能优化方面的措施不多,这个框架整体的性能表现比较一般。
7.3 Automatic Statistician
一个非常有野心的end-2-end AutoML框架,包含数据接入,搜索优化,模型评估/解释,自动报告生成等组件,可惜没有开源实现,不太清楚具体的完成度有多高。
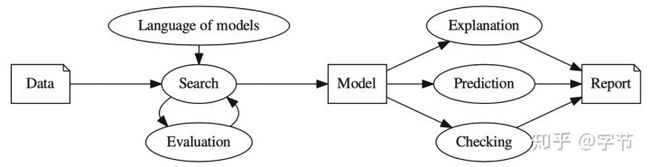
作者希望实现:
- 一种开放式的模型语言,达到足以捕捉各种现实世界现象的表达能力
- 一种搜索程序,可以高效地探索上述定义的模型语言空间
- 一种评估模型的原则方法,能够权衡复杂性,数据特性和资源使用情况等
- 一种自动解释模型的流程,使模型的假设能够准确且可理解的方式传达给非专业人员
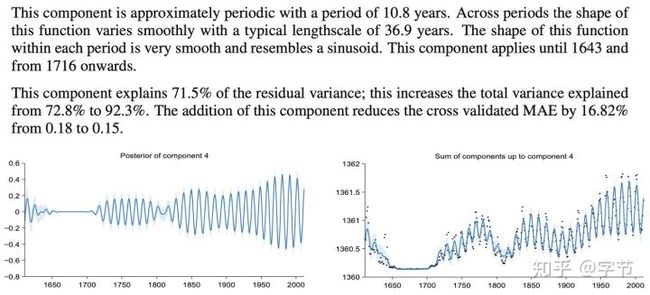
看起来有点抽象,他们的一篇文章(Lloyd et al., 2014)实现了其中自动拟合模型加模型解释的流程,还挺有意思。
7.4 AutoGluon
应该还比较新,在知乎上看了作者写的架构说明,感觉值得关注一波。同样ray tune在大规模搜索调优上面应该也挺有优势,这方面AutoML与系统架构设计结合的方向在实际生产落地中也是非常关键的。
7.5 其它
微软开源的nni看起来实现了非常多流行的AutoML算法,不过我个人还没有尝试过具体效果如何。RapidMiner,H2O中带了一些AutoML的功能,而Transmogrif是Salesforce开源的AutoML方案,背后支持了Einstein的运行。可以重点关注一下他们如何在企业级软件中结合AutoML的能力。
另外还有很多云平台也提供了AutoML的能力(例如前面提到过的Vizier就是Google家的),有兴趣的同学也可以参考借鉴商业化AutoML产品的设计与实现。