本文首发于泊浮目的:https://www.jianshu.com/u/204b8aaab8ba
| 版本 | 日期 | 备注 |
|---|---|---|
| 1.0 | 2020.9.13 | 文章首发 |
| 1.1 | 2020.11.8 | 优化对于第一个方案的措辞 |
| 1.2 | 2021.1.17 | 优化小结部分 |
| 1.3 | 2021.2.3 | 修改标题从利用Clean Architecture写好白盒测试 -> 遵循Clean Architecture写好白盒测试 |
| 1.4 | 2021.5.21 | 修改标题从遵循Clean Architecture写好白盒测试 -> 技巧:遵循Clean Architecture写好白盒测试 |
前言
Clean Architecture是Bob大叔在2012年提出的一个架构模型。其根据过去几十年中的一系列架构提炼而成:
- Hexagonal Architecture:由 Alistair Cockburn 首先提出
- DCI:由 James Coplien 和Trygve Reenskaug 首先提出
- BCE:由 Ivar Jacobson 在他的 Obect Oriented Software Engineering: A Use-Case Driven Approach 一书中首先提出
根据这些架构设计出来的系统,往往具有以下特点:
- 独立于框架:这些系统的架构并不依赖某个功能丰富的框架之中的某个函数。框架可以被当成工具来使用,但不需要让系统来适应框架 。
- 可被测试这些系统的业务逻辑可以脱离 UI、 数据库、Web 服务以及其他的外部元素来进行测试 。
- 独立于UI:这些系统的UI变更起来很容易,不需要修改其他的系统部分。例如,我们可以在不修改业务逻辑的前提下将一个系统的UI由Web 界面替换成命令行界面 。
- 独立于数据库:我们可以轻易将这些系统使用的Oracle、SQL Server 替换成 Mongo、BigTable、CouchDB 之类的数据库。因为业务逻辑与数据库之间已经完成了解耦 。独立于任何外部机构:这些系统的业务逻辑并不需要知道任何其他外部接口的存在 。
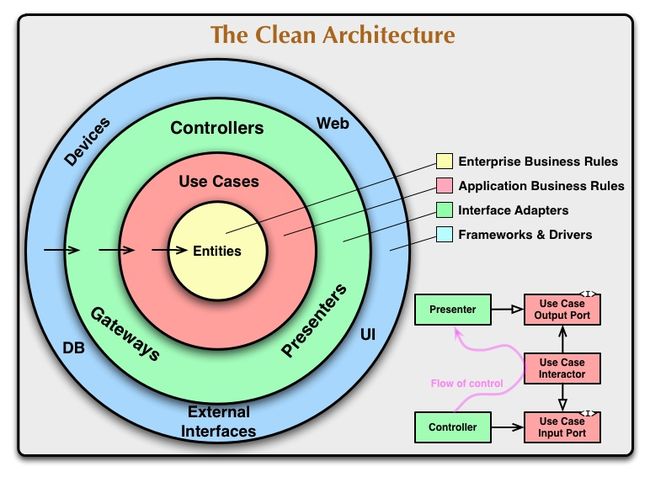
关于Clean Architecture的介绍到此为止,有兴趣的同学可以自行查阅google。
背景
最近写了很多业务代码,因为每个组件都是分布式部署的,导致手动测试时非常的痛苦,耗时耗力。于是笔者开始思考针对业务的自动化测试方案。
目前业务中一部分的代码使用了Storm这个框架,我们挑一个方便理解的用例,这里大概涉及三个组件:
- ReadSpout:从kafka、database读取消息,并将其下发
- DispatcherBolt:读取上游下发的消息,并根据一定的规则分发——比如自定义字段,将字段相同的数据放在一起并下发
- KafkaWriteBolt:读取上游下发的消息,将关键字一样的数据写入kafka同一个分区
DispatcherBolt的代码大致如下:
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
super.prepare(conf, context, collector);
try {
init();
} catch (Exception e) {
collector.reportError(e);
throw new RuntimeException(e);
}
}
@Override
public void execute(Tuple dataTuple) {
this.input = dataTuple;
try {
Object obj = dataTuple.getValueByField(EmitFields.MESSAGE);
String key = (String) dataTuple.getValueByField(EmitFields.GROUP_FIELD);
List messageEntries = (List) obj;
emitMessageEntry(key, messageEntries);
this.collector.ack(dataTuple);
} catch (Exception e) {
logger.info("Dispatcher Execute error: ", e);
this.collector.reportError(e);
this.collector.fail(dataTuple);
}
}
private void emitMessageEntry(String key, List messageEntries) throws Exception {
long lastPos = 0L, uniquePos = 0L, payloadSize = 0L;
UmsMessageBuilder builder = null;
String tableName = messageEntries.get(0).getEntryHeader().getTableName();
for (MessageEntry msgEntry : messageEntries) {
EntryHeader header = msgEntry.getEntryHeader();
header.setLastPosition(lastPos);
if (StringUtils.isEmpty(tableName) || (getExtractorConfig().getGroupType() == GroupType.SCHEMA && !StringUtils.equalsIgnoreCase(tableName, header.getTableName()))) {
emitBuilderMessage(builder, key);
builder = createUmsDataBuilder(msgEntry, destination, msgEntry.getBatchId(),
MediaType.DataSourceType.getTypeByName(getExtractorConfig().getNodeType()));
payloadSize = 0;
}
// DDL handle
if (msgEntry.isDdl()) {
emitBuilderMessage(builder, key);
executeDdlEvent(msgEntry);
emitDDLMessage(key, msgEntry);
builder = null;
continue;
}
if (builder != null && msgEntry.getEntryHeader().getHeader().getSourceType().equalsIgnoreCase(MediaType.DataSourceType.ORACLE.getName())) {
emitBoltMessage(key, builder.getMessage());
builder = createUmsDataBuilder(msgEntry, destination, msgEntry.getBatchId(),
MediaType.DataSourceType.getTypeByName(getExtractorConfig().getNodeType()));
payloadSize = 0;
}
// DML handle
if (builder == null) {
builder = createUmsDataBuilder(msgEntry, destination, msgEntry.getBatchId(),
MediaType.DataSourceType.getTypeByName(getExtractorConfig().getNodeType()));
payloadSize = 0;
}
for (CanalEntry.RowData rowData : msgEntry.getRowDataLst()) {
lastPos = Long.parseLong(header.getPosition()) + (++uniquePos);
if (header.isUpdate()) {
if (getExtractorConfig().getOutputBeforeUpdateFlg()) {
payloadSize += appendUpdateBefore2Builder(builder, header, rowData, EventType.BEFORE.getValue().toLowerCase());
}
if (ExtractorHelper.isPkUpdate(rowData.getAfterColumnsList())) {
payloadSize += appendUpdateBefore2Builder(builder, header, rowData, getEventTypeForUMS(CanalEntry.EventType.DELETE));
}
}
List 注意,这里的两个方法prepare和execute都是框架暴露出来的接口,用于初始化时获得strom的上下文以及strom下发的对象。如果开发者使用不当,则会导致业务代码和框架耦合。
方案1:Object Dependency Inject
这个方案在早期的时候做过尝试,简单的来说就是将中间那段emitMessageEntry相关的代码抽象成一个接口的方法,并在实现代码中填入现在的逻辑,并通过spring这种IOC框架注入进来,类似于:
override fun prepare(topoConf: MutableMap, context: TopologyContext, collector: OutputCollector) {
super.prepare(topoConf, context, collector)
try {
init()
this.dispatcherServer = IOCUtil.getBean(DispatcherServer::class.java).init(collector)
} catch (e: Exception) {
collector.reportError(e)
throw RuntimeException(e)
}
}
override fun execute(input: Tuple) {
val obj = dataTuple.getValueByField(EmitFields.MESSAGE)
val key = dataTuple.getValueByField(EmitFields.GROUP_FIELD) as String
val messageEntries = obj as List
dispatcherService.dispatcherLogical(messageEntries,key)
}
这样我们在单元测试里可以直接将dispatcherService类注入进来,并自己实现一个OutputCollector用于收集分发数据——通过配置spring框架来灵活的替换实现类。然后将mock的参数填入,并断言结果是否符合我们的期待。
但由于storm会涉及到分发相关事宜(如序列化),这会让业务代码有点变扭:
- 将这个
dispatcherService成员在Bolt里声明为Transient - 需要在初始化时初始化IOC容器
- 在初始化IOC容器后注入dispatcherService
可以看到,我们为了测试,竟然不得不修改业务代码——加入无关紧要的逻辑,这显然不是一个好的方案。
方案2:Mockito
Mockito实现的方案对业务没有任何入侵性,直接写测试代码即可,写出来的代码类似于:
@RunWith(PowerMockRunner::class)
@PowerMockIgnore("javax.management.*")
class DispatcherBoltTest {
private lateinit var config: AbstractSinkConfig
private lateinit var outputCollector: OutputCollector
private lateinit var tuple: Tuple
@Before
fun atBefore() {
config = PowerMockito.mock(AbstractSinkConfig::class.java)
outputCollector = PowerMockito.mock(OutputCollector::class.java)
tuple = PowerMockito.mock(Tuple::class.java)
}
private fun init(dispatcherBoltImpl: DispatcherBoltImpl) {
reset(config)
reset(outputCollector)
reset(tuple)
dispatcherBoltImpl.prepare(mutableMapOf(), PowerMockito.mock(TopologyContext::class.java), outputCollector)
}
@Test
fun testSingleUms() {
//定义mock对象的一些行为
`when`(config.configProps).thenReturn(Properties())
//将需要测试的类实例化
val dispatcherBoltImpl = DispatcherBoltImpl(config)
init(dispatcherBoltImpl)
val umsMap = generateSingleUmsBo()
val boMap = getBoMap(intArrayOf(1))
//定义mock对象的一些行为
`when`(tuple.getValueByField(EmitFields.MESSAGE)).thenReturn(umsMap.messages)
`when`(tuple.getValueByField(EmitFields.GROUP_FIELD)).thenReturn(umsMap.dispatchKey)
`when`(tuple.getValueByField(EmitFields.EX_BO)).thenReturn(boMap)
dispatcherBoltImpl.handleDataTuple(tuple)
// 结果验证
Mockito.verify(outputCollector, Mockito.times(1))
.emit(EmitFields.DATA_MSG, tuple, Values(umsMap.dispatchKey, umsMap.messages,
boMap,
EmitFields.EMIT_TO_BOLT))
}
}
逻辑很清晰易懂:先选择需要mock的对象,并定义其被mock的行为,然后把数据填装进去即可,最后根据结果校验——本质上将业务和框架的行为一起测试了进去。
但如果把视野放高点看,有两个潜在的问题需要考虑:
- 目前该类的业务逻辑比较简单,所以我们需要关注的链路也较少——这体现在我们对于mock对象的mock行为编写上。换句话说,该类越复杂,我们就需要编写越多的mock代码。
- 目前我们的业务和框架是紧耦合的,那么我们测试时需要将框架的行为一同考虑进去。同时也意味着框架行为变动时(如升级),测试用例需要大量变更。亦或是更换框架时,测试用例会变得几乎不可用。这已经违反整洁架构的原则了——业务需要独立于框架,而不是紧密耦合。
方案3:Clean Architecture
根据前面提到的,我们要做的第一件事就是剥离业务和框架的耦合。那么该如何剥离呢?我们直接拿出答案:
/**
* 剥离与任何流处理框架的耦合,仅关注UMS分发的服务
* */
interface DispatcherServer {
fun dispatcherMessageEntry(key: String, messageEntries: List, destination: String,
tableToDispatchColumn: HashMap>,
resultConsumer: (group: MutableMap, key: String) -> Unit,
executeDdlEventBlock: (messageEntry: MessageEntry) -> Unit,
ddlMessageConsumer: (key: String, messageEntry: MessageEntry) -> Unit)
}
我们定义了三个函数型参数。利用这种方式,我们可以轻易的将业务和框架隔离开来。于是代码调用起来就像这样:
override fun execute(dataTuple: Tuple) {
input = dataTuple
try {
val obj = dataTuple.getValueByField(EmitFields.MESSAGE)
val key = dataTuple.getValueByField(EmitFields.GROUP_FIELD) as String
val messageEntries = obj as List
dispatcherServer.dispatcherMessageEntry(key, messageEntries, destination, tableToDispatchColumn,
dmlMessageConsumer = { builder, innerKey -> emitBuilderMessage(builder, innerKey) },
executeDdlEventBlock = { entry -> executeDdlEvent(entry) },
ddlMessageConsumer = { innerKey, msgEntry -> emitDDLMessage(innerKey, msgEntry) }
)
collector.ack(dataTuple)
} catch (e: Exception) {
logger.info("Dispatcher Execute error: ", e)
collector.reportError(e)
collector.fail(dataTuple)
}
}
emitBuilderMessage、executeDdlEvent、emitDDLMessage只是DispatcherBolt中的一个私有方法,里面会将传入的数据通过collector按照一定规则下发下去。这样,我们就将框架相关的代码放在了DispatcherBolt里。
而和框架无关的业务代码,我们则可以将它放到DispatcherServer的实现中去。
测试的代码也可以专注在测试业务逻辑上:
@Test
fun testUpdateRecords() {
val originNamespace = "my_schema.my_table"
val mockData = listOf(getUpdate1Data())
val config = getMockConfig(extractorConfigJsonFile)
config.outputBeforeUpdateFlg = false
config.outputExtraValueFlg = false
config.payloadType = PayloadType.SIZE
config.maxPayloadSize = 10240
val dispatcherServer = DispatcherServerImpl(config)
val resultMap = mutableMapOf()
dispatcherServer.dispatcherMessageEntry(originNamespace, mockData, "M26", hashMapOf(),
dmlMessageConsumer = { builder, innerKey ->
resultMap.putAll(builder)
Assert.assertEquals(innerKey, originNamespace)
},
executeDdlEventBlock = { throw RuntimeException("这堆数据中不应该出现DDL事件") },
ddlMessageConsumer = { _, _ -> throw RuntimeException("这堆数据中不应该出现DDL相关的结果") })
assertEquals(1, resultMap.keys.toSet().size, "当前数据中,应该被分为3组——根据主键分发原则,他们来自于不同的主键")
assertEquals(1, resultMap.size, "当前数据中,应该被分为3组——根据主键分发原则,他们来自于不同的主键")
val umsList = resultMap.values.map { it.message }
umsList.forEach {
Assert.assertEquals("m.M26.my_schema.my_table", it.schema.namespace)
Assert.assertEquals(1, it.payloads.size)
assertEquals(9, it.schema.fields.size, "5个扩展字段+4个schema字段应该为9")
Assert.assertEquals("inc", it.protocol.type)
Assert.assertEquals("2", it.protocol.version)
assertEquals(MediaType.DataSourceType.MYSQL, KafkaKeyUtils.getDataSourceType(it))
}
}
看完了效果,我们再来谈谈上面所用到技巧。其实这很像面向对象中的Strategy模式——定义一个算法接口,并将每一种算法都在这个接口下实现其逻辑,令同一个类型的算法能够互换使用。这样做的好处是算法的变化不影响使用方,也不受使用方的影响。而如果函数是一等公民的话,则会让建立和操纵各种策略的工作变得十分简单。
那么怎样算是不简单的呢?如果用java的话,我们得先定义一个专门的接口,声明一个方法,在使用时用匿名内部实现将它传入,但这其实没什么必要,因为我们仅仅想传一个函数进去,而不是对象。典型的代码可以见:
ZStack源码剖析之设计模式鉴赏——策略模式:https://segmentfault.com/a/1190000013460437
设计模式要做的事不外乎减少代码冗余度,提高代码复用性。而在函数式语言中,复用主要表现为通过参数来传递作为第一等语言成分的函数,各种函数式编程库都频繁地运用了这种手法。与面向对象语言相比(以类型为单位),函数式语言的重用发生于较粗的粒度级别上(以行为为单位),着眼于提取一些共通的运作机制,并参数化地调整其行为。
小结
在本文中,我和大家讨论了一些典型的测试方法,最后我们使用策略模式较好的完成了测试代码。而策略模式本身其实是inversion of control的一种体现,关于IOC,我们可以用Hollywood Principle来理解它——don't call us, we'll call you:在最早版本时,我们的业务代码在执行完后直接“找到”了框架的方法,至使耦合。在最后的版本里,我们的业务代码暴露了策略接口,便于外部将逻辑灵活的注入进来,而不是紧耦在一起。