FFM:土豪的利器,平民该怎么玩?(tensorflow2, Bi-FFM)

作者 | xulu1352 目前在一家互联网公司从事推荐算法工作(知乎:xulu1352)
编辑 | auroral-L
(本篇文章已获得作者的独家授权)
0.前序
在之前推荐算法中的倚天剑: FM (tensorflow2实现)一文介绍了FM的有关原理,本文登场的是FM家族的肥仔,土豪公司的利器——FFM(Field-aware Factorization Machine,即具备特征域(Field)意识的FM。至于为何给它冠名肥仔+土豪利器,说来话长,本文后面会作详细分析。我们知道FFM源于FM,基于FM引入了Field概念,在特征组合上更加细腻,同一特征针对不同Field作特征交叉组合时使用不同隐向量(embedding),即有不同表征信息,而FM的每个特征与其他特征组合时共享一个embedding向量。因而FFM模型的表达能力更强,但其计算复杂度也因此更高。假设有F个特征域,那么FFM的参数量应该是FM的F-1倍,实际生产中特征域数都至少在几十以上,在一个很大的基数上再放大几十或成百倍,这个参数量的改变非常阔怕。更阔怕的是,它无法像FM那样通过数学公式转化,将计算复杂度由平方级降至线性级别。FFM的这一特性无疑抬高了训练与推理的门槛,让很多家里没矿的玩家不得不谨慎衡量投入回报比,也因此都望而却步。幸运的是,微博团队针对FFM参数量太大,耗内存,训练速度慢的问题,提出了Bi-FFM(Bilinear-FFM,双线性FFM模型),让我这样的平民玩家也可以在生产上试试FFM的威力,体验下土豪的乐趣。好了,吹水的话,就到此为止了,下面看看FFM与Bi-FFM的原理。
1.FFM原理
首先来回顾下FM的数学表达式,
FFM是FM的升级版,通过引入field的概念,FFM把相同性质的特征归于同一个field, FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。在FFM中,每一维特征,针对其它特征的每一种field,都会学习一个隐向量。因此,隐向量不仅与特征相关,也与field相关,根据FFM的field敏感特性,FFM模型方程定义为,
其中, 是第 个特征所属的field。对比式(1)与式(2)可以得出,基于field的FFM和FM的区别:
(1)FM特征 、 、 交叉时,对应的隐向量 、、是可以无区别得互相交叉的,也即是说 的系数为 , 的系数为 ,显然, 无论与 ,还是 与 做交叉时,组合系数都是共享同一个,并没有做区分。
(2)FFM同样是对特征进行交叉,但是FFM的特征 、 、 交叉时,对应的隐向量 、、,是将field差别信息考虑进去的;即 与特征 ,与特征做交叉时,组合系数不再使用同一个,而是根据field信息区分为 和 。
如果隐向量的长度为,那么FFM的二次参数有个,是远多于FM模型的个。此外,由于隐向量与field相关,FFM二次项并不能够简化,其预测复杂度是。

FM与FFM参数对比
接下来,我们探索FFM的loss function。
在ctr预估中,模型训练一般我们使用叉熵损失函数,假设我们有 组样本( ), 表示第 组数据及其对应的label。 则为表示label的一个数{0,1},即 取0或者1。那么,FFM交叉熵损失函数可表示为,
其中,为FFM推理公式输出值,为sigmoid概率输出函数,即,顺便提下其一个优良求导性质。
在利用梯度下降法求解参数时,其梯度推导过程如下,
推到这里可见,接下来我们只需关心 求导结果, 因为 在推理阶段已经计算过了,是一个已知结果。
继续解析,
当参数 为 时, 。
当参数为 时, 。
当参数为 时,二阶项的梯度更新公式:
总结下,
到此,我们发现FFM的梯度更新公式并不复杂,训练阶段的计算时间复杂度主要来源式(2)计算FFM的输出值,复杂度为 , 因此,训练时间复杂度为。想必此时,我给它冠名FM家族的肥仔+土豪利器,应该不过分,参数量远多于FM,训练时间复杂度又在,没有强大GPU资源做后盾,平民玩FFM就是跛足,举步维艰。
2.FFM的优化:Bi-FFM
为了减小参数量及提高训练速度,微博团队基于共享参数矩阵对FFM做一些改进,提出了双线性FFM模型,它的核心思想是:分别使用一个隐向量来表达,与FM一样,但是把两个特征交互的信息用一个共享参数矩阵表示。那么,Bi-FFM的二阶交叉项的表达式可写成如下形式:
图形表示如下:
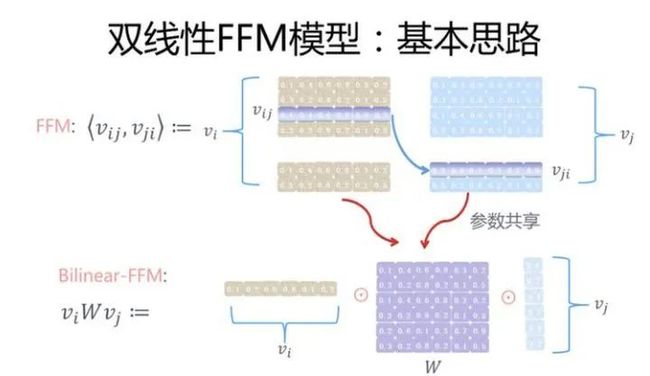
对于共享矩阵 ,Bi-FFM作者给出了三种选择:
类型1: 共享同一个 ,这是参数量最小的一种形式。 的参数量是 , 是特征Embedding的size;
类型2: 每个field共享一个,即每个field各自学各自的 ;
类型3: 每两个fields对共享一个,能更加细化地描述特征组合;

Bi-FFM对比FFM的参数量减少是非常显著的,由于一阶项并无区别,参数量差别集中在二阶交叉项。
比如以Criteo这个4500万的数据集为例,从下图我们可以非常明显的感受到它们之间参数量差异。

3.Bi-FFM的一种实现
关于Bi-FFM二阶交叉层的实现,主要参考了新浪微博机器学习团队发表在RecSys19上的FiBiNET中双线性交叉层的实现方式。文章标题为 FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction,下面看看它的tf实现方式。
class BilinearInteraction(Layer):
"""BilinearInteraction Layer used in FiBiNET.
Input shape
- A list of 3D tensor with shape: ``(batch_size,1,embedding_size)``. Its length is ``filed_size``.
Output shape
- 3D tensor with shape: ``(batch_size,filed_size*(filed_size-1)/2,embedding_size)``.
Arguments
- **bilinear_type** : String, types of bilinear functions used in this layer.
- **seed** : A Python integer to use as random seed.
References
- [FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction](https://arxiv.org/pdf/1905.09433.pdf)
"""
def __init__(self, bilinear_type="interaction", seed=1024, **kwargs):
self.bilinear_type = bilinear_type
self.seed = seed
super(BilinearInteraction, self).__init__(**kwargs)
def build(self, input_shape):
if not isinstance(input_shape, list) or len(input_shape) < 2:
raise ValueError('A `BilinearInteraction` layer should be called '
'on a list of at least 2 inputs')
embedding_size = int(input_shape[0][-1])
if self.bilinear_type == "all":
self.W = self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight")
elif self.bilinear_type == "each":
self.W_list = [self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight" + str(i)) for i in range(len(input_shape) - 1)]
elif self.bilinear_type == "interaction":
self.W_list = [self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight" + str(i) + '_' + str(j)) for i, j in
itertools.combinations(range(len(input_shape)), 2)]
else:
raise NotImplementedError
super(BilinearInteraction, self).build(
input_shape) # Be sure to call this somewhere!
def call(self, inputs, **kwargs):
if K.ndim(inputs[0]) != 3:
raise ValueError(
"Unexpected inputs dimensions %d, expect to be 3 dimensions" % (K.ndim(inputs)))
n = len(inputs)
if self.bilinear_type == "all":
vidots = [tf.tensordot(inputs[i], self.W, axes=(-1, 0)) for i in range(n)]
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)]
elif self.bilinear_type == "each":
vidots = [tf.tensordot(inputs[i], self.W_list[i], axes=(-1, 0)) for i in range(n - 1)]
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)]
elif self.bilinear_type == "interaction":
p = [tf.multiply(tf.tensordot(v[0], w, axes=(-1, 0)), v[1])
for v, w in zip(itertools.combinations(inputs, 2), self.W_list)]
else:
raise "NotImplementedError"
output = concat_func(p, axis=1)
return output
def compute_output_shape(self, input_shape):
filed_size = len(input_shape)
embedding_size = input_shape[0][-1]
return (None, filed_size * (filed_size - 1) // 2, embedding_size)
def get_config(self, ):
config = {'bilinear_type': self.bilinear_type, 'seed': self.seed}
base_config = super(BilinearInteraction, self).get_config()
base_config.update(config)
return base_config
Bi-FFM实现核心部分就如上了,下面就来看看Bi-FFM的模型搭建,整个代码框架参照了开源deepctr包,有些code组件依据需要做了改动,下面就来动动手撸一遍吧。
为了更好地演示Bi-FFM模型完整的搭建及训练,这里拟造部分我们真实场景所用数据,如下:

字段介绍:
label:为label数据 1:正样本,0:负样本
client_id: 用户id
c_follow_topic_id:该物料所属话题,是否为用户用户关注话题,是:1,否:0
c_topic_id_ctr:该物料所属话题,对用户三天内对该话题的ctr
follow_topic_id: 用户关注话题分类id
exposure_hourdiff: 物料曝光时帖子距创建时的小时数
topic_id: 物料所属的话题
relpy: 物料曝光是的回复数
share: 物料曝光是的分享数
keyword: 物料item对应关键词id
topic_id_ctr:用户三天内不同话题的ctr
import numpy as np
import pandas as pd
import datetime
import itertools
import tensorflow as tf
from tensorflow.keras.layers import *
import tensorflow.keras.backend as K
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.python.keras.initializers import Zeros, glorot_normal,glorot_uniform, TruncatedNormal
from collections import namedtuple, OrderedDict
########################################################################
#################数据预处理##############
########################################################################
# 定义参数类型
SparseFeat = namedtuple('SparseFeat', ['name', 'voc_size', 'hash_size', 'vocab','share_embed','embed_dim', 'dtype'])
DenseFeat = namedtuple('DenseFeat', ['name', 'pre_embed','reduce_type','dim', 'dtype'])
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'voc_size','hash_size', 'vocab', 'share_embed', 'weight_name', 'combiner', 'embed_dim','maxlen', 'dtype'])
valid_keyword = pd.read_csv('/opt/data/keyword_freq.csv',sep='\t')
valid_keyword = valid_keyword[valid_keyword.cnt >3]
print(len(valid_keyword))
# 筛选实体标签categorical 用于定义映射关系
CATEGORICAL_MAP = {
"keyword": valid_keyword.keyword_tag.unique().tolist(),
}
feature_columns = [DenseFeat(name='c_topic_id_ctr', pre_embed=None,reduce_type=None, dim=1, dtype="float32"),
SparseFeat(name="c_follow_topic_id", voc_size=2, hash_size= None, vocab=None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name="exposure_hourdiff", voc_size=6, hash_size= None, vocab=None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name="reply", voc_size=6, hash_size= None, vocab=None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name="share", voc_size=6, hash_size= None, vocab=None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name='topic_id', voc_size=720, hash_size= None, vocab=None,share_embed=None, embed_dim=8,dtype='int32'),
SparseFeat(name='exposure_hour', voc_size=25, hash_size= None, vocab=None,share_embed=None, embed_dim=8,dtype='int32'),
VarLenSparseFeat(name="follow_topic_id", voc_size=720, hash_size= None, vocab=None, share_embed='topic_id', weight_name = None, combiner= 'sum', embed_dim=8, maxlen=20,dtype='int32'),
VarLenSparseFeat(name="keyword", voc_size=21500, hash_size= None, vocab='keyword', share_embed=None, weight_name = None, combiner= 'sum', embed_dim=8, maxlen=5,dtype='int32'),
VarLenSparseFeat(name="topic_id_ctr", voc_size=720, hash_size= None, vocab=None, share_embed='topic_id', weight_name = 'topic_id_ctr_weight', combiner= 'sum', embed_dim=8, maxlen=5,dtype='int32'),
]
# 用户特征及贴子特征
linear_feature_columns_name = ['c_follow_topic_id', 'exposure_hourdiff', 'c_topic_id_ctr',]
bilinear_feature_columns_name = ["topic_id", 'exposure_hour','reply' , 'share', 'keyword', 'follow_topic_id', 'topic_id_ctr']
linear_feature_columns = [col for col in feature_columns if col.name in linear_feature_columns_name ]
bilinear_feature_columns = [col for col in feature_columns if col.name in bilinear_feature_columns_name ]
bucket_dict = {
'exposure_hourdiff': [3, 7, 15, 33],
'reply': [12, 30, 63, 136],
'share': [2, 11],
}
DEFAULT_VALUES = [[0],[''],[0],[0], [0.0],
[0], [0],[0],[0], ['0'], ['0'],['0:0']]
COL_NAME = ['label', 'client_id', 'c_follow_topic_id', 'exposure_hourdiff', 'c_topic_id_ctr',
"topic_id", 'exposure_hour','reply' , 'share', 'keyword', 'follow_topic_id', 'topic_id_ctr']
def _parse_function(example_proto):
item_feats = tf.io.decode_csv(example_proto, record_defaults=DEFAULT_VALUES, field_delim='\t')
parsed = dict(zip(COL_NAME, item_feats))
feature_dict = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
if feat_col.weight_name is not None:
kvpairs = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
kvpairs = tf.strings.split(kvpairs, ':')
kvpairs = kvpairs.to_tensor()
feat_ids, feat_vals = tf.split(kvpairs, num_or_size_splits=2, axis=1)
feat_ids = tf.reshape(feat_ids, shape=[-1])
feat_vals = tf.reshape(feat_vals, shape=[-1])
if feat_col.dtype != 'string':
feat_ids= tf.strings.to_number(feat_ids, out_type=tf.int32)
feat_vals= tf.strings.to_number(feat_vals, out_type=tf.float32)
feature_dict[feat_col.name] = feat_ids
feature_dict[feat_col.weight_name] = feat_vals
else:
feat_ids = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
feat_ids = tf.reshape(feat_ids, shape=[-1])
if feat_col.dtype != 'string':
feat_ids= tf.strings.to_number(feat_ids, out_type=tf.int32)
feature_dict[feat_col.name] = feat_ids
elif isinstance(feat_col, SparseFeat):
feature_dict[feat_col.name] = parsed[feat_col.name]
elif isinstance(feat_col, DenseFeat):
if not feat_col.pre_embed:
feature_dict[feat_col.name] = parsed[feat_col.name]
elif feat_col.reduce_type is not None:
keys = tf.strings.split(parsed[feat_col.pre_embed], ',')
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(keys))
emb = tf.reduce_mean(emb,axis=0) if feat_col.reduce_type == 'mean' else tf.reduce_sum(emb,axis=0)
feature_dict[feat_col.name] = emb
else:
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(parsed[feat_col.pre_embed]))
feature_dict[feat_col.name] = emb
else:
raise "unknown feature_columns...."
# 分桶离散化
for ft in bucket_dict:
feature_dict[ft] = tf.raw_ops.Bucketize(
input=feature_dict[ft],
boundaries=bucket_dict[ft])
label = parsed['label']
return feature_dict, label
pad_shapes = {}
pad_values = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
max_tokens = feat_col.maxlen
pad_shapes[feat_col.name] = tf.TensorShape([max_tokens])
pad_values[feat_col.name] = '-1' if feat_col.dtype == 'string' else -1
if feat_col.weight_name is not None:
pad_shapes[feat_col.weight_name] = tf.TensorShape([max_tokens])
pad_values[feat_col.weight_name] = tf.constant(-1, dtype=tf.float32)
# no need to pad labels
elif isinstance(feat_col, SparseFeat):
pad_values[feat_col.name] = '-1' if feat_col.dtype == 'string' else -1
pad_shapes[feat_col.name] = tf.TensorShape([])
elif isinstance(feat_col, DenseFeat):
if not feat_col.pre_embed:
pad_shapes[feat_col.name] = tf.TensorShape([])
else:
pad_shapes[feat_col.name] = tf.TensorShape([feat_col.dim])
pad_values[feat_col.name] = 0.0
pad_shapes = (pad_shapes, (tf.TensorShape([])))
pad_values = (pad_values, (tf.constant(0, dtype=tf.int32)))
filenames= tf.data.Dataset.list_files([
'./user_item_act_test.csv'
])
dataset = filenames.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
batch_size = 10
dataset = dataset.map(_parse_function, num_parallel_calls=50)
dataset = dataset.repeat()
dataset = dataset.shuffle(buffer_size = batch_size) # 在缓冲区中随机打乱数据
dataset = dataset.padded_batch(batch_size = batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 验证集
filenames_val= tf.data.Dataset.list_files(['./user_item_act_test_val.csv'])
dataset_val = filenames_val.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
val_batch_size = 1024
dataset_val = dataset_val.map(_parse_function, num_parallel_calls=50)
dataset_val = dataset_val.padded_batch(batch_size = val_batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset_val = dataset_val.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
########################################################################
#################自定义Layer##############
########################################################################
# 多值查找表稀疏SparseTensor >> EncodeMultiEmbedding
class VocabLayer(Layer):
def __init__(self, keys, mask_value=None, **kwargs):
super(VocabLayer, self).__init__(**kwargs)
self.mask_value = mask_value
vals = tf.range(2, len(keys) + 2)
vals = tf.constant(vals, dtype=tf.int32)
keys = tf.constant(keys)
self.table = tf.lookup.StaticHashTable(
tf.lookup.KeyValueTensorInitializer(keys, vals), 1)
def call(self, inputs):
idx = self.table.lookup(inputs)
if self.mask_value is not None:
masks = tf.not_equal(inputs, self.mask_value)
paddings = tf.ones_like(idx) * (-1) # mask成 -1
idx = tf.where(masks, idx, paddings)
return idx
def get_config(self):
config = super(VocabLayer, self).get_config()
config.update({'mask_value': self.mask_value, })
return config
class EmbeddingLookupSparse(Layer):
def __init__(self, embedding, has_weight=False, combiner='sum',**kwargs):
super(EmbeddingLookupSparse, self).__init__(**kwargs)
self.has_weight = has_weight
self.combiner = combiner
self.embedding = embedding
def build(self, input_shape):
super(EmbeddingLookupSparse, self).build(input_shape)
def call(self, inputs):
if self.has_weight:
idx, val = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=val, combiner=self.combiner)
else:
idx = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=None, combiner=self.combiner)
return tf.expand_dims(combiner_embed, 1)
def get_config(self):
config = super(EmbeddingLookupSparse, self).get_config()
config.update({'has_weight': self.has_weight, 'combiner':self.combiner})
return config
class EmbeddingLookup(Layer):
def __init__(self, embedding, **kwargs):
super(EmbeddingLookup, self).__init__(**kwargs)
self.embedding = embedding
def build(self, input_shape):
super(EmbeddingLookup, self).build(input_shape)
def call(self, inputs):
idx = tf.cast(inputs, tf.int32)
embed = tf.nn.embedding_lookup(params=self.embedding, ids=idx)
return embed
def get_config(self):
config = super(EmbeddingLookup, self).get_config()
return config
# 稠密转稀疏
class DenseToSparseTensor(Layer):
def __init__(self, mask_value= -1, **kwargs):
super(DenseToSparseTensor, self).__init__()
self.mask_value = mask_value
def call(self, dense_tensor):
idx = tf.where(tf.not_equal(dense_tensor, tf.constant(self.mask_value , dtype=dense_tensor.dtype)))
sparse_tensor = tf.SparseTensor(idx, tf.gather_nd(dense_tensor, idx), tf.shape(dense_tensor, out_type=tf.int64))
return sparse_tensor
def get_config(self):
config = super(DenseToSparseTensor, self).get_config()
config.update({'mask_value': self.mask_value})
return config
class HashLayer(Layer):
"""
hash the input to [0,num_buckets)
if mask_zero = True,0 or 0.0 will be set to 0,other value will be set in range[1,num_buckets)
"""
def __init__(self, num_buckets, mask_zero=False, **kwargs):
self.num_buckets = num_buckets
self.mask_zero = mask_zero
super(HashLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
super(HashLayer, self).build(input_shape)
def call(self, x, mask=None, **kwargs):
if x.dtype != tf.string:
zero = tf.as_string(tf.ones([1], dtype=x.dtype)*(-1))
x = tf.as_string(x, )
else:
zero = tf.as_string(tf.ones([1], dtype=x.dtype)*(-1))
num_buckets = self.num_buckets if not self.mask_zero else self.num_buckets - 1
hash_x = tf.strings.to_hash_bucket_fast(x, num_buckets, name=None)
if self.mask_zero:
# mask = tf.cast(tf.not_equal(x, zero), dtype='int64')
masks = tf.not_equal(x, zero)
paddings = tf.ones_like(hash_x) * (-1) # mask成 -1
hash_x = tf.where(masks, hash_x, paddings)
# hash_x = (hash_x + 1) * mask
return hash_x
def get_config(self, ):
config = super(HashLayer, self).get_config()
config.update({'num_buckets': self.num_buckets, 'mask_zero': self.mask_zero, })
return config
class Add(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super(Add, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
super(Add, self).build(input_shape)
def call(self, inputs, **kwargs):
if not isinstance(inputs,list):
return inputs
if len(inputs) == 1 :
return inputs[0]
if len(inputs) == 0:
return tf.constant([[0.0]])
return tf.keras.layers.add(inputs)
class BilinearInteraction(Layer):
"""BilinearInteraction Layer used in FiBiNET.
Input shape
- A list of 3D tensor with shape: ``(batch_size,1,embedding_size)``. Its length is ``filed_size``.
Output shape
- 3D tensor with shape: ``(batch_size,filed_size*(filed_size-1)/2,embedding_size)``.
Arguments
- **bilinear_type** : String, types of bilinear functions used in this layer.
- **seed** : A Python integer to use as random seed.
References
- [FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction](https://arxiv.org/pdf/1905.09433.pdf)
"""
def __init__(self, bilinear_type="interaction", seed=1024, **kwargs):
self.bilinear_type = bilinear_type
self.seed = seed
super(BilinearInteraction, self).__init__(**kwargs)
def build(self, input_shape):
if not isinstance(input_shape, list) or len(input_shape) < 2:
raise ValueError('A `BilinearInteraction` layer should be called '
'on a list of at least 2 inputs')
embedding_size = int(input_shape[0][-1])
if self.bilinear_type == "all":
self.W = self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight")
elif self.bilinear_type == "each":
self.W_list = [self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight" + str(i)) for i in range(len(input_shape) - 1)]
elif self.bilinear_type == "interaction":
self.W_list = [self.add_weight(shape=(embedding_size, embedding_size), initializer=glorot_normal(
seed=self.seed), name="bilinear_weight" + str(i) + '_' + str(j)) for i, j in
itertools.combinations(range(len(input_shape)), 2)]
else:
raise NotImplementedError
super(BilinearInteraction, self).build(
input_shape) # Be sure to call this somewhere!
def call(self, inputs, **kwargs):
if K.ndim(inputs[0]) != 3:
raise ValueError(
"Unexpected inputs dimensions %d, expect to be 3 dimensions" % (K.ndim(inputs)))
n = len(inputs)
if self.bilinear_type == "all":
vidots = [tf.tensordot(inputs[i], self.W, axes=(-1, 0)) for i in range(n)]
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)]
elif self.bilinear_type == "each":
vidots = [tf.tensordot(inputs[i], self.W_list[i], axes=(-1, 0)) for i in range(n - 1)]
p = [tf.multiply(vidots[i], inputs[j]) for i, j in itertools.combinations(range(n), 2)]
elif self.bilinear_type == "interaction":
p = [tf.multiply(tf.tensordot(v[0], w, axes=(-1, 0)), v[1])
for v, w in zip(itertools.combinations(inputs, 2), self.W_list)]
else:
raise "NotImplementedError"
output = concat_func(p, axis=1)
return output
def compute_output_shape(self, input_shape):
filed_size = len(input_shape)
embedding_size = input_shape[0][-1]
return (None, filed_size * (filed_size - 1) // 2, embedding_size)
def get_config(self, ):
config = {'bilinear_type': self.bilinear_type, 'seed': self.seed}
base_config = super(BilinearInteraction, self).get_config()
base_config.update(config)
return base_config
########################################################################
#################定义输入帮助函数##############
########################################################################
# 定义model输入特征
def build_input_features(features_columns, prefix=''):
input_features = OrderedDict()
for feat_col in features_columns:
if isinstance(feat_col, DenseFeat):
input_features[feat_col.name] = Input([feat_col.dim], name=feat_col.name)
elif isinstance(feat_col, SparseFeat):
input_features[feat_col.name] = Input([1], name=feat_col.name, dtype=feat_col.dtype)
elif isinstance(feat_col, VarLenSparseFeat):
input_features[feat_col.name] = Input([None], name=feat_col.name, dtype=feat_col.dtype)
if feat_col.weight_name is not None:
input_features[feat_col.weight_name] = Input([None], name=feat_col.weight_name, dtype='float32')
else:
raise TypeError("Invalid feature column in build_input_features: {}".format(feat_col.name))
return input_features
# 构造 自定义embedding层 matrix
def build_embedding_matrix(features_columns, linear_dim=None):
embedding_matrix = {}
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat) or isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
vocab_size = feat_col.voc_size + 2
embed_dim = feat_col.embed_dim if linear_dim is None else 1
name_tag = '' if linear_dim is None else '_linear'
if vocab_name not in embedding_matrix:
embedding_matrix[vocab_name] = tf.Variable(initial_value=tf.random.truncated_normal(shape=(vocab_size, embed_dim),mean=0.0,
stddev=0.001, dtype=tf.float32), trainable=True, name=vocab_name+'_embed'+name_tag)
return embedding_matrix
# 构造 自定义embedding层
def build_embedding_dict(features_columns):
embedding_dict = {}
embedding_matrix = build_embedding_matrix(features_columns)
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name)
elif isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
if feat_col.combiner is not None:
if feat_col.weight_name is not None:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name],combiner=feat_col.combiner, has_weight=True, name='emb_lookup_sparse_' + feat_col.name)
else:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name], combiner=feat_col.combiner, name='emb_lookup_sparse_' + feat_col.name)
else:
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name)
return embedding_dict
# 构造 自定义embedding层
def build_linear_embedding_dict(features_columns):
embedding_dict = {}
embedding_matrix = build_embedding_matrix(features_columns, linear_dim=1)
name_tag = '_linear'
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name+name_tag)
elif isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
if feat_col.combiner is not None:
if feat_col.weight_name is not None:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name],combiner=feat_col.combiner, has_weight=True, name='emb_lookup_sparse_' + feat_col.name +name_tag)
else:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name], combiner=feat_col.combiner, name='emb_lookup_sparse_' + feat_col.name+name_tag)
else:
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name+name_tag)
return embedding_dict
# dense 与 embedding特征输入
def input_from_feature_columns(features, features_columns, embedding_dict, cate_map=CATEGORICAL_MAP):
sparse_embedding_list = []
dense_value_list = []
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
_input = features[feat_col.name]
if feat_col.vocab is not None:
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
keys = cate_map[vocab_name]
_input = VocabLayer(keys)(_input)
elif feat_col.hash_size is not None:
_input = HashLayer(num_buckets=feat_col.hash_size, mask_zero=False)(_input)
embed = embedding_dict[feat_col.name](_input)
sparse_embedding_list.append(embed)
elif isinstance(feat_col, VarLenSparseFeat):
_input = features[feat_col.name]
if feat_col.vocab is not None:
mask_val = '-1' if feat_col.dtype == 'string' else -1
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
keys = cate_map[vocab_name]
_input = VocabLayer(keys, mask_value= mask_val)(_input)
elif feat_col.hash_size is not None:
_input = HashLayer(num_buckets=feat_col.hash_size, mask_zero=True)(_input)
if feat_col.combiner is not None:
input_sparse = DenseToSparseTensor(mask_value=-1)(_input)
if feat_col.weight_name is not None:
weight_sparse = DenseToSparseTensor()(features[feat_col.weight_name])
embed = embedding_dict[feat_col.name]([input_sparse, weight_sparse])
else:
embed = embedding_dict[feat_col.name](input_sparse)
else:
embed = embedding_dict[feat_col.name](_input)
sparse_embedding_list.append(embed)
elif isinstance(feat_col, DenseFeat):
dense_value_list.append(features[feat_col.name])
else:
raise TypeError("Invalid feature column in input_from_feature_columns: {}".format(feat_col.name))
return sparse_embedding_list, dense_value_list
def concat_func(inputs, axis=-1):
if len(inputs) == 1:
return inputs[0]
else:
return Concatenate(axis=axis)(inputs)
def combined_dnn_input(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_dnn_input = Flatten()(concat_func(sparse_embedding_list))
dense_dnn_input = Flatten()(concat_func(dense_value_list))
return concat_func([sparse_dnn_input, dense_dnn_input])
elif len(sparse_embedding_list) > 0:
return Flatten()(concat_func(sparse_embedding_list))
elif len(dense_value_list) > 0:
return Flatten()(concat_func(dense_value_list))
else:
raise "dnn_feature_columns can not be empty list"
def get_linear_logit(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten()(sparse_linear_layer)
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1)(dense_linear)
linear_logit = Add(name='linear_logit')([dense_linear_layer, sparse_linear_layer])
return linear_logit
elif len(sparse_embedding_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten(name='linear_logit')(sparse_linear_layer)
return sparse_linear_layer
elif len(dense_value_list) > 0:
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1, name='linear_logit')(dense_linear)
return dense_linear_layer
else:
raise "linear_feature_columns can not be empty list"
########################################################################
#################定义模型##############
########################################################################
def BilinearFFM(
linear_feature_columns,
bilinear_feature_columns,
bilinear_type='interaction',
seed=1024):
"""
Instantiates the BilinearFFM Learning architecture.
Args:
linear_feature_columns: An iterable containing all the features used by linear part of the model.
dnn_feature_columns: An iterable containing all the features used by deep part of the model.
bilinear_type: str,bilinear function type used in Bilinear Interaction Layer,can be ``'all'`` , ``'each'`` or ``'interaction'``
seed: integer ,to use as random seed.
return: A TF Keras model instance.
"""
features_columns = linear_feature_columns + bilinear_feature_columns
# 特征处理
features = build_input_features(feature_columns)
inputs_list = list(features.values())
# 构建 linear embedding_dict
linear_embedding_dict = build_linear_embedding_dict(linear_feature_columns)
linear_sparse_embedding_list, linear_dense_value_list = input_from_feature_columns(features, linear_feature_columns, linear_embedding_dict)
# linear part
linear_logit = get_linear_logit(linear_sparse_embedding_list, linear_dense_value_list)
# 构建 BI-FFM embedding_dict
bilinear_embedding_dict = build_embedding_dict(bilinear_feature_columns)
bilinear_sparse_embedding_list, _ = input_from_feature_columns(features, bilinear_feature_columns, bilinear_embedding_dict)
bilinear_out = BilinearInteraction( bilinear_type=bilinear_type, seed=seed)(bilinear_sparse_embedding_list)
bilinear_dot = Lambda(lambda x: K.sum(x, axis=-1), name='bilinear_dot')(bilinear_out) # ?, filed_size * (filed_size - 1) // 2
bilinear_logit = Lambda(lambda x: K.sum(x, axis=-1), name='bilinear_logit')(bilinear_dot) # ?, 1
final_logit = Add()([bilinear_logit, linear_logit])
output = tf.keras.layers.Activation("sigmoid", name="BilinearFFM")(final_logit)
model = Model(inputs=inputs_list, outputs=output)
return model
########################################################################
#################模型训练##############
########################################################################
model = BilinearFFM(linear_feature_columns, bilinear_feature_columns, bilinear_type='interaction', seed=1024)
model.compile(optimizer="adam", loss= "binary_crossentropy", metrics=tf.keras.metrics.AUC(name='auc'))
log_dir = '/mywork/tensorboardshare/logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tbCallBack = TensorBoard(log_dir=log_dir, # log 目录
histogram_freq=0, # 按照何等频率(epoch)来计算直方图,0为不计算
write_graph=True, # 是否存储网络结构图
write_images=True,# 是否可视化参数
update_freq='epoch',
embeddings_freq=0,
embeddings_layer_names=None,
embeddings_metadata=None,
profile_batch = 20)
total_train_sample = 100
total_test_sample = 100
train_steps_per_epoch=np.floor(total_train_sample/batch_size).astype(np.int32)
test_steps_per_epoch = np.ceil(total_test_sample/val_batch_size).astype(np.int32)
history_loss = model.fit(dataset, epochs=3,
steps_per_epoch=train_steps_per_epoch,
validation_data=dataset_val, validation_steps=test_steps_per_epoch,
verbose=1,callbacks=[tbCallBack])
Bi-FFM搭建模型的整体代码就如上了,感兴趣的同学可以copy代码跑跑,动手才是王道,下面我们看看上述code搭建的模型结构

参考文献
张俊林:FFM及DeepFFM模型在推荐系统的探索
梦醒潇湘:[FFM学习] 美团深度FFM原理与实践
FM/FFM
安超杰:FFM简介及实践
王多鱼:FFM算法原理及Bi-FFM算法实现
基于Tensorflow实现FFM_leadai的博客-CSDN博客_ffm tensorflow
FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
shenweichen/DeepCTR

