
GitHub源码分享
微信搜索:码农StayUp
主页地址:https://gozhuyinglong.github.io
源码分享:https://github.com/gozhuyinglong/blog-demos
1. 前言
在网站建设中一般会用到全国行政区域划分,以便于做区域数据分析。
下面我们用 Python 来爬取行政区域数据,数据来源为比较权威的国家统计局。爬取的页面为2020年统计用区划代码和城乡划分代码。
这里有个疑问,为啥统计局只提供了网页版呢?提供文件版岂不是更方便大众。欢迎了解的小伙伴给我留言。
2. 网站分析
在爬取数据之前要做的便是网站分析,通过分析来判断使用何种方式来爬取。
2.1 省份页面
一个静态页面,其二级页面使用的是相对地址,通过 class=provincetr 的tr元素来定位

2.2 城市页面
一个静态页面,其二级页面使用的是相对地址,通过 class=citytr 的tr元素来定位
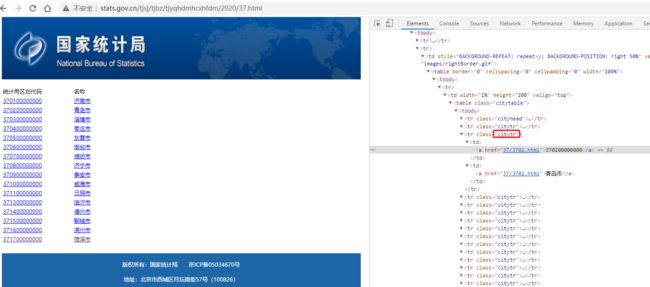
2.3 区县页面
一个静态页面,其二级页面使用的是相对地址,通过 class=countytr 的tr元素来定位

2.4 城镇页面
一个静态页面,其二级页面使用的是相对地址,通过 class=towntr 的tr元素来定位
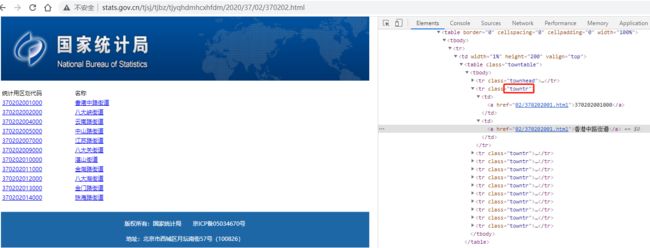
2.5 村庄页面
一个静态页面,没有二级页面,通过 class=villagetr 的tr元素来定位
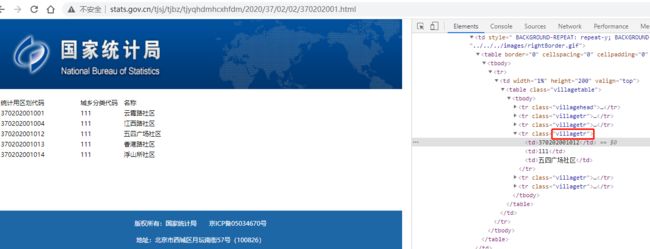
3. 安装所需库
通过上面的分析,使用爬取静态网页的方式即可。下面是一些必要的库,需要提前安装好:Requests、BeautifulSoup、lxml。
3.1 Requests
Requests 是一个 Python 的 HTTP 客户端库,用于访问 URL 网络资源。
安装Requests库:
pip install requests
3.2 BeautifulSoup
Beautifu lSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库。它能够通过指定的转换器实现页面文档的导航、查找、修改等。
安装 BeautifulSoup 库:
pip install beautifulsoup4
3.3 lxml
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML 和 HTML。
它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
安装lxml库:
pip install lxml
4. 代码实现
爬虫分以下几步:
- 使用Requests库来获取网页。
- 使用BeautifulSoup和lxml库解析网页。
- 使用Python的File来存储数据。
输出文件为:当前py文件所在目录,文件名称:area-number-2020.txt
输出结果为:级别、区划代码、名称,中间使用制表符分隔,便于存到Exce和数据库中。
下面看详细代码:
# -*-coding:utf-8-*-
import requests
from bs4 import BeautifulSoup
# 根据地址获取页面内容,并返回BeautifulSoup
def get_html(url):
# 若页面打开失败,则无限重试,没有后退可言
while True:
try:
# 超时时间为1秒
response = requests.get(url, timeout=1)
response.encoding = "GBK"
if response.status_code == 200:
return BeautifulSoup(response.text, "lxml")
else:
continue
except Exception:
continue
# 获取地址前缀(用于相对地址)
def get_prefix(url):
return url[0:url.rindex("/") + 1]
# 递归抓取下一页面
def spider_next(url, lev):
if lev == 2:
spider_class = "city"
elif lev == 3:
spider_class = "county"
elif lev == 4:
spider_class = "town"
else:
spider_class = "village"
for item in get_html(url).select("tr." + spider_class + "tr"):
item_td = item.select("td")
item_td_code = item_td[0].select_one("a")
item_td_name = item_td[1].select_one("a")
if item_td_code is None:
item_href = None
item_code = item_td[0].text
item_name = item_td[1].text
if lev == 5:
item_name = item_td[2].text
else:
item_href = item_td_code.get("href")
item_code = item_td_code.text
item_name = item_td_name.text
# 输出:级别、区划代码、名称
content2 = str(lev) + "\t" + item_code + "\t" + item_name
print(content2)
f.write(content2 + "\n")
if item_href is not None:
spider_next(get_prefix(url) + item_href, lev + 1)
# 入口
if __name__ == '__main__':
# 抓取省份页面
province_url = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2020/index.html"
province_list = get_html(province_url).select('tr.provincetr a')
# 数据写入到当前文件夹下 area-number-2020.txt 中
f = open("area-number-2020.txt", "w", encoding="utf-8")
try:
for province in province_list:
href = province.get("href")
province_code = href[0: 2] + "0000000000"
province_name = province.text
# 输出:级别、区划代码、名称
content = "1\t" + province_code + "\t" + province_name
print(content)
f.write(content + "\n")
spider_next(get_prefix(province_url) + href, 2)
finally:
f.close()
5. 资源下载
如果你只是需要行政区域数据,那么已经为你准备好了,从下面连接中下载即可。
链接:https://pan.baidu.com/s/18MDdkczwJVuRZwsH0pFYwQ
提取码:t2eg
6. 爬虫遵循的规则
引自:https://www.cnblogs.com/kongyijilafumi/p/13969361.html
- 遵守 Robots 协议,谨慎爬取
- 限制你的爬虫行为,禁止近乎 DDOS 的请求频率,一旦造成服务器瘫痪,约等于网络攻击
- 对于明显反爬,或者正常情况不能到达的页面不能强行突破,否则是 Hacker 行为
- 如果爬取到别人的隐私,立即删除,降低进局子的概率。另外要控制自己的欲望