我是用
ubuntu 18.x.x作为基础镜像,日后我会整理出一个Dockerfile
制作 hadoop 集群的基础镜像
# 拉取 ubuntu 镜像
docker pull ubuntu
# 生成一个容器
# --name 给容器命名
# -v 挂载宿主机路径
docker run -itd --name hadoop-base -v /Users/zhangbo/Documents/docker_hadoop_data_base:/home/novadeep ubuntu
# 进入该容器
docker exec -it hadoop-base /bin/bash
# 安装所需软件包
apt-get update
apt-get install vim
apt install net-tools
apt-get install iputils-ping
apt-get install openssh-server
- 在宿主机上下载 jdk 与 hadoop,然后放到容器与之对应的宿主文件夹下
hadoop-3.2.0.tar.gz
jdk-8u201-linux-x64.tar.gz
# 解压
tar -zxvf hadoop-3.2.0.tar.gz
tar -zxvf jdk-8u201-linux-x64.tar.gz
# 进入 .bashrc 中配置 java 及 hadoop 环境变量
vim ~/.bashrc
export JAVA_HOME=/home/novadeep/jdk1.8.0_201
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/novadeep/hadoop-3.2.0
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 退出 .bashrc 文件后,刷新环境变量
source ~/.bashrc
- 制作
ssh免密登录
# 生成密钥
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 查看本地 host
cat /etc/hosts
ssh your_local_ip
# 退出容器
exit
- 至此
hadoop集群容器做作完成
# 把该容器提交成镜像
docker commit hadoop-base hadoop-base
# 查看刚提交的镜像
...MacBook-Pro:/ zhangbo$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hadoop-base latest eb27091630dd 25 hours ago 265MB
编辑 hadoop 的配置文件
这里需要编辑7个配置文件
hadoop-env.sh | yarn-env.sh | core-site.xml | hdfs-site.xml | yarn-site.xml | mapred-site.xml | workers
注意老版本中workers被叫做slaves由于某种原因你们懂得,新版本中被改成了workers
-
hadoop-env.sh添加以下内容
export JAVA_HOME=/home/novadeep/jdk1.8.0_201
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
-
yarn-env.sh添加以下内容
export JAVA_HOME=/home/novadeep/jdk1.8.0_201
core-site.xml
fs.default.name
hdfs://master:9000
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/home/novadeep/tmp
hdfs-site.xml
dfs.namenode.name.dir
file:/home/novadeep/hdfs/name
dfs.datanode.data.dir
file:/home/novadeep/hdfs/data
dfs.replication
2
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
staff
dfs.permissions.enabled
false
yarn-site.xml
yarn.resourcemanager.hostname
master
yarn resourcemanager hostname is master
yarn.nodemanager.aux-services
mapreduce_shuffle
just mapreduce_shuffle can run MapReduce
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce's framework is yarm
-
workers把localhost删掉,添加以下内容。这里面添加的就是worker的host,下面会说到
node1
node2
node3
使用 docker 模拟 hadoop 集群
- 1主3从的配置
| ip | host name |
|---|---|
| 172.17.0.2 | master |
| 172.17.0.3 | node1 |
| 172.17.0.4 | node2 |
| 172.17.0.5 | node3 |
- 在 docker 中开启容器,注意与之对应的宿主文件夹。把
hadoop-3.2.0、jdk1.8.0_201先复制到node123中
主节点与从节点文件夹
# 启动容器
docker run -itd --name hadoop-master \
-v /Users/zhangbo/Documents/docker_hadoop_data_base:/home/novadeep \
-p 50070:50070 \
-p 9000:9000 \
-p 9870:9870 \
-p 9864:9864 \
-p 9866:9866 \
-p 9867:9867 \
-p 9868:9868 \
-p 8485:8485 \
-p 8480:8480 \
-p 50200:50200 \
-p 10020:10020 \
-p 19888:19888 \
-p 10033:10033 \
-p 8032:8032 \
-p 8030:8030 \
-p 8088:8088 \
-p 8031:8031 \
-p 8033:8033 \
-p 8040:8040 \
-p 8048:8048 \
-p 8042:8042 \
-p 10200:10200 \
-p 8188:8188 \
-p 8047:8047 \
-p 8788:8788 \
-p 8046:8046 \
-p 8045:8045 \
-p 8049:8049 \
-p 8089:8089 \
-p 9871:9871 \
-p 9865:9865 \
-p 8481:8481 \
-p 19890:19890 \
-p 8044:8044 \
-p 8190:8190 \
-p 8091:8091 \
-h master \
--add-host node1:172.17.0.3 \
--add-host node2:172.17.0.4 \
--add-host node3:172.17.0.5 \
hadoop-base /bin/bash -c "service ssh start&&/bin/bash"
docker run -itd --name hadoop-node1 \
-v /Users/zhangbo/Documents/docker_hadoop_data_base/node1:/home/novadeep \
-p 50070 \
-p 9000 \
-p 9870 \
-p 9864 \
-p 9866 \
-p 9867 \
-p 9868 \
-p 8485 \
-p 8480 \
-p 50200 \
-p 10020 \
-p 19888 \
-p 10033 \
-p 8032 \
-p 8030 \
-p 8088 \
-p 8031 \
-p 8033 \
-p 8040 \
-p 8048 \
-p 8042 \
-p 10200 \
-p 8188 \
-p 8047 \
-p 8788 \
-p 8046 \
-p 8045 \
-p 8049 \
-p 8089 \
-p 9871 \
-p 9865 \
-p 8481 \
-p 19890 \
-p 8044 \
-p 8190 \
-p 8091 \
--add-host master:172.17.0.2 \
-h node1 hadoop-base /bin/bash -c "service ssh start&&/bin/bash"
docker run -itd --name hadoop-node2 \
-v /Users/zhangbo/Documents/docker_hadoop_data_base/node2:/home/novadeep \
-p 50070 \
-p 9000 \
-p 9870 \
-p 9864 \
-p 9866 \
-p 9867 \
-p 9868 \
-p 8485 \
-p 8480 \
-p 50200 \
-p 10020 \
-p 19888 \
-p 10033 \
-p 8032 \
-p 8030 \
-p 8088 \
-p 8031 \
-p 8033 \
-p 8040 \
-p 8048 \
-p 8042 \
-p 10200 \
-p 8188 \
-p 8047 \
-p 8788 \
-p 8046 \
-p 8045 \
-p 8049 \
-p 8089 \
-p 9871 \
-p 9865 \
-p 8481 \
-p 19890 \
-p 8044 \
-p 8190 \
-p 8091 \
--add-host master:172.17.0.2 \
-h node2 hadoop-base /bin/bash -c "service ssh start&&/bin/bash"
docker run -itd --name hadoop-node3 \
-v /Users/zhangbo/Documents/docker_hadoop_data_base/node3:/home/novadeep \
-p 50070 \
-p 9000 \
-p 9870 \
-p 9864 \
-p 9866 \
-p 9867 \
-p 9868 \
-p 8485 \
-p 8480 \
-p 50200 \
-p 10020 \
-p 19888 \
-p 10033 \
-p 8032 \
-p 8030 \
-p 8088 \
-p 8031 \
-p 8033 \
-p 8040 \
-p 8048 \
-p 8042 \
-p 10200 \
-p 8188 \
-p 8047 \
-p 8788 \
-p 8046 \
-p 8045 \
-p 8049 \
-p 8089 \
-p 9871 \
-p 9865 \
-p 8481 \
-p 19890 \
-p 8044 \
-p 8190 \
-p 8091 \
--add-host master:172.17.0.2 \
-h node3 hadoop-base /bin/bash -c "service ssh start&&/bin/bash"
- 启动后查看已启动的容器,由于默认的
docker ps会有端口列,上面的容器开启的端口太多会妨碍查看。所以我们使用--format选项,来重新规定展示内容
# 使用 --format 来重新规定展示内容
docker ps --format "{{.ID}} : {{.Image}} : {{.Command}} : {{.Status}} : {{.Names}} : {{.Networks}}"
8c62fa26c36b : hadoop-base : "/bin/bash" : Up 2 hours : hadoop-node3 : bridge
ebaf47e07b28 : hadoop-base : "/bin/bash" : Up 2 hours : hadoop-node2 : bridge
10c0f49daa0f : hadoop-base : "/bin/bash" : Up 2 hours : hadoop-node1 : bridge
40816b388966 : hadoop-base : "/bin/bash" : Up 2 hours : hadoop-master : bridge
# --format 选项可以定义的列描述
Placeholder Description
.ID Container ID
.Image Image ID
.Command Quoted command
.CreatedAt Time when the container was created.
.RunningFor Elapsed time since the container was started.
.Ports Exposed ports.
.Status Container status.
.Size Container disk size.
.Names Container names.
.Labels All labels assigned to the container.
.Label Value of a specific label for this container. For example '{{.Label "com.docker.swarm.cpu"}}'
.Mounts Names of the volumes mounted in this container.
.Networks Names of the networks attached to this container.
- 至此 hadoop 集群的容器启动完成,接下来开始做最后的工作。
最后的工作
- 启动 hadoop 集群
# 第一次启动前,需要执行 namenode format
hadoop namenode -format
# 启动 hadoop 集群
start-all.sh
# 查看启动节点
root@master:/# jps -l
609 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
341 org.apache.hadoop.hdfs.server.namenode.NameNode
873 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
1545 sun.tools.jps.Jps
# ssh 到 node1
ssh root@node1
# 查看启动节点
root@node1:~# jps -l
241 org.apache.hadoop.yarn.server.nodemanager.NodeManager
117 org.apache.hadoop.hdfs.server.datanode.DataNode
447 sun.tools.jps.Jps
- 查看 hadoop web UI
在浏览器输入 http://localhost:9870
集群页面 http://localhost:8088
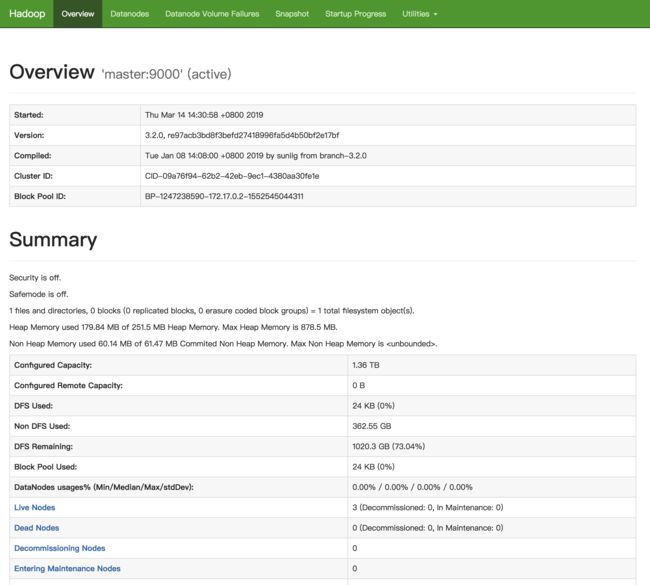
可以看到 live nodes 有3个 node
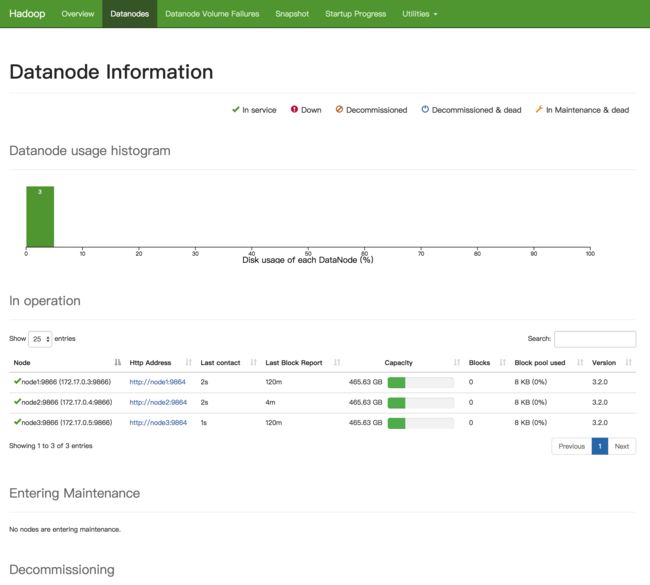
三个 node
可以看到这个页面说明hadoop集群已经配置完毕。并可以使用。
不足
每次都要手动启动各个容器。可以写个脚本一起启动 docker 容器。但我建议写一个 docker compose 配置文件,用 docker-compose 去启动集群。