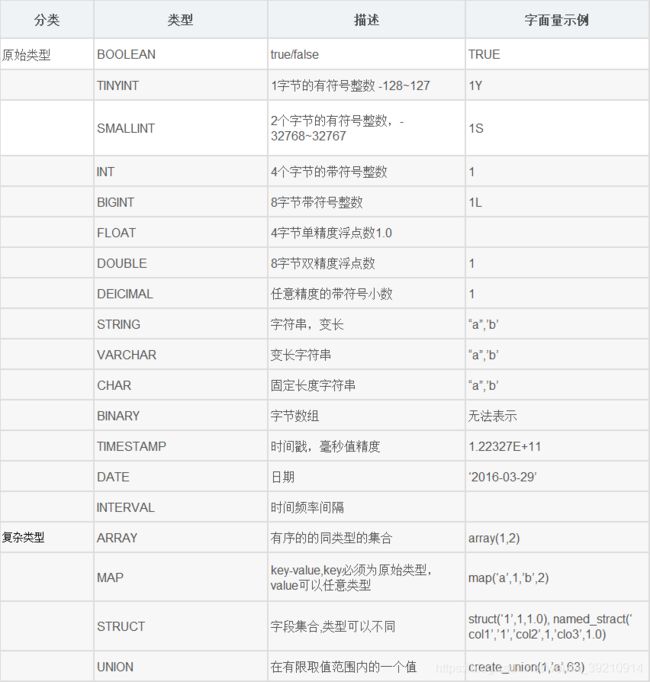
直接向分区表中插入数据(强烈不推荐使用) create table score3 like score;
insert into table score3 partition(month =‘201807’) values (‘001’,‘002’,‘100’);
通过查询插入数据 通过load方式加载数据 load data local inpath ‘/export/servers/hivedatas/score.csv’ overwrite into table score partition(month=‘201806’);
通过查询方式加载数据 create table score4 like score; insert overwrite table score4 partition(month = ‘201806’) select s_id,c_id,s_score from score;
多插入模式 常用于实际生产环境当中,将一张表拆开成两部分或者多部分 给score表加载数据 load data local inpath ‘/export/servers/hivedatas/score.csv’ overwrite into table score partition(month=‘201806’);
创建第一部分表: create table score_first( s_id string,c_id string) partitioned by (month string) row format delimited fields terminated by ‘\t’ ;
创建第二部分表: create table score_second(c_id string,s_score int) partitioned by (month string) row format delimited fields terminated by ‘\t’;
export导出与import 导入 hive表数据(内部表操作) create table techer2 like techer; export table techer to ‘/export/techer’; import table techer2 from ‘/export/techer’;
1.2.8 hive表中的数据导出(了解)
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等 insert导出 1) 将查询的结果导出到本地 insert overwrite local directory ‘/export/servers/exporthive’ select * from score;
2) 将查询的结果格式化导出到本地 insert overwrite local directory ‘/export/servers/exporthive’ row format delimited fields terminated by ‘\t’ collection items terminated by ‘#’ select * from student;
3) 将查询的结果导出到HDFS上(没有local)
insert overwrite directory ‘/export/servers/exporthive’ row format delimited fields terminated by ‘\t’ collection items terminated by ‘#’ select * from score;
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
分桶表的作用:最大的作用是用来提高join操作的效率; (思考这个问题: select a.id,a.name,b.addr from a join b on a.id = b.id; 如果a表和b表已经是分桶表,而且分桶的字段是id字段 做这个join操作时,还需要全表做笛卡尔积吗?)
全表查询
select * from score;
选择特定列查询
select s_id ,c_id from score;
列别名
1)重命名一个列。 2)便于计算。 3)紧跟列名,也可以在列名和别名之间加入关键字‘AS’
select s_id as myid ,c_id from score;
2.2、常用函数
1)求总行数(count) select count(1) from score; 2)求分数的最大值(max) select max(s_score) from score; 3)求分数的最小值(min) select min(s_score) from score; 4)求分数的总和(sum) select sum(s_score) from score; 5)求分数的平均值(avg) select avg(s_score) from score;
2.3 LIMIT语句
典型的查询会返回多行数据。LIMIT子句用于限制返回的行数。 select * from score limit 3;
2.4 WHERE语句
1)使用WHERE 子句,将不满足条件的行过滤掉。 2)WHERE 子句紧随 FROM 子句。 3)案例实操 查询出分数大于60的数据 select * from score where s_score > 60;
2.5 比较运算符(BETWEEN/IN/ IS NULL)
1)下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
2)案例实操 (1)查询分数等于80的所有的数据 select * from score where s_score = 80; (2)查询分数在80到100的所有数据 select * from score where s_score between 80 and 100; (3)查询成绩为空的所有数据 select * from score where s_score is null; (4)查询成绩是80和90的数据 select * from score where s_score in(80,90);
2.6 LIKE和RLIKE
1)使用LIKE运算选择类似的值 2)选择条件可以包含字符或数字: % 代表零个或多个字符(任意个字符)。 _ 代表一个字符。 3)RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。 4)案例实操 (1)查找以8开头的所有成绩 select * from score where s_score like ‘8%’; (2)查找第二个数值为9的所有成绩数据 select * from score where s_score like ‘_9%’; (3)查找成绩中含9的所有成绩数据 select * from score where s_score rlike ‘[9]’;
逻辑运算符(AND/OR/NOT) 案例实操 (1)查询成绩大于80,并且s_id是01的数据 select * from score where s_score >80 and s_id = ‘01’; (2)查询成绩大于80,或者s_id 是01的数 select * from score where s_score > 80 or s_id = ‘01’; (3)查询s_id 不是 01和02的学生 select * from score where s_id not in (‘01’,‘02’);
2.7、分组
GROUP BY语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。 案例实操: (1)计算每个学生的平均分数 select s_id ,avg(s_score) from score group by s_id; (2)计算每个学生最高成绩 select s_id ,max(s_score) from score group by s_id;
2)案例实操: 求每个学生的平均分数 select s_id ,avg(s_score) from score group by s_id; 求每个学生平均分数大于85的人 select s_id ,avg(s_score) avgscore from score group by s_id having avgscore > 85;
2.8、JOIN语句
2.8.1、等值JOIN
Hive支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。 案例操作 (1) 查询分数对应的姓名 SELECT s.s_id,s.s_score,stu.s_name,stu.s_birth FROM score s LEFT JOIN student stu ON s.s_id = stu.s_id
2.8.2、表的别名
1)好处 (1)使用别名可以简化查询。 (2)使用表名前缀可以提高执行效率。 2)案例实操 合并老师与课程表 select * from techer t join course c on t.t_id = c.t_id;
2.8.3、内连接(INNER JOIN)
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。 select * from techer t inner join course c on t.t_id = c.t_id;
2.8.4、左外连接(LEFT OUTER JOIN)
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
查询老师对应的课程 select * from techer t left join course c on t.t_id = c.t_id;
2.8.5、右外连接(RIGHT OUTER JOIN)
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。 select * from techer t right join course c on t.t_id = c.t_id;
SELECT * FROM techer t FULL JOIN course c ON t.t_id = c.t_id ;
2.8.7、多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。 多表连接查询,查询老师对应的课程,以及对应的分数,对应的学生 select * from techer t left join course c on t.t_id = c.t_id left join score s on s.c_id = c.c_id left join student stu on s.s_id = stu.s_id; 大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表techer和表course进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表score;进行连接操作。
2.9、 排序
2.9.1 全局排序(Order By)
Order By:全局排序,一个reduce 1)使用 ORDER BY 子句排序 ASC(ascend): 升序(默认) DESC(descend): 降序 2)ORDER BY 子句在SELECT语句的结尾。 3)案例实操 (1)查询学生的成绩,并按照分数降序排列 SELECT * FROM student s LEFT JOIN score sco ON s.s_id = sco.s_id ORDER BY sco.s_score DESC; (2)查询学生的成绩,并按照分数升序排列 SELECT * FROM student s LEFT JOIN score sco ON s.s_id = sco.s_id ORDER BY sco.s_score asc;
2.9.2 按照别名排序
按照学生分数的平均值排序 select s_id ,avg(s_score) avg from score group by s_id order by avg;
2.9.3 多个列排序
按照学生id和平均成绩进行排序 select s_id ,avg(s_score) avg from score group by s_id order by s_id,avg;
2.9.4 每个MapReduce内部排序(Sort By)局部排序
Sort By:每个MapReduce内部进行排序,对全局结果集来说不是排序。 1)设置reduce个数 set mapreduce.job.reduces=3; 2)查看设置reduce个数 set mapreduce.job.reduces; 3)查询成绩按照成绩降序排列 select * from score sort by s_score; 4) 将查询结果导入到文件中(按照成绩降序排列) insert overwrite local directory ‘/export/servers/hivedatas/sort’ select * from score sort by s_score;
设置reduce的个数,将我们对应的s_id划分到对应的reduce当中去 set mapreduce.job.reduces=7; 通过distribute by 进行数据的分区 insert overwrite local directory ‘/export/servers/hivedatas/sort’ select * from score distribute by s_id sort by s_score;
2.9.6 CLUSTER BY
当distribute by和sort by字段相同时,可以使用cluster by方式。 cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不能指定排序规则为ASC或者DESC。 1) 以下两种写法等价 select * from score cluster by s_id; select * from score distribute by s_id sort by s_id;
说明: 1、 -i 从文件初始化HQL。 2、 -e从命令行执行指定的HQL 3、 -f 执行HQL脚本 4、 -v 输出执行的HQL语句到控制台 5、 -p connect to Hive Server on port number 6、 -hiveconf x=y Use this to set hive/hadoop configuration variables. 设置hive运行时候的参数配置
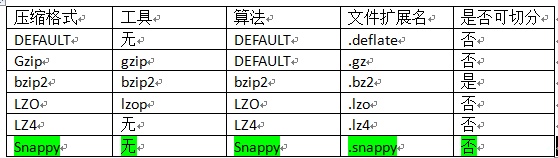
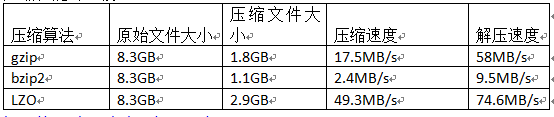
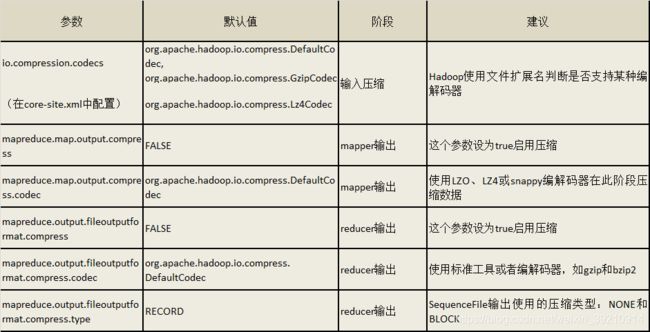
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示 压缩性能的比较 http://google.github.io/snappy/ On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
Enum是计算机编程语言中的一种数据类型---枚举类型。 在实际问题中,有些变量的取值被限定在一个有限的范围内。 例如,一个星期内只有七天 我们通常这样实现上面的定义:
public String monday;
public String tuesday;
public String wensday;
public String thursday
java.lang.IllegalStateException: No matching PlatformTransactionManager bean found for qualifier 'add' - neither qualifier match nor bean name match!
网上找了好多的资料没能解决,后来发现:项目中使用的是xml配置的方式配置事务,但是
原文:http://stackoverflow.com/questions/15585602/change-limit-for-mysql-row-size-too-large
异常信息:
Row size too large (> 8126). Changing some columns to TEXT or BLOB or using ROW_FORMAT=DYNAM
/**
* 格式化时间 2013/6/13 by 半仙 [email protected]
* 需要 pad 函数
* 接收可用的时间值.
* 返回替换时间占位符后的字符串
*
* 时间占位符:年 Y 月 M 日 D 小时 h 分 m 秒 s 重复次数表示占位数
* 如 YYYY 4占4位 YY 占2位<p></p>
* MM DD hh mm
在使用下面的命令是可以通过--help来获取更多的信息1,查询当前目录文件列表:ls
ls命令默认状态下将按首字母升序列出你当前文件夹下面的所有内容,但这样直接运行所得到的信息也是比较少的,通常它可以结合以下这些参数运行以查询更多的信息:
ls / 显示/.下的所有文件和目录
ls -l 给出文件或者文件夹的详细信息
ls -a 显示所有文件,包括隐藏文
Spring Tool Suite(简称STS)是基于Eclipse,专门针对Spring开发者提供大量的便捷功能的优秀开发工具。
在3.7.0版本主要做了如下的更新:
将eclipse版本更新至Eclipse Mars 4.5 GA
Spring Boot(JavaEE开发的颠覆者集大成者,推荐大家学习)的配置语言YAML编辑器的支持(包含自动提示,