上周一开始阅读了香港中文大学Bo Dai等人在ICCV 2017的文章,Towards Diverse and Natural Image Descriptions via a Conditional GAN,号称是第一个使用GAN处理Image Captioning的。巧的是,同期的会议上也出现了一篇同样用GAN处理Image Captioning的论文,Rakshith Shetty等人的Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training。两个工作的基本出发点大体相同,解决问题的思路有差异又有联系,于是我把这两篇论文一起总结了一下。
Towards Diverse and NaturalImage Descriptions via a Conditional GAN
问题背景
现有的Image Captioning技术主要通过MLE的思想来训练模型,即最大化训练样本出现的可能性。然而这样的做法有一个明显的缺陷,模型产生的图片描述会高度模仿ground truth,从而抑制多样化的表达,显得非常单调生硬。于是作者提出利用Conditional GAN让算法产生的图片描述贴近人类的表达,改善句子的naturalness和diversity。
模型设计
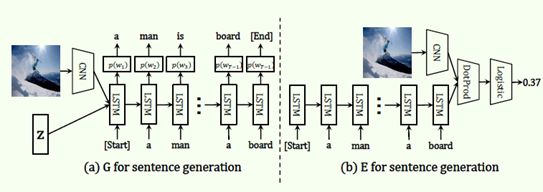
该论文提出的模型其实没什么太新奇的,唯一有趣的地方是,在该论文里,作者始终把Discriminator命名为Evaluator,其中的原因是这里的Discriminator会在后续的模型评估环节被赋予“Evaluator”的角色,这一点在后面我们会看到。
Generator方面,以CNN提取的图像特征及噪声作为输入,用LSTM生成句子,随后通过Monte Carlo Rollout从Evaluator那里得到reward,并通过Policy Gradient算法来更新参数。
Evaluator方面,中规中矩地用LSTM对句子编码,然后与图像特征一起处理,得到一个概率值。在训练Evaluator时,作者注意到了要把对Naturalness的判别和对Relevance的判别区分开,也就是说,Evaluator既要判别句子是否像是人类生成的,又要判别句子和图片是否相关。这个思想来源于Reed等人关于通过文本生成图像的工作:Generative adversarial text to image synthesis,他在论文里称这个trick为Matching Aware Discriminator。这个trick实现起来非常简单,只需把错误匹配的真实样本提供给Discriminator,令它把这样的样本也当作假样本,如下面算法的7-10行:

模型评估

传统的评估指标基本上都是在评估生成的句子与ground-truth句子的用词重合度,所以传统的MLE方法优势很大,而基于GAN的模型在这种评估指标下则占据很大的劣势,如上表的第3列至第8列。然而人类标记员给出的句子是多样化的,所以在这种评估体系下也是很吃亏的,这说明这种评估体系不能很好地体现算法的质量。上表的最后两列是GAN的Evaluator给出的分数,E-GAN指“通过对抗性训练得到Evaluator”,E-NGAN则是指“不更新Generator,单独训练Evaluator”。在这种基于训练的Evaluator的评估体系下,人类的表现基本上是最好的,这更符合我们的认知。同时,E-GAN指标描绘出了算法与人类的差距,因此是比E-NGAN更靠谱的指标。
上面的结果暗示了基于GAN的模型表现比基于MLE的模型更好,于是作者找了人类标记员在直观上比较这两个模型。结果在意料之中,虽然GAN模型与人类相比还有不小的差距,然而明显比MLE模型更让人接受。
Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Shetty等人的这个工作和上面Dai等人的工作基本出发点是一致的,都是旨在利用对抗性学习提高caption的多样性。所以问题背景就不赘述了,两者的差异仅在于模型设计和评估方法。
同样是应用了Conditional GAN,Shetty等人的模型设计略显复杂。
Generator设计
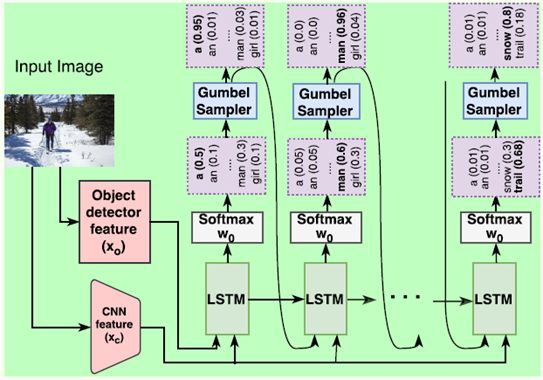
上图是Generator的结构,与Dai等人的Generator相比,主要有两个差异:
1. 输入项除了噪声(图上没有标识出来)和CNN特征外,还有一个目标检测的特征,通过常用的目标检测网络Faster Region-Based Convolutional Neural Network (RCNN)得到,这是为了让Generator捕捉到更清晰的目标信息。
2. 为解决Generator的采样过程不可微的问题,这里没有选择目前最常用的Policy Gradient算法,而是用Gumbel-Softmax的技巧把采样过程近似成连续可微的操作。
关于Gumbel-Softmax,补充一些说明。
首先,对于从一个Categorical分布进行采样的过程,可用Gumbel-Max技巧进行再参数化(re-parameterization)。假设一个categorical distribution的参数为
则从这个分布中采样的随机变量r可以表示为:
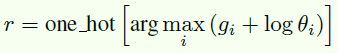
这个再参数化把 r 表达成了一个关于原类别概率的函数,其中是服从标准Gumbel分布的随机变量,使r的结果具备一定的随机性,模拟采样过程。
在上面的公式中,唯一不可导的部分是argmax,因此用softmax来进行连续化的近似,得到:

其中,是用来控制 r' 与 r 近似程度的参数,当越接近0,r' 与 r 越近似。
这样一来,采样过程就完全连续化了,可以用一般的BP算法来传播梯度。同时,如果设置得当,Gumbel-Softmax分布与原Categorical分布的误差很小,如下图:

跟Policy Gradient相比,Gumbel-Softmax的优势在于计算效率上。
Discriminator设计

这个工作的Discriminator结构显得复杂许多。
最大的特点是,这里的Discriminator以一张图像和与之对应的一组句子作为输入,为的是有效评估一组caption内部的多样性,例如,如果Generator对同一个图像多次生成的caption都趋于一致,Discriminator应当对这种缺乏多样性的表现给出低分。
为了对一组句子编码,这里借鉴了Salimans等人在Improved Techniques for Training GANs中提出的minibatch discrimination技巧,用Distance Kernel衡量一组句子内部的距离,具体的计算过程是:

具体的直观解释可参考Salimans等人的论文。
用同样的方法,可以对一张图像和一组句子进行编码,得到图像与句子的距离,这个距离用于判别句子和图像是否相关。
训练过程
与一般的GAN训练相比,这个模型的训练有两个特别之处:
1. 和Dai等人模型的训练一样,这里Discriminator的训练同样考虑了要训练Discriminator判别错误匹配的真实样本能力,具体而言就是应用Reed等人的matching aware discrimination技巧。
2. 借鉴了Salimans等人的feature matching loss技巧:Generator生成的样本在Discriminator中间层的特征应该要尽量与真实样本的一致。于是Generator的loss变成了

评估方法
在评估方法上,传统的指标很难反映多样性,而与Dai等人的工作依赖人类标记员的主观评价不同,这个工作使用了一些客观的指标来评估多样性。
在全局的语料库层面,有Vocabulary Size(所用到的词汇表大小)、% Novel Sentences(在训练集中没有出现过的句子占比);对于单张图像的一组caption,有Div-1(unique unigram的占比)、Div-2(unique bigram的占比)、mBleu(其中一个句子与同组其余句子之间的Bleu均值,数值低表示一组句子的内部重合度低,多样性强)。
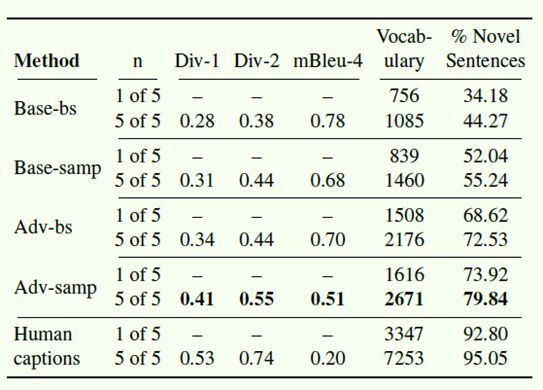
自动化测试的结果表明,对抗性的模型(Adv-bs和Adv-samp)在多样性上明显好于传统的模型(Base-bs和Base-samp),同时,算法与人类还是存在较大的差距。
小结
总结一下,两个工作的共同点有:
1. 在大局上,都注意到Image Captioning传统方法对多样性的忽视,以此作为切入点,然后都通过GAN来实现多样性。
2. 在具体的方法上,训练Discriminator时都考虑了分别判断文本和图片是否匹配以及文本是否像人工标记的那样具备多样性。结合其他的文献来看,训练这种双层次的Discriminator似乎已成为把GAN应用到多模态问题时的主流做法。
值得一提的还有两个模型在实现多样性上的差异:Dai等人的模型主要依靠Generator的随机噪声输入产生多样性;但在Shetty等人的工作中,Discriminator以一张图像和与之对应的一组caption作为输入,以此引导Generator对同一张图像产生多样化的caption,同时作者发现Generator的随机噪声在这里作用不大,因为其sampling过程已经有充足的随机性。