注意力机制在图像描述模型上的几篇论文笔记
得益于深度学习的发展,图像描述模型目前有很多非常优秀的模型和一些模型提升方法,在本文中我以注意力机制为线路,给出几篇代表性论文,以供交流。
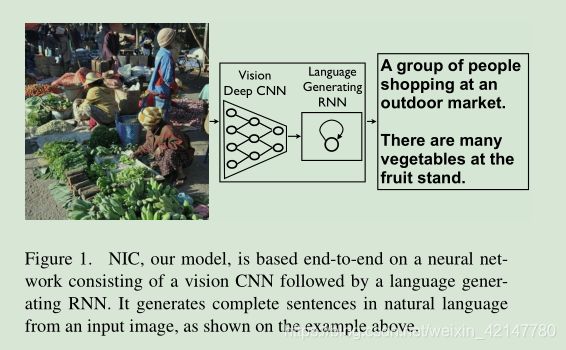
论文一:Show and Tell: A Neural Image Caption Generator(将 图像描述 视为 机器翻译 的任务)
本篇论文受机器翻译模型的启发,设计了一种适用于图像描述任务的encode-decode框架,不同于机器翻译模型的编码与解码,图像描述模型的编码对象是图像,因此在编码部分将RNN换成更适用于图像的CNN。模型如下:
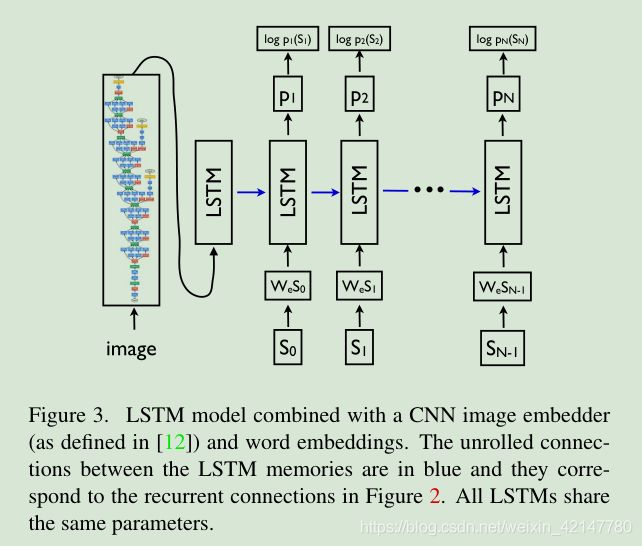
图像编码部分是一个CNN
语言生成部分是一个LSTM
单词的生成变成一个联合条件概率分布下的多分类问题,分类的类别大小等于词汇表的大小。
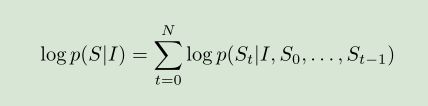
论文二:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention(图像描述模型引入自顶向下的空间注意力模型)
由于encode-decode模型将CNN编码的最后一层信息直接作为编码向量(通常保持不变,还是一维的),然后将图像编码向量输入给RNN进行解码。这种方式生成的图像编码,在语言生成过程中解码的时候容易丢失或者忽略一些重要的视觉信息,因此生成的句子质量不是太好,或者容易忽视图像中的一些目标。本文首次首次将注意力机制引入到图像描述模型中,图像编码部分不再是用CNN的顶层表示,而是提取来自CNN的底层向量表示(,之前是一维的,现在是立体的)。然后在解码的过程中借助于注意力机制计算注意力分布,然后在每一个单词生成的时候都会有意识的注意到图像的视觉区域。本文中提到两种注意力方法。
在下文中会详细讲解。
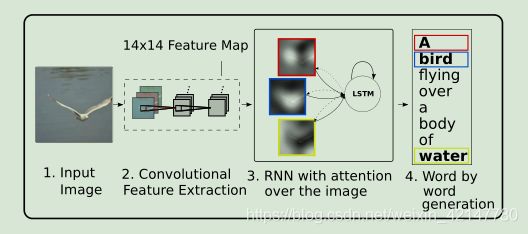

图上,卷积得到的不再是一维的向量,而是空间特征图,解码的时候在每一次生成一个单词的时候,会注意到图像的视觉区域,如右图,生成“dog”的时候模型注意的是图片的那个阴影区域。
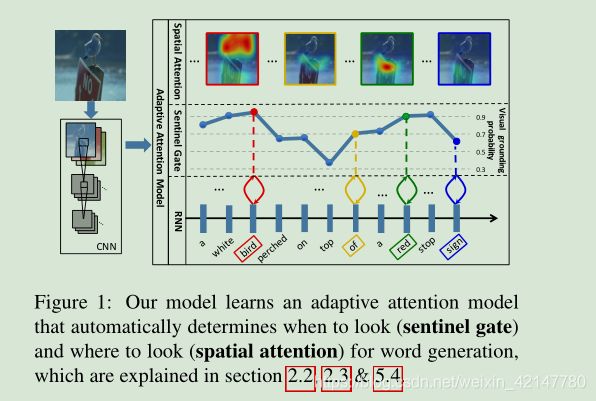
论文三:Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning(会自适应的自顶项下的空间注意力)
上面的方法,在生成的句子单词中,有些时候并不是每一个时间步(单词)都应该注意图像的一个视觉区域,比如在生成单词 ‘a’ 'the' ‘of’的时候, 这些单词不是一个视觉概念,因此是不必要注意的。而之前的方法没有这个感知能力,因此这篇论文提出来一种适应的注意力模型方法。知道什么时候该引起模型注意。

论文四:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering (引进了自底向上的注意力)
之前的方法在注意力分布,提取注意力区域的过程中都是基于整个全局的视觉特征图,并且特征图的每个块的大小都是一样大的。这种方式有一个弊端就是,无法权衡在为每一个特征视觉图上的位置,在提取注意力分布权重的时候,无法均衡在特征图上的位置的“粗”与“细”,因此会忽视一些很显著的目标区域(一个目标整体,或者目标概念区域)。
我们人类看东西的时候,在注意一个物体的时候,有一种方式是有意识的有目的的 自上而下 的 慢慢的聚集式的注意方式,也有来自于一种无意识的无预期的被某些显著的颜色或者视觉特征等的视觉刺激引起的视觉注意。之前的注意力方法(如论文二、三,)都是自上而下的。因此会忽视来自于显著的一些概念区域。

在这篇论文中为了提取自底向上的视觉注意区域,引进了目标检测模型,自底向上的概念先用目标检测的模型提取感兴趣的区域,然后在结合自上而下的注意力方式去有意识的给与适当的注意。
-------------------------------分割线之 注意力机制 原理-------------------------------
注意力一般分为两种:一种是自上而下(top-down)的有意识的注意力,称为聚焦式注意力。聚焦式注意力是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力(论文二,论文三);另一种是自下而上(bottem-top)的无意识的注意力,称为基于显著性(Saliency-Based)的注意力,也可以说是基于刺激(论文四).
到底什么是注意力?举个例子:你在一个嘈杂的环境里与朋友聊天,尽管旁边很吵但是你还是可以听到你朋友的说话信息(聚焦式),而忽略旁边吵闹的声音。但是,假如有一个人突然叫你的名字,你会马上注意到(显著性注意力)。
注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均
用![]() ]表示N 个输入信息,给定一个和任务相关的查询向量q (在这里可能就是某个单词 如 'people'),
]表示N 个输入信息,给定一个和任务相关的查询向量q (在这里可能就是某个单词 如 'people'),
注意力分布:
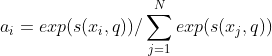
打分函数: 为注意力计算在特征图上每个区域的分布权重。
加性模型 ![]() (论文三)
(论文三)
点积模型 ![]()
缩放点积模型: ![]()
双线性模型: ![]()
加权平均:注意力分布α_i 可以解释为在给定任务相关的查询q时,第i个信息受关注的程度,因此有了关注就要有汇总。
汇总方式有两种,来软的和来硬的。
软性注意力加权 
硬性注意力加权 ![]() 其实 i 是概率最大的输入信息的下标。
其实 i 是概率最大的输入信息的下标。
硬性注意力需要用强化学习,所以用的不多,一般用软的,吃软怕硬。