秋招面经整理
复习进度
- C++
- 算法
- 操作系统
- 计算机网络
- 计算机图形学
- 数据库
- 场景题
- 智力题
- HR面
目录
- 语言基础C++
-
- 基本概念的区别
-
- 指针与引用
- 指针,数组,函数指针
- 类与结构体
- 隐藏、覆盖、重载
- new/delete malloc/free
- 浅拷贝和深拷贝
- 介绍一下关键字 xxx?
-
- 1. const (高频)
-
- const修饰函数时,想改变成员变量的两种方法?
- const修饰的函数可以重载么
- const和#define的区别
- const和constexpr的区别
- 2. static (高频)
- 3. inline
-
- inline函数优缺点?
- inline和宏的区别
- 4. cast (高频)
-
- dynamic_cast的原理? 让你设计的话怎么做?
- static_cast返回失败时怎么办 (不确定)
- cast 的缺点
- 介绍一下多态?
-
- 虚函数是什么?虚表是什么?
- 多态的作用
- 静态多态与动态多态? 实现原理?
- 虚函数调用是怎么实现的?
- 多继承的子类有几个虚函数表? 菱形继承怎么解决?
- 虚函数内存泄漏怎么解决?
- 构造函数能为虚函数吗?析构函数?
- 在构造函数中调用虚函数?
- 父类指针调用父类非虚函数? 调用子类的非虚函数?
- STL
-
- vector和list有什么区别? 适用场景?
- 介绍一下vector?
- 介绍一下map
-
- 红黑树什么时候需要调整?
- 为什么有平衡二叉树了还要红黑树?
- 介绍一下unordered_map
-
- 链的长度太长了怎么办?
- 除了开链地址法,还有哪些冲突处理方法?
- 容器迭代器失效的情况
- 让你自己设计一个哈希表要怎么设计? 为什么要引入哈希表? (米哈游)
- STL中的堆?
- 智能指针? 实现原理(怎么确保内存不泄露)?
-
-
- 使用智能指针需要注意什么?
-
- 介绍一下C++11的新特性
-
- 右值引用
- 列表初始化
- 可变参数模板
- lambda表达式
- C++的垃圾回收机制?
- C++的异常机制
- 其他
-
- 请讲一下B继承A是一个什么流程?
- C++程序的生成过程
- extern "C" 的作用
- 内存对齐
- 行读取和列读取的效率
- 数据结构
-
- 二叉树
-
- 概念题
- 前中后序遍历迭代版
- 之字形遍历
- 二叉搜索树的Kth
- 二叉搜索树转双向链表
- 最低公共祖先LCA
- 含根二叉树求后继
- 从输入构建二叉树
- 哈希表
-
- 找0~n-1重复数(原地哈希)
- 最长连续序列(不要求原位置连续)
- 链表
-
- 排序链表删重(不是去重)
- 翻转
-
- 部分翻转
- K翻转
- 链表交点
- 复杂链表的复制
- 单链表的快速排序
- 链表归并排序
- 栈
-
- 用栈模拟队列
- 中缀转后缀
- 单调栈
- 算法
-
- 动态规划
-
- 约瑟夫环
- 最大子序和(连续子数组和)
- 正则表达式匹配(递归型DP)
- 搜索
-
- 贪心法
-
- 剪绳子
- 二分查找
-
- 旋转数组的最小元素
- k在有序数组中出现的次数
- 第一个比k大的数
- 找1~n中重复数(抽屉原理)
- 实现平凡根
- DFS(回溯)和BFS
-
- 矩形中的字符串路径
- 应用二: 机器人可达范围(BFS/DFS)
- 到叶节点和为k的路径
- 判断是否BST的后序遍历
- 字符串分割成回文串
- 排序
-
- 数组快速排序
- 数组归并排序
- 字符串
-
- 字符串压缩 (双指针)
- 去除偶数
-
- 以指定字符分割字符串
- 进制转换
- 循环左移
- 位运算
-
- 计算二进制中1的个数
- 特殊高频
-
- 实现LRU
- 洗牌算法
- 双指针系列
-
- 合并区间 (排序+双指针)
- 跳跃游戏 (是否可以到达最后)
- 删除数组中的偶数
- 螺旋打印
- 二维数组的查找
- 数学
- 操作系统
-
- 按下开机键发生的事
- 进程内存模型 (网易一面)
-
- 堆与栈的区别
- (网易一面) 进程fork出一个子进程后,它们的内存总占用是多少呢?
- 内存管理
-
- 内存泄漏? 怎么避免?
- 手撕智能指针
- 虚拟内存是什么?可以解决什么问题?
- 进程的虚拟物理地址如何转换的?
- Cache缓存
- 进程与线程的区别? 进程开销为什么会大? 为什么线程可以提高并发性?
- 进程通信(同步)有哪些方式?线程的通信(同步)?
- 并行与并发的区别
- 阻塞与非阻塞的区别
- 手撕生产者消费者模型
- 简述 IO 多路复用
- 死锁
- 进程调度的算法有哪些?
- 僵尸进程和孤儿进程如何解决?
- 生产者消费者模型的好处? 同步与异步是什么? 协程是什么?
- 线程池要如何设计?
- 如何设计一个定时器?
- Linux
-
- 介绍一下linux基本命令
- GDB调试?
- 计算机网络
-
- TCP/UDP的区别?适用场景?
-
- 三次握手四次挥手
- 流量控制和拥塞控制
- TCP为什么可靠? UDP怎么实现可靠?
- TCP为什么用流传输? 沾包指什么?
- tcp和udp是否可以共用(同时监听)端口号? 为什么?
- 端口处于time_wait状态是什么原因? 怎么解决?
- 四次挥手突然断电,端口还能用吗? 怎么查询端口?
- 客户端断网, 服务器怎样才能知道要停止服务?
- HTTP建立连接的过程
-
- dns解析过程?
- http和https的区别?
- 长连接和短连接的区别是什么?
- 在全球IP地址快速找一个IP,怎么做?
- 计算机图形学
-
- 三维空间直线方程怎么写? 直线中常量的意义
- (字节二面)点乘叉乘的物理意义? 作用?
- 介绍一下渲染管线?
-
- 一个三角形绘制到屏幕的过程?
- 传统的光照模型? phong式光照模型? 介绍PBR?
- 概率题
-
- 不等概率生成等概率
- 随机数扩展
- 场景题
-
- 海量数据问题
-
- 快速获得高考排名
- 一个地图中有一个圆,怎么快速算出在圆内的人数?
- 空投点如何在一个圆内均匀且随机?
- 判断矩形相交
- 对英雄施加定时持续伤害,如何实现?
- 附近地点搜索
- 微信抢红包怎么实现?
- 一条公路上有多个点,每个点都有一辆车,给定公路坐标轴,车的速度和行驶方向,求最早两辆车相遇的时间?
- 实现线程安全的智能指针
- 分析玩网络游戏发生延迟的原因,从客户端,服务端,中间传输考虑
- 现在有一堆标记为危险的ip地址,如何管理,比如20.30.40.50,第三段区间为40-60的有危险,或者某一段出现特定值为危险,设计存储,查询ip的方法.
- 现在有个系统,查询频率很高,但是数据量太大了,设计一个分布式的系统
- 数据库
-
- 为什么要用B+树?
- 数据库中范式用来解决什么?
- 智力题
-
- 两根香,一根烧完1小时,如何测量15分钟
- 海盗分金币(博弈论)
- 扔鸡蛋
- 红白球
- 过桥问题
- 倒水问题
- 蓝眼睛红眼睛
- HR面
-
- 对手游怎么看?
- 说说自己的缺点
- 如何看待加班?
- 遇到过的最大的技术问题和非技术问题是什么? 怎么解决的?
- 未来三年的职业规划? 期望达到的薪资情况?
- 你觉得程序员和哪个职业最相似?
- 最擅长的语言? 为什么选择这个语言?
- 了解的最新技术是什么? 最牛的技术是什么? 牛在哪里?
语言基础C++
基本概念的区别
指针与引用
- 指针是一个变量,它的内容是所指向的内存的地址, 它本身需要占用额外的内存空间(4个字节);引用对变量起的别名,类似于
#define一样的功能, 本身不占用额外的内存空间,所以sizeof引用得到的是所指向的变量(对象)的大小,而sizeof指针得到的是指针本身的大小;自增自减操作得到的结果也不同 - 引用定义时必须初始化并且不能再改变指向;指针可以不进行初始化,可以在任何时候改变它的内容.
- 引用不能为空,指针可以为空
指针,数组,函数指针
数组名可以看成是一个常量,不能对它赋值,但可以取地址。取了地址可以赋值给一个指向数组的指针。把数组名当作函数参数的时候就退化为指针。
| 概念 | 形式 | 说明 |
|---|---|---|
| 指针数组 | int *p[5] |
[]优先级高于*, 因此p首先是个数组,每个数组元素的类型是int * |
| 指向数组的指针 | int (*p)[5] |
()优先级最高,因此p首先是个指针,然后指向匿名数组int[5] |
| 函数指针 | int *(*p)(int x, int y) |
p是个指向形参为(int x, int y)返回值为int*的函数的指针 |
| 函数指针数组 | int *(*p[5])(int *x) |
()优先级最高,它的内容是个指针数组,每个元素都是函数指针 |
| 指向函数指针数组的指针 | int *(*(*p)[5])(int *x) |
()优先级最高,它的内容是一个指针,指向了一个含5各元素的数组. 数组内每个元素类型都是指向某种函数的指针, 该种函数形参为(int* x),返回值为int * |
类与结构体
- 默认的成员/数据访问权限不同
- 默认的继承访问权限不同
可以理解为一个是数据结构的实现方式,另一个是对象的实现方式
有了类为什么还要保留结构体? 答:兼容性。
隐藏、覆盖、重载
- 覆盖:函数同名+参数列表相同+基类virtual
- 隐藏:函数同名+参数列表相同+基类无virtual 或 函数同名+参数不同
- 重载:函数同名+参数列表不同+同一个类内
new/delete malloc/free
new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。new在申请内存时会自动计算所需字节数,而malloc则需我们自己输入申请内存空间的字节数。
为什么有malloc了还需要new?
浅拷贝和深拷贝
浅拷贝指的是拷贝对象的指针,会使得多个指针指向同一块内存,如果不小心就会出现野指针。深拷贝则是拷贝指针指向的内容.。
举例来说, 浅拷贝就像一个英雄使用影分身技能, 死了分身也没了. 深拷贝就像用另一个号创建同一个英雄参加到战场上.
介绍一下关键字 xxx?
1. const (高频)
这个关键字都是为了说明修饰的变量或对象都是不能被改变的。具体用法:
- 修饰类的成员变量、类的对象时,放在前面,表示不能修改。const变量要在其他文件中访问必须加extern关键字,非const变量则默认为extern.
- 修饰类的成员函数时,放在函数名后面,表示该函数内不会修改类的除了static成员之外的数据成员。并且类的const对象只能调用被const修饰的成员函数。
- 修饰引用,一般用于形参类型,避免拷贝,又避免函数对值的修改.
- 修饰指针,放在类型前面(如const int *p)表示指向常量的指针,只能读取指向的内容而不能修改,但可以改变指向,甚至可以指向非const对象。放在类型后面(如int *const p)表示指针常量,声明时必须初始化,初始化后不能改变指向,但是可以改变指向的内容。
const修饰函数时,想改变成员变量的两种方法?
- 将成员变量声明为mutable
- 使用const_cast将成员变量的指针转换为非const类型
- 将成员变量以引用传值的形参类型传入const函数,调用时用this指针解引用的方式
const修饰的函数可以重载么
可以。并且参数列表可以相同。重载后,非const对象调用的是非const版本,const对象调用的是const版本。实现原理是调用成员函数时传入的第一个参数是this指针,所以实际上调用该函数时,传入的是第一个参数不相同的参数列表。
const和#define的区别
const常量具有类型,编译器可以进行安全检查;#define宏定义没有数据类型,只是简单的字符串替换,不能进行安全检查。
const和constexpr的区别
用constexpr修饰主要是为了效率, 表示这个变量或函数在编译器就可以计算出它的值. 对于函数来说, 如果其传入的参数可以在编译时期计算出来,编译器就可以将函数体直接优化成编译期常量. 如果不能, 那么就作为普通函数对待.
2. static (高频)
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
(字节二面) static成员变量可以在类内初始化吗?
答:一般情况下必须在类外初始化,如果需要在类内初始化,那就要声明为static const类型
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员
3. inline
inline函数是在调用时,在行内插入或替换整个函数的代码。它只是对编译器的建议,具体是否为inline取决于编译器。一般包含循环,switch/goto语句,递归,静态变量的函数会被忽略inline请求。可以用于解决重复定义的函数问题(单一定义原则), 但是否inline还是取决于编译器.
针对单一定义原则还可以使用static和匿名命名空间修饰函数.
隐式: 定义在类内的函数会被当作inline函数。
显式: 必须加在函数定义之前,声明前面是无效的。
inline函数优缺点?
优点是节省了函数调用的开销,会进行类型检查,比宏更安全。缺点是以函数复制为代价,会消耗内存;如果有循环体,代码的执行时间可能要大于函数调用的开销。
inline和宏的区别
宏是由预处理器进行的简单的代码替换。而inline是编译器来控制实现的,会进行类型安全检查或自动类型转换,并且只在调用时进行展开。
4. cast (高频)
static_cast 的作用类似于C语言中的强制类型转换,例如可以将int强制转为double, void*转为带类型的对象指针等,但不能把整个struct通过static_cast转为int或double. 当然除此以外还可以将左值转化为右值引用,来实现完美转发。
dynamic_cast用于继承体系中安全的向下转型,即父类转为子类。需要多态的支持。
const_cast只用于去除对象的const或volatile属性.
介绍一下volatile关键字的作用?
reinterpret_cast 是对转换数进行二进制的重新解释。例如说char *p; int i = reinterpret_cast就是将指针p的值以二进制形式重新解释为int然后赋值给i. 一般用于不同类型的函数指针的转换。
dynamic_cast的原理? 让你设计的话怎么做?
dynamic_cast最常用于父类向下转型。对象的类型信息被存在虚表的首部,运行期间,父类指针根据子类对象的虚指针找到虚表后,比对虚表首部的类型和要转换的类型是否一致。我来设计的话,我会在基类中添加一个虚函数getClassType,在运行时获取对象的类型,和转换的类型对比是否一致。
static_cast返回失败时怎么办 (不确定)
static_cast不提供运行时的检查,所以在代码编写阶段就要确认转换的安全性。返回失败是说明编译不通过,要自己检查类型是否可以转换。
cast 的缺点
static_cast不进行类型安全检查,转换失败时也不会返回NULL,如果实际指向父类的指针被转换为子类指针,可能会导致越界崩溃。dynamic_cast由于需要通过虚表查询类型进行转换,会带来性能上的损失。const_cast强制去除了对象的const属性,这与初始化const对象时的意向相违背,会导致原本可以避免的意外发生.reinterpret_cast是平台依赖,所以会导致代码的移植性差.
介绍一下多态?
多态指的是相同的接口类型会因为参数或对象类型的不同而引发不同的动作. 举例来说, 调用类的某个虚函数时, 根据类实例化对象的不同, 同名的虚函数会有不同的操作.
虚函数是什么?虚表是什么?
虚函数指的是virtual修饰的成员函数。每一个包含虚函数的类,编译器都会构造一个函数表,按声明顺序存储每个虚函数的调用地址,这就是虚表。虚表是在编译时确定的,属于类而不属于某个具体的实例。虚函数表存放在可执行文件的只读数据字段,仅有一份。
多态的作用
主要是使得代码可扩充性增加,更易于维护.
举例来说的话, 比如英雄类包含法师,战士,射手等职业, 编写法师类的时候, 就要分别编写对战士射手的攻击和受伤函数, 如果增加一个新职业,就要修改每个职业的类. 但是使用多态的话, 在编写某个职业的攻击函数时,只需要传入一个英雄类指针,这是一个父类指针, 然后在运行时会具体指向某个职业的对象, 这样新增职业就不需要去修改每个职业的类
静态多态与动态多态? 实现原理?
动态多态:对于相关的对象类型,确定它们之间的一个共同功能集,然后在基类中,把这些共同的功能声明为多个公共的虚函数接口。
动态多态是虚函数,虚表, 虚指针和动态绑定来实现的。基类的函数被定义为virtual,派生类方法可以进行override定义自己的行为,其中包含定义为virtual函数的基类隐含一个指针成员,指向虚函数表,该表按照虚函数声明顺序保存地址,派生类中也包含这样一张表,如果发生重写,就更新虚函数表中的对应地址。
静态多态:对于相关的对象类型,直接实现它们各自的定义,不需要共有基类,甚至可以没有任何关系。只需要各个具体类的实现中要求相同的接口声明,这里的接口称之为隐式接口。
静态绑定通过函数重载或函数模板实现。
函数重载的原理是使用name mangling(倾轧)技术修改函数名,以区分不同参数列表的同名函数。可以对编译后的.o文件执行objdump -t命令来查看符号表。
函数名的修改有什么原则吗? 有。修改规则为:
固定前缀_Z+参数个数+函数名+参数类型首字母
函数模板的原理是编译器先对声明的函数体进行第一次编译,得到一个带有类型参数的半成品,在调用处对根据指定的参数类型再编译一次。
虚函数调用是怎么实现的?
包含虚函数的类的对象的头部含有一个虚指针,指向自己的虚表。发生动态绑定时,父类指针指向的是子类的对象,所以可以通过该对象的虚指针找到正确的虚表,再找到所调用的虚函数的地址。
虚函数的地址是按声明顺序存在虚表中的,所以调用的是第几个虚函数,就从虚表中取出第几行,也就是调用函数的实际地址。(可以理解为偏移量)
多继承的子类有几个虚函数表? 菱形继承怎么解决?
多重继承(不是多级派生)时,有多少个含虚函数的基类,子类对象就有多少个虚指针,对应着不同的虚表,排列顺序按照声明顺序。 子类的成员函数被放到了第一个父类的表中。
通过使用虚继承来解决菱形继承,这样通过多条路径间接继承虚基类的派生类中只有一份虚基类成员的拷贝。构造时调用虚基类的构造函数对虚基类初始化,而忽略虚基类的其他派生类对虚基类的构造函数。
虚函数内存泄漏怎么解决?
虚函数出现内存泄漏的情况一般是父类指针没有正确调用子类的析构函数,把父类的析构函数声明为虚函数可以避免内存泄漏。
构造函数能为虚函数吗?析构函数?
不可以。如果构造函数是虚的,就需要通过虚表来调用,可是虚表是通过对象的虚指针来访问的,此时对象还没有实例化,就无法找到对应虚表,所以构造函数不能是虚函数。在发生继承关系时,析构函数必须是虚函数,否则无法正确销毁对象。
在构造函数中调用虚函数?
父类的构造函数中调用虚函数,这时不会发生多态行为,调用的仍然是父类自己的虚函数。因为子类对象还未生成,无法通过虚指针找到对应的子类虚函数。
父类指针调用父类非虚函数? 调用子类的非虚函数?
当父类指针指向子类对象,并调用一个父类中的非虚函数,这时不会发生多态行为。不论子类的同名函数是否为虚,此时父类指针调用的这个函数是父类中的函数,不是子类中的。父类指针无法调用子类的非虚函数。
若用子类指针调用与父类同名的非虚函数,则调用的是子类中的函数,即不发生多态行为而是隐藏。
STL
vector和list有什么区别? 适用场景?
vector是数组,底层是一段连续的内存空间,list是链表,内存空间不连续。vector可以O(1)时间访问第i个元素,而list必须遍历。但是插入删除中间某个数时,vector需要移动其他数,为O(n). 而list为O(1).
vector适用于需要在中间插入删除较少,而随机访问较多的场景;list与它相反.
介绍一下vector?
介绍一下map
STL中的map基于红黑树。它是一种接近平衡的二叉搜索树, 它的性质是任意一个节点到它的每个叶子节点的路径包含着相同数目的黑色节点, 所有叶子节点到根节点的路径上不会有连续的红色节点.
红黑树的优点: 最长路径不会超过最短路径的2倍
一些特殊树的概念
二叉搜索树 = 二叉排序树 = BST
平衡二叉树 = AVL树
红黑树 = RB树 = 近似AVL树的二叉搜索树
红黑树什么时候需要调整?
插入节点默认红色,当它的父节点也是红色时,需要向上染色,或者进行旋转操作,来保持性质.
为什么有平衡二叉树了还要红黑树?
红黑树相比于AVL树,牺牲了部分平衡性,以换取删除/插入操作时少量的旋转次数,整体来说,性能优于平衡二叉树。
由于严格的平衡性, 有时候平衡二叉树可能会需要一直调整到根节点.
介绍一下unordered_map
STL中的unordered_map基于开链地址法的哈希表。用一个vector容器存储各个链表的头指针. 每个链表称为一个桶,按照在vector中的存储顺序进行编号. 插入一个键值对的时候, 由hash函数算出hash值,再对桶总数取模得到桶的编号,然后放到这个桶里. hash函数: 设计尽量复杂的hash函数, 基于线性同余的伪随机数生成器来计算哈希值,然后再对桶数量取模.
链的长度太长了怎么办?
需要增加桶的数量,也就是vector的长度, 然后重新hash. 增加的数量来自于下一个最接近2倍的质数. 选用质数的原因是为了减少冲突的可能性. 可以举例2468模4和模5.
除了开链地址法,还有哪些冲突处理方法?
- 开放定址法: 再往后查找一个空位
- 再哈希法: 多个不同哈希函数
- 溢出区法: 建立一个公共的溢出表存放溢出的元素
容器迭代器失效的情况
- 负载因子超过默认值, 系统增加桶的数量并重新进行哈希, 此时容器的迭代器失效. 但是指向单个键值对的指针和引用仍然有效.
- 调用
erase函数时,删除元素的迭代器失效,并且不返回
让你自己设计一个哈希表要怎么设计? 为什么要引入哈希表? (米哈游)
STL中的堆?
堆结构是个特殊的完全二叉树,一般存在一个数组中。第i个数的左子节点的下标是2i+1,右是2i+2,每次插入新元素就从最后一个分支节点也就是n/2开始检查它和子节点的大小关系,然后进行调整。
在STL中一般将优先队列priority_queue当作堆来使用。
智能指针? 实现原理(怎么确保内存不泄露)?
总共三种(auto_ptr已被移除)。通过资源获取即初始化(RAII)的思想来实现的。在智能指针的构造函数中进行控制块的申请,在其析构函数中对资源进行释放.
unique_ptr 保证内存只会一个指针占有, 当它的生存期结束,就自动调用析构函数,释放指针和指针所指向的内存.
share_ptr通过引用计数, 每增加一个指向资源的指针,计数器就加1, 每销毁一个指针就减1, 在销毁最后一个指针时, 引用计数为0, 析构函数中就会自动释放资源.
weak_ptr是为了解决shared_ptr使用过程中遇到的一些问题. 例如说
- 两个
shared_ptr的循环引用, 会使得use_count永远都不为0; - 还有多线程程序中,如果
shared_ptr提前被某个线程reset()了, 另一个线程在访问的时候就会访问到空指针.
weak_ptr的实现原理是通过一个lock()函数来实现的,它产生一个临时变量保存share_ptr的值,并且不影响share_ptr中的use_count的值。即使share_ptr被reset或者被销毁,它所指向的内存地址也能继续通过weak_ptr的lock()函数来获取,一直被保留到最后一个weak_ptr的生命周期为止,从而避免内存泄漏。
(字节一面) 那怎么判断什么时候要使用
weak_ptr呢?
使用智能指针需要注意什么?
- 尽量用make_shared/make_unique,少用new(数据和控制块同时申请)
- 智能指针管理的资源它只会默认删除new分配的内存,如果不是new分配的则要传递给其一个删除器,例如malloc分配的内存 -> malloc/new的区别
- 不要把一个原生指针给多个shared_ptr或者unique_ptr管理 (多次析构)
介绍一下C++11的新特性
右值引用
右值引用的目的是为了延长右值的生命周期, 例如 a+b这个表达式,就是一个右值, 可以被右值引用之后, 重新用于后续的计算. 右值引用最大的作用是用于实现移动语义和完美转发.
先说移动语义. 有时候我们会有一些需求, 在函数内部产生对象, 进行一些处理以后,将处理之后的对象返回到外部. 函数的返回值是一个临时对象, 它通过拷贝构造函数被创建,然后又在外部通过拷贝赋值函数复制给外部变量. 因为这个临时对象几乎转瞬即逝, 没有必要花费这些拷贝开销.
移动语义是通过右值引用和移动构造函数实现的. 移动构造函数接收一个临时对象的引用(即右值引用),然后直接转移该引用指向的内存的所有权, 而不进行内存的申请和拷贝操作.
说说移动构造函数?
完美转发指的是创建一个转发函数时,要将接收到的参数按原本的类型转发给目标函数. 其中最特别的就是右值, 通过函数形参的方式传入自然就变成了左值. 要实现完美转发就要借助forward函数返回右值引用, 再传给目标函数.
列表初始化
可变参数模板
lambda表达式
C++的垃圾回收机制?
C++没有提供垃圾回收机制,需要自己实现. 据我了解是有标记清除, 引用计数等垃圾回收算法. 一般来说使用智能指针可以规避大部分的产生内存垃圾的情况.
C++为什么没有提供?
C++的异常机制
异常指的是程序在运行过程中出现的问题,例如程序奔溃,内存泄漏,越界访问等等. C++的异常机制提供了异常抛出,异常标识和捕获,对应throw,try和catch关键字. 作用是: 不希望程序立刻奔溃,而是可以打印当前的异常,进行一些修复工作,然后继续执行后面的工作.
其他
请讲一下B继承A是一个什么流程?
B首先调用A的构造函数,完成A成员的初始化,然后调用自己的构造函数,若存在同名函数和数据成员,则会发生隐藏行为。若存在同名虚函数,则发生覆写行为。
C++程序的生成过程

extern “C” 的作用
是为了在C++代码中调用C语言编写的库时能够正确链接.
原因详解: C++为了实现重载, 会对函数的汇编代码进行修饰. 而C语言不会. 所以要用extern "C"告诉编译器:这是一个用 C 写成的库文件,请用 C 的方式来链接它们。
内存对齐
数据成员对齐的规则就是,而在第一个成员之后,每个成员距离struct首地址的距离 offset, 都是struct内成员自身长度(sizeof) 与 #pragma pack(n)中的n的最小值的整数倍,如果未经对齐时不满足这个规则,在对齐时就会在这个成员前填充空子节以使其达到数据成员对齐。
作用是什么?
提高CPU 的内存访问速度。有些平台每次读都是从偶地址开始,如果一个 int 型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这 32 位,而如果存放在奇地址开始的地方,就需要 2 个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该 32 位数据。显然,这在读取效率上下降很多。
如何关闭? #pragma pack(1)
行读取和列读取的效率
与二重循环内外大小无关,尽量保证内循环操作连续数据即可。
CPU读取内存某地址处的值,并不是每次都去内存中取出来,有时候会从cache里读取。当初次访问数组的时候,会把连续一块(chunk)内存地址上的值都读到cache里(比如,64字节),后续CPU接受到一个内存地址要读取数据时,先看cache里有没有,没有的话再去内存上取。
数据结构
二叉树
概念题
二叉排序和堆排序的区别?
在二叉排序树中,某结点的右孩子结点的值一定大于该结点的左孩子结点的值;在堆中却不一定,堆只是限定了某结点的值大于(或小于)其左右孩子结点的值,但没有限定左右孩子结点之间的大小关系。
二叉排序树是为了实现动态查找而设计的数据结构,它是面向查找操作的,在二叉排序树中查找一个结点的平均时间复杂度是O(log n);
堆是为了实现排序而设计的一种数据结构,它不是面向查找操作的,因而在堆中查找一个结点需要进行遍历,其平均时间复杂度是O(n)。
二叉树的节点数计算?
二叉树的节点数: 遍历, 前中后层之
满二叉数的节点数: 2 k − 1 2^k-1 2k−1 (1 << depth) - 1
(网易一面)等比数列的推导? 错位相减
完全二叉树节点数:
- d l e f t = = d r i g h t d_{left} == d_{right} dleft==dright 左子树为满二叉树 结果为 ( 1 < < d l e f t ) − 1 + g e t N ( r i g h t ) + 1 (1<< d_{left} )-1+getN(right)+1 (1<<dleft)−1+getN(right)+1
- d l e f t > d r i g h t d_{left}>d_{right} dleft>dright 右子树为满二叉树 结果为 ( 1 < < d r i g h t ) − 1 + g e t N ( l e f t ) + 1 (1<< d_{right})-1+getN(left)+1 (1<<dright)−1+getN(left)+1
时间复杂度 O ( l o g 2 N ) O(log^2N) O(log2N)
前中后序遍历迭代版
leetcode相关练习:前序 中序 后序
stack<TreeNode*> s; auto p = root;
// 前序
while(s.size() || p)
if(p) s.push(p), visit(p), p=p->left;
else p=s.top(), s.pop() , p=p->right;
// 中序 (和前序区别是visit位置不同)
while(s.size() || p)
if(p) s.push(p), p=p->left;
else p=s.top(), s.pop(), visit(p), p=p->right;
// 后序 (根右左,暂存在r栈中,O(n)空间)
while(s.size() || p)
if(p) s.push(p), r.push(p), p=p->right;
else p=s.top(), s.pop() , p=p->left;
while(r.size()) visit(r.top()), r.pop(); //从r栈中取出
// 后序 O(1)空间
TreeNode* r = nullptr; // r记录前一步visit的节点
while(s.size() || p)
if(p) s.push(p), p=p->left;
else{
//用 r来检查 p的 right是否访问过
p = s.top();
if(!p->right || p->right == r)
//访问后要把 p置为空,因为要去取栈中的点
visit(p), s.pop(), r=p, p=nullptr;
else p = p->right;
}
之字形遍历
如果不是要求返回res而是输出,level数组可以进一步优化:队列中同时出现两个nullptr时说明树已遍历完。
// 层序基础上,加上nullptr分隔
queue<TreeNode*> q; q.push(root); q.push(nullptr);
while(q.size()){
auto t = q.front(); q.pop();
if(!t){
q.push(nullptr); // 因此补上下一层的结尾
if(level.empty()) break; // 树已遍历完
// 偶数层时翻转
if(res.size()&1) reverse(level.begin(), level.end());
res.push_back(level), level.clear();
}
else{
//不为空时,访问+扩展
level.push_back(t->val);
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
}
}
二叉搜索树的Kth
找第k大就右根左,第k小就左根右
void dfs(TreeNode* root, int& k){
if(!root) return;
dfs(root->right, k); // 先右
if(!--k) {
res = root->val; return; }
dfs(root->left, k); // 再左
}
二叉搜索树转双向链表
leetcode习题
Node* pre = nullptr, *head = nullptr;
Node* treeToDoublyList(Node* root) {
if(!root) return nullptr;
dfs(root);
// 本题要求返回一个循环的双向链表
pre->right = head, head->left = pre;
return head;
}
void dfs(Node* root){
if(!root) return;
dfs(root->left); // 先转换左子树,完成后pre是左子树最右边的节点
root->left = pre; // 左子树已完成,把left直接指向pre
pre? pre->right=root : head=root; // pre为空时,说明是最左边的节点
pre = root; // 更新pre
dfs(root->right);
}
最低公共祖先LCA
TreeNode* LCA(TreeNode* root, TreeNode* p, TreeNode* q) {
if(!root) return nullptr;
if(root==p || root==q) return root;
auto left = LCA(root->left, p, q);
auto right = LCA(root->right, p, q);
if(!left) return right; // 左子树中没找到,那就是右子树中找到的那个节点
if(!right) return left; // 同理
// 如果左右子树中都找到了【包含p或q的节点】
return root;
}
//二叉搜索树拥有一些性质
TreeNode* LCA_BST(TreeNode* root, TreeNode* p, TreeNode* q){
if(!root) return nullptr;
if(root->val>p->val && root->val>q->val)
return LCA_BST(root->left, p, q);
if(root->val<p->val && root->val<q->val)
return LCA_BST(root->right, p, q);
return root;
}
含根二叉树求后继
给定一个节点,求后继
if(p->right){
// 存在右子树,则右子树最左下节点就是后继节点
p = p->right;
while(p->left) p=p->left;
return p;
}
// 否则沿着father往上找到第一个满足 p == p->father->left 的点
while(p->father && p == p->father->left)
p = p->father;
从输入构建二叉树
层序输入,空节点用任意非整数字符表示
// 待补充
哈希表
找0~n-1重复数(原地哈希)
while(i<num.size()){
x = num[i];
if(num[i] != i)
if(num[x] == x) return x; //出现重复
else swap(num[x], nums[i]); // 换到正确的位置
else i++;
}
最长连续序列(不要求原位置连续)
int longestConsecutive(vector<int>& nums) {
unordered_set<int> m; //记录出现的数
for(int x:nums) m.insert(x);
int res = 0;
for(int x:nums){
//只有x-1没出现过,包含x的区间才没被计算过
if(!m.count(x-1)){
int cur = x, len = 1;
//cur+1存在,就可以往前走
while(m.count(cur+1)) cur++, len++;
res = max(len, res);
}
} return res;
}
链表
排序链表删重(不是去重)
// q向前探索,p记录非重位置
ListNode* solve(ListNode* head){
ListNode dummy = ListNode(-1);
dummy.next = head;
ListNode* p = &dummy;
while(p->next){
// 用虚拟头节点,可以处理head为空的情况
auto q = p->next;
while(q&&p->next->val==q->val) // 一直探索重复数
q = q->next;
// q只移动一次,说明下一个数非重
if(q == p->next->next) p = p->next;
else{
// 仅仅跳过重复元素会内存泄漏
auto t1 = p->next; p->next = q;
while(t1!=q){
// 一直删到q
auto t2 = t1->next; delete t1; t1 = t2;
}
}
} return dummy.next;
}
翻转
迭代版
ListNode* reverseList(ListNode* head) {
ListNode* cur = head, *pre = nullptr;
while(cur) swap(cur->next, pre), swap(pre, cur);
return pre;
}
递归版
// 递归版本1,加一个辅助函数比较好理解
ListNode* reverseList(ListNode* head) {
return reverse(nullptr, head);
}
ListNode* reverse(ListNode* p, ListNode* c){
if(!c) return p; //终点,返回pre
swap(c->next, p); //把pre换给next
return reverse(c, p);
}
// 递归版本2,不加辅助函数稍微难理解一点,要画图
ListNode* reverseList(ListNode* head) {
if(!head || !head->next) return head;
// 当前节点之后的部分翻转完成,并返回了最后一个节点
auto res = reverseList(head->next);
// 然后再处理当前节点,就是cur.next.next -> cur
head->next->next = head;
head->next = nullptr;
return res;
}
部分翻转
翻转链表的第m到n个节点
ListNode* reverseBetween(ListNode* head, int m, int n) {
auto dummy = new ListNode(-1); dummy->next = head;
//从dummy开始相当于下标从0开始,这样第一个节点的下标也是1
auto s = dummy;
//走m-1步,到达第m-1个点(下标也为m-1)
for(int i=0; i<m-1; ++i) s = s->next;
//从第 m点开始执行翻转算法
ListNode* c = s->next, *p = nullptr;
// 要翻转 n-m+1 个点,而不是 n-m 个点
for(int i=0; i<n-m+1; ++i) swap(c->next,p), swap(p,c);
// 翻转后,s->m-1, p->n, c->n+1
s->next->next = c, s->next = p;
return dummy->next;
}
K翻转
思路分两步:
- 裁剪出k个点
- 翻转后,正确接入
需要两个指针pre和end辅助
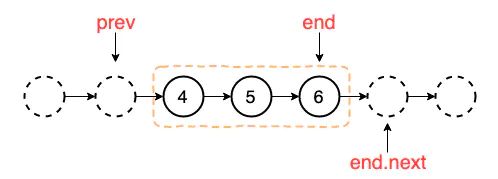
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode dummy(-1, head), *pre, *end;
pre = end = &dummy;
while(end->next){
for(int i=0; i<k && end; ++i) end=end->next;
if(!end) break; // 最后一组少于k,不处理
auto next = end->next; // 打断前保存
end->next = nullptr; // 用打断来分组
auto begin = pre->next; // 翻转的起点
pre->next = reverse(begin); // 返回终点
begin->next = next; // 翻转后begin变成终点
end = pre = begin; // 继续处理下一组
} return dummy.next;
}
链表交点
复杂链表的复制
leetcode习题
主要思路:
复制q->next=p->next, p->next=q, p=p->next
关联next->random = random->next
拆解p->next = p->next->next, p=p->next
auto p = head;
while(p){
// 交错复制出一份
auto q = new Node(p->val);
q->next = p->next, p->next = q;
p = q->next;
}
// 最核心的一步
for(p=head; p; p=p->next->next)
if(p->random) p->next->random = p->random->next;
// 虚拟头节点可以处理空链表
auto dummy = new Node(-1);
// cur就指向【要返回的链表】中的每个节点
auto cur = dummy;
// p收集原链表,cur收集复制的链表
for(p=head; p; p=p->next){
cur->next = p->next, cur=cur->next;
// 拆解的关键步骤
p->next = p->next->next;
}
return dummy->next;
单链表的快速排序
leetcode习题
// 链表的partition用的是交换节点值的方法
Node* partition(Node* pBegin, Node* pEnd){
auto p = pBegin, q = p->next;
int pivot = p->key;
while(q != pEnd){
// 类似于 while(l
if(q->key < pivot) // 小的换到前面
p = p->next, swap(p->key,q->key);
q = q->next;
}
// 最后一个节点还要交换一下
swap(p->key, pBegin->key);
return p;
}
void quickSort(Node* pBeign, Node* pEnd){
if(pBeign != pEnd){
Node* mid = partition(pBeign,pEnd);
quickSort(pBeign, mid), quickSort(mid->next, pEnd);
}
}
链表归并排序
递归版
ListNode* merge(ListNode* l1, ListNode* l2){
if(!l1) return l2; if(!l2) return l1;
if(l1->val < l2->val){
l1->next = merge(l1->next, l2); return l1;
}else{
//较小的节点,表示它已经属于结果链表
l2->next = merge(l2->next, l1); return l2;
}
}
ListNode* sortList(ListNode* head){
if(!head || !head->next) return head;
ListNode *s, *f, *p; // 先用快慢指针分割出一半链表
for(s=f=head; f&&f->next; s=s->next, f=f->next->next)
p = s;
p->next = nullptr; // 打断,很重要
return merge(sortList(head), sortList(s));
}
迭代版 leetcode习题
// 从链表中剪出n个节点,并返回第n+1点
ListNode* cut(ListNode* head, int n){
auto p = head;
// 已经有了head, 只需要走n-1步
while(p && --n) p=p->next;
if(!p) return nullptr;
// 用打断实现剪除,打断前先保存
auto save = p->next;
p->next = nullptr;
return save;
}
// 合并操作,注意最后要接上还剩余元素的链表
ListNode* merge(ListNode* l1, ListNode* l2){
ListNode dummy(-1); auto c = &dummy;
while(l1 && l2){
if(l1->val < l2->val)
c->next = l1, l1 = l1->next;
else c->next = l2, l2 = l2->next;
c = c->next;
} c->next = l1? l1 : l2;
return dummy.next;
}
// 主函数
ListNode* sortList(ListNode* head){
if(!head || !head->next) return head;
int len = 0; // 计算链表长度
for(auto p=head; p; p=p->next) len++;
ListNode dummy(-1); dummy.next = head;
// 以step为间隔进行裁剪,两两合并,指数增大step
for(int step=1; step<len; step*=2){
// p指向前半部分的末尾,c指向向前处理节点
auto p = &dummy, c = dummy.next;
while(c){
// c会一直向后移动, head也会变
auto l = c, r = cut(l, step); // 左半部分
c = cut(r, step); // 右半部分
p->next = merge(l, r); // 合并后, 接在p后面
while(p->next) p = p->next; // p始终指向末尾
}
} return dummy.next;
}
栈
用栈模拟队列
中缀转后缀
从左到右开始扫描中缀表达式
遇到数字, 直接输出
遇到运算符
- 若为“(” 直接入栈
- 若为“)” 将符号栈中的元素依次出栈并输出, 直到 “(“, “(“只出栈, 不输出
- 若为其他符号, 将符号栈中的元素依次出栈并输出, 直到遇到比当前符号优先级更低的符号或者”(“。 将当前符号入栈。
扫描完后, 将栈中剩余符号依次输出
单调栈
算法
动态规划
约瑟夫环
d p i = ( d p i − 1 + m ) % i , i ≥ 2 dp_i = (dp_{i-1}+m)\ \%\ i, \ i \ge 2 dpi=(dpi−1+m) % i, i≥2
vector<int> dp(n+1); // dp[0]不使用
dp[1] = 0; // 只有一个人,那就是0
for(int i=2; i<=n; ++i)
dp[i] = (dp[i-1]+m) % i;
return dp[n];
最大子序和(连续子数组和)
d p i = m a x ( a i , a i + d p i − 1 ) dp_i = max(a_i, a_i+dp_{i-1}) dpi=max(ai,ai+dpi−1)
int pre = nums[0], res = pre;
for(int i=1; i<nums.size(); ++i){
pre = max(nums[i]+pre, nums[i]);
res = max(res, pre);
}
正则表达式匹配(递归型DP)
vector<vector<int>> f;
int s_len, p_len;
bool isMatch(string s, string p) {
s_len = s.size(), p_len = p.size();
// 末尾添加空字符处理边界
f.resize(s_len+1, vector<int>(p_len+1, -1));
// 边界条件 p为空时,不与s中的任何串匹配
for(int i=0; i<s_len; ++i) f[i][p_len] = false;
f[s_len][p_len] = true; // 只有都为空时,才匹配
// 从0,0开始匹配
return dp(0, 0, s, p);
}
bool dp(int i, int j, string &s, string &p)
{
// 记忆化搜索,将递归剪支
if(f[i][j] != -1) return f[i][j];
bool matched = (p[j]==s[i]) || (p[j]=='.');
if(j<p_len && p[j+1] == '*') // 扩展dp之前,写清楚边界条件,也有利于记忆
f[i][j] = j<p_len-1 && dp(i, j+2, s, p) //直接忽略b*的情况
|| matched && i<s_len && dp(i+1, j, s, p); // b至少出现一次,那么需要继续向后匹配
else
f[i][j] = matched && i<s_len && j<p_len && dp(i+1, j+1, s, p);
return f[i][j];
}
搜索
贪心法
剪绳子
int res = 1; // 条件是 m>=2, 58>=n>=2
int solve(int n){
if(n<4) return n-1; // 注意只能分成1*1或1*2的情况
if(n%3 == 1) res *= 4, n -= 4; // 余1时,分出2*2
if(n%3 == 2) res *= 2, n -= 2; // 余2时,分出2
while(n) res*=3, n-=3; return res;
}
贪心的正确性证明:
如果存在某一段 n i ≥ 5 n_i \ge 5 ni≥5,则拆出一个 3 3 3,那么拆出的数乘积比 n i n_i ni 要大,即:
3 ∗ ( n i − 3 ) = 3 n i − 9 ≥ n i ⇒ 2 n i ≥ 9 3*(n_i-3)=3n_i-9 \ge n_i \Rightarrow 2n_i \ge 9 3∗(ni−3)=3ni−9≥ni⇒2ni≥9
所以所有的绳子都小于 5 5 5,而 4 = 2 ∗ 2 4=2*2 4=2∗2 ,所以所有绳子不是 2 2 2 就是 3 3 3.
并且拆成 3 3 3 比拆成 2 2 2 价值更大: 3 ∗ 3 > 2 ∗ 2 ∗ 2 3*3 > 2*2*2 3∗3>2∗2∗2
所以贪心得到的结果是正确的。
二分查找
旋转数组的最小元素
if(n < 0) return -1;
// 先去除掉末尾等于a[0]的数,否则无法二分
while(n > 0 && a[n] == a[0]) n--;
// 如果无法去除任何一个,说明没发生旋转
if(a[n] >= a[0]) return a[0];
// 二分模板找最小元素
// 因为末尾中等于开头元素的部分被去除,靠
int l = 0, r = n; // 这里的n是已经去除末尾重复元素的n
while(l<r){
int mid = l + r >> 1;
if(a[mid]<a[0]) r = mid; // mid比a[0]小,说明mid在答案右边,并且mid可能是答案
else l = mid + 1; // >= 说明mid一定在答案的左边
}
k在有序数组中出现的次数
int getNumberOfK(vector<int>& nums , int k) {
if(nums.empty()) return 0;
int l = 0, r = nums.size()-1;
while(l<r){
// 查找k第一次出现的位置
int mid = l + r >> 1;
if(nums[mid]<k) l = mid+1; // l = mid+1, 所以使用模板1
else r = mid;
}
if(nums[l] != k) return 0; //没找到
int left = l; // 找到了,记录该位置
l = 0, r = nums.size()-1;
while(l<r){
// 查找k最后一次出现的位置
int mid = l+r+1 >> 1; // 模板2
// 这里用条件nums[mid]<=k才能区分right的左右两端
// 用nums[mid]
if(nums[mid]<=k) l = mid; // l = mid时要用模板2
else r = mid-1;
} return r-left+1; // 返回区间长度+1
}
第一个比k大的数
int l=0, r=a.size()-1;
while(l<r){
int mid = l + r >> 1;
if(a[mid]>k) r = mid; //mid也可能是结果
else l = mid+1; //l=mid时要用模板二
} return a[l];
找1~n中重复数(抽屉原理)
int l = 1, r = a.size()-1;
while(l<r){
int mid = l + r >> 1; // 把取值区间划分为[l, mid]和[mid+1, r]
int cnt = 0;
// 统计在区间[l, mid]内的数的个数
for(auto x:a) cnt += x>=l&&x<=mid;
// [l, mid]内的个数大于区间的长度,说明重复元素在这个区间里
if(cnt > mid-l+1) r = mid;
else l = mid+1;
}
实现平凡根
// n为数字,e为精度(容忍度)
float sqrt_n(float n, float e){
float x = 0;
if (n > 0 && e > 0){
float l=0, r=n;
while (l < r){
float mid = l+r>>1;
if (mid*mid < n - e) l = mid;
else if(mid*mid > n + e) r = mid;
else {
x = mid; break; }
}
} return x;
}
DFS(回溯)和BFS
矩形中的字符串路径
// 给定矩阵和字符串,枚举矩阵每个元素作为字符串起点
vector<vector<char>> m; string s;
for(int i=0; i<m.size(); ++i)
for(int j=0; j<m[0].size(); ++j)
if(dfs(i, j, 0)) return true;
bool dfs(int x, int y, int l){
if(m[x][y] != s[l]) return false; // 当前字符不相等就剪枝
// 否则,若已经匹配到末尾字符,说明找到一个路径
if(l == s.size()-1) return true;
// 上右下左
int dx[4] = {
-1, 0, 1, 0}, dy = {
0, 1, 0, -1};
m[x][y] = '*'; // 用其他字符表示已访问过
for(int i=0; i<4; ++i){
// 枚举所有可能,扩展分支
int a = x+dx[i], b = y+dy[i];
// 扩展分支时的条件
if(a>=0 && a<m.size() && b>=0 && b<m[0].size())
if(dfs(m, a, b, s, l+1)) return true;
}
m[x][y] = s[l]; // 回溯,还原现场
return false; // 能到这里的,都是匹配不成功的
}
应用二: 机器人可达范围(BFS/DFS)
int getSum1(int x){
int s=0; while(x) s+=x%10, x/=10; return s;
}
int getSum2(pair<int, int> xy){
return getSum1(xy.first)+getSum1(xy.second);
}
vector<vector<bool>> v; // 记录访问过的点
int res = 0; // 存结果
int solve(int k, int r, int c){
if(!r || !c) return 0;
// 经典BFS
queue<pair<int, int>> q;
q.push({
0,0}); // 起点
while(q.size()){
auto xy = q.front(); q.pop();
// 剪枝
if(v[xy.first][xy.second] || getSum2(xy) > k) continue;
// 访问并计数
v[xy.first][xy.second] = true; res++;
// 扩展, 四方向扩展技巧
int dx[4] = {
-1, 0, 1, 0}, dy[4] = {
0, 1, 0, -1};
for(int i=0; i<4; ++i){
int a=xy.first+dx[i], b=xy.second+dy[i];
if(a>=0 && a<r && b>=0 && b<c)
q.push({
a, b});
}
}; return res;
}
到叶节点和为k的路径
leetcode习题
void dfs(TreeNode* root, int k){
if(!root) return; // k有可能<0, 不能剪枝
k-=root->val, path.push_back(root->val);
if(!k && !root->left && !root->right)
res.push_back(path);
dfs(root->left, k), dfs(root->right, k);
path.pop_back(); // path共享,需要恢复现场
}
判断是否BST的后序遍历
bool dfs(int l, int r){
if(l>=r) return true; // 检查完毕,合法
//从右边起第一个比root小的位置k
int k = r-1; while(k>=l && s[k]>s[r]) --k;
//检查 i∈[l,k]是否都比root小
for(int i=k; i>=l; --i) if(s[i]>s[r]) return false;
// 需要递归检查
return dfs(l, k) && dfs(k+1, r-1);
}
字符串分割成回文串
用dfs枚举当前字符串长度内所有可能,如果s[0...i)是回文则dfs(s[i,n)) 终点是i==n, n是当前字符串长度
void dfs(const string &s, vector<string> &path){
int n = s.size();
for(int i=1; i<=n; ++i){
auto t = s.substr(0, i); // 前缀s[0...i)
if(isHuiwen(t)){
path.push_back(t);
// 递归终点是前缀枚举到字符串末尾, 即i==n
i==n ? res.push_back(path) : dfs(s.substr(i, n-i), path);
// 恢复现场
path.pop_back();
}
}
}
排序
leetcode习题-第k大的数
数组快速排序
int partition(vector<int>& a, int l, int r){
int i = l-1, j = r+1, pivot = a[l+r>>1];
while(i<j){
do i++; while(a[i]<pivot); // 左边第一个不小于pivot的数
do j--; while(a[j]>pivot); // 右边第一个不大于pivot的数
if(i<j) swap(a[i], a[j]);
} return j; // 为什么是j呢? i为什么是错误的?
}
// 递归版
void qSort(vector<int>& a, int l, int r){
if(l>=r) return;
int mid = partition(a, l, r);
qSort(a, l, mid-1), qSort(a, mid+1, r);
}
// 迭代版
void qSort(vector<int>& a, int l, int r){
if(l>=r) return; stack<pair<int,int>> s;
s.push({
l,r}); // 初始区间
while(s.size()){
l=s.top().first, r=s.top().second, s.pop();
int mid = partition(a, l, r);
if(l<mid) s.push({
l,mid});
if(r>mid+1) s.push({
mid+1,r});
}
}
数组归并排序
vector<int> a(n), t(n); // 数组的归并排序无法避免要用辅助数组
void merge(int l1, int r1, int l2, int r2){
int i=l1, j=l2, k=l1; // k是合并链表的指针
while(i<=r1 && j<=r2) t[k++] = a[i]<a[j]? a[i++]:a[j++];
while(i<=r1) t[k++] = a[i++];
while(j<=r2) t[k++] = a[j++];
// 默认区间是[l1,r1,l2,r2]
for(i=l1; i<=r2; ++i) a[i] = t[i];
}
void mSort(int l, int r){
if(l>=r) return; // 递归终点
int mid = l + r >> 1;
mSort(l,mid), mSort(mid+1, r);
// 递归完[l,mid]和[mid+1,r]已经有序
merge(l, mid, mid+1, r);
}
字符串
字符串压缩 (双指针)
abbbcdd压缩为a3bc2d
i 指向当前处理到的位置,j 向前移动,指向最近的与 i 不相等的字符
int i = 0, j = 0, n = s.size();
while(j1) // 若i,j不相邻,需要压缩为数字
res += to_string(j-i-1);
// 无论压不压缩,都需要添加一个字符
res += s[i];
i = j; // i移动到的位置
}
去除偶数
以指定字符分割字符串
// 接收整行字符串,转为iss
string s; getline(cin, s); istringstream iss(s);
vector<string> sv; // 分割结果存在一个vector中
while(getline(iss, s, ',')) // 假设以,分割
sv.emplace_back(move(s));
进制转换
// 十进制转二进制,循环 %2 和 /2
void d2b(int dec, stack<int> &bin){
do bin.push(dec % 2); while(dec /= 2);
}
// 二进制转十进制,循环 *2 + c-'0'
void b2d(string bin, int &dec){
//
for(int i=0; i<bin.size(); ++i)
dec = 2*dec + bin[i]-'0';
}
循环左移
问题抽象为 A B → B A AB \rightarrow BA AB→BA, 借鉴矩阵算法 B A = ( A T B T ) T BA=(A^TB^T)^T BA=(ATBT)T 可以达到 O ( n ) O(n) O(n).
reverse(s.begin(), s.begin()+k); // A^T
reverse(s.begin()+k, s.end()); // B^T
reverse(s.begin(), s.end());
位运算
计算二进制中1的个数
int count1(int n){
// 拿一个1不断右移,最后移出int范围
int res = 0, a = 1;
while(a){
// 不能改写成 res+=(n&a)
if(n&a) res++;
a <<= 1;
} return res;
}
特殊高频
实现LRU
数据结构采用哈希链表(list+unordered_map)
哈希表中存list的迭代器,方便代码的编写
函数l1.splice(it1, l2, it2)会把l2中的it2剪到l1的it1位置
如果l1==l2则it2不会失效,否则会失效
// 哈希链表 = 双向链表 + 哈希表(键+迭代器)
struct node {
int k, v;}; list<node> l; int c;
unordered_map<int, list<node>::iterator> m;
int get(int k) {
if(!m.count(k)) return -1;
//命中时移到 l开头,表示最新访问
l.splice(l.begin(), l, m[k]);
return l.front().v;
}
void put(int k, int v) {
//如果键已存在,删除旧数据
if(m.count(k)) l.erase(m[k]);
//在 l开头插入新数据,新建 m记录
l.push_front({
k,v}), m[k] = l.begin();
//超载,删除 l的末尾和它在 m中的对应记录
if(m.size()>c) m.erase(l.back().k), l.pop_back();
}
洗牌算法
for(int i=n-1;i>=0;i--){
//每次随机取0~i之间的下标和第i张牌交换
swap(arr[i],arr[rand()%(i+1)]);
}
双指针系列
合并区间 (排序+双指针)
vector<vector<int>> merge(vector<vector<int>>& intervals) {
int n = intervals.size(); if(n<2) return intervals;
sort(intervals.begin(), intervals.end(), [](vector<int>& i1, vector<int>& i2){
return i1[0]<i2[0] || i1[0]==i2[0]&&i1[1]<i2[1];});
vector<vector<int>> res;
int b = intervals[0][0], e = intervals[0][1];
for(int i=1; i<n; ++i){
// 当前区间左端点落入前一个区间,更新e
if(intervals[i][0] <= e) e = max(e, intervals[i][1]);
// 否则记录区间,更新b,e
else res.push_back({
b, e}), b = intervals[i][0], e = intervals[i][1];
} res.push_back({
b, e}); // 最后一个区间要额外添加
return res;
}
跳跃游戏 (是否可以到达最后)
题目: a i a_i ai表示当前位置最远可走步数,判断能否到达最后
思路:j 表示当前可到的最远位置,每次移动 i 都要尝试更新 j = m a x ( i + a i , j ) j=max(i+a_i, j) j=max(i+ai,j)
也是一种贪心思想:每次在当前可走范围内选一个能走得最远的格子走
for(int i=0, j=nums[0]; i<=j; ++i){
if(j>=nums.size()-1) return true;
j = max(j, i+nums[i]);
} return false;
删除数组中的偶数
总体思路就是将所有奇数都换到前部分,然后删掉剩下的数. i 指向当前要占有的位置,j 向前移动,指向最近的奇数
void removeEven(vector<int> &a){
int i = 0, n = a.size();
// 找到第一个偶数
while(i<n && a[i]&1) i++;
if(i==n) return; // 没有要删除的元素(其中包括空数组)
// j先行一步找奇数
int j = i + 1;
while(j<n){
// j一直走到最近的奇数
while(j<n && a[j]%2==0) j++;
// 把奇数交换到i位置,各后移一位
if(j<n) swap(a[i++], a[j++]);
}
// 只保留前i个数,它们都是奇数
a.erase(a.begin()+i, a.end());
}
螺旋打印
画图移动u,d,l,r四个指针 leetcode习题
if(matrix.empty()) return vector<int>();
int n = matrix.size(), m = matrix[0].size();
int u=0, d=n-1, l=0, r=m-1, s=0, i;
vector<int> res(n*m);
while(true){
for(i=l; i<=r; ++i) res[s++] = matrix[u][i];
if(++u > d) break;
for(i=u; i<=d; ++i) res[s++] = matrix[i][r];
if(--r < l) break;
for(i=r; i>=l; --i) res[s++] = matrix[d][i];
if(--d < u) break;
for(i=d; i>=u; --i) res[s++] = matrix[i][l];
if(++l > r) break;
} return res;
二维数组的查找
int i = r, j = 0; // 从左下角开始找
while(i>-0 && j<=c){
if(a[i][j] == target) return true;
else if(a[i][j] > target) i--; // 大的话往上找
else j++; // 小的话往右找
}
数学
快速幂
double Power(double base, int exp){
bool is_minus = exp<0;
double res = 1; // 得数
while(exp){
// 若指数的某位为1,此时底数有贡献
if(exp&1) res *= base;
exp >>= 1, base*=base; // 指数右移底数翻倍
} return res;
}
判定质数
if(u<2 || u%2 == 0) return false;
// 3 ~ sqrt(u)
for (int i=3; i<=sqrt(u); i+=2)
if(u%i == 0) return false;
return true;
求a,b的最大公约数/最小公倍数
int gcd(a, b){ // 欧几里得算法求最大公约数
return b? gcd(b, a%b) : a;
}
int lcm(a, b){ // 最小公倍数 = a/gcd * b
return a/gcd(a,b) * b;
}
扩展欧几里得算法: 求解 a x + b y = g c d ( a , b ) ax+by=gcd(a,b) ax+by=gcd(a,b)的一组解 ( x , y ) , d = g c d ( a , b ) (x,y),d=gcd(a,b) (x,y),d=gcd(a,b)
void exgcd(a, b, &d, &x, &y){
if(b==0)//若b=0,则最大公约数为a,a=1*a+0*0
d=a, x=1, y=0;
else {
exgcd(b,a%b,d,x,y);
int t=x; x=y; y=t-(a/b)*y;
}
}
组合数: C n m = n ⋅ ( n − 1 ) ⋅ ⋅ ⋅ ( n − m + 1 ) m ! C_n^m = \frac{n \cdot (n-1) \cdot \cdot \cdot (n-m+1)}{m!} Cnm=m!n⋅(n−1)⋅⋅⋅(n−m+1)
卡特兰数: C 2 n n − C 2 n n − 1 = C 2 n n n + 1 C_{2n}^n-C_{2n}^{n-1}=\frac{C_{2n}^n}{n+1} C2nn−C2nn−1=n+1C2nn
等比数列和: S n = a 1 ( 1 − q n ) 1 − q ( q ≠ 1 ) S_n=\frac{a_1(1-q^n)}{1-q}(q \ne 1) Sn=1−qa1(1−qn)(q=1)
应用: 1 + 1 2 + 1 4 + ⋅ ⋅ ⋅ = 2 ⇒ 1 2 + 1 4 + ⋅ ⋅ ⋅ = 1 1+\frac{1}{2}+\frac{1}{4}+ \cdot \cdot\cdot =2 \Rightarrow \frac{1}{2}+\frac{1}{4}+ \cdot \cdot\cdot = 1 1+21+41+⋅⋅⋅=2⇒21+41+⋅⋅⋅=1
操作系统
按下开机键发生的事
计算机通电后,最先运行BIOS进行硬件自检,然后根据用户指定的启动顺序从第一个设备启动,先加载第一个物理扇区,然后由主引导记录从分区表中查找活动分区,再加载该分区的第一个扇区中的引导记录到内存中,然后引导操作系统启动。
进程内存模型 (网易一面)
Linux通过页表管理内存,因此进程不能直接访问物理地址,故进程使用的地址均为虚拟地址. 操作系统留出虚拟地址最高的一部分空间给内核,剩余的空间就是进程使用的用户空间(但是也可以通过系统调用访问到内核空间)。但是实际上映射到物理空间时,内核是从最低地址开始的。
每个进程都拥有整个用户空间大小的虚拟空间,彼此互不干扰,可以看作是内存沙盒。它的布局从高到低为栈,内存映射段,堆,未初始化数据段,初始化数据段,代码段。
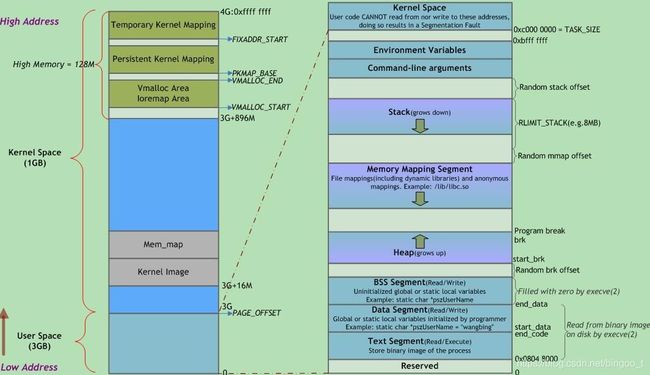
这个沙盒模型几乎每个进程都是相同的,因此为攻击程序漏洞的人提供了一些便利,他们可以利用这个模型的规律,探索出一些程序引用的绝对内存地址。所以近些年地址空间的随机排布也流行起来,具体可以在每个段的起始地址加上随机的偏移量来打乱布局。
堆与栈的区别
一个形象的比喻,使用栈就像去餐馆吃饭,只负责点菜,付钱,吃完就可以走,高效便捷;使用堆则需要自己买菜,自己决定买多少菜,吃完还得洗碗洗锅倒垃圾等,时间花费比较大,但可以自由发挥菜单。
栈就是先进先出的栈结构,是一块连续的内存空间,资源的分配和释放只能按顺序,而且空间比较小,适合由系统来管理,放那些程序运行时候的必要数据,例如局部变量,函数参数的保存;
堆则类似于链表,堆的空间受限于运行时有效的虚拟内存,可以自由分配和释放,具有非常大的灵活性,可以适应程序运动的动态需求。
(网易一面) 进程fork出一个子进程后,它们的内存总占用是多少呢?
fork()出来的子进程只是拥有了和父进程一样的页表,指向相同地址空间的页帧。其中代码段部分是不会变的,所以父子进程将共享一份。对于数据段,当需要进行修改时,才会复制出一份,然后子进程的页表项指向复制的那部分内存。
内存管理
段页式管理,以一定大小的内存单元为一页,将非连续的地址空间映射到连续的线性页表中。
内存泄漏? 怎么避免?
释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
- 申请与释放的对象是否一致:static int count,构造函数count++, 析构函数中count–, 程序结束前析构所有类,看最后是否输出count=0
- 检查类中的空间是否全部释放
- new和delete是否成对出现
- 是否存在提前跳出函数的的地方没释放内存
- 子类在析构是是否释放父类申请的空间。
- 通过使用智能指针来减少内存泄漏的发生
手撕智能指针
虚拟内存是什么?可以解决什么问题?
指的是将物理内存上的一块空间(也称为一页)映射到一个虚拟地址空间,使得逻辑上似乎有很大的内存空间可使用,但实际上只有一部分内容被装载到物理内存中,其他部分在硬盘上。当程序引用到不在物理内存中的页时会产生缺页中断,操作系统就从硬盘上把缺失的部分装载进物理内存,然后继续执行程序。内存满了的话还会执行换页算法。
可以解决内存资源稀缺,相当于拿一部分硬盘来充当内存使用,动态进行加载。对一个进程来说,它可以在逻辑上认为自己拥有连续可用的内存空间。从安全性上,程序员只知道逻辑地址,这样也能保护一些不希望被修改的物理地址的内容被修改。
进程的虚拟物理地址如何转换的?
首先先根据虚拟地址检索快表,找到对应的页表项,然后把页表项中的物理块号和页内地址拼成物理地址。
如果在快表中没有找到,就去内存中查找页表是否存在,如果存在就修改快表,并且按相同方式拼成物理地址。
如果内存中也没找到,就产生缺页中断,然后从硬盘中找需要的页调入内存,之后按相同方式拼成物理地址。
Cache缓存
缓存为什么高效? 局部性原理: 时间局部性和空间局部性。
如何保持缓存高效?换页算法FIFO, LRU, LFU
进程与线程的区别? 进程开销为什么会大? 为什么线程可以提高并发性?
进程是一个程序在一个数据集合上的一次运行过程,线程是进程中的一个实体,是程序执行流的最小单元。
- 资源上,进程是资源分配的基本单位,线程不拥有资源,可以访问属于进程的资源。
- 调度上,线程是独立调度的基本单位,同一进程中线程可以自由切换,不同进程中的线程切换会引起进程的切换。
- 开销上,进程要分配资源和回收资源,切换也要保存执行环境,所以开销大。而线程不拥有资源,只需要少量的寄存器内容,开销很小。
- 通信上,线程共享进程中的数据,可以直接读写数据进行通信;进程通信需要借助进程间通信IPC.
因为线程的切换开销比进程要小很多。所以同一个任务能让更多的线程参与,而不会大幅度影响到总的处理时间,因此可以提高并发性。
进程通信(同步)有哪些方式?线程的通信(同步)?
进程通信: 管道(命名) / 信号量 / 消息队列 / 信号 / 共享内存 / socket
管道? 命名管道和消息队列的区别?
管道是用于父子进程间的通信,命名管道则不受限制。命名管道需要进程自己实现通信机制,进程只能无条件接收;而消息队列独立于进程存在,读进程根据消息类型有选择地进行接收。
共享内存是什么?
内核专门留出的一块内存区用于进程共享,需要访问的进程把这部分内存映射到自己的私有地址空间,就可以直接读取数据。同步仍然需要用一些机制,比如信号量。
进程有哪些资源是共享/不共享的?
全局变量、静态变量、动态内存堆,文件等公共资源是共享的。函数堆栈,线程ID, 寄存器的状态等是独享的。
线程呢?
信号量? 信号与信号量的区别?
信号量就是计数器,限定多少访问量,有P操作和V操作,P表示若非0则通过否则阻塞,V表示释放。
线程通信: 互斥量(锁), 信号量,事件。
(字节一面) 锁和信号量的区别? 常见锁有哪些?
锁是二元信号量,另外锁必须由同一线程上锁和释放,信号量则不需要。互斥锁,读写锁,自旋锁
并行与并发的区别
所谓并发,就是多个任务流宏观上同时执行,实际微观上是顺序轮流执行,并发的概念产生的比较早,我们的分时操作系统就是基于这个原理。并行,是指多个任务真正的在多个处理器上面同时运行。
阻塞与非阻塞的区别
手撕生产者消费者模型
1、当队列元素已满的时候,阻塞插入操作;
2、当队列元素为空的时候,阻塞获取操作;
互斥锁保证在某个时刻只有一个线程访问临界区(push和pop),信号量的等待队列负责保存被阻塞的线程。
mutex mtx;
condition_variable consume, produce;
void consumer(){
while(true){
sleep(1);
unique_lock<mutex> lck; // 保证q.pop不会被其他线程抢占
// 将当前线程放入consume变量的等待队列,然后将互斥锁解锁
// 只有其他线程调用了notify,该函数才会返回,并重新加锁lck
while(q.empty()) consume.wait(lck);
q.pop(); // 消费, 要保证该操作的原子性,需要上锁
// 让produce变量的等待队列中的线程处于就绪态
produce.notify_all();
lck.unlock(); // 消费完释放锁
}
}
// 对称的
void producer(int id){
while(true){
sleep(1);
unique_lock<mutex> lck;
while(q.size()==maxSize) produce.wait(lck);
q.push(id); // 生产一个
consume.notify_all(); // 唤醒阻塞的消费者
lck.unlock();
}
}
简述 IO 多路复用
死锁
必要条件: 互斥,占有并等待,非抢占,循环等待
处理方法
-
死锁预防: 预分配策略(当满足运行条件才分配),允许强制,按序分配
-
死锁避免: 银行家算法
(字节二面) 详述一下银行家算法涉及的数据结构和算法流程?
- 死锁解除: 终止进程,打破循环;回滚到安全状态。
进程调度的算法有哪些?
批处理系统:要保证吞吐量和周转时间。先来先服务, 短作业优先,最短剩余时间优先。
交互式系统:要保证实时性。时间片轮转,优先级,多级反馈队列(前两者结合)。
僵尸进程和孤儿进程如何解决?
僵尸进程: 父进程并没有调用wait或waitpid获取子进程的状态信息, 并且自身陷入循环。子进程的进程描述符等还占用着系统资源无法被释放。
孤儿进程则是父进程结束后某个子进程还在运行,这些进程就变成孤儿进程。最终会被init进程(进程号为1)领养,并释放资源。
僵尸进程解决: 找到它的父进程, 将父进程杀死 ps -ef | grep
生产者消费者模型的好处? 同步与异步是什么? 协程是什么?
解耦,支持并发,支持忙闲不均。
同步就是指各个过程之间的执行状态是顺序进行的,不能跨越,一个调用者必须阻塞等待被调用者完成并返回状态以后,才能继续执行。比如用户登陆,是需要用户通过验证以后,才能登陆系统。
异步则是只是发送了调用的指令,调用者无需等待被调用的方法完全执行完毕;而是继续执行下面的流程。
协程就是微线程。
线程池要如何设计?
一个线程池包括四个基本部分:
- 线程管理器(ThreadPool):用于创建并管理线程池,包括创建线程、销毁线程池、添加新任务。
- 工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务。
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口、任务执行 完后的收尾工作、任务的执行状态等。
- 任务队列(TaskQueue):用于存放没有处理的任务,提供一种缓冲机制。
如何设计一个定时器?
Linux
介绍一下linux基本命令
find / -name # 查找文件
ps -ef | grep tomcat # 查看与tomcat有关的进程
kill -9 ID # 杀死进程
chmod 777 file # 改变权限
tar -xvzf / unzip -oq # 解压文件
tail -f file.log # 自动显示文件新增的内容,默认10行
kill和kill -9的区别?
kill发送SIGTERM,kill -9发送SIGKILL,SIGKILL不可屏蔽不可捕获
GDB调试?
# 编译时必须增加 -g 参数
break 文件名:行号
break 函数名
ignore 断点号 忽略次数
# 打印/自动打印变量值
print/display 文件名或者函数名::变量名
print *指针@长度
# 断点调试单步/进入/继续/直到/跳过
next/step/continue/until/skip
计算机网络
TCP/UDP的区别?适用场景?
三次握手四次挥手
流量控制和拥塞控制
TCP为什么可靠? UDP怎么实现可靠?
TCP为什么用流传输? 沾包指什么?
tcp和udp是否可以共用(同时监听)端口号? 为什么?
端口处于time_wait状态是什么原因? 怎么解决?
四次挥手突然断电,端口还能用吗? 怎么查询端口?
客户端断网, 服务器怎样才能知道要停止服务?
HTTP建立连接的过程
dns解析过程?
http和https的区别?
长连接和短连接的区别是什么?
在全球IP地址快速找一个IP,怎么做?
计算机图形学
三维空间直线方程怎么写? 直线中常量的意义
- 三维平面的交线
- 参数方程: 方向向量*t+一个点
恒过一个点.
(字节二面)点乘叉乘的物理意义? 作用?
介绍一下渲染管线?
另一种划分
应用阶段:进行一些碰撞检测等
几何阶段:顶点shader(其实就是坐标变换),裁剪
光栅化阶段:三角形遍历(生成片元),片元着色,测试混合(alpha测试,模板测试,深度测试)
一个三角形绘制到屏幕的过程?
加载顶点,坐标变换,装配成三角形,通过视口映射到屏幕,光栅化,着色
传统的光照模型? phong式光照模型? 介绍PBR?
以下都省略了材质系数和光强。
- Lambert = I a + m a x ( 0 , n ∗ l ) = m a x ( 0 , cos θ ) I_a+max(0, n*l) = max(0,\cos \theta) Ia+max(0,n∗l)=max(0,cosθ)
- halfLambert = I a + 0.5 + n ∗ l ∗ 0.5 I_a+0.5+n*l*0.5 Ia+0.5+n∗l∗0.5 将[0,1]映射到[0.5,1]上, 提亮暗部
- Phong = I L a m b e r t + ( v ∗ r ) n I_{Lambert}+(v*r)^n ILambert+(v∗r)n 在Lamert的基础上加上了高光,指数反比于视点方向与反射光的夹角
- Blinn-Phong = I L a m b e r t + ( n ∗ h ) n I_{Lambert}+(n*h)^n ILambert+(n∗h)n 其中h是半程向量,视点方向和光源夹角的一半的单位向量,为的是解决Phong模型在处理 v ∗ r < 0 v*r<0 v∗r<0时会出现高光断层的问题。
只知道PBR是基于物理的渲染方法,还有迪斯尼的BRDF就属于PBR
概率题
不等概率生成等概率
已知随机数生成函数f(),返回0的概率是60%,返回1的概率是40%。根据f()求随机数函数g(),使返回0和1的概率是50%,不能用已有的随机生成库函数。
两次调用f(), (0,1)和(1,0)的概率相等。因此如果和为1,就返回a==0&&b==1,否则重新调用。
随机数扩展
用[1,m]随机数生成器,生成[1,n]的随机. 参考博客
int rand_n(){
int val, t; //t为n的最大倍数且t
do{
val = m*(rand_m() - 1) + rand_m();
}while(val > t); // 如果>t就重新生成
return val%n + 1;
}
场景题
海量数据问题
快速获得高考排名
桶排序。分成751个桶,每个桶代表0~750任意分数。扫描一遍考生和分数,一个桶内的分数是相同的。获取排名只需要把桶内元素相加即可。
一个地图中有一个圆,怎么快速算出在圆内的人数?
首先用圆的外接正方形, 通过点的坐标过滤正方形以外的点, 在正方形内的点进行距离计算.
空投点如何在一个圆内均匀且随机?
算法1: 外接一个正方形, 在边长范围内随机生成(x,y),如果没有在圆内,就重新生成一次.
算法2: 极坐标法,先选一个 ρ \rho ρ 满足 x 2 + y 2 = ρ 2 x^2+y^2=\rho^2 x2+y2=ρ2, 它在圆内必须是随机的, 所以还要满足 ρ 2 = r a n d ∗ R 2 \rho^2 = rand*R^2 ρ2=rand∗R2, 所以 ρ = r a n d ∗ R \rho=\sqrt{rand}*R ρ=rand∗R, 然后再随机取一个角度 θ \theta θ
判断矩形相交
用中心点距离小于长宽的一半来判断:
∣ c x 1 − c x 2 ∣ ≤ ( w 1 + w 2 ) / 2 |c^1_x-c^2_x| \le (w_1+w_2)/2 ∣cx1−cx2∣≤(w1+w2)/2
∣ c y 1 − c y 2 ∣ ≤ ( h 1 + h 2 ) / 2 |c^1_y-c^2_y| \le (h_1+h_2)/2 ∣cy1−cy2∣≤(h1+h2)/2
或者四个顶点
bool isOverlap(const Rect& r1, const Rect& r2)
return !( ((r1.right < r2.left) || (r1.bottom > r2.top)) ||
((r2.right < r1.left) || (r2.bottom > r1.top)) );
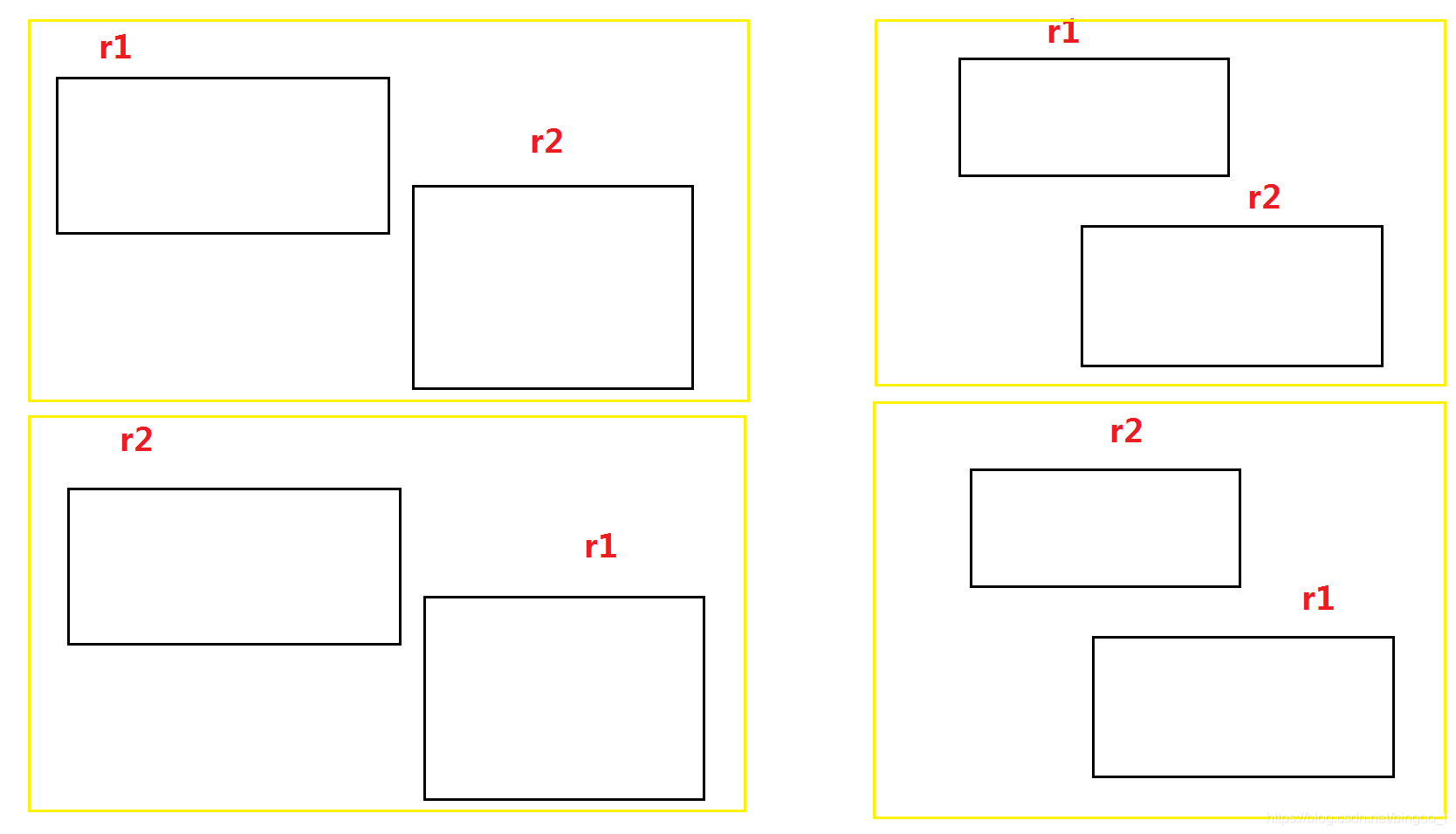
对英雄施加定时持续伤害,如何实现?
英雄内部增加受伤害的函数,时间间隔和伤害用参数传入。
附近地点搜索
一个二维平面,上面有很多店铺,(x,y)坐标,有的稀疏有的密集,现在要求给定点的最近店铺是哪一个?
首先可以先想到网格存储,然后搜索范围
进一步地考虑四叉树存储和搜索
最后给出业界的解决方案,R树+二维搜索或geohash,可以参考这个博客
微信抢红包怎么实现?
int remainSize, remainMoney;
double getMoney(){
if(!--remainSize) return remainMoney;
double maxMoney = remainMoney/remainSize * 2;
// 随机数
default_random_engine e(time(0));
uniform_real_distribution<double> u(0.01, maxMoney);
// 扣除随机金额
double money = u(e); remainMoney -= money;
return money;
}
一条公路上有多个点,每个点都有一辆车,给定公路坐标轴,车的速度和行驶方向,求最早两辆车相遇的时间?
实现线程安全的智能指针
分析玩网络游戏发生延迟的原因,从客户端,服务端,中间传输考虑
现在有一堆标记为危险的ip地址,如何管理,比如20.30.40.50,第三段区间为40-60的有危险,或者某一段出现特定值为危险,设计存储,查询ip的方法.
现在有个系统,查询频率很高,但是数据量太大了,设计一个分布式的系统
数据库
为什么要用B+树?
实际上,查询索引操作最耗资源的是磁盘IO。节点与节点之间的数据是不连续的,不同节点很可能分布在不同的磁盘页,那么一次读取节点就要操作一个磁盘io。也就是磁盘的寻址加载次数很多。而对于 B 树,由于 B 树的每一个节点,可以存放多个元素,所以磁盘寻址加载的次数会比较少。
B+树对比B树有如下好处:
- io次数少:b+树中间节点只存索引,不存在实际的数据,所以可以存储更多的数据。索引树更加的矮胖,io次数更少。
- 性能稳定:b+树数据只存在于叶子节点,查询性能稳定
- 范围查询简单:b+树不需要中序遍历,遍历链表即可。
数据库中范式用来解决什么?
解决数据的冗余性和插入异常等
举例来说,多个学生对应一个学院
智力题
两根香,一根烧完1小时,如何测量15分钟
开始时一根香两头点着,一根香只点一头,两头点着的香烧完说明过去了半小时,这时将只点了一头的香另一头也点着,从这时开始到烧完就是15分钟。
海盗分金币(博弈论)
参考博客
假设方案的提出顺序:
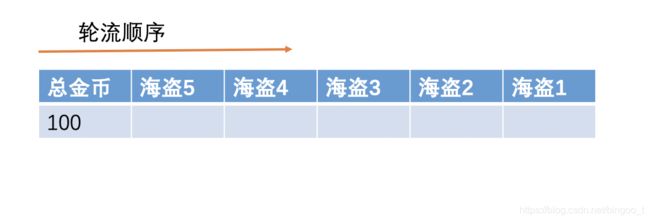
仅剩2个海盗时:
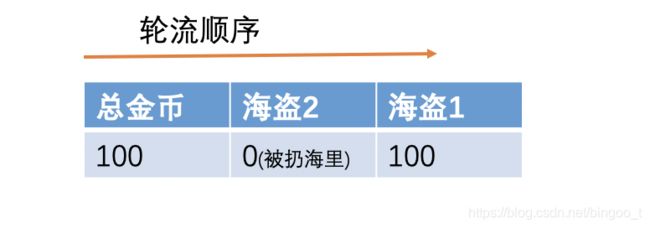
仅剩3个海盗时:

当然也可以分1个给海盗2(天行九歌里的三姬分金)
4个海盗:
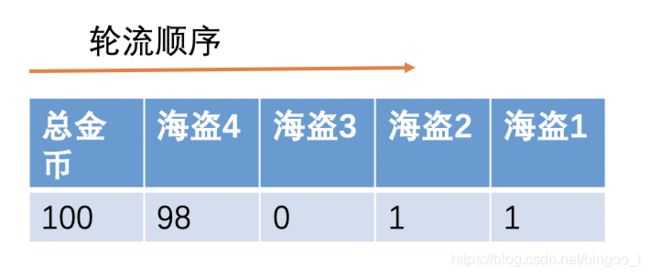
5个海盗:

扔鸡蛋
折半查找 或 平方根查找
最优解: 100层,2个鸡蛋, 转化为扔k次,能到达的最高层数. 最少需要14次: 14-27-39-50…
红白球
一个箱子1红, 另一个49红+50白, 概率最大约等于0.75
过桥问题
能者多劳: 快的人多负责传递手电筒
假设按速度排序为: A,B,…,Y,Z
有以下两种方案,使得最慢的两个人过河并且手电筒回到原岸:
(1) A+Z过河,A回,A+Y过河,A回 花费2A+Y+Z
(2) A+B过河,A回,Y+Z过河,B回 花费2B+A+Z
那么每次选两种方案最小值,就能使得问题规模减2
边界条件是
(1) 剩余A,B,C时,最短要花费A+B+C
(2) 剩余AB时,要花费B
(3) 剩余A时,要花费A
倒水问题
用小桶的倍数不断对大桶取模,举例来说,要用5升和3升的桶得到4升的水:
3 % 5 = 3 装满3桶倒入5桶
6 % 5 = 1 再装满3桶倒入5桶,5桶满了就倒空
9 % 5 = 4 把3桶的水倒入5桶,再装满倒入
蓝眼睛红眼睛
有多少个红眼睛,他们就会在第几天集体自杀, 思路参考
HR面
对手游怎么看?
说说自己的缺点
强迫症, 对待细节太认真, 追求极致.
解决思路:给自己预设一个提前的ddl.
做决定不能很快, 需要听取很多建议. 但是我不是盲目听取, 会有自己的想法, 并且随着经验和经历的积累, 我相信会越来越善于做出自己的决定
如何看待加班?
首先我觉得加班对一个快速发展的企业来说,是非常正常的.
第二, 如果是自己的工作任务没有完成, 那么加班是理所当然的. 这时候我会先从自己的角度去反思为什么任务没有完成, 是自己拖沓还是专业技能不够. 这些都排除以后, 我会再去反思上面交待的任务难度是不是现阶段的我能够完全承担, 必要的时候我会跟我的直系领导沟通一下.
第三就是, 遇到一些突发的紧急状况需要加班,这个时候肯定是站在公司的整体利益的角度来考虑的, 我会竭尽所能帮助公司解决遇到的问题.
遇到过的最大的技术问题和非技术问题是什么? 怎么解决的?
未来三年的职业规划? 期望达到的薪资情况?
你觉得程序员和哪个职业最相似?
emmm搬砖工人? (大雾
那就建筑师吧
最擅长的语言? 为什么选择这个语言?
C++, 因为它快. (垃圾语言毁我青春