普罗米修斯?古希腊泰坦之神?异形?不,新一代企业级监控组件—Prometheus!
文章目录
-
- Prometheus + Grafana 监控效果图
- 一、Prometheus 简介
-
- Prometheus成长历程
-
- Prometheus诞生背景
-
- 云时代的到来
- Prometheus 监控特点
- 二、Prometheus 架构模型
-
- Prometheus 核心组件
- 三、Prometheus 指标设计
-
- 指标设计规范的诞生
- 四、Prometheus 存储模型
-
- LSM 结构模型
-
- LSM 模型—写操作
- LSM 模型—读操作
- LevelDb 结构模型
-
- LevelDb模型—写操作
- LevelDb模型—读操作
- Prometheus 存储引擎
-
- 时间分片策略
- 时间分片策略优势
- 磁盘文件结构
-
- block
- meta.json
- chunks
-
- Cut切分策略
- Index
-
- 索引生效过程
- tombstones
- 数据压缩「Data Compress」
-
- Chunk Compress
-
- 双增量策略「delta-of-delta」
- XOR策略
- 五、Prometheus集群部署
-
- 单小集群解决方案
-
- 部署架构
- 多集群部署解决方案
-
- 联邦策略
- Thanos 高可用解决方案
- 部署架构
- 大集群场景解决方案
-
-
- 分片策略
-
- Q&A
- 附录
普罗米修斯?古希腊泰坦之神?异形? 都不是,Prometheus是新一代企业级实时监控组件,大小厂牌都在用,监控届扛把子的存在。
掌握了这个——普罗米修斯,大小厂牌工作任你挑选,升职加薪如丝般顺滑。
下面给大家**全方位刨析一下 Prometheus **。
注:本文对初级同学相对存在门槛,可以收藏关注,在成长中积累….
Prometheus + Grafana 监控效果图
这里先放个 Prometheus + Grafana 集成效果图,让刚认识 Prometheus 监控系统的同学脑海中有个基本概念。
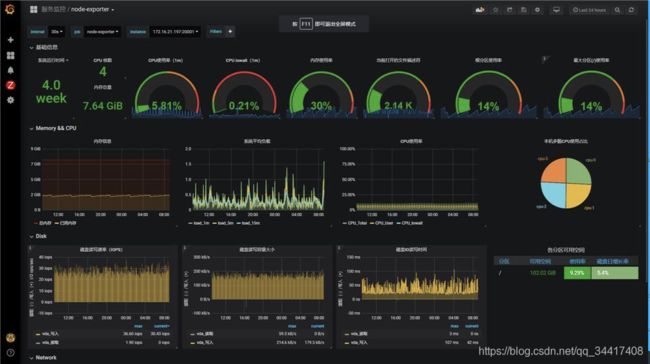
对,这样式的就是企业级实时监控可视化面板,下面还有…

感觉怎么样?看着还行吧,哈哈哈,下面进入正题,刨析一下 Prometheus …细品,品…
一、Prometheus 简介
Prometheus 作为新一代的开源实时监控系统,提供了 Kubernetes ,数据库,消息队列,基础架构等各类技术组件的监控能力,实时洞察在线服务各个指标动态变化,帮助快速数据分析及问题定位。
在全面拥抱云原生时代中,为云原生架构提供安全保障,形成市场竞争中真正的敏捷力量!
Prometheus成长历程
- 2012年
SoundCloud 启动 Prometheus孵化项目。 - 2015年
Prometheus在GitHub 完全开源后,STAR数直逼9K,同时被很多公司作为监控方案采用。 - 2016年
Prometheus 加入 CNCF(Cloud Native Computing Foundation),继 Kubernetes 加入后的第二个项目成员。 - 2017年
Prometheus 2.0 发布,这是Prometheus的一个重要的里程碑,在集成TSDB后的Prometheus 2.0,与Prometheus 1.8相比,CPU使用率降低到20%-40%,磁盘I/O、磁盘空间使用率降低到33%-50%,查询负载通常平均<1%, 可以支持单机每秒1000w个指标的收集。 - 2020年
现在 Prometheus STAR数已超40K,已经是云原生架构中不可分割的重要一部分……
Prometheus诞生背景
Prometheus 顺应云时代浪潮滚滚而来,推动技术架构走向敏捷,面向未来…
云时代的到来
软件正在吞噬世界。 ——Mark Andreessen
正如 Mark 所说“软件正在吞噬这个世界“,21世纪软件服务已经渗透到了世界的各个角落,云服务也是其中的一个,悄无声息地蔓延开来….
随着云基础设施「包含公有云、私有云、混合云」的蓬勃发展,应用服务上云的浪潮来势汹汹……
基于云原生的架构,云可以提供弹性、自主的提供和释放计算、网络、存储等资源;同时服务的部署更加安全、迅速,软件交付、持续服务、用户体验能力无限提升;使公司在市场竞争中拥有最敏捷的力量优势。
服务上云已经势不可挡! 上云,伴随而来的是需要大量新的技术组件提供云特性支持,而 Prometheus 就是其中一员。
Prometheus 拥抱云原生,作为 CNCF 第二大项目,对云基础设施提供全面的兼容服务,实时动态监测服务节点及容器各项指标,是云原生架构中安全及业务性能强有力的保障,是其不可或缺的一部分。
Prometheus 监控特点
Prometheus 顺应云原生而诞生,对云原生提倡的 容器化、容器编排、服务代理、发现和治理…等方案都做了兼容,这也是其最突出的特色。
- 1、具有 Metrics 名称和 key/value 对标识的时间序列数据的多维数据模型
- 2、利用数据模型进行有效的警报和图形展示的查询语言
- 3、支持本地存储,不依赖分布式存储文件系统
- 4、通过 HTTP WEB 交互方式获取时间序列数据
- 5、可配置推送的方式进行时间序列数据采集
- 6、支持 Client 通过服务发现和静态配置发现
- 7、兼容多种视图模式
- 8、Docker、Kubernetes 原生支持
- 9、…
那么,是什么样的设计满足这些特色能力呢?好奇感十足,下面抛出具体的架构图,来分析分析,它咋那么牛!!!
二、Prometheus 架构模型
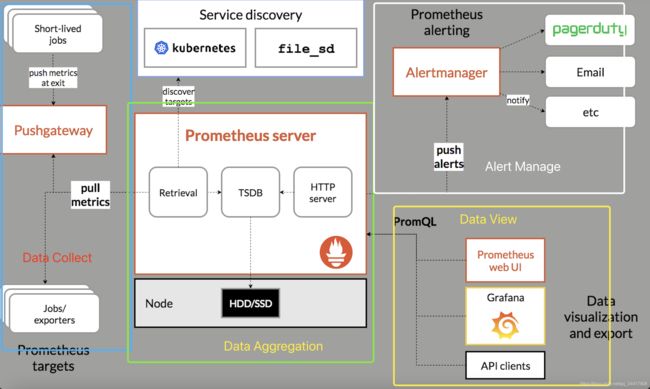
Prometheus 组件可分为数据采集、数据聚合、数据展示、告警四部分。
- 数据采集可采用 “侵入式” 或 “ Explore 格式转换「非侵入式」” 的方式收集,按照配置的刮擦粒度以 “ API ” 的形式与数据聚合模块交互
- 数据分析将采集到的指标数据进行存储,本地存储使用类 LeveDB 结构模型
- 数据展示通过使用 PromQL 过滤数据,渲染可视化面板、视图
- 数据告警把符合配置阈值条件的数据推送给用户,进行告警调度
Prometheus 核心组件
Prometheus 拥有四大核心组件,分别为 Prometheus Server、Pushgateway、Alertmanager、Exporter 完成主要监控任务。
- Prometheus Server:用于刮擦目标 Job Metric、存储本地TSDB数据
- Pushgateway:推送网关,以 Push 模式将本地 Metrics 数据推送到PushGateway
- Alertmanager:警报组件,配置分组、警报发送源
- Exporter:暴露本地 Metrics 给 Prometheus ,让Prometheus 通过 Pull 模式刮擦目标Job指标数据
这里讲了架构和核心组件,大概晓得了基本配置,可具体用的时候呢?起步姿势是啥呢?来来来,下面来聊下,先从监控数据设计入手…
三、Prometheus 指标设计
Prometheus 指标由两部分组成,可简单概括为
K『 k「metricName」+ v「key/val」+ T「 timestamp 」』—— V『sample』
- K:— k「metricName」-v「key/val」+T「 timestamp 」
- V:— sample

内层k/v对代表了数据维度,每个 metricName 标识了监控指标的唯一身份,T为时间戳,Sample 则是当前指标的数值。
外层Key包含 Metric Name、Labels、Timestamp;Value 包含 Sample 。
指标设计规范的诞生
为什么这样式约束监控指标呢/?令人深思的问题!Why?
仔细品品之后,发现!!!
在实时监控系统中,需要实时监听个目标Job的各项数据,统计实时数据及勾勒时间为轴的各类可视化面板。
- 从数据属性来看,自带时间属性,天然时序数据。
- 从数据读写来看,是垂直写,水平读的场景,读写比例占比很大。

综合上述,选择了K-V数据模型有了充分的理由,没毛病!!
数据已经有了,那么怎么进行数据聚合存储呢?不慌,下面就刨析存储模型!!
四、Prometheus 存储模型
数据模型建立在存储模型之上。 ——《 Data Structure Design 》
首先在基于云服务的实时监控场景中,存储模型它需要满足这几个条件:
在自动弹性伸缩的云原生环境中, 实例的产生和消亡更加频繁,即系统中将会存在大量时序数据指标,但其中只有部分处于活跃状态,这会在很多方面带来挑战:
- 1、有限的本地存储,如何存储大量时序避免资源浪费?
- 2、海量数据中,如何定位被查询的少数几个时序?
围绕这几个条件,Prometheus 本地存储存储模型选择了,基于 LSM 结构的类 LevelDB 组件。但是,为什么呢?下面来说道说道!!!
LSM 结构模型
LSM 思想模型中将数据读写进行分层,提升读写性能,主要针对的场景是写密集、少量查询的场景。
主要在 key-value 存储系统中应用,如 LevelDB,RocksDB,还有分布式行式存储数据库 Cassandra 也用了基于 LSM-tree 的存储模型。
在实际生产环境中,日常的日志存储,一般都是先把日志在内存缓存,批量以追加的形式写入磁盘。
LSM ,顾名思义,Log Structured「日志结构」、Merge「合并」是像写日志一样的思想模型,数据模型如下:

LSM 模型是一个多层结构,就像一个树一样,上小下大。
首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。
LSM 模型—写操作
1、首先写入数据到 memory 中 C0 层。
当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是 Compaction(合并)。
2、合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。
- 「注意数据的写入可能重复,新版本需要覆盖老版本。什么叫新版本,我先写(a=1),再写(a=233),233 就是新版本了。假如 a 老版本已经到 Ck 层了,这时候 C0 层来了个新版本,这个时候不会去管底下的文件有没有老版本,老版本的清理是在合并的时候做的。」
- 「写入过程基本只用到了内存结构,Compaction 可以后台异步完成,不阻塞写入。」
LSM 模型—读操作
最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有要查的 k,再查 C1,逐层查。
LSM 盘的差不多了,不过 Prometheus 只是借鉴了模型,离实际实现还有一步——看看 LevelDB…
LevelDb 结构模型
Prometheus 本地是基于 LevelDb 完成监控指标的存储,LevelDb 是一款基于K-V的时序数据库。
其设计基于 LSM ,但又不同于 LSM ,在读写性能上继承 LSM 优异的水平,在结构上更加严谨,更具实操意义。
LeveDb 结构图大体类似 LSM ,有细节不同:

LSM-tree 被分成三种文件,第一种是内存中的两个 memtable,一个是正常的接收写入请求的 memtable ,一个是不可修改的 immutable memtable 。另外一部分是磁盘上的 SStable (Sorted String Table),有序字符串表,这个有序的字符串就是数据的 key 。SStable 一共有七层(L0 到 L6)。下一层的总大小限制是上一层的 10 倍。
加入了WAL机制,提高生产环境中的容灾能力;
在数据层级中,做了层级限制,以提升有限资源利用率;
……
LevelDb模型—写操作
1、首先将写入操作写 WAL 日志中,接下来把数据写到 memtable中,当 memtable 满了,就将这个 memtable 切换为不可更改的 immutable memtable,并新开一个 memtable 接收新的写入请求。而这个 immutable memtable 就可以刷磁盘了。这里刷磁盘是直接刷成 L0 层的 SSTable 文件,并不直接跟 L0 层的文件合并。
2、每一层的所有文件总大小是有限制的,每下一层大十倍。一旦某一层的总大小超过阈值了,就选择一个文件和下一层的文件合并。
- 「数据重复场景:L0 层的多个文件在同一层,有先后关系的,后面的同个 key 的数据也会覆盖前面的。会为每个 key-value 加个版本号。在 Compaction 时候应该只会留下最新的版本」
LevelDb模型—读操作
先查 memtable,再查 immutable memtable ,然后查 L0 层的所有文件,最后一层一层往下查。
LevelDb 存储模型就是这样,大的框架流程,我们已经了解了,下面结合业务数据走进Prometheus 存储引擎吧!!!
Prometheus 存储引擎
Prometheus 存储引擎基于 LevelDb,结合自身业务特点,设计实现自身的存储引擎。
时间分片策略
Prometheus 存储引擎将所有时序数据按时间分片,在时间维度上将数据划分成互不重叠的 blocks,如图:

那么为什么要以时间分片这种形式存储呢?一个监控指标一个文件是不是也可以?
时间分片策略优势
以时间分片这种形式是经过 Prometheus1.0、2.0、3.0版本之后,最终确定的版本,也是最优的、最适合这种场景的方式,它具有以下几个优势:
1、当查询某个时间范围内的数据,通过时序直接定位至目标 blocks,加快查询速度
2、写完一个 block 后,我们可以将轻易地其持久化到磁盘中,只涉及到少量几个文件的写入,减轻磁盘IO压力
3、新的数据,也是最常被查询的数据会处在内存中,提高查询效率
4、每个 chunk 大小不固定,我们可以选择任意合适的大小,选择合适的压缩方式,提升资源利用率
5、删除超过留存时间的数据变得异常简单,直接删除整个文件夹即可
磁盘文件结构
引擎存储在磁盘中的文件结构如下图:
 为了防止数据丢失,所有新采集的数据都会被写入到 WAL 日志中,在系统恢复时能快速地将其中的数据恢复到内存中。
为了防止数据丢失,所有新采集的数据都会被写入到 WAL 日志中,在系统恢复时能快速地将其中的数据恢复到内存中。
block
每个 block 内部存储着该时间窗口内的所有时序数据,它同时拥有自己的 index 和 chunks 。除了最新的、正在接收新鲜数据的 block 之外,其它 blocks 都是不可变的。
block 结构形式如下图:

block 的实质就是将一段时间里的内存数据组织成文件形式保存下来。
meta.json
meta.json 存储当前 block 的一些元信息。
{
"ulid":"01EPVA7WJ5DXTV6FR06VJ0CT40",
"minTime":1605081600,
"maxTime":1605085200,
"stats":{
"numSamples":1359295562,
"numSeries":441979,
"numChunks":11207472
},
"compaction":{
"level":1,
"sources":[
"01EPVA7WJ5DXTV6FR06VJ0CT40"
]
},
"version":2,
"numChunkFile":3
}
从中我们可以看出:
该 Block 是由1个含有3个 chunk 的原始 Block 「01EPVA7WJ5DXTV6FR06VJ0CT40压缩生成」;
时序数据指标的范围是<1605081600,1605085200>;
总共拥有samples个数为:1359295562;
数据指标个数:441979;
chunks个数:11207472;
…
chunks
chunk 结构图如下:
![]()
series ref 是用于访问内存中数据列的 ID 。 mint 和 maxt 是在 chunk sample 中看到的最小和最大时间戳。encoding 是用于压缩块的编码。 len 是此后的字节数,data 是压缩块的实际字节数。CRC32 是上述chunk内容的校验和,用于检查数据的完整性。
Cut切分策略
当写入磁盘单个文件超过512M的时候,就会自动切分一个新的文件。
Index
这个文件就是 Prometheus 最复杂的索引结构。索引就是为了让我们快速的找到想要的内容。为了便于理解,就通过一次数据的寻址来探究一下Prometheus的磁盘索引结构。
索引生效过程
假设我们要检索拥有系列三个标签的所有序列数据。
({
__name__:http_request}{
api:api-server})且时间为 start\end
1、根据检索时间范围定位 block 位置
从选择 block开始,遍历所有 block的 meta.json ,找到具体的 block 。
2、Label 过滤
找到目标 block 之后,需要通过 label 过滤检索,那么问题来了!
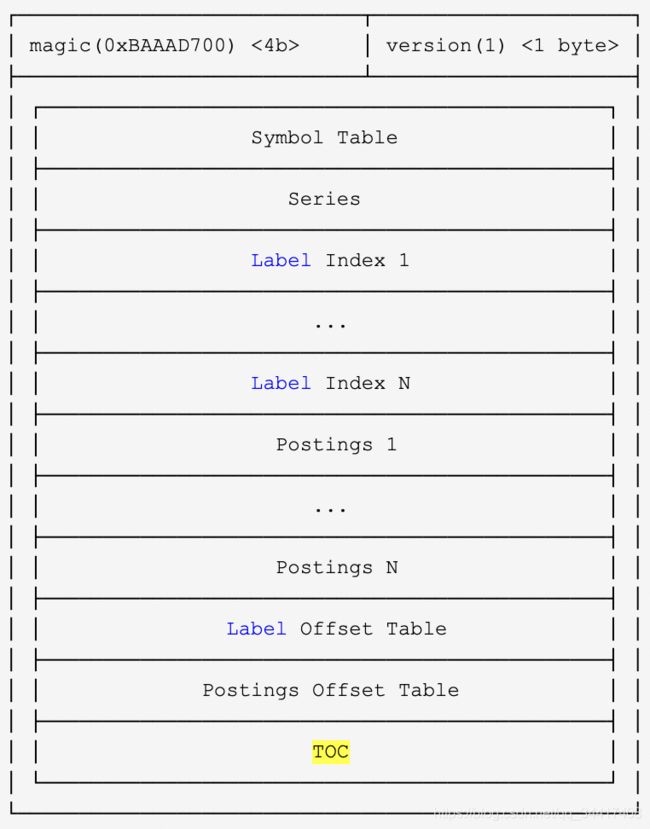
- 前文说了,通过 Labels 找数据是通过倒排索引。我们的倒排索引是保存在 index 文件里面的。那么怎么在这个单一文件里找到倒排索引的位置呢?这就引入了 TOC(Table Of Content) 。
- TOC结构,如下图:
- 首先我们访问的是 Posting offset table ,如下所示:
- 由于倒排索引按照不同的 LabelPair(key/value) 会有非常多的条目。所以 Posing offset table 就是决定到底访问哪一条 Posting 索引。offset 就是指的这一 Posting 条目在文件中的偏移。Postings 如下所示:
- 假设我们通过三条 Postings 倒排索引索引取交集得出
{series1,Series2,Series3}∩{series1,Series2}∩{Series1}={Series1} 中的数据,而 Posting 中的 Ref(Series1) 即为这 Series 在 index 文件中的偏移。Series结构如下所示:
- Series 以 Delta 的形式记录了 chunkId 以及该 chunk 包含的时间范围。这样就可以很容易过滤出我们需要的 chunk ,然后再按照 chunk 文件的访问,即可找到最终的原始数据。



tombstones
由于 Prometheus block 的数据一般在写完后就不会变动。如果要删除部分数据,就只能记录一下删除数据的范围,由下一次 compactor 组成新 block 的时候删除。而记录这些信息的文件即是 tomstones。
Prometheus核心的索引结构及生效过程聊完了,除了索引结构,其提供的数据超级压缩策略也是其在海量数据中,依旧坚挺的原因之一,下面来聊聊压缩策略…
数据压缩「Data Compress」
假设我们以平均每秒采集 20w+ 个数据指标写入数据,chunk 平均1KB,block 平均4KB ,每秒对磁盘的 IO 压力还是挺大…
假如我们需要查询一周的数据,那么这个查询将涉及到 80 多个 blocks ,数据也需要进行大量的磁盘 IO 到内存中聚合最终结果……
为了减轻磁盘 IO 压力,就需要充分利用内存。而内存的资源十分宝贵,为了达到在有限都内存资源中存储更多的数据指标的目标, Prometheus 提出了数据压缩「Data Compress」。
Chunk Compress
目前, prometheus.v3 具备将每个指标压缩至 1.28 bytes/sample 的压缩能力。
假设指标只含有 float64 类型的 Sample\TimeStamp ,不做压缩已经占用16byte ,加上变长的指标维度变量、名称后压缩至 1.28bytes ,可以说压缩比是 8% ,非常惊人。那么下面聊聊这样的压缩比下,隐藏了哪些不为人知的压缩策略…
双增量策略「delta-of-delta」
由于监控业务特性,使 timestamp、value/sample 天生具有连贯性、递增性,且连续 sample 相差幅度极小,故在统计存储时,无须完整记一值,只需记录其相对增量就可以达到压缩的目的。

如图,在每个 chunk 中,只存储一个完整的 value + Timestamp 作为基准,后续数据指标基于数据增长趋势「斜率」值的差额即可,有效的缩短了数值长度。
此策略也是 Prometheus 默认压缩编码策略。
XOR策略
大家都知道浮点数在计算机中存储结构是这样的:

由于相邻的 sample 点的数据值差异很小,也可以采用 XOR 策略。
通过连续两个值做异或操作,不同的 bits 只有2位,头部( leading )和尾部( trailing )都有大量连续的位是 ’ 0 ‘ , 根据这种情况,对 leading 和 trailing 的’ 0 ’进行压缩存储就能节约大量空间。
XOR结构图如下:

上面跟大家唠了那么多存储,都是基于本地存储。当我们线上生产环境需要集群部署的时候,可咋办呢?不慌,继续唠…
<有点喝了,欢迎关注收藏,歇歇下次继续看…>
五、Prometheus集群部署
云设施的完善和发展,使服务上云的节奏不断加快,推动着主流的产品技术走向未来。
在基于云的部署中,常见物理机、虚拟机逐渐将会被容器化技术代替,基于容器的 k8s ,慢慢的走向大众视野….
那么 Prometheus 在生产环境中部署该如何做呢?
注:下面的集群部署方案部分基于 Kubernetes 。
单小集群解决方案
单个集群中,利用 Kubernetes 提供的 kube-state-metrics、node-exporter、apiserver,controller-manager,scheduler,kubelet 等组件,提供每个组件核心功能相关的数据,比如 QPS、容器 CPU 使用率、内存使用率、Pod 的基本信息等…
通过 Prometheus 提供的 Explore 机制将相关指标转化为 Prometheus 格式即可。
名词小课堂:
- Kube-state-metrics:这个组件用于监控Kubernetes资源的状态,比如Pod的状态。原理是将Kubernetes中的资源,转换成Prometheus的指标,让Prometheus来采集。比如Pod的基本信息,Serivce的基本信息。
- Node-exporter:用于监控Kubernetes节点的基本状态,这个组件以DeamonSet的方式部署,每个节点一个,用于提供节点相关的指标,比如节点的cpu使用率,内存使用率等等。
……
部署架构
使用这种方式,就可以将集群的节点,组件,资源状态,容器运行时状态都给监控起来。

多集群部署解决方案
当我们拥有多个集群需要监控,需要将他们的监控数据存储在一起进行聚合处理,利用单机群的架构就存在两个问题:
1、网络问题
多个集群之间网络可能是不通的,也就意味着通过API无法拉取数据。
2、服务发现问题
Prometheus无法对集群外的集群做服务发现,无法跨集群操作。
针对这种情况,Prometheus 提供了联邦策略。
联邦策略
Prometheus 支持拉取其他 Prometheus 的数据到本地,称为联邦机制。
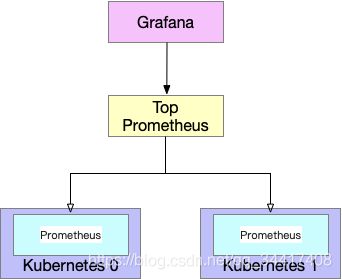
通过对每个集群单独部署 Prometheus 服务,在他们上层部署一个 Top Prometheus ,用于拉取各个集群内部的 Prometheus 数据进行汇总。
在集群规模普遍较小,整体数据量不大的情况下,联邦的方案部署简单,理解成本低,没有其他组件的引入,是一个很不错的选择。
1、当数据规模庞大的时候,数据存储压力全在 Top Prometheus ,会出现无法承载的问题。
2、另外一点是,如果最底层 Prometheus 没有关闭本地存储的话,还会存在数据冗余的问题(Prometheus2.x 版本一下不支持关闭本地存储)。
Thanos 高可用解决方案
Thanos 是一款开源的 Prometheus 高可用解决方案,其支持从多个Prometheus 中查询数据并进行汇总和去重,并支持将 Prometheus 本地数据传送到云上对象存储进行长期存储。
部署架构
Thanos 顶层替换掉 Top Prometheus ,底层集群添加 Sidecar 组件进行数据采集上传到对象存储,数据通过 Query 组件去重汇总处理进行外显。
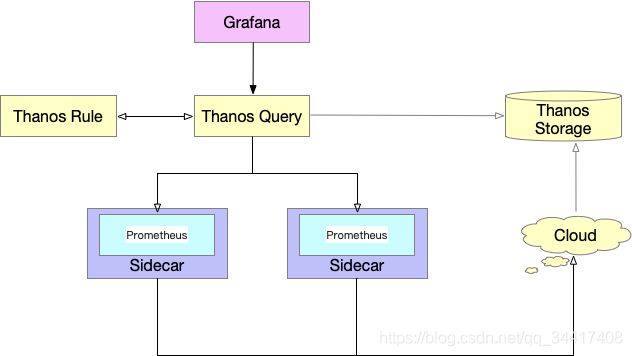
如上图所示,包含以下几个基本组件。
- Query:Query代理Prometheus作为查询入口,它会去所有Prometheus,Store以及Ruler查询数据,汇总并去重。
- Sidecar:将数据上传到对象存储,也负责接收Thanos Query的查询请求。
- Ruler:进行数据的预聚合及告警。
- Store: 负责从对象存储中查询数据。
Thanos 相对联邦机制有以下几个优势:
1、数据不再存储在单个 Prometheus 中,所以整体能承载的数据规模比联邦大。
2、Thanos Query 组件有去重能力,每个集群中可以部署2+个Prometheus来做数据多副本。
3、监控数据可传送到云上对象存储,能支持更长久的存储。
大集群场景解决方案
大集群场景的特点是数据规模大,无论是节点的规模,还是数据量,都是一个 Prometheus 无法采集的。
分片策略
Prometheus 支持在配置文件中加入 hashmod ,通过某个 label 的值来进行 hash ,让每个 Prometheus 只采集部分节点。
例如按节点的地址进行 hashmod ,让节点采集任务分散到3个 Prometheus 中。这样每个 Prometheus 就只会采集部分节点,从而达到分片效果。由于每个分片的 hashmod 取值不一样,所以每个分片需要使用单独的配置文件。
虽然使用 hashmod 的方式在一定程度上可以将负载分散到多个 Prometheus 中,但是其至少存在以下问题:
1、配置管理复杂:由于每个分片都要有单独的配置文件,需要维护多份配置文件。
2、配置项有侵入:需要为每个 Job 考虑 hashmod 的方式,而且需要清楚所采集数据根据那个 label 来 hash 才可能平均,对使用者相当不友好。
3、可能出现热点:hashmod 是不保证负载一定均衡的,因为如果多个数据规模较大的节点被 hashmod 到一个分片,这个分片就有可能 OOM 。
Thanos 支持 Prometheus 的分片策略解决大集群部署问题,但针对上述存在的问题,暂时没有较好的解决方案。
Q&A
1、文中开始的效果图是 Prometheus + Grafana ,Prometheus 生产数据源之后怎么和Grafana 交互可以讲解下吗?
具体详情请关注后续博文
2、文中提出云原生,云原生架构具体是指什么呢?
具体详情请关注后续博文
3、Prometheus 诞生于云时代的到来,这里云是指哪些?
文中的云基础设施包含公有云、私有云、混合云。
4、Prometheus 和其他监控组件有什么区别?面对监控场景该如何选型呢?
细品 Prometheus 特点,拥抱云原生! 具体详情请关注后续博文
5、Prometheus 自身节点数据如何监控呢?
需要根据实际情况去搭建一个,最好依托手边现有的基础设施监控,将Prometheus部署在上面即可。
具体详情请关注后续博文
6、倒排索引具体策略是什么呢?
请关注后续博文,或移步Es「https://blog.csdn.net/qq_34417408/article/details/117196166?spm=1001.2014.3001.5502」
8、云时代中,容器化、云原生化是每个系统都会逐步发展的目标或是终点吗/?
首先,微服务、容器和云原生架构并不是适合每个项目;
随着VR\loT等技术的发展,系统或架构的演进或许没有终点…
具体详情请关注后续博文
附录
通过刨析 Prometheus 内部策略及各种结构「细品」,希望对以后架构设计有所帮助!
一天一个小技巧,偷偷超越隔壁老大哥!