需求分析:
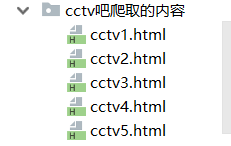
从控制台输入指定爬取的贴吧名称,起始页面,结束页面,并在文件中创建以 贴吧名称+“爬取内容” 为名字创建文件件,里面的每一个文件都是爬取到的每一页html文件,文件名称:贴吧名称_page.html
import urllib.request
import urllib.parse
import os#引入os模块
tieba_name =input("请输入你要爬取的贴吧的名称")
page_start =int(input("请输入你要爬取的起始页面"))
page_end =int(input("请输入你要爬取的结束页面"))
url ='http://tieba.baidu.com/f?'
name_next ='吧爬取的内容'
#创建文件夹
os.mkdir(tieba_name+name_next)
#设置循环,爬取每一页
for pagein range(page_start,page_end+1):
print('第%d页正在下载'%page)
data = {
'kw':tieba_name,
'pn':(page-1)*50
}
data = urllib.parse.urlencode(data)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
}
#发出请求
url_t = url+data
request = urllib.request.Request(url=url_t,headers=headers)
response = urllib.request.urlopen(request)
path = tieba_name+name_next+'/'+tieba_name+str(page)+'.html'
with open(path,'wb')as fp:
fp.write(response.read())
print('第%d页下载完成' % page)
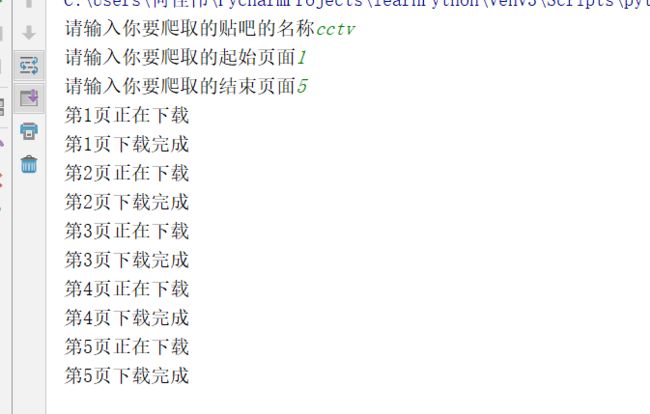
运行结果显示: