1 配置环境
本机环境
系统:Windows10
- OpenCV:3.42
下载地址:https://opencv.org/releases.html
安装完后需配置系统环境变量
Python:3
IDE:VS2017
- CUDA:10.2
下载地址:https://developer.nvidia.com/cuda-downloads
配置系统环境变量后,cmd输入
nvcc -V
会出现版本信息
CUDNN:7.65
需预先注册账号后下载:https://developer.nvidia.com/rdp/cudnn-download
下载完后复制内容到CUDA对应文件夹内-
神经网络:Darknet
下载命令:git clone https://github.com/AlexeyAB/darknet
需使用VS2017编译[Release|64],使用VS2017,且使用gpu,打开以下sln文件
darknet-master\darknet-master\build\darknet\darknet.sln
并使用文本文档编辑darknet.vcxproj,搜索得到两处CUDA版本号,替换成自己的
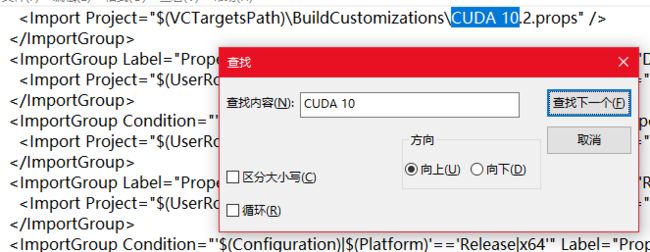
编译需添加OpenCV环境依赖
VC++ 目录—>包含目录—>编辑,添加以下三项[选择自己安装位置的绝对路径]
C:\opencv\build\include
C:\opencv\build\include\opencv
C:\opencv\build\include\opencv2
VC++ 目录—>库目录中添加
C:\opencv\build\x64\vc15\lib
链接器->输入->附加依赖项添加[根据自己安装的版本]
opencv_world342d.lib
opencv_world342.lib
编译完成后,darknet.exe会在x64文件夹中
2 数据集准备
2.1以VOC格式准备自己的数据集文件夹
├─VOCdevkit2007
│ └─VOC2007
│ ├─Annotations
│ ├─ImageSets
│ │ └─Main
│ ├─JPEGImages
│ └─labels
- JPEGImages 用于放置待标注的图像,格式为jpg
2.2使用脚本批量更改图片名称
import os
path = r'C:\Users\Dexter0ion\Desktop\TrainData\VOCdevkit2007\VOC2007\JPEGImages'
filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹)
count=0 # 编号从0开始
for file in filelist:
print(file)
for file in filelist:
# 遍历所有文件
Olddir=os.path.join(path,file) # 原来的文件路径
if os.path.isdir(Olddir): # 如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] # 文件名
filetype=os.path.splitext(file)[1] # 文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) # 用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir) # 重命名
count+=1
运行命令
python ./rename.py
2.3使用labelImg软件对数据进行标注
labelImg下载地址:http://tzutalin.github.io/labelImg/
解压后在data/predefined_classes.txt中修改预设的class名字

- Open Dir[Ctrl+u] 选择图片目录为JPEGImages
- Change Save Dir[Ctrl+r] 选择标注结果xml目录为Annotations
即可开始标注,快捷键流程
[w]框选
[Ctrl+s]保存
[d]下一张
3.处理标注后的数据
3.1生成Main目录下的txt文件
import os
import random
trainval_percent = 0.7 # trainval占总数的比例
train_percent = 0.5 # train占trainval的比例
xmlfilepath = r'C:\Users\Dexter0ion\Desktop\TrainData\VOCdevkit2007\VOC2007\Annotations'
txtsavepath = r'C:\Users\Dexter0ion\Desktop\TrainData\VOCdevkit2007\VOC2007\ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + r'\trainval.txt', 'w')
ftest = open(txtsavepath + r'\test.txt', 'w')
ftrain = open(txtsavepath + r'\train.txt', 'w')
fval = open(txtsavepath + r'\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行命令
python ./generatetxt.py
3.2生成darknet可用的yolo类型数据
将VOCdevkit2007文件夹整个复制到
darknet-master\darknet-master\build\darknet
文件夹下
进入
darknet-master\darknetmaster\build\darknet\VOCdevkit2007
文件夹
创建voc_label.py脚本
voc_label.py[此次只训练一个目标,在classes中改为你要训练的目标名字,多个则用逗号分隔]
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["redbox"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
之后会在VOC2007同目录下得到
│ 2007_test.txt
│ 2007_train.txt
│ 2007_val.txt
4 训练准备
需要配置
- 下载
darknet53.conv.74预训练权重
下载地址:http://pjreddie.com/media/files/darknet53.conv.74
下载后移动到:darknet-master\build\darknet\x64
文件夹下
- 创建
data/obj.data训练文本路径配置
classes= 1
#自己先前生成文件的绝对路径
train = C:\Users\Dexter0ion\Desktop\TrainData\darknet-master\darknet-master\build\darknet\VOCdevkit2007\2007_train.txt
valid = C:\Users\Dexter0ion\Desktop\TrainData\darknet-master\darknet-master\build\darknet\VOCdevkit2007\2007_test.txt
names = data/obj.names
backup = backup/
- 创建
data/obj.name分类名称
redbox
- 修改
darknet-master\build\darknet\x64文件夹下yolov3.cfg训练配置,并重命名为yolo-obj.cfg
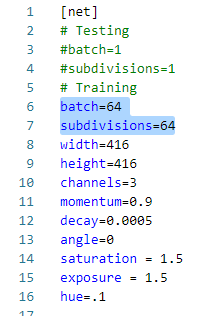
修改batch和subdivisions
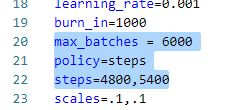
修改max_batches(作者声明最好是2000*训练目标个数,但不要小于4000)和steps(80%,90%,降低学习率阈值)
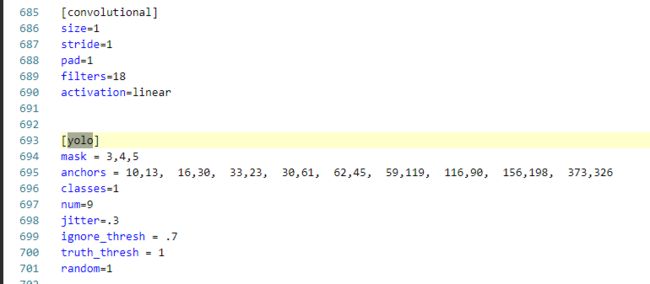
修改三处[convolutional] [yolo]
filters = 3*(5+classes数目) classes = 本次训练目标数,即1个



5 开始训练
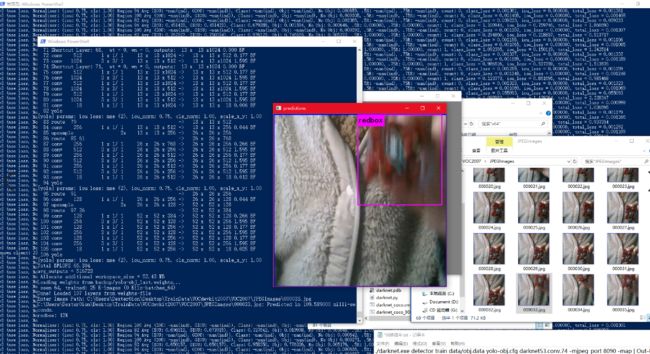
在darknet-master\build\darknet\x64目录下运行指令
./darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 mjpeg_port 8090 -ext_output | Out-File ./alpha_train_log.txt
注意:前100次loss会很高,之后会逐步下降
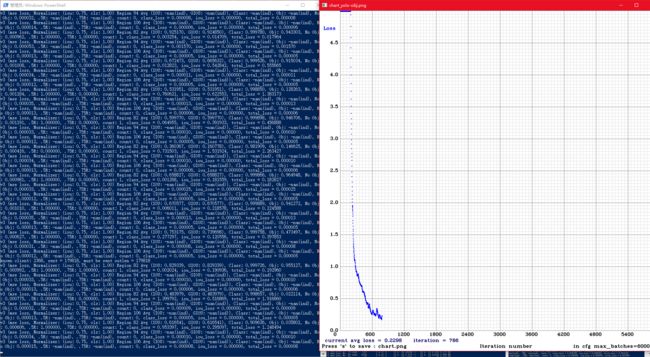
训练完成的权重文件默认保存在backup文件夹中
6 测试训练结果
复制yolo-obj.cfg且重命名为yolo-obj-test.cfg
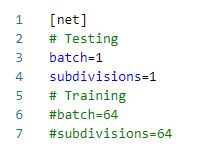
在darknet-master\build\darknet\x64目录下运行指令
./darknet detector test data/obj.data yolo-obj-test.cfg backup/yolo-obj_last.weights -thresh 0.1