本项目是在云服务器中的linux环境中进行的
以下是对adventure work项目的一个整体总结
BI可视化链接

一、业务背景
Adventure Works Cycles是AdventureWorks样本数据库所虚构的公司,这是一家大型跨国制造公司。该公司生产和销售金属和复合材料自行车到北美,欧洲和亚洲的商业市场。虽然其基地业务位于华盛顿州博塞尔,拥有290名员工,但几个区域销售团队遍布整个市场。
Adventure Works Cycle这家公司的客户主要有两种:
- 个体:这些客户购买商品是通过网上零售店铺
- 商店: 这些是从Adventure Works Cycles销售代表处购买转售产品的零售店或批发店。
这家公司主要有下面四个产品线:
- Adventure Works Cycles 生产的自行车
- 自行车部件,例如车轮,踏板或制动组件
- 从供应商处购买的自行车服装,用于转售给Adventure Works Cycles的客户。
- 从供应商处购买的自行车配件,用于转售给Adventure Works Cycles客户。
二、项目任务
- 将数据导入Hive数据库
- 探索数据库并罗列分析指标
- 汇总数据建立数据仓库(Sales主题)
- powerbi可视化
三、项目过程
1. 将数据导入Hive数据库
1.1什么是Hive?
- hive是基于Hadoop的一个数据仓库工具
- 可以将结构化的数据文件映射为一张数据库表,并提供类sql(HQL)的查询功能
- 可以将sql语句转换为MapReduce任务进行运行
- 可以用来进行数据提取转化加载(ETL)
Hive体系架构
- 元数据存储
- 驱动
- 查询编译器
- 执行引擎
- 服务器
- 客户端组件
- 可扩展接口

优点与缺点
- 成本低,入手较快
- 可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用
- 不支持实时查询
1.2怎么导入数据
目标:将29份CSV文件数据导入
这些文件的分隔符都是“|”,没有表头(字段),还有一份SQL文件,是数据库导出的建表语句,我要从这里面提取出表名和字段以及字段。
如图:


但是Hive导入数据分隔符默认是“,” 所以要将csv文件中的“|” 替换为 “,”
这里可以用Excel直接替换,但是为了方便还是用python进行循环读取文件,然后进行替换,在输出csv文件。
步骤:
1)用pd.read_csv()进行读取
2)文件获取用os.walk("文件路径下的文件")
分别会出现文件绝对路径、文件夹、文件,利用for root,dirs,files in os.walk("文件路径的文件夹")的for file in files 循环文件名
3)在循环内部进行异常检测,避免出错中止循坏
for root,dirs,files in os.walk(fromfile):
for file in files:
file_path = os.path.join(root,file)
try:
df = pd.read_csv(file_path,sep="|",encoding="utf-16LE",header=None,na_values='null',dtype=str)
except Exception as e:
print(e)
continue
4)将转换好的csv文件输出到新的文件夹,可以用df.to_csv("")和os.path.join("文件夹路径+文件csv")组合起来用。
1.3 csv文件中没有字段,这些字段需要在sql中提取出来
这里可以用python的正则表达式,从上面的图可以看出,这些表名和字段都在“[]”这里面,可以从里面提取,代码:
if "CREATE TABLE" in content.upper():
se0bj = re.search(r"\[(.*?)\].\[(.*?)\]",content,re.I) #读取表名的正则表达式
if se0bj:
table_name = se0bj.group(2) #读取表名,传给变量table_name
matOjb = re.search(r"\[(.*?)\] \[(.*?)\].*",content.lstrip(),re.I) # 读取字段名和字段类型的正则表达式
再进行函数文件的读取,循环写入,输出到一个新的脚本文件,在linux进行执行。
下面是涉及到的函数
shell_file = open("文件名","w") #w为写入模式
shell_file.writelines("写入文字") 按一行写入
shell_file.write("写入文字") 不限制行
shell_file.close() 关闭
将csv文件导入到hive也是用同样的方法,
1.4linux脚本执行
bash是启动器、shell是解释器
bash类似于开启一个虚拟登录的用户,然后该用户对文件进行读取认识、输出等即shell。
脚本的本质是开启了一个子bash,然后执行脚本,再退出子bash。
一般后缀为.sh的就是shell,读取方式两种:
当前Shell:. file.sh 或者 source file.sh
新建子Shell:/bin/bash file 或者 ./file.sh
将.sh变为可执行文件 :chmod +x file.sh
2.数据探索、指标罗列
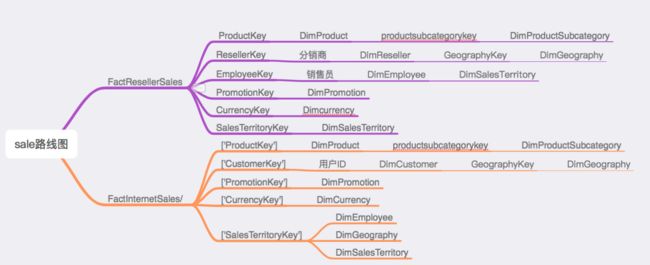
这里主要是以销售(sales)为主题进行探索
表主要分为事实表(Fact开头的)和 维度表(Dim开头的),两种表通过主键连接,表的设计结构为星型模型。
维度表:固定标签信息,比如地理维度表中有地理id、国家、省份、城市、经纬度等信息,那么在别的表中有地理id字段,连接则获得相应其他字段,节约表的空间。
事实表:实际业务发生过程的存储表。比如淘宝用户每日下单的记录,买家可获得其汇总信息,包括有userid、订单号、支付时间、支付链接等等
主要指标罗列:
1、地区维度、时间维度、产品种类维度
2、销售额、订单量、客单价、平均运费、平均税率、销售额预期完成率
3、销售额、销量随着时间变化趋势
4、销售地理分布

2.1目的及问题:
1.建立一个adventure的数据仓库,需要对其加工为可视化界面,减少数据加工的花费时间。
2.以销售情况为主题,给公司有需要的人提供业务情况的基本信息。
3.结合数据仓库情况,分析基本信息的指标应有哪些。
4.搭建指标框架结构,设计可视化界面的布局。
2.2数据了解及整理:
重点放在销售表中。
事实表:
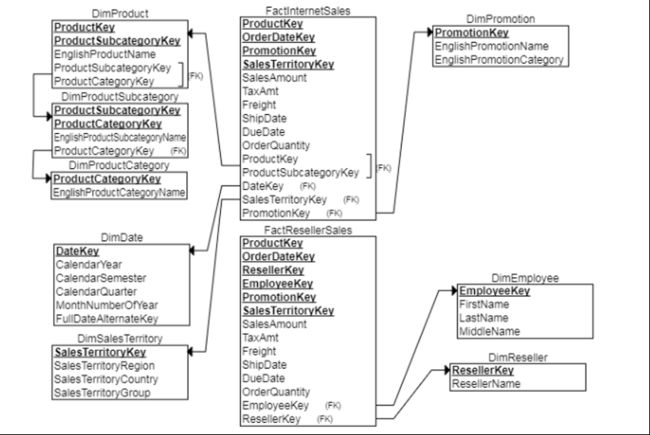
存在FactInternetSales(线上销售)和FactResellerSales(线下销售)表,
里面存在字段差异有:
FactResellerSales存在员工主键和经销商主键,而FactInternetSales无。
维度表:
事实表中的主键Key存在有:ProductKey、promotionKey、OrderDateKey、SalesTerritoryKey、(EmployeeKey、ResellerKey)
ER关系图如下:
2.4列出可分析的指标和维度:
维度:
产品维度:产品分类、产品子分类
时间维度:年、季、月
地区维度:销售地区
可分析的指标:
1.总销售额=销售量*客单价
2.总成本=产品标准成本*销售量+每笔订单的税收+运费
3.利润情况=销售额-总成本
4.销售指标达成情况
5.销售量最佳的产品Top10
6.各维度下搭配,如时间维度下的销售情况、销售区域变化情况
地区情况下的销售额、推广情况
产品分类下的销售情况
3.相应SQL语句及步骤:
目标:
通过给一些指定需求,让同学们在完成的同时对数据集有一定的了解
要求:
根据现有数据集,结合excel文档,统计出以下指标数据。
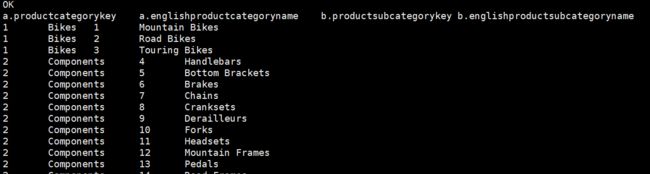
- 找出产品主类和子品类的对应关系
提示:产品大类表为 DimProductCategory ,产品子类表为 DimProductSubcategory。
select
a.ProductCategoryKey,
a.EnglishProductCategoryName,
b.ProductSubcategoryKey,
b.EnglishProductSubcategoryName
from DimProductCategory a
join DimProductSubcategory b
on a.ProductcategoryKey=b.ProductCategoryKey;
3.1将事实表通过key与各维度表相连(这一步可在BI或者SQL中实现)
这里还在数据仓库的汇总层创建了两个新的事实表(Fact_time和Factinternet)

2)这里通过FactinternetSales和DimProduct进行连接,新建几个指标,来模拟预测数据。

4.Power BI 可视化
导入BI后发现格式不正确的,在HIVE中重新清洗正确。
BI只是辅助手段,里面需要的相减获得利润字段,或者相除获得的客单价字段等,在BI进行模拟时,后续回到HIVE中添加相应语句,
4.1. 连接hive获取数据
1、powerbi连接HIVE数据库导入数据:
参考:PowerBI连接HIVE数据库
服务器需求:需要开启hiveserver2在后台运行
a、安装驱动
ClouderaHiveODBC6
b、连接数据库导入数据
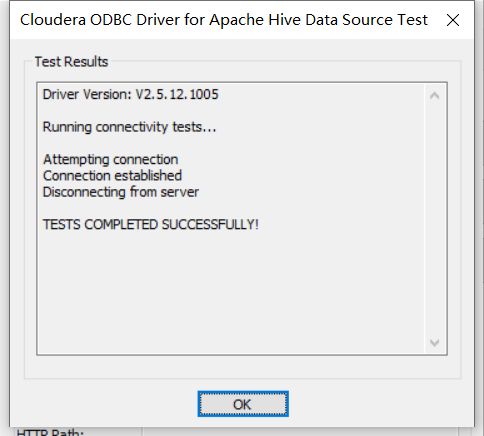
在电脑中搜索ODBC,打开64-bit ODBC Administrator
选择”系统DSN”选项卡,点击”添加”,选择cloudera ODBC Driver for Apache Hive DSN Setup,进行配置,点击test测试成功就说明配置成功了
c、检查远程连接服务是否开启:在linux服务器上运行以下命令看10000端口是否启用
netstat -nltp | grep 10000

4.2. power bi布局原则
贴合场景、主次分明、指标清晰。
一般5~6图表即可。
核心指标显示大、指标构成的其余信息科适当减小。
页面以维度为划分,探讨该维度下的不同信息。
4.3. 最终展示成果
主页:基本销售指标情况

- 指标情况(总销售额、目标达成金额、总订货量、平均运费、平均税费)
- 产品分类下的销售情况
- 不同地区下的销售情况
趋势:时间维度下的不同趋势

- 基本季度、月份、总的销售金额和订单数量以及预测值,还有环比增长率
- 不同地区的切片器
地区:区域分布销售

最后将BI发布到Web。