概述
接着翻译第二部分,原文打开速度好慢
原文地址
原文地址
作者:LAURENT BERNAILLE
介绍
在这篇blog的第一部分,我们知道了Docker如何给overlay创建了独有的网络命名空间并且将overlay上面的容器连接到这个命名空间。我们也知道了overlay网络在Docker宿主机之间的通信是利用VXLAN。在第二部分,我们将更加详细的探究一下VXLAN并且了解Docker是如何使用VXLAN的。
什么是VXLAN
从wikipedia
Virtual Extensible LAN (VXLAN) is a network virtualization technology that attempts to improve the scalability problems associated with large cloud computing deployments.
VXLAN是一项通道技术,它将L2(链路层)的网络帧包装在UDP包里面并通过4789端口发送出去,这项技术最开始是被VMWare,Arista和思科一起开发的。VXLAN的主要目标是简化需要在L2层多租户的云部署。它提供:
- 通过在L3上构建通道传输L2以避免群集中所有主机之间的L2连接的必要性
- 可以超过4096个独立的网络(VLAN ID的数量被限制为不能大于4096)
在Linux上,Openvswitch支持VXLAN并且内核自3.7版本开始原生支持VXLAN。另外,从内核3.16开始,VXLAN支持网络命名空间。
下面是一个VXLAN包的样子:

外层的IP包用于在宿主机之间的通信,内层的L2帧被加上了一个VXLAN的头部信息(特别是VXLAN ID)然后被包装在一个UDP包里面的。
我们用tcpdump可以验证我们的宿主机是用VXLAN进行通信的。我们从docker1上的容器ping C0并且在docker0上面抓包:
docker1:~$ docker run -it --rm --net demonet debian ping 192.168.0.100
PING 192.168.0.100 (192.168.0.100): 56 data bytes
64 bytes from 192.168.0.100: icmp_seq=0 ttl=64 time=0.680 ms
64 bytes from 192.168.0.100: icmp_seq=1 ttl=64 time=0.503 ms
docker0:~$ sudo tcpdump -pni eth0 "port 4789"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
12:55:53.652322 IP 10.0.0.11.64667 > 10.0.0.10.4789: VXLAN, flags [I] (0x08), vni 256
IP 192.168.0.2 > 192.168.0.100: ICMP echo request, id 1, seq 0, length 64
12:55:53.652409 IP 10.0.0.10.47697 > 10.0.0.11.4789: VXLAN, flags [I] (0x08), vni 256
IP 192.168.0.100 > 192.168.0.2: ICMP echo reply, id 1, seq 0, length 64
在tcpdump的输出信息中,由于包含了对于VXLAN帧的分析(为了可读性有些字段被删除了),每个包都产生两行信息:
- 外层帧,IP地址为10.0.0.11 和 10.0.0.10(docker宿主机)
- 里层帧,IP地址为192.168.0.100 和 192.168.0.2(我们的容器)和ICMP payload。我们也可以看到容器的MAC地址
更新网络结构图如下

解析容器名称和位置
我们知道了从docker1上的容器ping docker0上的容器是使用VXLAN的,但是我们现在还不知道在各自宿主机上的容器是如何将IP映射为MAC地址,并将L2帧传送到合适的宿主机上。
让我们在docker1上面创建一个容器并查看容器的ARP表:
docker1:~$ docker run -it --rm --net demonet debian bash
root@6234b23677b9:/# ip neighbor show
现在在容器里面没有ARP信息。当我们ping C0的时候,容器将会发起ARP通信。让我们先在docker0的overlay网络命名空间上看一下这个arp通信的是什么样的:
docker0:~$ sudo nsenter --net=$overns tcpdump -pni any "arp"
回到刚才创建的容器,我们将试着去ping C0,这将会创建一个ARP包:
root@6234b23677b9:/# ping 192.168.0.100
在docker0的tcpdump输出中没看到任何信息,所以ARP包并没有在VXLAN通道中发送(你也许看到arp请求,但是没有针对主机是192.168.0.100的)。让我们在docker1上面再创建一个容器并且在docker1的overlay网络命名空间中利用tcpdump抓包,从而确认我们是有ARP请求的。
docker1:~$ docker run -it --rm --net demonet debian bash
我们在另一个窗口上运行tcpdump。我们列出Docker的网络命名空间以便挑选出跟overlay相关的命名空间。这个命名空间可能变化了是因为当没有容器附在这个overlay网络上的时候,overlay的命名空间会被删除。
docker1:~$ sudo ls -1 /var/run/docker/netns
102022d57fab
x-13fb802253
docker1:~$ overns=/var/run/docker/netns/x-13fb802253
docker1:~$ sudo nsenter --net=$overns tcpdump -peni any "arp"
当我们在容器的窗口执行ping命令后,可以在看到tcpdump的输出:
19:16:40.658369 Out 02:42:c0:a8:00:02 ethertype ARP (0x0806), length 44: Request who-has 192.168.0.100 tell 192.168.0.2, length 28
19:16:40.658352 B 02:42:c0:a8:00:02 ethertype ARP (0x0806), length 44: Request who-has 192.168.0.100 tell 192.168.0.2, length 28
19:16:40.658371 In 02:42:c0:a8:00:64 ethertype ARP (0x0806), length 44: Reply 192.168.0.100 is-at 02:42:c0:a8:00:64, length 28
19:16:40.658377 Out 02:42:c0:a8:00:64 ethertype ARP (0x0806), length 44: Reply 192.168.0.100 is-at 02:42:c0:a8:00:64, length 28
我们可以看到ARP的请求和应答,这意味着overlay网络命名空间有相关的信息并且它充当一个ARP代理的角色。我们可以简单验证一下:
docker1:~$ sudo nsenter --net=$overns ip neigh show
192.168.0.100 dev vxlan0 lladdr 02:42:c0:a8:00:64 PERMANENT
这条记录被标志为PERMANENT意味着这是一条静态记录并且是被手工添加的(不是通过ARP发现得到的结果)。如果我们在docker0上面创建第二个容器,那么将会发生什么呢?
docker0:~$ docker run -d --ip 192.168.0.200 --net demonet --name C1 debian sleep 3600
docker1:~$ sudo nsenter --net=$overns ip neigh show
192.168.0.200 dev vxlan0 lladdr 02:42:c0:a8:00:c8 PERMANENT
192.168.0.100 dev vxlan0 lladdr 02:42:c0:a8:00:64 PERMANENT
记录被自动添加了,即使目前还没有通信包被发到这个新的容器中。这意味着Docker自动操作在overlay网络命名空间中的ARP记录,并且vxlan网卡充当一个代理去应答ARP请求。
如果我们查看vxlan网卡的配置,我们可以看到代理标志是被设置好的。这解释了这个这个行为(我们将在后面看到另外的选项)。
docker1:~$ sudo nsenter --net=$overns ip -d link show vxlan0
xx: vxlan0: mtu 1450 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default
link/ether 5a:71:8f:a4:b8:1b brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 256 srcport 10240 65535 dstport 4789 proxy l2miss l3miss ageing 300
bridge_slav
那如何来查看MAC地址的所在的位置呢(02:42:c0:a8:00:64是在那台主机上面)?我们可以查看overlay命名空间里面的网桥的转发数据库:
docker1:~$ sudo nsenter --net=$overns bridge fdb show
5a:71:8f:a4:b8:1b dev vxlan0 vlan 0 master br0 permanent
9a:ad:35:64:39:39 dev veth2 vlan 0 master br0 permanent
02:42:c0:a8:00:c8 dev vxlan0 dst 10.0.0.10 self permanent
02:42:c0:a8:00:64 dev vxlan0 dst 10.0.0.10 self permanent
33:33:00:00:00:01 dev veth2 self permanent
01:00:5e:00:00:01 dev veth2 self permanent
我们可以看到docker0容器的MAC地址在数据库里面,并且被标志为permanent。这个信息也是docker动态添加的。

我们发现了Docker自动操作MAC地址和FDB的信息。它是如何做到的呢?
我们可以先看一下Consul的内容。它里面存了写什么?
在我们刚开始的时候,这个网络是空的,但是现在它包含了一些信息。我们可以利用overlay网络的id来识别它。
当key的长度太长的时候,Consul的UI不能显示key。但是我们可以使用curl去查看内容(docker将信息通过base64编码过然后存为json格式,Consul应答格式为json):
net=$(docker network inspect demonet -f {{.Id}})
curl -s http://consul:8500/v1/kv/docker/network/v1.0/network/${net}/ | jq -r ".[0].Value" | base64 -d | jq .
{
"addrSpace": "GlobalDefault",
"attachable": false,
"created": "2017-04-23T16:33:02.442759329Z",
"enableIPv6": false,
"generic": {
"com.docker.network.enable_ipv6": false,
"com.docker.network.generic": {}
},
"id": "13fb802253b6f0a44e17e2b65505490e0c80527e1d78c4f5c74375aff4bf882a",
"inDelete": false,
"ingress": false,
"internal": false,
"ipamOptions": {},
"ipamType": "default",
"ipamV4Config": "[{\"PreferredPool\":\"192.168.0.0/24\",\"SubPool\":\"\",\"Gateway\":\"\",\"AuxAddresses\":null}]",
"ipamV4Info": "[{\"IPAMData\":\"{\\\"AddressSpace\\\":\\\"GlobalDefault\\\",\\\"Gateway\\\":\\\"192.168.0.1/24\\\",\\\"Pool\\\":\\\"192.168.0.0/24\\\"}\",\"PoolID\":\"GlobalDefault/192.168.0.0/24\"}]",
"labels": {},
"name": "demonet",
"networkType": "overlay",
"persist": true,
"postIPv6": false,
"scope": "global"
}
我们可以看到网络的所有元数据:
- 名称: demonet
- id:13fb802253b6f0a44e17e2b65505490e0c80527e1d78c4f5c74375aff4bf882a
- 子网: 192.168.0.0/24
我们也可以利用curl获取网络端信息,但是太难阅读了,所以我们将使用一个简单的python(在GitHub的repository获取)脚本来获取这个信息
import consul
import json
# First we connect to consul
c=consul.Consul(host="consul",port=8500)
# We retrieve all endpoint keys from Consul
(idx,endpoints)=c.kv.get("docker/network/v1.0/endpoint/",recurse=True)
epdata=[ ep['Value'] for ep in endpoints if ep['Value'] is not None]
# We print some interesting data on these endpoints
for data in epdata:
jsondata=json.loads(data.decode("utf-8"))
print("Endpoint Name: %s" % jsondata["name"])
print("IP address: %s" % jsondata["ep_iface"]["addr"])
print("MAC address: %s" % jsondata["ep_iface"]["mac"])
print("Locator: %s\n" % jsondata["locator"])
这个脚本展示了容器网络端的主要信息:
- 名称
- IP地址
- MAC地址
- 位置: 容器所在的宿主机
以下是我们当前的设置:
docker1:~$ python/dump_endpoints.py
Endpoint Name: adoring_einstein
IP address: 192.168.0.2/24
MAC address: 02:42:c0:a8:00:02
Locator: 10.0.0.11
Endpoint Name: C1
IP address: 192.168.0.200/24
MAC address: 02:42:c0:a8:00:c8
Locator: 10.0.0.10
Consul被用作所有静态信息的中心存储。然而,当有容器创建的时候,这还不足以动态通知所有的主机。事实证明,Docker使用serf和Gossip协议来实现这一目标。我们可以利用在docker0上订阅serf事件然后再在docker1上面创建一个容器来验证这一点。
docker0:~$ serf agent -bind 0.0.0.0:17946 -join 10.0.0.11:7946 -node demo -log-level=debug -event-handler=./serf.sh
#########################################
New event: member-join
demo 10.0.0.10
docker0 10.0.0.10
docker1 10.0.0.11
#########################################
为了我们能够关注相关的信息,我删掉了大多数的输出。我们可以看到所有的节点都参与到Gossip中。
Serf利用以下的选项来启动:
- bind: 绑定一个不同于7946的端口(这个端口已经被Docker使用)
- join: 加入serf集群中
- node: 给定一个节点名称(docker0 已经被使用了)
- event-handler:一个简单的脚本来显示serf事件
- log-level=debug: 这个选项用于看到event handler脚本的输出
serf.sh脚本的内容如下:
echo "New event: ${SERF_EVENT}"
while read line; do
printf "${line}\n"
现在,我们在docker1上面创建一个容器,然后看一下docker0上面的输出:
docker1:~$ docker run -it --rm --net demonet debian sleep 10
在docker0上,我们看到:
New event: user
join 192.168.0.2 255.255.255.0 02:42:c0:a8:00:02
Docker的守护程序订阅这些事件,然后去创建和删除ARP表和FDB上面的记录。

在swarm模式中,Docker不是依赖于Serf去同步节点的信息,而是利用它自己的Gossip协议的实现,但是实际上是做的一样的事情。
另一些VXLAN通信选项
Docker的守护程序利用serf通过Gossip协议来获取信息,然后自动操作ARP表和FDB表,然后依赖VXLAN网卡的ARP代理overlay网络的的通信。但是,VXLAN也提供了其他选项去发现信息。
端到端通信
当VXLAN配置“remote”选项,它会将未知的通信包都发送到这个IP,这个设置非常简单但是仅限于两个主机间的通道。

多播通信
当VXLAN配置为“group”选项,它将所有的未知包都发送给多播组。这个配置非常有效,但是需要所有主机间的多播连接。并不总是可用的,特别是在公有云上面。
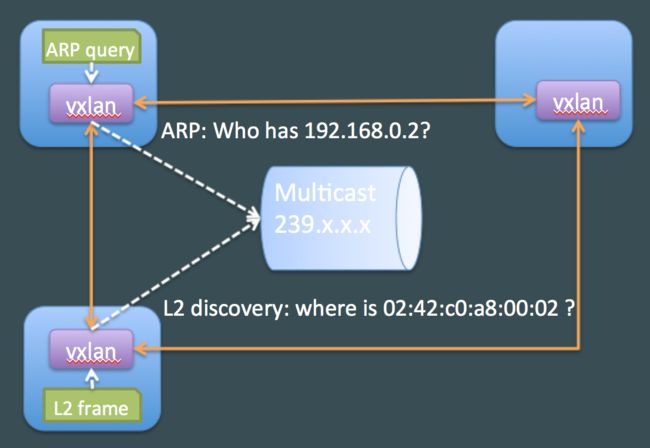
更多关于VXLAN在linux上的配置的详细信息,我推荐这个非常完整的post:VXLAN&Linux。
结论
在前面的两部分,我们看到Docker的overlay网络是如何工作的和它所依赖的技术。在第三部分,也是最后一部分,我们可以只利用Linux命令来创建自己的overlay网络。