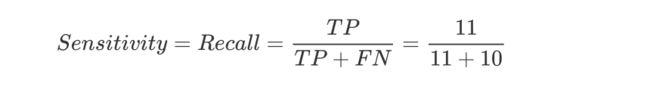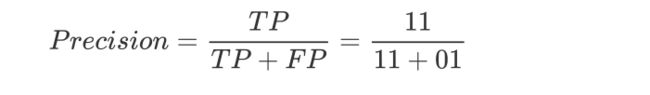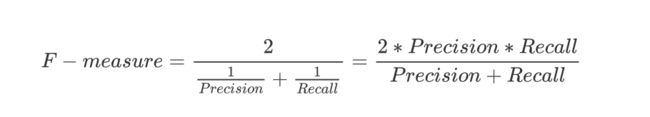有监督学习算法,同时可用于分类问题和回归问题。
贪心算法:从包含全部训练数据的根开始,每一步都选择最佳划分。依赖于所选择的属性是数值属性还是离散属性,每次将数据划分为两个或n个子集,然后使用对应的子集递归地进行划分,直到所有训练数据子集被基本正确分类,或没有合适的特征为止
· 先解决存在:数据间有关系,有模型)
· 再解决唯一:最优模型,泛化能力(期望)最高的
经验:对历史数据的学习能力判断(训练集预测精度),影响期望
希望决策树以最快的方法到达叶子节点,就需要有个特征选择的度量方式——信息熵
特征选择
选择标准:信息熵减小最快的方向(包含信息较少的特征)
1. 信息熵:是表示随机变量不确定性的度量
信息量:就是指数据的混杂程度
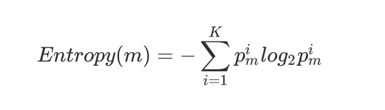
两个事件概率应该相乘,但是累乘计算难度高,取对数可以把累乘变成累加;去负号是因为log对0-1之间的数是负数,所以加个负号变成正数为了计算方便。信息熵的取值范围是[0,1]的

2. 基尼指数
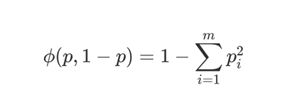
3. 误分类误差
决策树的生成
1. ID3算法:多叉树。只能处理分类型变量,连续型变量处理要分箱。用信息增益来度量的决策树算法
对某结点(数据集)进行切分的时候,尽可能选取使得该结点对应的子节点信息熵最小的特征进行切分。就是要求父节点信息熵和子节点总信息熵之差(信息增益)要最大
算法迭代的结束条件:满足之一会停下来
→当特征用完了,并且特征不能够重复使用
→样本用完了
→每个叶子节点都达到了最纯的状态
局限性:
ID3算法局限主要源于局部最优化条件,即信息增益的计算方法,其局限性主要有以下几点:
(1)分支度越高(分类水平越多)的离散变量量往往⼦子结点的总信息熵更更小,ID3是按照某一列进行切分,有一些列的分类可能不会对结果有足够好的指示。极端情况下取ID作为切分字段,每个分类的纯度都是100%,因此这样的分类方式是没有效益的。
(2)不能直接处理连续型变量,若要使用ID3处理连续型变量,则首先需要对连续变量进行离散化。
(3)对缺失值较为敏感,使用ID3之前需要提前对缺失值进行行处理。
(4)没有剪枝的设置,容易导致过拟合,即在训练集上表现很好,测试集上表现很差
2. C4.5算法(针对ID3缺点的提升):基于信息增益比选择特征进行分发,多叉树,可能处理连续型变量
计算过程:先排序,再选中位数,基于中位数划分,得到当前节点的信息熵,再和父节点做信息增益比的对比
由于连续型变量会基于某个阈值被划分为二分类,所以连续型变量是可以重复使用的特征,但是分类型特征仍然不能被重复使用
C4.5对ID3的缺点进行了怎样的改变?
3. CART分类回归树(目前最常用):二叉树递归划分,左子树为真,右子树为假
有监督的最优分箱法,x类型既可以是连续型变量也可以是分类型变量,一般不做分箱,数据是什么样就是什么样
分类树:基于基尼系数选择特征进行分支
回归树:基于均方误差MSE选择特征进行分支
可以自动进行连续型变量的二值化
树的剪枝
处理过拟合问题:sklearn使用后剪枝
方法一:基于父节点和子节点的预测误差大小进行判断,当父节点的误差小于子节点的总加权平均误差时,那么我们就会进行剪枝(适用C4.5多叉树)
方法二:限制树的结构来防止过拟合(仅适用于CART树,多叉树无法确定结构)
子节点总加权平均错误率并和父节点进行比较,子节点错误率更高,考虑剪枝
sklearn重要参数
from sklearn.tree import DecisionTreeClassifier
Criterion:一般默认选择gini基尼系数,如果数据模型的学习能力不太好选择entropy信息熵,entropy更容易发生过拟合。可以通过学习曲线和网格搜索进行调参,以结果为导向
splitter:是否基于重要性程度最高的特征优先分支,默认best;如果是random,就可以用到random_state来随机
剪枝参数:
max_depth 最大深度
min_samples_leaf 子节点最少包含的样本集
min_samples_split 节点最少包含多少个才样本集可以分支
为了提高运算速度,用网格搜索调参可以两两运行
重要接口
feature_importances_ #特征重要性,数值越大,重要性越高,可以做特征筛选的依据,选择大于0.02的。数值最大的基本就是根节点
feature_names #看特征名称
target_names #看标签名字
用网格搜索进行调参:
best_params_ #返回最佳参数的接口
best_score_ #最佳得分
混淆矩阵对模型进行评价
from sklearn.metrics import classification_report
print(classification_report(Ytest,clf.predict(Xtest)))
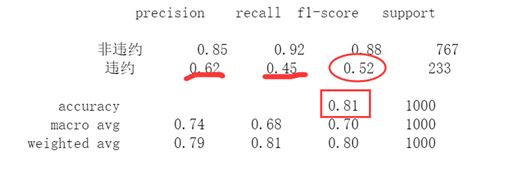
正确率一般是当0和1平衡,且在业务上重要程度相同时,正确率才有效。一般在业务场景中都不能满足,我们会更加看中1,所以正确率一般不关心
召回率:一个都不能漏,会犯错,人工量会提升。用于事情比较严重时。在银行中预测是否会违约,重点看召回率,模型中召回率要在85%以上这个模型才可以用于评分卡的使用
精准率:一个都不能错,可以漏点也不是很重要的事情上
举例,在电商中对会员进行营销时,要看中精准率。因为VIP是绝对不能被打扰的,要精准营销
f1协波平均数:协调精准率和召回率的综合指标
计算公式: