概论
本来预计写完前几篇文章之后,想研究NLP技术。不过我发现有些产品经理在面试的过程中有提到知识图谱相关方面的问题,所以就花了几天时间研究了一下知识图谱技术。
本篇文章结合了如下几位作者的思路,因为我没有实战应用的经验,所以更多的是从网络获取相关的概念型的知识,然后结合一些产品经理实战经验,从而得到了这篇文章,本文算是一个比较浅显的认识。
知识图谱在现在的的人工智能应用当中运用的很普遍,比如说现在淘宝里面的关联推荐,支付宝的风控金融以及NLP等相关技术都有涉及,所以可以说这是未来人工智能应用的基石,而且有实力的互联网大型公司大部分都具备知识图谱,这样对于后续的AI发展有很大的帮助。
知识图谱的定义
知识图谱的定义有很多,在机器之心的官方网站上是这样概括的:知识图谱本质上是语义网络(Semantic Network)的知识库。
在这里先简单的介绍一下语义网络和知识库这两个概念,语义网络:语义网络是由Quillian于上世纪60年代提出的知识表达模式,其用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。知识库:知识库是用于知识管理的一种特殊的数据库,以便于有关领域知识的采集、整理以及提取。知识库中的知识源于领域专家,它是求解问题所需领域知识的集合,包括基本事实、规则和其它有关信息。
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。 知识图谱这个概念最早由Google提出,主要是用来优化现有的搜索引擎。不同于基于关键词搜索的传统搜索引擎,知识图谱可用来更好地查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。比如在百度的搜索框里输入迪丽热巴的时候,搜索结果页面的右侧还会出现其他涉及相关的明星等等。
我偏笑文章里面的概括比较抽象但全面,在这里我建议换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图。(Multi-relational Graph)
那什么叫多关系图呢? 学过数据结构的都应该知道什么是图(Graph)。图是由节点(Vertex)和边(Edge)来构成,但这些图通常只包含一种类型的节点和边。但相反,多关系图一般包含多种类型的节点和多种类型的边。比如左下图表示一个经典的图结构,右边的图则表示多关系图,因为图里包含了多种类型的节点和边。这些类型由不同的颜色来标记。

在知识图谱里,我们通常用“实体(Entity)”来表达图里的节点、用“关系(Relation)”来表达图里的“边”。实体指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
现实世界中的很多场景非常适合用知识图谱来表达。 比如一个社交网络图谱里,我们既可以有“人”的实体,也可以包含“公司”实体。人和人之间的关系可以是“朋友”,也可以是“同事”关系。人和公司之间的关系可以是“现任职”或者“曾任职”的关系。 类似的,一个风控知识图谱可以包含“电话”、“公司”的实体,电话和电话之间的关系可以是“通话”关系,而且每个公司它也会有固定的电话。
知识图谱的表示
根据不同的应用场景,需要决定知识图谱最后可视化呈现的格式。一般来说,我们会看到两种界面上的展示:
-
类似google/百度等搜索引擎的展现方式,在这种展示里面,我们获取到的是一大堆与搜索目标相类似接近的结果,不过最近随着知识图谱的完善,搜索结果已越来越趋向于搜索想要的结果。举个例子,当我搜索阿里巴巴董事长的时候,会跳出来搜索结果,左边是相关联的企业家,如图所示:
搜索结果.png
这种常见的界面表现比较适合满足于寻求信息量杂、查找范围广、信息类别多样的诉求。但是针对目的明确,信息类别确定的情况(也可理解为垂直诉求),这种表现方式反而不太合适,因此需要我们用另外的形式去展现信息。
-
逻辑关系式的表现方式
在现实世界中,实体和关系也会拥有各自的属性,比如人可以有“姓名”和“年龄”。当一个知识图谱拥有属性时,我们可以用属性图(Property Graph)来表示。下面的图表示一个简单的属性图。李明和李飞是父子关系,并且李明拥有一个138开头的电话号,这个电话号开通时间是2018年,其中2018年就可以作为关系的属性。类似的,李明本人也带有一些属性值比如年龄为25岁、职位是总经理等。
 image
image
这种属性图的表达很贴近现实生活中的场景,也可以很好地描述业务中所包含的除了属性图,知识图谱也可以用RDF来表示,它是由很多的三元组(Triples)来组成。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。目前来看,RDF主要还是用于学术的场景,在工业界我们更多的还是采用图数据库(比如用来存储属性图)的方式
数据的类型和存储
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
结构化数据(Structed Data),如关系数据库
非结构化数据,如图片、音频、视频
半结构化数据 如XML、JSON、百科

如何存储上面这三类数据类型呢?一般有两种选择,一个是通过RDF(资源描述框架)这样的规范存储格式来进行存储,比较常用的有Jena等。

还有一种方法,就是使用图数据库来进行存储,常用的有Neo4j等。

从上图就可以看出基于图数据库的关联查询效率非常好,任何实体之间的关系都简洁明了,除此之外,基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。
知识图谱的构建
知识图谱的架构
知识图谱的架构,包括知识图谱自身的逻辑结构以及构建知识图谱所采用的技术(体系)结构。
逻辑结构
知识图谱的逻辑结构分为两个层次:数据层和模式层。
在知识图谱的数据层,知识以事实(fact)为单位存储在图数据库。如果以『实体-关系-实体』或者『实体-属性-值』三元组作为事实的基本表达方式,则存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的图谱。
模式层在数据层之上,是知识图谱的核心,在模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式层,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系。本体库在知识图谱中的地位相当于知识库的模具,拥有本体库的知识库冗余知识较少。
如果还是有点模糊,可以看看这个例子:
模式层:实体-关系-实体,实体-属性-性值
数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
技术架构
知识图谱的整体架构如图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。

知识图谱的构建过程是从原始数据出发,采用一系列自动或半自动的技术手段,从原始数据中提取出知识要素(即事实),并将其存入知识库的数据层和模式层的过程。这是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:信息抽取、知识融合以及知识加工。
知识图谱有自顶向下和自底向上2种构建方式。所谓自顶向下构建是借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中;所谓自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
目前知识图谱大多采用自底向上的方式构建,本文也主要介绍自底向上的知识图谱构建技术,按照知识获取的过程分为3个层次:信息抽取、知识融合以及知识加工。
知识图谱的构建
采用自底向上的方式构建知识图谱的过程是一个迭代更新的过程,每一轮更新包括3个步骤:
信息抽取,即从各种类型的数据源中提取出实体(概念)、属性以及实体捡的相互关系,在此基础上形成本体化的知识表达
知识融合,在获得新知识后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等
知识加工,对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量,新增数据之后,可以进行知识推理、拓展现有知识、得到新知识。
见下图展示知识图谱的架构原理:

信息抽取
信息抽取是知识图谱构建的第一步,其中的关键问题是如何从异构数据源中自动抽取信息得到候选知识单元。信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:命名实体识别、关系抽取和属性抽取。
命名实体识别(实体抽取)
命名实体识别(named entity recognition,NER)也称实体抽取,是指从文本数据集中自动识别出命名实体。实体抽取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息抽取中最为基础和关键的部分。
2012年Ling等人归纳出112种实体类别,并基于条件随机场CRF进行实体边界识别,最后采用自适应感知机算法实现了对实体的自动分类,取得了不错的效果。
但是随着互联网中内容的动态变化,采用人工预定义实体分类体系的方式已经很难适应时代的需求,因此提出了面向开放域的实体识别和分类研究。
在面向开放域的实体识别和分类研究中,不需要(也不可能)为每个领域或者每个实体类别建立单独的语料库作为训练集。因此,该领域面临的主要挑战是如何从给定的少量实体实例中自动发现具有区分力的模型。
一种思路是根据已知的实体实例进行特征建模,利用该模型处理海量数据集得到新的命名实体列表,然后针对新实体建模,迭代地生成实体标注语料库。
另一种思路是利用搜索引擎的服务器日志,事先并不给出实体分类等信息,而是基于实体的语义特征从搜索日志中识别出命名实体,然后采用聚类算法对识别出的实体对象进行聚类。
比如在下图中,通过实体抽取我们可以从其中抽取出三个实体——“Steve Balmer”, "Bill Gates",和"Microsoft"。

关系抽取
文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系,通过关联关系将实体(概念)联系起来,才能够形成网状的知识结构,研究关系抽取技术的目的,就是解决如何从文本语料中抽取实体间的关系这一基本问题。
早期的关系抽取研究方法主要是通过人工构造语法和语义规则。随后,出现了大量基于特征向量或者核函数的有监督学习方法,关系抽取的准确性也不断提高。但以上研究成果的共同特点是需要预先定义实体关系类型,如雇佣关系、整体部分关系以及位置关系等。
与之相对的,Banko等人提出了面向开放域的信息抽取方法框架(open information extraction,OIE),并发布了基于自监督(self-supervised)学习方式的开放信息抽取原型系统(TextRunner),该系统采用少量人工标记数据作为训练集,据此得到一个实体关系分类模型,再依据该模型对开放数据进行分类,依据分类结果训练朴素贝叶斯模型来识别『实体-关系-实体』三元组,经过大规模真实数据测试,取得了显著优于同时期其他方法的结果。
TextRunner系统中错误的部分主要是一些无意义或者不和逻辑的实体关系三元组,据此引入语法限制条件和字典约束,采用先识别关系指示词,然后再对实体进行识别的策略,有效提高了关系识别准确率。
文本语料经过实体抽取之后,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。这就是关系抽取需要做的事,如下图所示。

属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
由于可以将实体的属性视为实体与属性值之间的一种名词性关系,因此也可以将属性抽取问题视为关系抽取问题。
百科类网站提供的半结构化数据是当前实体属性抽取研究的主要数据来源。但是还有大量的实体属性数据隐藏在非结构化的公开数据中。
一种解决方案是基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取;
另一种方案是采用数据挖掘的方法直接从文本中挖掘实体属性与属性值之间的关系模式,据此实现对属性名和属性值在文本中的定位。这种方法的基本假设是属性名和属性值之间在位置上有关联关系,事实上在真实语言环境中,许多实体属性值附近都存在一些用于限制和界定该属性值含义的关键词(属性名),在自然语言处理技术中将这类属性称为有名属性,因此可以利用这些关键字来定位有名属性的属性值。
知识融合
通过信息抽取,我们就从原始的非结构化和半结构化数据中获取到了实体、关系以及实体的属性信息。
如果我们将接下来的过程比喻成拼图的话,那么这些信息就是拼图碎片,散乱无章,甚至还有从其他拼图里跑来的碎片、本身就是用来干扰我们拼图的错误碎片。也就是说:拼图碎片(信息)之间的关系是扁平化的,缺乏层次性和逻辑性;拼图(知识)中还存在大量冗杂和错误的拼图碎片(信息)那么如何解决这一问题,就是在知识融合这一步里我们需要做的了。
知识融合包括2部分内容:实体链接和知识合并
实体链接
实体链接(entity linking)是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
实体链接的基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
实体链接的一般流程是:
从文本中通过实体抽取得到实体指称项
进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义,以及知识库中是否存在其他命名实体与之表示相同的含义
在确认知识库中对应正确实体对象之后,将该实体指称链接到知识库中对应实体。
实体消歧是专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接,实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
共指消解技术主要用于解决多个指称对应同一实体对象的问题。在一次会话中,多个指称可能指向的是同一实体对象。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象,由于该问题在信息检索和自然语言处理等领域具有特殊的重要性,吸引了大量的研究努力。共指消解还有一些其他的名字,比如对象对齐、实体匹配和实体同义。
共指消解问题的早期研究成果主要来自自然语言处理领域,近年来统计机器学习领域的学者越来越多的参与到这项工作中。
基于自然语言处理的共指消解是以句法分析为基础的,代表方法是Hobbs算法和向心理论(centering theory)。Hobbs算法是最早的代词消解算法之一,主要思路是基于句法分析树进行搜索,因此适用于实体与代词出现在同一句子中的场景,有一定的局限性。
向心理论的基本思想是:将表达模式(utterance)视为语篇(discourse)的基本组成单元,通过识别表达式中的实体,可以获得当前和后续语篇中的关注中心(实体),根据语义的局部连贯性和显著性,就可以在语篇中跟踪受关注的实体。
随着统计机器学习方法被引入该领域,共指消解技术进入了快速发展阶段,McCarthy等人首次将C4.5决策树算法也被应用于解决共指消解问题。
除了将共指消解问题视为分类问题之外,还可以将其作为聚类问题来求解。聚类法的基本思想是以实体指称项为中心,通过实体聚类实现指称项与实体对象的匹配。其关键问题是如何定义实体间的相似性测度。Turney基于点互信息来求解实体所在文档的相似度,能够有效的实现共指消解。
基于统计机器学习的共指消解方法通常受限于2个问题:训练数据的(特征)稀疏性和难以在不同的概念上下文中建立实体关联。为解决该问题,Pantel等人基于Harris提出的分布相似性模型,提出了一个新的实体相似性测度模型,称为术语相似度(term similarity),借助该模型可以从全局语料中得到所有术语间的统计意义上的相似性,据此可以完成实体合并,达到共指消解的目的。
知识合并
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据获取知识输入。
常见的知识合并需求有两个,一个是合并外部知识库,另一个是合并关系数据库。
将外部知识库融合到本地知识库需要处理两个层面的问题:
数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余
通过模式层的融合,将新得到的本体融入已有的本体库中
然后是合并关系数据库,在知识图谱构建过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。业界和学术界将这一数据转换过程形象地称为RDB2RDF,其实质就是将关系数据库的数据换成RDF的三元组数据。
经过刚才那一系列步骤,我们终于走到了知识加工这一步了!
感觉大家可能已经有点晕眩,那么让我们再来看一下知识图谱的这张架构图。
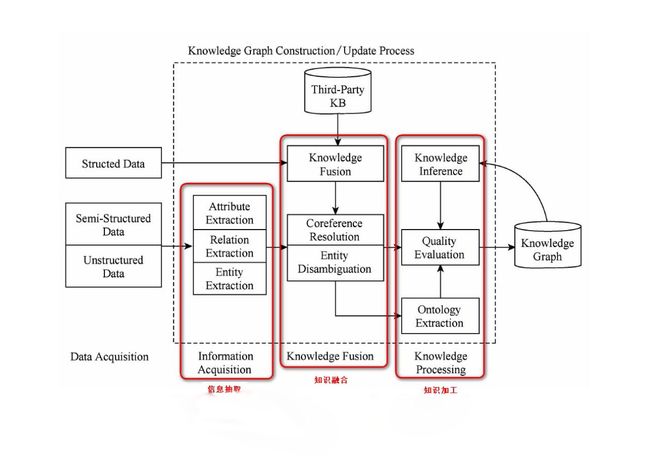
在前面,我们已经通过 信息抽取,从原始语料中提取出了实体、关系与属性等知识要素,并且经过 知识融合,消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。
然而事实本身并不等于知识。要想最终获得结构化,网络化的知识体系,还需要经历 知识加工的过程。
知识加工主要包括3方面内容: 本体构建、知识推理和质量评估。
本体(ontology)是对概念进行建模的规范,是描述客观世界的抽象模型,以形式化的方式对概念及其之间的联系给出明确定义。本体最大的特点在于它是共享的,本体反映的知识是一种明确定义的共识。
本体是同一领域内的不同主体之间进行交流的语义基础。本体是树状结构,相邻层次的节点(概念)之间有严格的『IsA』关系。在知识图谱中,本体位于模式层,用于描述概念层次体系,是知识库中知识的概念模板。
本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以以数据驱动的自动化方式构建本体,其包含3个阶段:实体并列关系相似度计算、实体上下位关系抽取以及本体的生成。
实体并列关系相似度适用于考察任意给定的两个实体在多大程度上属于同一概念分类的指标测度,相似度越高,表明这2个实体越有可能属于同一语义类别。所谓并列关系,是相对于纵向的概念隶属关系而言的。
实体上下位关系抽取是用于确定概念之间的隶属(IsA)关系,这种关系也称为上下位关系。
本体生成阶段的主要任务是对各层次得到的概念进行聚类,并对其进行语义类的标定(为该类的中的实体指定1个或多个公共上位词)。
当前主流的实体并列关系相似度计算方法有两种:模式匹配法和分布相似度。其中,模式匹配法采用预先定义实体对模式的方法,通过模式匹配取得给定关键字组合在同一语料单位中共同出现的频率,据此计算实体对之间的相似度。分布相似度方法的前提假设是:在相似的上下文管径中频繁出现的实体之间具有语义上的相似性。
实体上下位关系抽取是该领域的研究重点,主要的研究方法是基于语法模式(如Hearst模式)抽取IsA实体对。也有方法利用概率模型判定IsA关系和区分上下位词,通常会借助百科类网站提供的概念分类知识来帮助训练模型,以提高算法精度。
比如对下面这个例子,当知识图谱刚得到“阿里巴巴”、“腾讯”、“手机”这三个实体的时候,可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就会发现,阿里巴巴和腾讯之间可能更相似,和手机差别更大一些。
这就是第一步的作用,但这样下来,知识图谱实际上还是没有一个上下层的概念,它还是不知道,阿里巴巴和手机,根本就不隶属于一个类型,无法比较。因此我们在实体上下位关系抽取这一步,就需要去完成这样的工作,从而生成第三步的本体。
当三步结束后,这个知识图谱可能就会明白,“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”

知识推理是指从知识库中已有的实体关系数据出发,进行计算机推理,建立实体间的新关联,从而拓展和丰富知识网络。知识推理是知识图谱构建的重要手段和关键环节,通过知识推理,能够从现有知识中发现新的知识。
知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。
知识的推理方法可以分为2大类:基于逻辑的推理和基于图的推理。
基于逻辑的推理主要包括一阶逻辑谓词、描述逻辑以及基于规则的推理。
一阶谓词逻辑建立在命题的基础上,在一阶谓词逻辑中,命题被分解为个体(individuals)和谓词(predication)2部分。个体是指可独立存在的客体,可以是一个具体的事物,也可以是一个抽象的概念。谓词是用来刻画个体性质及事物关系的词。比如(A,friend,B)就是表达个体A和B关系的谓词。
对于复杂的实体关系,可以采用描述逻辑进行推理。描述逻辑(description logic)是一种基于对象的知识表示的形式化工具,是一阶谓词逻辑的子集,它是本体语言推理的重要设计基础。
基于规则的推理可以利用专门的规则语言,如SWRL(semantic Web rule language)。
基于图的推理方法主要基于神经网络模型或Path Ranking算法。Path Ranking算法的基本思想是将知识图谱视为图(以实体为节点,以关系或属性为边),从源节点开始,在图上执行随机游走,如果能够通过一个路径到达目标节点,则推测源和目的节点可能存在关系。
在我们完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,那么这个时候,我们就可以使用知识推理技术,去完成进一步的知识发现。
比如在下面这个例子里:

我们可以发现:如果A是B的配偶,B是C的主席,C坐落于D,那么我们就可以认为,A生活在D这个城市。
根据这一条规则,我们可以去挖掘一下在图里,是不是还有其他的path满足这个条件,那么我们就可以将AD两个关联起来。除此之外,我们还可以去思考,串联里有一环是B是C的主席,那么B是C的CEO、B是C的COO,是不是也可以作为这个推理策略的一环呢?
当然知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。
比如:
推理属性值:已知某实体的生日属性,可以通过推理得到该实体的年龄属性;
推理概念:已知(老虎,科,猫科)和(猫科,目,食肉目)可以推出(老虎,目,食肉目)
这一块的算法主要可以分为3大类,基于逻辑的推理、基于图的推理和基于深度学习的推理。

质量评估
质量评估也是知识库构建技术的重要组成部分。其意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识,可以保障知识库的质量。
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。
概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。
数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗杂等问题)等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。
知识更新
知识图谱的内容更新有两种方式:
全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;
增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
知识图谱的应用
通过知识图谱,不仅可以将互联网的信息表达成更接近人类认知世界的形式,而且提供了一种更好的组织、管理和利用海量信息的方式。目前的知识图谱技术主要用于智能语义搜索、移动个人助理(Siri)以及深度问答系统(Watson),支撑这些应用的核心技术正是知识图谱技术。
在智能语义搜索中,当用户发起查询时,搜索引擎会借助知识图谱的帮助对用户查询的关键词进行解析和推理,进而将其映射到知识图谱中的一个或一组概念之上,然后根据知识图谱的概念层次结构,向用户返回图形化的知识结构,这就是我们在谷歌和百度的搜索结果中看到的知识卡片。
在深度问答应用中,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。比如,如果用户提问:『如何判断是否感染了埃博拉病毒?』,则该查询有可能被等价变换为『埃博拉病毒的症状有哪些?』,然后再进行推理变换,最终形成等价的三元组查询语句,如(埃博拉,症状,?)和(埃博拉,征兆,?)等。如果由于知识库不完善而无法通过推理解答用户的问题,深度问答系统还可以利用搜索引擎向用户反馈搜索结果,同时根据搜索结果更新知识库,从而为回答后续的提问提前做出准备。
以上大部分来自如下几篇文章:
浅谈知识图谱基础(我偏笑):https://bit.ly/2TssC4z
知识图谱基础(一)-什么是知识图谱:https://bit.ly/2UOlLEd
一文揭秘!自底向上构建知识图谱全过程:https://bit.ly/2U8a3qJ
知识图谱|项目前期产品经理需要做哪些准备?:https://bit.ly/2ToDzUU
这是一份通俗易懂的知识图谱技术与应用指南(机器之心):https://bit.ly/2CBn16v