写在前面:该篇文章不会作特别详细的解释,只是讲述一下大致的使用方法和应用场景
先了解scrapy的工作流程,如下图:
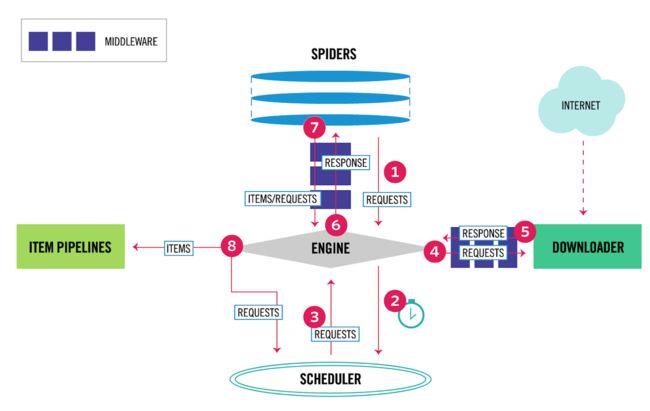
scrapy框架流程图.png
中间件的分类
- 下载中间件(Downloader Middleware)
- 爬虫中间件(Spider Middleware)
- 自定义中间件
一、下载中间件
应用场景
- 更换代理ip
- 更换Cookies
- 更换User-Agent
- 自动重试
1. 更换代理ip
a. middlewares.py
import random
from Test.settings import PROXY
class ProxyMiddleware(object):
def process_request(self, request, spider):
proxy = random.choice(PROXY)
# 这里可以根据具体情况选择使用http还是https的代理
request.meta['proxy'] = proxy
b. settings.py
# 启用中间件
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.Proxy': 542,
}
#代理列表举例
PROXY = ['http://182.158.6.123:8888', 'https://182.158.6.123:8888']
优化:使用代理池(以下代码的导包就不再展示)
a. middlewares.py
class RandomProxy(object):
def process_request(self, request, spider):
# 使用代理池,防止ip被封
pool = redis.ConnectionPool(host=POOL_HOST, port=POOL_PORT, db=POOL_DB, decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 获取代理的方法,以及代理存放的方式都可根据不同场景更换;以下是redis取代理举例
while True:
if r.llen('xb') > 0:
ip = r.lpop('xb')
if str(ip) != 'None':
ip = json.loads(ip)
temp_cha = int(time.time()) - int(ip["time"])
if temp_cha <= 60:
del ip['time']
break
r.close()
# 使用代理,这里可以选择只使用http的代理
request.meta['proxy'] = ip['http']
b. settings.py
# 启用中间件
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.RandomProxy': 542,
}
# 代理池配置
POOL_HOST = '192.168.0.123'
POOL_PORT = 6379
POOL_DB = 2
注意:
- 启用中间件时,后边的数字(例如:542)表示中间件执行的优先级,这个数字越小,优先级越高,越早被执行;范围:100 - 900
- 如果要禁用中间件,可以注释掉或者将优先级值设为 None
- Scrapy其实自带了UA中间件(UserAgentMiddleware)、代理中间件(HttpProxyMiddleware)和重试中间件(RetryMiddleware),所以原则上要开发者三种中间件,需要先禁用自带的中间件,如:
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.RandomProxy': 542,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None
}
但是大可不必这样做,因为scrapy自带的中间件源码已经给我们做了处理,关键源码:
def process_request(self, request, spider)
# ignore if proxy is already set
if 'proxy' in request.meta:
return
所以当我们设置了自定义的代理、UA等的时候,不需要注释掉自带的中间件
2. 更换UA
a. middlewares.py
class UAMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(settings['USER_AGENT_LIST'])
request.headers['User-Agent'] = ua
b. settings
# 启用中间件
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.UAMiddleware': 542,
}
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)",
"Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"AndroidDownloadManager",
"Apache-HttpClient/UNAVAILABLE (java 1.4)",
"Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)",
"Android50-AndroidPhone-8000-76-0-Statistics-wifi",
"Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)",
"Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)",
"Lite 1.0 ( http://litesuits.com )",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)",
]
3. 使用Cookies
可以修改下载中间件里的process_request方法,也可自定义
a. middlewares.py
class TestDownloaderMiddleware(object):
def process_request(self, request, spider):
# 使用cookie访问
request.cookies = COOKIES
return None
b. settings.py(这里就不再重复启用中间件的代码)
COOKIES = {
'a': 'aaaa',
'b': 'bbbbb',
'c': 'ccccc,
}
优化:将获取cookies的功能封装成一个程序,启动程序,重复获取cookie并存入redis或者数据库中,做一个cookie池,然后中间件中直接从cookie池中取cookie进行访问即可。降低被发现或者封号的可能性。
4. 中间件使用Selenium
selenium能够帮助我们解决异步加载的网站数据的抓取;不过弊端也很多,如效率低下,维护困难,爬虫程序启动所依赖的工具增加(浏览器和驱动)
a. middlewares.py
from scrapy.http import HtmlResponse
from selenium import webdriver
class SeleniumMiddleware(object):
def __init__(self):
# 这里以Chrome为例
self.driver = self.set_driver()
def set_driver(self):
"""
设置webdriver
"""
chrome = webdriver.ChromeOptions()
# 将js window.navigator.webdriver 的执行结果置为 undefined
chrome.add_experimental_option('excludeSwitches', ['enable-automation'])
# 设置代理(这里也可改为自动获取随机代理),然后填入
chrome.add_argument('--proxy-server=195.169.5.123:8888')
chrome.headless = True # 设置无头浏览器
path = r'./chromedriver.exe'
driver = webdriver.Chrome(options=chrome, executable_path=path)
return driver
def process_request(self, request, spider):
if spider.name == 'seleniumSpider':
self.driver.get(request.url)
time.sleep(2)
body = self.driver.page_source
return HtmlResponse(self.driver.current_url,
body=body,
encoding='utf-8',
request=request)
5. 中间件中重试
对于请求失败失败的url或者被重定向未取到数据的url,我们可以在中间件的process_response中进行重试
class RetryMiddleware(RetryMiddleware):
def __init__(self, settings):
RetryMiddleware.__init__(self, settings)
def process_response(self, request, response, spider):
# 如果重定向,我们可以使用request.meta['redirect_urls']这个方法查看到被重定向的url列表,列表里边保存了每次重定向的url
url = request.meta['redirect_urls'][0] # 取出有真实数据的那个url
yield scrapy.Request(url=url, method='POST', body=json_body, headers=headers)
6. 中间件中处理异常
一般情况下,请求失败之后,scrapy会原地重试三次,如果三次都失败了,则放弃这个请求;但如果url正确,由于各种原因导致三次请求都失败,则我们需要重新将其加入请求队列中;修改 process_exception 即可。例如现在有一个TCP超时错误:twisted.internet.error.TCPTimeOutError
# 先导入这个异常
from twisted.internet.error import TCPTimedOutError
# 还是在重试中间件中
class RetryMiddleware(RetryMiddleware):
def __init__(self, settings):
RetryMiddleware.__init__(self, settings)
def process_exception(self, request, exception, spider):
if isinstance(exception, TCPTimedOutError):
# 这里可以根据具体场景进行一系列操作(比如:如果是代理异常,则删除失效代理),我这里就不再举例
return request.copy()
二、爬虫中间件
应用场景
- 处理爬虫本身的异常;常用来处理爬虫异常(比如将错误记录到数据库中)
被调用的情况
- 当运行到yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。
- 当爬虫本身的代码出现了Exception的时候,爬虫中间件的process_spider_exception()方法被调用。
- 当爬虫里面的某一个回调函数parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。
- 当运行到start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
1. process_spider_exception(self, response, exception, spider)
a. middlewares.py
class ExceptionCheckMiddleware(object):
def process_spider_exception(self, response, exception, spider):
# 创建一个erroritem
error_item = ErrorItem()
# 记录错误发生的页数和时间
error_item['error_time'] = datetime.datetime,now().striftime('%Y-%m-%d %H:%M:%S')
error_item['page'] = response.meta['page']
yield error_item
b. settings.py
# 激活爬虫中间件
SPIDER_MIDDLEWARES = {
'Test.middlewares.TestSpiderMiddleware': 543,
}
2. process_spider_output(response, result, output)
这里只写关键代码
def process_spider_output(response, result, spider):
for item in result:
if isinstance(item, scrapy.Item):
# 这里可以对即将被提交给pipeline的item进行各种操作
print(f'item将会被提交给pipeline')
yield item