姓名:王怀帅 学号:16040410035
转载自:http://www.jianshu.com/p/27ce7c93b2d0=有修改
【嵌牛导读】:梯度下降是机器学习中较为基本也比较常见的一类优化算法的总称。
【嵌牛鼻子】:度量错误、批量梯度下降、其他梯度下降
【嵌牛提问】:如何通过sigmoid函数、链式求导法则以及基础的矩阵乘法来研究梯度下降?
【嵌牛正文】:
度量错误
梯度下降是一种从“错误”中学习的算法。你也许意识到我们需要找到一种度量预测的错误程度的方法(metric)。通常情况下我们会选择均方误差(MSE),但也有一些其他的选择,比如误差平方和(SSR)或是平均绝对误差(MAE)。文中统一使用均方误差。
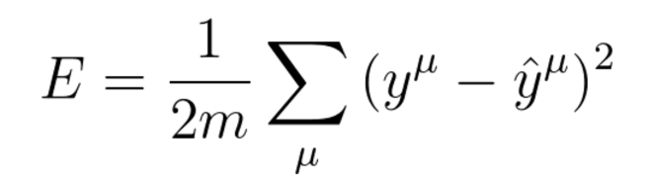
均方误差
图中的y以及y_hat的上角标μ指代的是训练数据集中第μ个数据,而非表示幂乘。
Google 和 Wikipedia 永远是最好的帮手,如果你想权衡使用 MSE 和 MAE 的利弊,我推荐你自己去探索一下。之前在StackExchange上看到过一个相关的问题,留在这里供你参考。一言以蔽之,MSE 对偏离实际值越多的预测值“惩罚”的越多(你想想,都给误差值平方了),有利于我们的模型更好的趋近最优情况。
这里需要插一句,梯度下降有很多不同的变种(稍后讨论),我们上面中给出的均方误差公式和接下来的算法,是对应批量梯度下降法(Batch Gradient Descent,简称BGD)的,这是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新。我们将继续使用 sigmoid 函数作为激活函数。
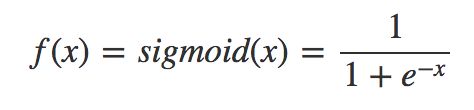
Sigmoid 函数

Sigmoid 函数的导数
我们先给出从 Udacity 深度学习课程中截取的算法描述,我们进行逐步分析这个算法的实现。

批量梯度下降
预设:
这一部分没有写在上图的算法中,但是是不可缺少的。我们需要初始化一些参数。分别为训练次数e,学习率(learning rate)η和预设权重(weight)w。关于预设权重的设定,请参考下面这段话。
First, you'll need to initialize the weights. We want these to be small such that the input to the sigmoid is in the linear region near 0 and not squashed at the high and low ends. It's also important to initialize them randomly so that they all have different starting values and diverge, breaking symmetry. So, we'll initialize the weights from a normal distribution centered at 0. A good value for the scale is 1/√
n where n is the number of input units. This keeps the input to the sigmoid low for increasing numbers of input units.
第一步将初始化变化的权重 Δw,这一步实际上是便于我们稍后将算法转为代码。接下来第二步,针对训练数据集中的每一组数据我们执行以下三个小步骤 (公式已略去,参见上图):
将数据集在神经网络中进行一次正向传递,得到预测结果y_hat
计算输出层神经元的误差梯度(error gradient)δ
更新权重变化Δw_i
在完成了一次对整个数据集的遍历之后,我们将进行第三步,将Δw_i (权重变化值)和w_i (预设的权重)相加,得到新的w_i。 这样,我们便完成了一次对权重的更新。之后我们只需要重复e次第二、三步。
梯度下降的整个过程可以用下图来进行理解。最开始我们预设的权重在最外侧深红色圆环上,经过一次一次的迭代逐渐靠近中心的最优点(optima)。
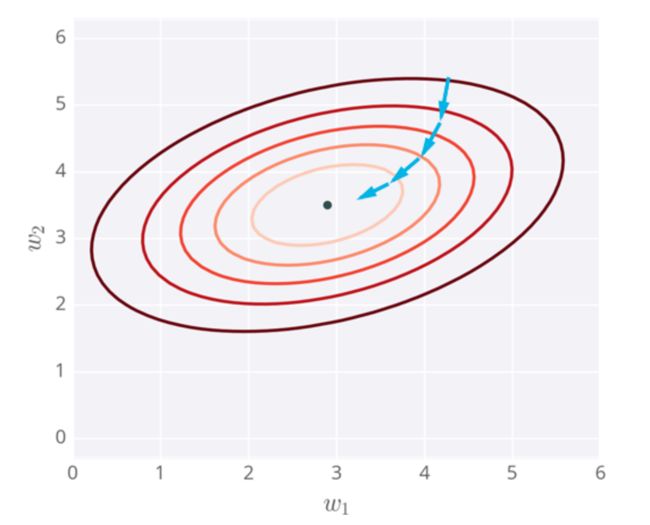
梯度下降过程的可视化
接下来我们来一起构建一个 Python 完成的梯度下降算法。完整的数据和代码可以在我的GitHub Repo找到,这里就不贴出数据和准备数据的代码了。
import numpy as np
from data_prep import features, targets, features_test, targets_test
def sigmoid(x):
"""Calculate sigmoid"""
return 1 / (1 + np.exp(-x))
np.random.seed(42)
n_records, n_features = features.shape
last_loss = None
# 预设权重
weights = np.random.normal(scale=1 / n_features ** .5, size=n_features)
# 设定循环次数和学习率
epochs = 1000
learnrate = 0.5
for e in range(epochs):
# 第一步,设定预设变化的权重为0
del_w = np.zeros(weights.shape)
# 遍历全部数据集
for x, y in zip(features.values, targets):
# 正向传递计算y_hat
output = sigmoid(np.dot(weights, x))
# 计算误差梯度
error = (y - output) * output * (1 - output)
# 更新权重变化
del_w += error * x
# 对预设权重的更新
weights += learnrate * del_w / n_records
# 打印出运算过程的一些数据
if e % (epochs / 10) == 0:
out = sigmoid(np.dot(features, weights))
loss = np.mean((out - targets) ** 2)
if last_loss and last_loss < loss:
print("Train loss: ", loss, " WARNING - Loss Increasing")
else:
print("Train loss: ", loss)
last_loss = loss
# 验证我们的算法,在测试数据上进行测试
tes_out = sigmoid(np.dot(features_test, weights))
predictions = tes_out > 0.5
accuracy = np.mean(predictions == targets_test)
print("Prediction accuracy: {:.3f}".format(accuracy))
如果你对第三步中更新预设权重的部分有疑惑,这里有一行代码需要你额外注意,
# 对预设权重的更新
weights += learnrate * del_w / n_records
由于我们是将所有训练数据都遍历了一遍之后得到的变化权重del_w, 所以需要将它除以训练数据集的数量。这也是和我们即将提到的另一种算法有差异的部分。
其他梯度下降方法
可以从参考资料的第一篇文章中得知,除了批量梯度下降法(Batch Gradient Descent,简称BGD)外,还有随机梯度下降法(Stochastic Gradient Descent,简称SGD)以及更进一步的小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)。这几种不同方法的优劣对比可以单开一篇文章来探讨(或者参见参考资料第一篇),这里只通过介绍性的知识进行简单总结。
随机梯度下降法和批量梯度下降法不同的是,在后者的训练过程中,每一次的训练都需要遍历全部的训练数据集,这种算法的确可以保证达到全局最优解(global optimal)。然而,如果我们的数据量较大,或者训练数据的维度较高(特征数量多)的时候,巨大的计算量会极大的拖慢我们模型的训练速度。所以这里提出一种改进的算法——随机梯度下降法。唯一一点和批量梯度下降法不同的是,我们每次选取一个训练数据,计算误差梯度后,直接在预设权重上进行更新。这样就避免了遍历全部数据后再求平均变化权重的计算过程。极大的减少了计算量,对训练速度有着明显的提高。美中不足的是,这种算法只能达到一个和全局最优解极为接近的数值,而且不利于并行实现。
下面给出随机梯度下降法的实现
import numpy as np
from data_prep import features, targets, features_test, targets_test
def sigmoid(x):
"""Calculate sigmoid"""
return 1 / (1 + np.exp(-x))
np.random.seed(42)
n_records, n_features = features.shape
last_loss = None
# 预设权重
weights = np.random.normal(scale=1 / n_features ** .5, size=n_features)
# 设定学习率
learnrate = 0.5
# 遍历全部数据集
for x, y in zip(features.values, targets):
# 正向传递计算y_hat
output = sigmoid(np.dot(weights, x))
# 计算误差梯度
error = (y - output) * output * (1 - output)
# 更新预设权重
weights += error * x
# 验证我们的算法,在测试数据上进行测试
tes_out = sigmoid(np.dot(features_test, weights))
predictions = tes_out > 0.5
accuracy = np.mean(predictions == targets_test)
print("Prediction accuracy: {:.3f}".format(accuracy))
可以看到,除了少去了整体循环的过程和更新权重的部分有变化,其余的地方并没有太多改动过。
小批量梯度下降法(MBGD),是一种结合了以上两种梯度下降法的新想法。其思路非常简单,在 BGD 方法中,每次循环都将遍历整个数据集,而在 SGD 方法中,没有额外循环,只遍历每个数据一次即可。MBGD 则保留了 BGD 中循环的思路,但每次循环中并不会遍历全部数据,而是有选择的随机选取少量数据。具体的思路可以参考 Google。
BGDSGDMBGD
全局最优是近似比SGD更接近最优
训练速度很慢很快比SGD稍慢