https://www.kaggle.com/c/house-prices-advanced-regression-techniques
0、模型准备
#Essentials
import pandas as pd
import numpy as np
#Plots
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
#Models
from sklearn import linear_model
from sklearn import svm
from sklearn import ensemble
import xgboost
import lightgbm
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
from mlxtend.regressor import StackingCVRegressor
#Misc
from sklearn import model_selection
from sklearn import metrics
from sklearn import preprocessing
from sklearn import neighbors
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
#ignore warnings
import warnings
warnings.filterwarnings("ignore")
# path='C:\\Users\\sunsharp\\Desktop\\kaggle\\house-pricing\\'
path=r'/Users/ranmo/Desktop/kaggle/house-pricing/'
#===========
# 函数定义
#===========
#1、训练模型
def model_eval(model,X_train,y_train):
l_rmes=[]
kf=model_selection.KFold(10,random_state=10)
for train,test in kf.split(X_train):
X_train1 = X_train.iloc[train]
y_train1 = y_train.iloc[train]
X_test1 = X_train.iloc[test]
y_test1 = y_train.iloc[test]
y_pred1=model.fit(X_train1,y_train1).predict(X_test1)
e=np.sqrt(metrics.mean_squared_error(y_pred1,y_test1)) #还要再转化为root值
l_rmes.append(e)
print(l_rmes)
print(np.mean(l_rmes))
print()
print()
return np.mean(l_rmes)
#2、模型预测
def model_predict(model,X_test,outpath):
y_test_pred=model.predict(X_test)
SalePrice_pred=np.floor(np.exp(y_test_pred))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)
#看一下特征情况
df=pd.read_csv('%strain.csv'%path)
df=df.set_index('Id')
df['SalePrice']=np.log(df['SalePrice']) #直接在原数据进行处理了,方便之后的分析
df.columns
#看一下有无负值
df.describe().min() #无负值数据
#看一下非数值类的数据,需要进行独热编码
df.dtypes[df.dtypes==object]
df1=pd.get_dummies(df)
df.shape
df1.shape #由原始的81个特征扩展为289个特征
#检查缺失项,独热编码会把缺失项全编码为0,因此是不用考虑的
# 可以通过这样的方式来直接判断
# df[df.dtypes[df.dtypes!=object].index].info()
# 不好直接判断,也可以通过这样来判断
for i in df1.columns:
if df1[i].value_counts().sum()!=len(df1):
print(i)
#查看一下缺失项的具体详情:
# LotFrontage:Linear feet of street connected to property 物业到街道的距离
# MasVnrArea:Masonry veneer area in square feet 砌面贴面面积
# GarageYrBlt:Year garage was built 车库建成的日期
#处理缺失值
df1['LotFrontage']=df1['LotFrontage'].fillna(df['LotFrontage'].mean())
df1['MasVnrArea']=df1['MasVnrArea'].fillna(0)
df1['GarageYrBlt']=df1['GarageYrBlt'].fillna(df['GarageYrBlt'].mean())
#数据处理完,用xgboost跑一下基本模型
X_train=df1.sample(frac=1,random_state=10).drop('SalePrice',axis=1)
y_train=df1.sample(frac=1,random_state=10).SalePrice
#=============
#xgboost 跑一下基本模型
#=============
reg=xgboost.XGBRegressor(objective='reg:squarederror')
model_eval(reg,X_train,y_train)

image.png
#=============
#用基本模型跑一下训练集
#=============
df_test=pd.read_csv('%stest.csv'%path).set_index('Id')
#独热编码,这个必须联合train里的数据进行编码了,不然维度是不够的
temp=pd.concat([df,df_test],axis=0)
temp=temp[df.columns] #columns被打乱,重新排一下
temp=pd.get_dummies(temp)
df1_test=temp.loc[df_test.index.to_list()]
#缺失值处理
for i in df1_test.columns:
if df1_test[i].value_counts().sum()!=len(df1_test):
print(i)
#缺失值有点多,有比较多0值的都处理为0
df1_test['LotFrontage']=df1_test['LotFrontage'].fillna(df['LotFrontage'].mean())
df1_test['MasVnrArea']=df1_test['MasVnrArea'].fillna(0)
df1_test['BsmtFinSF1']=df1_test['BsmtFinSF1'].fillna(0)
df1_test['BsmtFinSF2']=df1_test['BsmtFinSF2'].fillna(0)
df1_test['BsmtUnfSF']=df1_test['BsmtUnfSF'].fillna(0)
df1_test['TotalBsmtSF']=df1_test['TotalBsmtSF'].fillna(0)
df1_test['BsmtFullBath']=df1_test['BsmtFullBath'].fillna(0)
df1_test['BsmtHalfBath']=df1_test['BsmtHalfBath'].fillna(0)
df1_test['GarageYrBlt']=df1_test['GarageYrBlt'].fillna(df['GarageYrBlt'].mean())
df1_test['GarageCars']=df1_test['GarageCars'].fillna(0)
df1_test['GarageArea']=df1_test['GarageArea'].fillna(0)
#用训练好的模型预测
X_test=df1_test.drop('SalePrice',axis=1)
if X_test.shape[1]==X_train.shape[1]:
print('ok')
# #模型预测
# outpath='%s//reg//1211//'%path
# reg.fit(X_train,y_train)
# model_predict(reg,X_test,outpath)
- 实际成绩13.971
一、EDA
1.1 目标值的偏态检测
#重新进行EDA探索
#销售价格分布
plt.figure(figsize=(8,7))
sns.distplot(df.SalePrice)
plt.grid(True)
print('偏度:%f'%df.SalePrice.skew()) #标准正太分布为0
print('峰度:%f'%df.SalePrice.kurt()) #标准正太分布为1
# 对原始数据去了对数之后,正好分布趋于正态分布

image.png
(因为已经做过对数处理了)
1.2 相关性检测
#数据相关性
corrmat=df.corr()
plt.figure(figsize=(15,15))
sns.heatmap(corrmat,linewidths=0.5)

image.png
#选取相关性最高的10个特征
corrmat_new=df[corrmat.nlargest(10,'SalePrice')['SalePrice'].index].corr()
plt.figure(figsize=(10,10))
sns.heatmap(corrmat_new,linewidths=0.5,annot=True)

image.png
(实际上针对高度线性相关的数据可能应该做处理,我这里没有做处理,在最后提出的优化方案那里会说一下。。)
sns.set()
sns.pairplot(df[['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']])
#这里是只保留了部分特征,去掉了GarageArea、1stFloor、TotRmsAbvGrd

image.png
- 从上面的对图可以看出是存在离群点(异常点的),所以有必要把离群点筛选出来
1.3 离群点检测
#检测异常点,这个只是单纯靠样本分布的间隔来检测
def detect_outliers(x,k=5,plot=False,y=df.SalePrice,n=40):
x_new=x.dropna() #必须把空值去了
lof=neighbors.LocalOutlierFactor(n_neighbors=n)
lof.fit_predict(np.array(x_new).reshape(-1,1))
lof_scr = lof.negative_outlier_factor_
out_idx=x_new.index[pd.Series(lof_scr).sort_values()[:k].index] #因为去了空值之后index不对应了,所以要转化
if plot:
plt.figure(figsize=(10,8))
plt.scatter(x_new,y[x_new.index],c=np.exp(lof_scr), cmap='RdBu') #用指数是为了放大差距
return out_idx
- 附局部密度离群点检测:https://blog.csdn.net/wangyibo0201/article/details/51705966
# 以GrLivArea为例进行检测
#sns.set()
outs=detect_outliers(df.GrLivArea,plot=True)
#实际上 lof 离群检测中n的设置会影响结果,看一下n的合适取值
for i in range(10,70,5):
outs=detect_outliers(df.GrLivArea,n=i)
print('n=%d: %s'%(i, list(outs)))

image.png
#对所有数据维度进行lof 离群点检测,并判断其离群的次数
from collections import Counter
all_outliers=[]
numeric_features = df.drop('SalePrice',axis=1).dtypes[df.drop('SalePrice',axis=1).dtypes != 'object'].index
for i in numeric_features:
outs=detect_outliers(df[i]) #存在nan值情况
all_outliers.extend(outs)
print(Counter(all_outliers).most_common())

image.png
#一共检测出140个离群点,理论上出现次数越多的点,为离群点的概率就越大,这里用模型精度来检验
l_rems_list=[]
print('outlier_number=0:')
l_rems_list.append(model_eval(reg,X_train,y_train))
i=5
while i<=140:
outliers_list=Counter(all_outliers).most_common()[:i]
outliers_listid=pd.DataFrame(outliers_list,columns=['Id','times']).Id
#开始模型精度测试
print('outlier_number=%d:'%(i))
l_rems=model_eval(reg,X_train.drop(index=outliers_listid),y_train.drop(index=outliers_listid))
l_rems_list.append(l_rems)
i+=5
plt.figure(figsize=(10,6))
plt.plot(range(0,141,5),l_rems_list,)
plt.xlabel('outliers_number')

image.png
#粗筛异常点
from collections import Counter
numeric_features = df.drop('SalePrice',axis=1).dtypes[df.drop('SalePrice',axis=1).dtypes != 'object'].index
outliers_number=[]
l_rems_list1=[] #用剔除异常后的数据训练模型并自行测试
l_rems_list2=[] #用剔除异常后的数据训练模型并测试全部数据
print('k=0,outlier_number=0:')
l_rems=model_eval(reg,X_train,y_train)
l_rems_list1.append(l_rems)
l_rems_list2.append(l_rems)
for k in range(4,10,1):
all_outliers=[]
for i in numeric_features:
outs=detect_outliers(df[i],k=k)
all_outliers.extend(outs)
outliers_number.append(len(Counter(all_outliers).most_common()))
#将其全部剔除后进行模型测试
outliers_listid=pd.DataFrame(Counter(all_outliers).most_common(),columns=['Id','times']).Id
#开始模型精度测试
print('k=%d,outlier_number=%d:'%(k,len(Counter(all_outliers).most_common())))
l_rems1=model_eval(reg,X_train.drop(index=outliers_listid),y_train.drop(index=outliers_listid))
l_rems_list1.append(l_rems1)
l_rems2=np.sqrt(metrics.mean_squared_error(reg.fit(X_train.drop(index=outliers_listid),y_train.drop(index=outliers_listid)).predict(X_train),y_train))
l_rems_list2.append(l_rems2)
# plt
plt.figure(figsize=(10,6))
plt.plot([0,4,5,6,7,8,9],l_rems_list1)
plt.plot([0,4,5,6,7,8,9],l_rems_list2)
plt.xlabel('k_number')

image.png
#精筛异常点,k=4时,共有114个异常点
for i in numeric_features:
outs=detect_outliers(df[i],k=4) #存在nan值情况
all_outliers.extend(outs)
print(Counter(all_outliers).most_common())
l_rems_list1=[] #用剔除异常后的数据训练模型并自行测试
l_rems_list2=[] #用剔除异常后的数据训练模型并测试全部数据
print('outlier_number=0:')
l_rems=model_eval(reg,X_train,y_train)
l_rems_list1.append(l_rems)
l_rems_list2.append(l_rems)
i=5
while i<=114:
outliers_list=Counter(all_outliers).most_common()[:i]
outliers_listid=pd.DataFrame(outliers_list,columns=['Id','times']).Id
#开始模型精度测试
print('outlier_number=%d:'%(i))
l_rems1=model_eval(reg,X_train.drop(index=outliers_listid),y_train.drop(index=outliers_listid))
l_rems_list1.append(l_rems1)
l_rems2=np.sqrt(metrics.mean_squared_error(reg.fit(X_train.drop(index=outliers_listid),y_train.drop(index=outliers_listid)).predict(X_train),y_train))
l_rems_list2.append(l_rems2)
i+=5
# plt
plt.figure(figsize=(10,6))
plt.plot(range(0,114,5),l_rems_list1)
plt.plot(range(0,114,5),l_rems_list2)
plt.xlabel('outlier_number')

image.png
# 剔除20个异常点
# from collections import Counter
# all_outliers=[]
# numeric_features = df.drop('SalePrice',axis=1).dtypes[df.drop('SalePrice',axis=1).dtypes != 'object'].index
# for i in numeric_features:
# outs=detect_outliers(df[i]) #存在nan值情况
# all_outliers.extend(outs)
# print(Counter(all_outliers).most_common())
i=20
outliers_list=Counter(all_outliers).most_common()[:i]
outliers_listid=pd.DataFrame(outliers_list,columns=['Id','times']).Id
df_new=df.drop(index=outliers_listid)
X_train=df_new.sample(frac=1,random_state=10).drop('SalePrice',axis=1)
y_train=df_new.sample(frac=1,random_state=10).SalePrice
print(df_new.shape)
print(df.shape)

image.png
- 实际成绩由0.13971变为0.13634
二、特征工程
# 合并train和test,但同时要防止leak
df_new=df.drop(index=outliers_listid) #因为上面一步在测算模型的时候进行了填充,所以得重新更新下
df_feature=pd.concat([df_new,df_test],axis=0)
df_feature=df_feature[df_new.columns] #columns被打乱,重新排一下
df_feature
2.1 将不属于数值型的特征转化为字符串
df_feature.dtypes[df_feature.dtypes!=object] #依次对照,检查其是否不应该为数值型

image.png
df_feature['MSSubClass'] = df_feature['MSSubClass'].apply(str)
df_feature['YrSold'] = df_feature['YrSold'].astype(str)
df_feature['MoSold'] = df_feature['MoSold'].astype(str)
2.2 缺失值填充
#2.2 缺失值填充
df_feature.isnull().any()[df_feature.isnull().any()] #查看样本说明确定那些是允许缺失的特征(该样本没有这项特征)
special_features=['Alley','BsmtQual','BsmtCond','BsmtExposure','BsmtFinType1','BsmtFinType2','FireplaceQu',
'GarageType','GarageFinish','GarageQual','GarageCond','PoolQC','Fence','MiscFeature']
features_missing=list(df_feature.isnull().any()[df_feature.isnull().any()].index)
for i in special_features:
features_missing.remove(i)
print(len(features_missing))
features_missing

image.png
#顺便看一下train数据中缺失项
features_missing_train=list(df_new.isnull().any()[df_new.isnull().any()].index)
for i in special_features:
try:
features_missing_train.remove(i)
except:
continue
print(len(features_missing_train))
features_missing_train

image.png
# 缺失值填充的函数定义
#中间会涉及到数据泄露,因为没有严格剥离
def feature_missing(df,feature,feature_refer=None,method='mode'):
#数值型的method=[0,'mean','median']
#非数值型的method=['mode']
if feature_refer==None:
if method=='mode':
return df[feature].fillna(df[feature].value_counts().index[0]) #返回众数
if method==0:
return df[feature].fillna(0) #返回0
if method=='mean':
return df[feature].describe()['mean']
if method=='median':
return df[feature].describe()['50%']
else:
df[feature_refer]=feature_missing(df,feature=feature_refer) #参考列不能有空值,按众数填充
if method=='mean':
return df.groupby(feature_refer)[feature].transform(lambda x:x.fillna(x.mean()))
if method=='mode':
return df.groupby(feature_refer)[feature].transform(lambda x:x.fillna(x.mode()[0]))
if method=='median':
return df.groupby(feature_refer)[feature].transform(lambda x:x.fillna(x.median()))
def feature_corr(df,feature,k=10):
corrmat=df.corr()
corrmat_feature=df[corrmat.nlargest(k,feature)[feature].index].corr()
plt.figure(figsize=(10,10))
sns.heatmap(corrmat_feature,linewidths=0.5,annot=True)
def fillmethod_eval(model,df,feature,method_list,feature_refer_list=None): #feature_refer和method_list都必须是list形式
#数值型的method=[0,'mean','median']
#非数值型的method=['mode']
if feature_refer_list==None:
for i in method_list:
df_eval=df
#第一步填充,第二步测评
df_eval[feature]=feature_missing(df,feature,method=i)
df_eval=pd.get_dummies(df_eval)
print('method:%s'%(i))
model_eval(model,df_eval.sample(frac=1,random_state=10).drop('SalePrice',axis=1),df_eval.sample(frac=1,random_state=10).SalePrice)
else:
for j in feature_refer_list:
for i in method_list:
try: #因为数值型没有mode,非数值型没有mean和median
df_eval=df
#第一步填充,第二步测评
df_eval[feature]=feature_missing(df,feature,feature_refer=j,method=i)
df_eval=pd.get_dummies(df_eval)
print('refre:%s ,method:%s'%(j,i))
model_eval(model,df_eval.sample(frac=1,random_state=10).drop('SalePrice',axis=1),df_eval.sample(frac=1,random_state=10).SalePrice)
except:
continue

image.png
- 所以其实我是基于模型测试结果来进行填充,主要是三种办法:1、如果有相关性很高的,则用相关性很高的变量来填充;2、用自己的均值、中位数等等来填充;三、用其他变量的分组的均值、中无数等来填充
# train缺失特征填充
#MasVnrType和MasVnrArea
df_feature['MasVnrType']=df_feature['MasVnrType'].fillna('None')
df_feature['MasVnrArea']=df_feature['MasVnrArea'].fillna(0)
#LotFrontage
# feature_corr(df_feature,'LotFrontage') #没有很强相关性的
print('no refer:')
fillmethod_eval(reg,df_feature[:1440],'LotFrontage',method_list=[0,'mean','median'])
print('refer:')
fillmethod_eval(reg,df_feature[:1440],'LotFrontage',method_list=['mode','mean','median'],
feature_refer_list=['MSZoning','LotArea','Street','Alley','Neighborhood','Condition1'])
#结论:refre:street ,method:mean
#LotFrontage
df_feature[:1440].groupby('Street')['LotFrontage'].agg(lambda x: np.mean(pd.Series.mode(x))) #数值型groupby的众数读取
for i in df_feature.index:
if str(df_feature.loc[i,'LotFrontage'])=='nan': #配合列的名称则必须用loc
if df_feature.loc[i,'Street']=='Grvl':
df_feature.loc[i,'LotFrontage']=90.25
else:
df_feature.loc[i,'LotFrontage']=60.00
#Electrical
print('no refer:')
fillmethod_eval(reg,df_feature[:1440],'Electrical',method_list=['mode'])
print('refer:')
fillmethod_eval(reg,df_feature[:1440],'Electrical',method_list=['mode'],
feature_refer_list=['Heating','HeatingQC','CentralAir'])
#结论:refre:CentralAir ,method:mode
#Electrical
df_feature[:1440].groupby('CentralAir')['Electrical'].describe() #非数值型groupby的众数读取
df_feature['Electrical'].fillna('SBrkr')
#GarageYrBlt
feature_corr(df_feature,'GarageYrBlt') #有强相关性的
df_feature[['GarageYrBlt','YearBuilt']] #查看,基本上GarageYrBlt=YearBuilt
for i in df_feature.index:
if str(df_feature.loc[i,'GarageYrBlt'])=='nan': #配合列的名称则必须用loc
df_feature.loc[i,'GarageYrBlt']=df_feature.loc[i,'YearBuilt']
#结论:GarageYrBlt=YearBuilt

image.png
df_feature['MSZoning']=feature_missing(df_feature,feature='MSZoning',feature_refer='MSSubClass',method='mode')
df_feature['Utilities']=feature_missing(df_feature,feature='Utilities',method='mode')
for i in df_feature.index:
if str(df_feature.loc[i,'Exterior1st'])=='nan': #配合列的名称则必须用loc
df_feature.loc[i,'Exterior1st']=df_feature.loc[i,'Exterior2nd']
for i in df_feature.index:
if str(df_feature.loc[i,'Exterior2nd'])=='nan': #配合列的名称则必须用loc
df_feature.loc[i,'Exterior2nd']=df_feature.loc[i,'Exterior1st']
# df_feature['Exterior1st'].value_counts().sum()
# df_feature['Exterior2nd'].value_counts().sum()
# 检查出来还剩一项空值,用众数填充
df_feature['Exterior1st']=feature_missing(df_feature,feature='Exterior1st',method='mode')
df_feature['Exterior2nd']=feature_missing(df_feature,feature='Exterior2nd',method='mode')
# df_feature.BsmtFinSF1[df_feature.BsmtFinSF1.isnull()]
# df_feature.BsmtFinSF2[df_feature.BsmtFinSF2.isnull()]
# df_feature[['BsmtQual','BsmtCond','BsmtFinSF1','BsmtFinSF2']].loc[2121]
#检查出来其实是0值
df_feature['BsmtFinSF1']=df_feature['BsmtFinSF1'].fillna(0)
df_feature['BsmtFinSF2']=df_feature['BsmtFinSF2'].fillna(0)
df_feature['BsmtUnfSF']=df_feature['BsmtUnfSF'].fillna(0)
df_feature['TotalBsmtSF']=df_feature['TotalBsmtSF'].fillna(0)
df_feature['BsmtFullBath']=df_feature['TotalBsmtSF'].fillna(0)
df_feature['BsmtHalfBath']=df_feature['TotalBsmtSF'].fillna(0)
df_feature['KitchenQual']=feature_missing(df_feature,feature='KitchenQual',method='mode')
df_feature['Functional']=feature_missing(df_feature,feature='Functional',method='mode')
#feature_corr(df_feature,'GarageCars') #GarageCars和GarageArea强相关,但正好两个都是空值,但偏偏又有车库。。。
# df_feature.GarageArea[df_feature.GarageArea.isnull()]
# df_feature.GarageCars[df_feature.GarageCars.isnull()]
# df_feature.GarageType[df_feature.GarageCars.isnull()]
df_feature['GarageCars']=feature_missing(df_feature,feature='GarageCars',method='mode')
df_feature['GarageArea']=feature_missing(df_feature,feature='GarageArea',method='mode')
df_feature['SaleType']=feature_missing(df_feature,feature='SaleType',method='mode')
- 实际成绩由0.13634降为0.13596,说明缺失值填充对模型精度提高很有限,而且在填充过程中你并不能确定哪一种方法是最好的。
2.3 数据偏度矫正
#数值型数据列偏度矫正
df_feature3=df_feature
highskew_index=df_feature3[numeric_features].skew()[df_feature3[numeric_features].skew() >0.15].index
#将偏度大于0.15的进行矫正,实际上根据测试,选哪个阈值进行矫正,影响都不大
for i in highskew_index:
df_feature3[i] = boxcox1p(df_feature3[i], boxcox_normmax(df_feature3[i] + 1))
2.4 特征删除
#特征删除
df_feature3.Utilities.value_counts()
df_feature3.Street.value_counts()
df_feature3.PoolQC.value_counts()
df_feature3.Fence.value_counts()
df_feature3.FireplaceQu.value_counts()
df_feature3.MiscFeature.value_counts()
#上面几个特征缺失率都太高了
df_feature5=df_feature3.drop(['Utilities', 'Street', 'PoolQC','MiscFeature', 'Alley', 'Fence'], axis=1)
2.5 融合生成新特征(其实应该最后来做这个步骤)
#融合生成新特征
#根据直觉进行的融合
df_feature6=df_feature5.copy() #为什么一定要copy???不用copy,对df_feature6的更改会影响df_feature5.。。疑问??
df_feature6['HasWoodDeck'] = (df_feature6['WoodDeckSF'] == 0) * 1
df_feature6['HasOpenPorch'] = (df_feature6['OpenPorchSF'] == 0) * 1
df_feature6['HasEnclosedPorch'] = (df_feature6['EnclosedPorch'] == 0) * 1
df_feature6['Has3SsnPorch'] = (df_feature6['3SsnPorch'] == 0) * 1
df_feature6['HasScreenPorch'] = (df_feature6['ScreenPorch'] == 0) * 1
df_feature6['YearsSinceRemodel'] = df_feature6['YrSold'].astype(int) - df_feature6['YearRemodAdd'].astype(int)
df_feature6['Total_Home_Quality'] = df_feature6['OverallQual'] + df_feature6['OverallCond']
df_feature6['TotalSF'] = df_feature6['TotalBsmtSF'] + df_feature6['1stFlrSF'] + df_feature6['2ndFlrSF']
df_feature6['YrBltAndRemod'] = df_feature6['YearBuilt'] + df_feature6['YearRemodAdd']
df_feature6['Total_sqr_footage'] = (df_feature6['BsmtFinSF1'] + df_feature6['BsmtFinSF2'] +
df_feature6['1stFlrSF'] + df_feature6['2ndFlrSF'])
df_feature6['Total_Bathrooms'] = (df_feature6['FullBath'] + (0.5 * df_feature6['HalfBath']) +
df_feature6['BsmtFullBath'] + (0.5 * df_feature6['BsmtHalfBath']))
df_feature6['Total_porch_sf'] = (df_feature6['OpenPorchSF'] + df_feature6['3SsnPorch'] +
df_feature6['EnclosedPorch'] + df_feature6['ScreenPorch'] +
df_feature6['WoodDeckSF'])
df_feature6['YrBltAndRemod']=df_feature6['YearBuilt']+df_feature6['YearRemodAdd']
df_feature6['TotalSF']=df_feature6['TotalBsmtSF'] + df_feature6['1stFlrSF'] + df_feature6['2ndFlrSF']
df_feature6['Total_sqr_footage'] = (df_feature6['BsmtFinSF1'] + df_feature6['BsmtFinSF2'] +
df_feature6['1stFlrSF'] + df_feature6['2ndFlrSF'])
df_feature6['Total_Bathrooms'] = (df_feature6['FullBath'] + (0.5 * df_feature6['HalfBath']) +
df_feature6['BsmtFullBath'] + (0.5 * df_feature6['BsmtHalfBath']))
df_feature6['Total_porch_sf'] = (df_feature6['OpenPorchSF'] + df_feature6['3SsnPorch'] +
df_feature6['EnclosedPorch'] + df_feature6['ScreenPorch'] +
df_feature6['WoodDeckSF'])
2.6 简化特征(应该在特征融合之间)
#简化特征,对于某些分布单调(比如100个数据中有99个的数值是0.9,另1个是0.1)的数字型数据列,进行01取值处理。
#要确保其他字段没有包含这部分信息,比如有一个字段专门表示有无pool的,那就不用额外生成
df_feature7=df_feature6.copy()
df_feature7['haspool'] = df_feature7['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
df_feature7['has2ndfloor'] = df_feature7['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
df_feature7['hasgarage'] = df_feature7['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
df_feature7['hasbsmt'] = df_feature7['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
df_feature7['hasfireplace'] = df_feature7['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
2.7 删除单一特征
#get_dummies并删除单一特征(比如某个值出现了99%以上)的特征
print("before get_dummies:",df_feature7.shape)
df_feature_final = pd.get_dummies(df_feature7)
print("after get_dummies:",df_feature_final.shape)
X_train=df_feature_final.iloc[:1440].sample(frac=1,random_state=10).drop('SalePrice',axis=1)
y_train=pd.DataFrame(df_feature_final.iloc[:1440].sample(frac=1,random_state=10).SalePrice) #不然会变成series
X_test=df_feature_final.iloc[1440:].drop('SalePrice',axis=1)
##删除单一特征,但模型结果无差异,毕竟xgboost本身就具备筛掉不重要的特征的功能,所以这里不进行单一特征删除
# for thre in np.arange(99.8,100,0.02):
# overfit = []
# for i in X_train.columns:
# counts = X_train[i].value_counts()
# zeros = counts.iloc[0]
# if zeros / len(X_train) * 100 > thre: #99.94是可以调整的,80,90,95,99...
# overfit.append(i)
# print('thre',thre)
# print(overfit)
# model_eval(reg,X_train.drop(overfit,axis=1),y_train)
print('X_train', X_train.shape, 'y_train', y_train.shape, 'X_test', X_test.shape)
print('feature engineering finished!')

image.png
- 删除单一特征和简化特征都是一样的目的,只不过删除单一特征是在get_dummies之后再删除了一次,删除的是独热编码特征。
2.8 结论
X_train.to_csv('%sX_train.csv'%path)
y_train.to_csv('%sy_train.csv'%path)
X_test.to_csv('%sX_test.csv'%path)
- 特征工程里面最有效的步骤是异常值筛选,然后把原始的0.139的成绩提升为0.133~0.135之间
三、训练模型
X_train=pd.read_csv('%sX_train.csv'%path,index_col='Id')
y_train=pd.read_csv('%sy_train.csv'%path,index_col='Id')
X_test=pd.read_csv('%sX_test.csv'%path,index_col='Id')
# 函数定义:
def find_cv(model,X_train,y_train,param_test):
model_cv=model_selection.GridSearchCV(model,param_test,cv=10,n_jobs=-1,scoring='neg_mean_squared_error')
model_cv.fit(X_train,y_train)
print("model_cv.cv_results_['mean_test_score']:=%s"%np.sqrt(-model_cv.cv_results_['mean_test_score'])) #结果是开根号值
print()
print(np.sqrt(-model_cv.best_score_))
print(model_cv.best_params_)
3.1 lasso
# lasso win
model=linear_model.Lasso(0.00037,random_state=10)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//lasso//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.11658
3.2 ridge
# ridge
model=linear_model.Ridge(9,random_state=10)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//ridge//'%path
y_test_pred=model.fit(X_train,y_train).predict(X_test)
SalePrice_pred=np.exp(y_test_pred)
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred2.reshape(1,-1)[0]}).set_index('Id') #ridge模型自己怪。。生成的结果不是标准格式
df_reg.to_csv('%stest_pred.csv'%outpath)
#实际成绩 0.11668
3.3 ela
model=linear_model.ElasticNet(0.00039,0.95,random_state=10)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//ela//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.11775
3.4 svr
model=svm.SVR(gamma=1e-08,C=125000)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//svr//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.12521
- svr C值过大,怀疑是因为数据没有进行归一化导致的。。。
3.5 GDBT
model=ensemble.GradientBoostingRegressor(
max_depth=3,
min_weight_fraction_leaf=0.004,
min_impurity_split=0,
subsample=0.82,
max_features=0.45,
n_estimators=480,
learning_rate=0.064,
random_state=10
)
# model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//gdbt//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.13023
3.6 lgbm
model=lightgbm.LGBMRegressor(random_state=10,
max_depth=8,
num_leaves=11,
min_child_samples=20,
min_child_weight=0,
min_split_gain=0,
subsample=0.8,
colsample_bytree=0.24,
subsample_freq=1,
reg_alpha=0.0009,
reg_lambda=0.00088,
learning_rate=0.006,
n_estimators=2550
)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//lgbm//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.12411
3.7 xgbt
model=xgboost.XGBRegressor(random_state=10,
max_depth=6,
min_child_weight=6,
min_split_gain=6,
subsample=0.77,
colsample_bytree=0.62,
reg_alpha=1e-5,
reg_lambda=1,
n_estimators=150,
learning_rate=0.1,
)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//xgbt//'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.12839
四、stacking
lasso=linear_model.Lasso(0.00037,random_state=10)
ridge=linear_model.Ridge(9,random_state=10)
ela=linear_model.ElasticNet(0.00039,0.95,random_state=10)
svr=svm.SVR(gamma=1e-08,C=125000)
gdbt=ensemble.GradientBoostingRegressor(
max_depth=3,
min_weight_fraction_leaf=0.004,
min_impurity_split=0,
subsample=0.82,
max_features=0.45,
n_estimators=480,
learning_rate=0.064,
random_state=10
)
lgbm=lightgbm.LGBMRegressor(random_state=10,
max_depth=8,
num_leaves=11,
min_child_samples=20,
min_child_weight=0,
min_split_gain=0,
subsample=0.8,
colsample_bytree=0.24,
subsample_freq=1,
reg_alpha=0.0009,
reg_lambda=0.00088,
learning_rate=0.006,
n_estimators=2550
)
xgbt=xgboost.XGBRegressor(random_state=10,
max_depth=6,
min_child_weight=6,
min_split_gain=6,
subsample=0.77,
colsample_bytree=0.62,
reg_alpha=1e-5,
reg_lambda=1,
n_estimators=150,
learning_rate=0.1,
)
4.1 第二层模型采用原始特征
reg_stack=StackingCVRegressor(regressors=lasso,meta_regressor=lasso,random_state=10,use_features_in_secondary=True)
param_test = {
'regressors':[(lasso,ridge,ela,svr,gdbt,lgbm)],
'meta_regressor':[lasso,ridge,ela,svr,gdbt,lgbm,xgbt]
}
find_cv(reg_stack,X_train,y_train,param_test)
model=StackingCVRegressor(regressors=(lasso,ridge,ela,svr,gdbt,lgbm),
meta_regressor=ridge,random_state=10,use_features_in_secondary=True)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//stack//ridge'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.11689
4.2 第二层模型不采用原始特征
第二层不采用原始特征,则meta_regressor自然也不用采用之前网格寻优得到的模型
#单模型stacking,第二层不用特征量,但是混合模型是默认模型,如果可以的话,还可以对第二层网格进行寻优
reg_stack=StackingCVRegressor(regressors=lasso,meta_regressor=lasso,random_state=10,use_features_in_secondary=False)
param_test = {
'regressors':[(lasso,ridge,ela,svr,gdbt,lgbm)],
'meta_regressor':[linear_model.Lasso(random_state=10),
linear_model.Ridge(random_state=10),
linear_model.ElasticNet(random_state=10),
svm.SVR(),
ensemble.GradientBoostingRegressor(random_state=10),
lightgbm.LGBMRegressor(random_state=10),
xgboost.XGBRegressor(random_state=10)]
}
find_cv(reg_stack,X_train,y_train,param_test)
model=StackingCVRegressor(regressors=(lasso,ridge,ela,svr,gdbt,lgbm),
meta_regressor=ridge,random_state=10,use_features_in_secondary=True)
model_eval(model,X_train,y_train)
#模型预测
outpath='%s//reg//1220//stack//ridge'%path
model_predict(model.fit(X_train,y_train),X_test,outpath)
#实际成绩 0.11689
五、blending
lasso=linear_model.Lasso(0.00037,random_state=10)
ridge=linear_model.Ridge(9,random_state=10)
ela=linear_model.ElasticNet(0.00039,0.95,random_state=10)
svr=svm.SVR(gamma=1e-08,C=125000)
gdbt=ensemble.GradientBoostingRegressor(
max_depth=3,
min_weight_fraction_leaf=0.004,
min_impurity_split=0,
subsample=0.82,
max_features=0.45,
n_estimators=480,
learning_rate=0.064,
random_state=10
)
lgbm=lightgbm.LGBMRegressor(random_state=10,
max_depth=8,
num_leaves=11,
min_child_samples=20,
min_child_weight=0,
min_split_gain=0,
subsample=0.8,
colsample_bytree=0.24,
subsample_freq=1,
reg_alpha=0.0009,
reg_lambda=0.00088,
learning_rate=0.006,
n_estimators=2550
)
xgbt=xgboost.XGBRegressor(random_state=10,
max_depth=6,
min_child_weight=6,
min_split_gain=6,
subsample=0.77,
colsample_bytree=0.62,
reg_alpha=1e-5,
reg_lambda=1,
n_estimators=150,
learning_rate=0.1,
)
stack=StackingCVRegressor(regressors=(lasso,ridge,ela,svr,gdbt,lgbm),
meta_regressor=ridge,random_state=10)
def linear_blend_models_predict(models,X_train,y_train,X_test,coefs):
tmp=[np.array(model.fit(X_train,y_train).predict(X_test)).reshape(1,-1)[0] for model in models] #ridge输出格式问题
tmp =[c*d for c,d in zip(coefs,tmp)]
pres=np.array(tmp).swapaxes(0,1) #numpy中的reshape不能用于交换维度,一开始的种种问题,皆由此来
pres=np.sum(pres,axis=1)
return pres
def blend_model_eval(models,X_train,y_train,coefs,):
l_rmes=[]
kf=model_selection.KFold(10,random_state=10)
for train,test in kf.split(X_train):
X_train1 = X_train.iloc[train]
y_train1 = y_train.iloc[train]
X_test1 = X_train.iloc[test]
y_test1 = y_train.iloc[test]
y_pred1=linear_blend_models_predict(models,X_train1,y_train1,X_test1,coefs)
e=np.sqrt(metrics.mean_squared_error(y_pred1,y_test1)) #还要再转化为root值
l_rmes.append(e)
print(l_rmes)
print(np.mean(l_rmes))
print()
print()
return np.mean(l_rmes)
def blend_model_predict(models,X_train,y_train,X_test,coefs,outpath):
y_test_pred=linear_blend_models_predict(models,X_train,y_train,X_test,coefs)
SalePrice_pred=np.floor(np.exp(y_test_pred))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)

image.png
5.1 基础模型blend
models=[lasso,ridge,ela,svr,gdbt,lgbm,xgbt,stack]
print('1')
models=[lasso,ridge,ela]
coefs=[1,1,1]/np.sum([1,1,1])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//1//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11619
print('2')
models=[gdbt,lgbm,xgbt]
coefs=[1,1,1]/np.sum([1,1,1])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//2//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.12502
print('3')
models=[lasso,ridge,ela,stack]
coefs=[1,1,1,1]/np.sum([1,1,1,1])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//3//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11605
print('4')
models=[lasso,ridge,ela,stack,lgbm,svr]
coefs=[1,1,1,1,0.8,0.8]/np.sum([1,1,1,1,0.8,0.8])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//4//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11604
print('5')
models=[lasso,ridge,ela,stack,lgbm,svr,xgbt]
coefs=[1,1,1,1,0.8,0.8,0.6]/np.sum([1,1,1,1,0.8,0.8,0.6])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//5//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11621
print('6')
models=[lasso,ridge,ela,stack,lgbm,svr,xgbt,gdbt]
coefs=[1,1,1,1,0.8,0.8,0.6,0.5]/np.sum([1,1,1,1,0.8,0.8,0.6,0.5])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//6//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11664
print('7')
models=[lasso,ridge,ela,stack,lgbm,svr,xgbt,gdbt]
coefs=[1.5,1,1,1,0.8,0.8,0.6,0.3]/np.sum([1.5,1,1,1,0.8,0.8,0.6,0.3])
blend_model_eval(models,X_train,y_train,coefs)
outpath='%s//reg//1220//blend//7//'%path
blend_model_predict(models,X_train,y_train,X_test,coefs,outpath)
#0.11634

image.png
5.2 top kernel mix
sub1=pd.read_csv('%s//reg//1220//lasso//test_pred.csv'%path).set_index('Id')
sub2=pd.read_csv('%s//reg//1220//ridge//test_pred.csv'%path).set_index('Id')
sub3=pd.read_csv('%s//reg//1220//stack//ridge//2//test_pred.csv'%path).set_index('Id')
sub4=pd.read_csv('%s//reg//1220//blend//3//test_pred.csv'%path).set_index('Id')
sub5=pd.read_csv('%s//reg//1220//blend//4//test_pred.csv'%path).set_index('Id')
outpath='%s//reg//1220//blendtop//1//'%path
SalePrice_pred=np.floor(0.25*(sub1.SalePrice)+0.25*(sub2.SalePrice)+0.25*(sub3.SalePrice)+0.25*(sub4.SalePrice))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)
#0.11613
outpath='%s//reg//1220//blendtop//2//'%path
SalePrice_pred=np.floor(0.2*(sub1.SalePrice)+0.2*(sub2.SalePrice)+0.2*(sub3.SalePrice)+0.2*(sub4.SalePrice)+0.2*(sub5.SalePrice))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)
#0.11601
outpath='%s//reg//1220//blendtop//3//'%path
SalePrice_pred=np.floor(0.5*(sub4.SalePrice)+0.5*(sub5.SalePrice))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)
#0.11590
outpath='%s//reg//1220//blendtop//5//'%path
SalePrice_pred=np.floor(0.2*(sub1.SalePrice)+0.1*(sub2.SalePrice)+0.1*(sub3.SalePrice)+0.3*(sub4.SalePrice)+0.3*(sub5.SalePrice))
df_reg=pd.DataFrame({'Id':X_test.index,'SalePrice':SalePrice_pred}).set_index('Id')
df_reg.to_csv('%stest_pred.csv'%outpath)
#0.11595
- 历史最优成绩0.11590
六、最后调整
根据一些参考理论:让超低的房价更低,让超高的房价更高(通常来说,会将小者放大,大者缩小,但房价有其特殊性:有些偏远地区的房子比预测更低。但实际上并未取得更好地效果
#让超低的房价更低,让超高的房价更高(通常来说,会将小者放大,大者缩小,但房价有其特殊性:有些偏远地区的房子比预测更低,
outpath='%s//reg//1220//submission//3//'%path
submission=pd.read_csv('%s//reg//1220//blendtop//2//test_pred.csv'%path).set_index('Id')
q1 = submission['SalePrice'].quantile(0.0045)
q2 = submission['SalePrice'].quantile(0.998)
submission['SalePrice'] = submission['SalePrice'].apply(lambda x: x if x > q1 else x*0.84)
submission['SalePrice'] = submission['SalePrice'].apply(lambda x: x if x < q2 else x*1.05)
submission.to_csv('%stest_pred.csv'%outpath)
#0.11647
x=list(range(len(y_train)))
y1=np.exp(y_train.SalePrice).sort_values()
y2=np.exp(y_train_pred.loc[np.exp(y_train.SalePrice).sort_values().index])
sns.set()
plt.figure(figsize=(20,12))
plt.plot(x,y1)
plt.plot(x,y2)
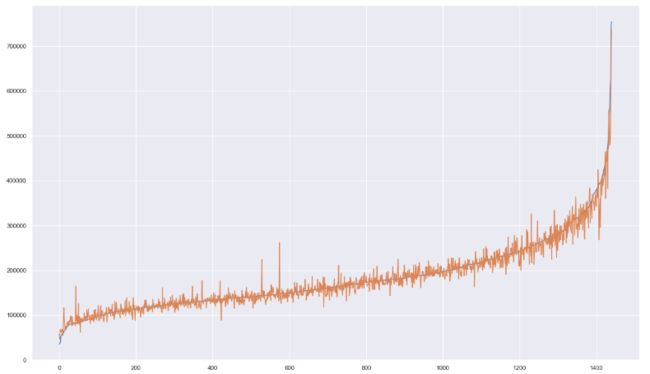
image.png
- 所以从训练集中可以看出,预测的结果和实际结果在末尾和订单的偏差,有大也有小,有高也有低。
- 所以尝试用训练集自己的结果,来确定是应该增加还是减少,增加和减少的比率又是多少:
#对down进行操作,关键列表:q_down_list,coef_down_list,rmse_down_min_list
q_down=[0]
rmse=np.sqrt(metrics.mean_squared_error(np.log(y2),np.log(y1)))
rmse_down_min_list=[rmse]
q_down_list=[0]
coef_down_list=[]
y_temp=y2.copy()
# for i in np.arange(0,0.1,0.0005):
for i in np.arange(0,0.1,0.0005):
q_down.append(y2['SalePrice'].quantile(i))
rmse_temp=[]
for j in np.arange(0.3,3,0.01):
a = y_temp['SalePrice'].apply(lambda x: x if x >= q_down[-1] or x <= q_down[-2] else x*j)
rmse_temp.append(np.sqrt(metrics.mean_squared_error(np.log(a),np.log(y1))))
temp=rmse_temp-rmse_down_min_list[-1]
if temp.min()<0:
q_down_list.append(y2['SalePrice'].quantile(i))
rmse_down_min_list.append(np.array(rmse_temp).min())
coef_down_list.append(list(np.arange(0.3,3,0.01))[np.array(rmse_temp).argmin()])
y_temp['SalePrice'] = y_temp['SalePrice'].apply(lambda x: x if x >= q_down_list[-1] or x <= q_down_list[-2] else x*coef_down_list[-1])
#对up进行操作,,关键列表:q_up_list,coef_up_list,rmse_up_min_list
q_up=[0]
rmse=np.sqrt(metrics.mean_squared_error(np.log(y2),np.log(y1)))
rmse_up_min_list=[rmse]
q_up_list=[0]
coef_up_list=[]
y_temp=y2.copy()
# for i in np.arange(0,0.1,0.0005):
for i in np.arange(0,0.1,0.0005):
q_up.append(y2['SalePrice'].quantile(1-i))
rmse_temp=[]
for j in np.arange(0.3,3,0.01):
a = y_temp['SalePrice'].apply(lambda x: x if x <= q_up[-1] or x >= q_up[-2] else x*j)
rmse_temp.append(np.sqrt(metrics.mean_squared_error(np.log(a),np.log(y1))))
temp=rmse_temp-rmse_up_min_list[-1]
if temp.min()<0:
q_up_list.append(y2['SalePrice'].quantile(1-i))
rmse_up_min_list.append(np.array(rmse_temp).min())
coef_up_list.append(list(np.arange(0.3,3,0.01))[np.array(rmse_temp).argmin()])
y_temp['SalePrice'] = y_temp['SalePrice'].apply(lambda x: x if x <= q_up_list[-1] or x >= q_up_list[-2] else x*coef_up_list[-1])
#调整边缘房价
outpath='%s//reg//1220//submission//5//'%path
submission=pd.read_csv('%s//reg//1220//blendtop//3//test_pred.csv'%path).set_index('Id')
for i in range(len(q_down_list)-1):
submission['SalePrice']=submission['SalePrice'].apply(lambda x: x if x >= q_down_list[i+1] or x <= q_down[i] else x*coef_down_list[i])
submission.to_csv('%stest_pred.csv'%outpath)
#0.12527
- 但是调整结果很不理想。。。
七、结论
大概从stack开始就没有起到很好的优化效果,最终结果0.1159和lasso的0.11658提升有限。。思考了一下,可能有以下几个方面还可以优化: