多线程(连接池)操作MySQL插入数据
针对于此篇博客的收获心得:
- 首先是可以构建连接数据库的连接池,这样可以多开启连接,同一时间连接不同的数据表进行查询,插入,为多线程进行操作数据库打基础
- 多线程根据多连接的方式,需求中要完成多语言的入库操作,我们可以启用多线程对不同语言数据进行并行操作
- 在插入过程中,一条一插入,比较浪费时间,我们可以把数据进行积累,积累到一定的条数的时候,执行一条sql命令,一次性将多条数据插入到数据库中,节省时间cur.executemany
1.主要模块
DBUtils : 允许在多线程应用和数据库之间连接的模块套件
Threading : 提供多线程功能
2.创建连接池
PooledDB 基本参数:
- mincached : 最少的空闲连接数,如果空闲连接数小于这个数,Pool自动创建新连接;
- maxcached : 最大的空闲连接数,如果空闲连接数大于这个数,Pool则关闭空闲连接;
- maxconnections : 最大的连接数;
- blocking : 当连接数达到最大的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会一直等待,直到当前连接数小于最大连接数,如果这个值是False,会报错;
def mysql_connection():
maxconnections = 15 # 最大连接数
pool = PooledDB(
pymysql,
maxconnections,
host='localhost',
user='root',
port=3306,
passwd='123456',
db='test_DB',
use_unicode=True)
return pool
# 使用方式
pool = mysql_connection()
con = pool.connection()
3.数据预处理
文件格式:txt
共准备了四份虚拟数据以便测试,分别有10万, 50万, 100万, 500万行数据
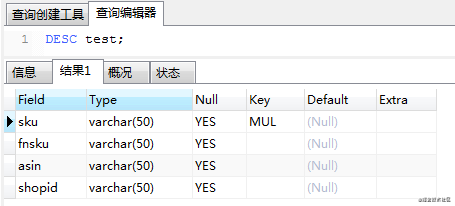
MySQL表结构如下图:
数据处理思路 :
- 每一行一条记录,每个字段间用制表符 “\t” 间隔开,字段带有双引号;
- 读取出来的数据类型是 Bytes ;
- 最终得到嵌套列表的格式,用于多线程循环每个任务每次处理10万行数据;
格式 : [ [(A,B,C,D), (A,B,C,D),(A,B,C,D),…], [(A,B,C,D), (A,B,C,D),(A,B,C,D),…], [], … ]
import re
import time
st = time.time()
with open("10w.txt", "rb") as f:
data = []
for line in f:
line = re.sub("\s", "", str(line, encoding="utf-8"))
line = tuple(line[1:-1].split("\"\""))
data.append(line)
n = 100000 # 按每10万行数据为最小单位拆分成嵌套列表
result = [data[i:i + n] for i in range(0, len(data), n)]
print("10万行数据,耗时:{}".format(round(time.time() - st, 3)))
# 10万行数据,耗时:0.374
# 50万行数据,耗时:1.848
# 100万行数据,耗时:3.725
# 500万行数据,耗时:18.493
4.线程任务
每调用一次插入函数就从连接池中取出一个链接操作,完成后关闭链接;
executemany 批量操作,减少 commit 次数,提升效率;
def mysql_insert(*args):
con = pool.connection()
cur = con.cursor()
sql = "INSERT INTO test(sku,fnsku,asin,shopid) VALUES(%s, %s, %s, %s)"
try:
cur.executemany(sql, *args)
con.commit()
except Exception as e:
con.rollback() # 事务回滚
print('SQL执行有误,原因:', e)
finally:
cur.close()
con.close()
5.启动多线程
代码思路 :
设定最大队列数,该值必须要小于连接池的最大连接数,否则创建线程任务所需要的连接无法满足,会报错 : pymysql.err.OperationalError: (1040, ‘Too many connections')循环预处理好的列表数据,添加队列任务如果达到队列最大值 或者 当前任务是最后一个,就开始多线程队执行队列里的任务,直到队列为空;
def task():
q = Queue(maxsize=10) # 设定最大队列数和线程数
# data : 预处理好的数据(嵌套列表)
while data:
content = data.pop()
t = threading.Thread(target=mysql_insert, args=(content,))
q.put(t)
if (q.full() == True) or (len(data)) == 0:
thread_list = []
while q.empty() == False:
t = q.get()
thread_list.append(t)
t.start()
for t in thread_list:
t.join()
6.完整示例
import pymysql
import threading
import re
import time
from queue import Queue
from DBUtils.PooledDB import PooledDB
class ThreadInsert(object):
"多线程并发MySQL插入数据"
def __init__(self):
start_time = time.time()
self.pool = self.mysql_connection()
self.data = self.getData()
self.mysql_delete()
self.task()
print("========= 数据插入,共耗时:{}'s =========".format(round(time.time() - start_time, 3)))
def mysql_connection(self):
maxconnections = 15 # 最大连接数
pool = PooledDB(
pymysql,
maxconnections,
host='localhost',
user='root',
port=3306,
passwd='123456',
db='test_DB',
use_unicode=True)
return pool
def getData(self):
st = time.time()
with open("10w.txt", "rb") as f:
data = []
for line in f:
line = re.sub("\s", "", str(line, encoding="utf-8"))
line = tuple(line[1:-1].split("\"\""))
data.append(line)
n = 100000 # 按每10万行数据为最小单位拆分成嵌套列表
result = [data[i:i + n] for i in range(0, len(data), n)]
print("共获取{}组数据,每组{}个元素.==>> 耗时:{}'s".format(len(result), n, round(time.time() - st, 3)))
return result
def mysql_delete(self):
st = time.time()
con = self.pool.connection()
cur = con.cursor()
sql = "TRUNCATE TABLE test"
cur.execute(sql)
con.commit()
cur.close()
con.close()
print("清空原数据.==>> 耗时:{}'s".format(round(time.time() - st, 3)))
def mysql_insert(self, *args):
con = self.pool.connection()
cur = con.cursor()
sql = "INSERT INTO test(sku, fnsku, asin, shopid) VALUES(%s, %s, %s, %s)"
try:
cur.executemany(sql, *args)
con.commit()
except Exception as e:
con.rollback() # 事务回滚
print('SQL执行有误,原因:', e)
finally:
cur.close()
con.close()
def task(self):
q = Queue(maxsize=10) # 设定最大队列数和线程数
st = time.time()
while self.data:
content = self.data.pop()
t = threading.Thread(target=self.mysql_insert, args=(content,))
q.put(t)
if (q.full() == True) or (len(self.data)) == 0:
thread_list = []
while q.empty() == False:
t = q.get()
thread_list.append(t)
t.start()
for t in thread_list:
t.join()
print("数据插入完成.==>> 耗时:{}'s".format(round(time.time() - st, 3)))
if __name__ == '__main__':
ThreadInsert()
插入数据对比
共获取1组数据,每组100000个元素.== >> 耗时:0.374's
清空原数据.== >> 耗时:0.031's
数据插入完成.== >> 耗时:2.499's
=============== 10w数据插入,共耗时:3.092's ===============
共获取5组数据,每组100000个元素.== >> 耗时:1.745's
清空原数据.== >> 耗时:0.0's
数据插入完成.== >> 耗时:16.129's
=============== 50w数据插入,共耗时:17.969's ===============
共获取10组数据,每组100000个元素.== >> 耗时:3.858's
清空原数据.== >> 耗时:0.028's
数据插入完成.== >> 耗时:41.269's
=============== 100w数据插入,共耗时:45.257's ===============
共获取50组数据,每组100000个元素.== >> 耗时:19.478's
清空原数据.== >> 耗时:0.016's
数据插入完成.== >> 耗时:317.346's
=============== 500w数据插入,共耗时:337.053's ===============
7.思考/总结
思考 :多线程+队列的方式基本能满足日常的工作需要,但是细想还是有不足;
例子中每次执行10个线程任务,在这10个任务执行完后才能重新添加队列任务,这样会造成队列空闲.如剩余1个任务未完成,当中空闲数 9,当中的资源时间都浪费了;
是否能一直保持队列饱满的状态,每完成一个任务就重新填充一个.
到此这篇关于Python3 多线程(连接池)操作MySQL插入数据的文章就介绍到这了,更多相关Python3 多线程插入MySQL数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!