Linux 开机启动过程?
1、主机加电自检,加载 BIOS 硬件信息。
2、读取 MBR 的引导文件(GRUB、LILO)。
3、引导 Linux 内核。
4、运行第一个进程 init (进程号永远为 1 )。
5、进入相应的运行级别。
6、运行终端,输入用户名和密码。
Linux 有哪些系统日志文件?
比较重要的是
/var/log/messages日志文件。
该日志文件是许多进程日志文件的汇总,从该文件可以看出任何入侵企图或成功的入侵。另外,如果胖友的系统里有 ELK 日志集中收集,它也会被收集进去。
journalctl 用来查询 systemd-journald 服务收集到的日志。systemd-journald 服务是 systemd init 系统提供的收集系统日志的服务。journalctl通常用来查询systemd管理的Unit的日志信息。
内容一:journalctl 日志工具的常用用法
journalctl | grep <服务器名关键词>
journalctl -u <服务名> -p <优先级>
journalctl -n <消息数>
journalctl --since="
内容二:journalctl 日志工具的使用案例
2.1 案例一:列出最近 5 条重要程度在 ERR 及以上的日志信息
# journalctl -p err -n 5
2.2 案例二:列出所有与服务 httpd 相关的日志信息
# journalctl -u httpd
2.3 案例三:列出前 5 个小时内的日志信息
# journalctl --since "2019-05-01 14:00" --until "2019-05-01 19:00"
2.4 案例四:在紧急模式下查看系统日志
# journalctl -xb
在 if-then 中使用测试命令( -gt 等)来比较两个数字。例如






Find命令

grep 的规则表达式:


ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
linux上进程有5种状态:
1. 运行(正在运行或在运行队列中等待)
2. 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
3. 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
4. 僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
5. 停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
top 命令
显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等
前五行是当前系统情况整体的统计信息区。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us— 用户空间占用CPU的百分比。3.4%sy— 内核空间占用CPU的百分比。0.0%ni— 改变过优先级的进程占用CPU的百分比90.4%id— 空闲CPU百分比0.0%wa—IO等待占用CPU的百分比0.0%hi— 硬中断(HardwareIRQ)占用CPU的百分比0.2%si— 软中断(SoftwareInterrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016ktotal — 物理内存总量(32GB)14411180kused — 使用中的内存总量(14GB)18537836kfree — 空闲内存总量(18GB)169884kbuffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556ktotal — 交换区总量(32GB)0kused — 使用的交换区总量(0K)32764556kfree — 空闲交换区总量(32GB)3612636kcached — 缓冲的交换区总量(3.6GB)
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID— 进程idUSER— 进程所有者PR— 进程优先级NI— nice值。负值表示高优先级,正值表示低优先级VIRT— 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES— 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR— 共享内存大小,单位kbS— 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU— 上次更新到现在的CPU时间占用百分比%MEM— 进程使用的物理内存百分比TIME+— 进程使用的CPU时间总计,单位1/100秒COMMAND— 进程名称(命令名/命令行)
tar 命令
用来压缩和解压文件。tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成。
弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件



1.root@lap-141:~# sar -u 1 3
15时12分21秒 CPU %user %nice %system %iowait %steal %idle
15时12分22秒 all 8.03 0.00 4.92 0.00 0.00 87.05
'cat /etc/issue' 'uname -a'
cat /proc/version cat /proc/stat
# 由md设备驱动程序控制的RAID设备信息
cat /proc/mdstat
# OS版本信息
'cat /etc/issue''uname -a' cat /proc/version cat /proc/stat
# 由md设备驱动程序控制的RAID设备信息 cat /proc/mdstat
CPU负载‘load average: 0.02, 0.04, 0.05’,具体指的什么意思?
以单核CPU说明:
0.02, 0.04, 0.05 是1分钟、5分钟、15分钟内系统的平均负荷
假设:CPU每分钟最多处理100个进程
当负荷 0.2,则CPU在这1分钟里只处理20个进程
当负荷 1.0,则CPU在这1分钟里正好处理100个进程
当负荷 1.7,则CPU正在处理的100个进程以外,还有70个进程正排队等着CPU处理
很显然:单核的话,1.0是一个关键值,当这个值达到0.7,就应当引起注意。问题出在哪里,防止情况恶化
当负荷达到5.0,就表明你的系统有很严重的问题
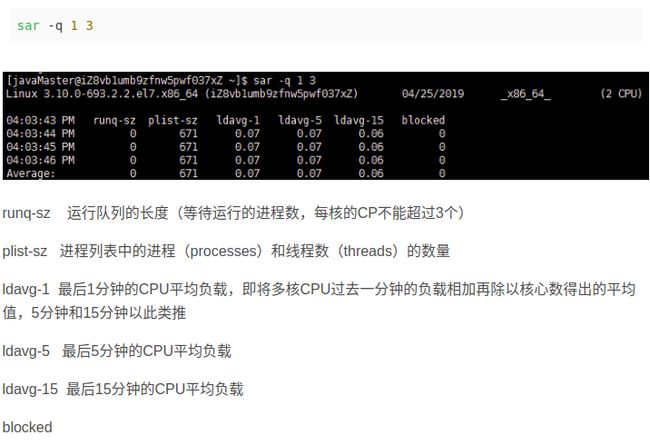

sar -d

DEV 磁盘设备的名称,如果不加-p,会显示dev253-0类似的设备名称,因此加上-p显示的名称更直接
tps 每秒I/O的传输总数
rd_sec/s 每秒读取的扇区的总数
wr_sec/s 每秒写入的扇区的总数
avgrq-sz 平均每次次磁盘I/O操作的数据大小(扇区)
avgqu-sz 磁盘请求队列的平均长度
await 从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒等于1000毫秒),等于寻道时间+队列时间+服务时间
svctm I/O的服务处理时间,即不包括请求队列中的时间
%util I/O请求占用的CPU百分比,值越高,说明I/O越慢
默认监控: sar 1 1 // CPU和IOWAIT统计状态
(1) sar -b 1 1 // IO传送速率
(2) sar -B 1 1 // 页交换速率
(3) sar -c 1 1 // 进程创建的速率
(4) sar -d 1 1 // 块设备的活跃信息
(5) sar -n DEV 1 1 // 网路设备的状态信息
(6) sar -n SOCK 1 1 // SOCK的使用情况
(7) sar -n ALL 1 1 // 所有的网络状态信息
(8) sar -P ALL 1 1 // 每颗CPU的使用状态信息和IOWAIT统计状态
(9) sar -q 1 1 // 队列的长度(等待运行的进程数)和负载的状态
(10) sar -r 1 1 // 内存和swap空间使用情况
(11) sar -R 1 1 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
(12) sar -u 1 1 // CPU的使用情况和IOWAIT信息(同默认监控)
(13) sar -v 1 1 // inode, file and other kernel tablesd的状态信息
(14) sar -w 1 1 // 每秒上下文交换的数目
(15) sar -W 1 1 // SWAP交换的统计信息(监控状态同iostat 的si so)
(16) sar -x 2906 1 1 // 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上
(17) sar -y 1 1 // TTY设备的活动状态
strace概述
在操作系统中,进程分为用户态进程和内核态进程,应用程序运行在用户态,内核态负责对资源包括网络,磁盘,内存等管理,用户态进程要访问这些资源时,需要通过系统调用陷入内核态,由内核来统一管理和分配

strace -p pid
跟踪正在执行的进程,正在执行的系统调用,先来熟悉几个查找进程的命令,pidof 查看当前进行运行程序的进程pid,pstree,跟踪当前进程pid查看,进程树关系。

1.2.2 strace -i
现在在原来-p的基础上,加上-i参数,可以查看系统调用的入口指针。
通过(1.2.1)步骤,重新查看server的pid,并用strace -p pid -i跟踪系统调用并查看系统调用入口指针。

strace -t
在原来-p 的基础上加上-t,跟踪系统调用,同时查看系统调用的时间戳。结合步(1.2.1)使用strace -p pid -t 跟踪系统调用,同时查看。

其中最左侧的是系统调用的时间戳。
其中strace -t 是精确度是时分秒,-tt是精确为s。
用法:strace -p pid -tt
Shell 命令十问十答
1.在 shell 脚本成功执行前,如何中断脚本执行?
解答:我们需要使用exit命令来实现以上描述的情境。exit命令被强制输出非0值时,脚本会报错并退出。在 Unix 环境下的 shell 脚本中,0值表示成功执行。因此,在脚本终止前执行一个不带引号的exit -1命令将使脚本中止。
#!/bin/bashecho "Hello"exit-1echo "bye"
保存文件并执行。
# sh linuxmi.shHellolinuxmi.sh:行3: exit-1: 未找到命令bye
2.如何使用 Linux 命令来移除文件头?
解答:当我们需要删除文件中的指定行时,sed命令可以用来解决该问题。
这个是用来删除文件头(文件的首行)的正确命令。
# sed '1 d' file.txt
好吧,其实sed命令内建的-i开关就可以干这活,就不需要重定向符了吧。
# sed -i '1 d' file.txt
3. 你怎么检查一个文本文件中某一行的长度?
解答:sed命令也可以用来查找文本文件中的某一行或者检查其长度。
sed -n ‘n p’ file.txt可以解决,这里n表示行号,p打印出匹配内容(到标准输出),该命令通常与-n命令行选项连用。那么,怎样来获取长度计数呢?很明显,我们需要通过管道输出给wc命令来计算。
# sed –n 'n p' file.txt | wc –c
要得到文本文件‘linuxmi.txt’的第五行的长度,运行如下命令:
# sed -n '5 p' linuxmi.txt | wc -c
4.假如你是一个员工组的团队领导,为xyz公司工作。公司要求你创建一个dir_xyz目录,让该组成员都能在该目录下创建或访问文件,但是除了文件创建者之外的其他人不能删除文件,你会怎么做?
# mkdir dir_xyz# chmod g+wx dir_xyz# chmod +t dir_xyz
5.你能告诉我一个Linux进程经历的各个阶段吗?
解答:一个 Linux 进程在它的一生中,通常经历了四个主要阶段。
这里是Linux进程要经历的四个阶段。
等待:Linux进程等待资源。
运行:Linux进程当前正在执行中。
停止:Linux进程在成功执行后或收到杀死进程信号后停止。
僵尸:如果该进程已经结束,但仍然留在进程表中,被称为‘僵尸’。
6.Linux中cut命令怎么用?
解答:cut是一个很有用的 Linux 命令,当我们要截取文件的指定部分并打印到标准输出,当文本区域以及文件本身很大时,这个命令很有用。
例如,截取txt_linuxmi文件的前10列。
# cut -c1-10 txt_linuxmi
要截取该文件中的第二,第五和第七列。
# cut -d;-f2 -f5 -f7 txt_linuxmi
7.cmp和diff命令的区别是什么?
解答:cmp和diff命令用来获取相同的东西,但各有侧重。
diff命令输出为了使两个文件一样而应该做的修改。而‘cmp’命令则将两个文件逐字节对比,并报告第一个不匹配的项。
8. 可以用echo命令来替换ls命令吗?
解答:可以的。‘ls’命令可以用‘echo’命令来替代。‘ls’命令列出目录内容,从替换上述命令的角度讲,我们可以使用‘echo *’,两个命令的输出完全一样。
9. 你可能听过 inode 吧。你能简要描述一下 inode 吗?
解答:inode 是一个数据结构,在 Linux 上用于文件标识。每个文件在 Unix 系统上有一个独立的 inode 和一个唯一的 inode 号。
ss命令
基本使用
我们按照使用场景来看下ss的用法。
查看系统正在监听的tcp连接
ss -atr ss -atn #仅ip
查看系统中所有连接
ss -alt
查看监听444端口的进程 pid
ss -ltp | grep 444
查看进程555占用了哪些端口
ss -ltp | grep 555
和某个 IP 的所有连接
ss dst 10.66.224.130
ss dst 10.66.224.130:http
ss dst 10.66.224.130:smtp
ss dst 10.66.224.130:443
查看流量
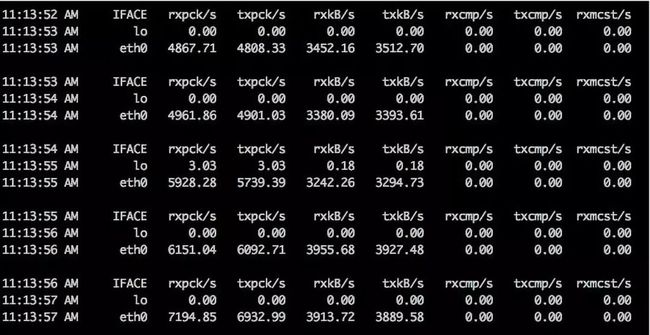
有很多工具可以看网络流量,但我最喜欢sar。sar是linux上功能最全的监控软件。如图,使用sar -n DEV 1即可每秒刷新一次网络流量。
查看占流量最大的 IP
有时候我们发现网络带宽占用非常高,但我们无法判断到底流量来自哪里。这时候,iftop就可以帮上忙了。如图,可以很容易的找出流量来自哪台主机。

当你不确定内网的流量来源,比如有人在压测,api调用不合理等,都可以通过这种方法找到他。
tcpdump
当我们需要判断是否有流量,或者调试一个难缠的 netty 应用问题,则可以通过抓包的方式去进行进一步的判断。在 Linux 上,可以通过 tcpdump 命令抓取数据,然后使用Wireshark 进行分析。
tcpdump -i eth0 -nn -s0 -v port 80
-i 指定网卡进行抓包
-n 和ss一样,表示不解析域名
-nn 两个n表示端口也是数字,否则解析成服务名
-s 设置抓包长度,0表示不限制
-v 抓包时显示详细输出,-vv、-vvv依次更加详细
1)加入-A选项将打印 ascii ,-X打印 hex 码。
tcpdump -A -s0 port 80
2)抓取特定 IP 的相关包
tcpdump -i eth0 host 10.10.1.1tcpdump -i eth0 dst 10.10.1.20
TIME_WAIT
TIME_WAIT 是主动关闭连接的一方保持的状态,像 nginx、爬虫服务器,经常发生大量处于time_wait状态的连接。TCP 一般在主动关闭连接后,会等待 2MS,然后彻底关闭连接。由于 HTTP 使用了 TCP 协议,所以在这些频繁开关连接的服务器上,就积压了非常多的 TIME_WAIT 状态连接。
某些系统通过 dmesg 可以看到以下信息。
__ratelimit: 2170 callbacks suppressedTCP: time wait bucket table overflowTCP: time wait bucket table overflowTCP: time wait bucket table overflowTCP: time wait bucket table overflow
通过ss -s命令查看,可以看到timewait已经有2w个了。
ss -sTotal: 174 (kernel 199)TCP: 20047 (estab 32, closed 20000, orphaned 4, synrecv 0, timewait 20000/0), ports 10785
sysctl 命令可以设置这些参数,如果想要重启生效的话,加入/etc/sysctl.conf文件中。
# 修改阈值net.ipv4.tcp_max_tw_buckets = 50000# 表示开启TCP连接中TIME-WAIT sockets的快速回收net.ipv4.tcp_tw_reuse = 1#启用timewait 快速回收。这个一定要开启,默认是关闭的。net.ipv4.tcp_tw_recycle= 1 # 修改系統默认的TIMEOUT时间,默认是60snet.ipv4.tcp_fin_timeout = 10
测试参数的话,可以使用 sysctl -w net.ipv4.tcp_tw_reuse = 1 这样的命令。如果是写入进文件的,则使用sysctl -p生效。
CLOSE_WAIT
CLOSE_WAIT一般是由于对端主动关闭,而我方没有正确处理的原因引起的。说白了,就是程序写的有问题,属于危害比较大的一种。