Spark 大数据分析-介绍
目录
- Spark的技术生态
-
- Spark core
- Spark SQL
- Spark streaming
- MLlib
- GraphX
- Spark的基本原理
-
- Application
- Executor
- Worker
- Task
- Job
- Stage
- DAGScheduler
- TaskScheduler
- RDD
- 一些疑问
-
- 如何定义一个Job
- Stage和task的划分
- 一些结论
Spark是一个以复杂计算为核心的大数据分析框架,是MapReduce的“后继者”,具备高效性、通用性等特点。
Spark最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark提供的技术更加全面,速度更快(比MapReduce快一百倍)。
Spark的技术生态
Spark的技术生态包含了各种丰富的组件,而不同的组件提供了不同功能,以适应不同场景。
Spark core
spark core包含Spark的基本功能,定义了RDD的API以及以此为基础的其他动作。Spark的其他库都构建在RDD和Spark Core之上。
Spark SQL
提供通过HiveQL与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL的查询会被转换为Spark操作。
Spark streaming
对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。严格来说Spark streaming并不是实时的,而是准实时(跟Storm相比)。
MLlib
一个基于RDD的机器学习算法库,包含了可扩展的机器学习算法。
GraphX
控制图、并行图操作和计算的一组算法和工具的集合。
Spark的基本原理

Application
Application是在使用spark-submit 提交的打包程序,也就是需要写的代码。
完整的Application一般包含以下步骤:
(1)获取数据
(2)计算逻辑
(3)输出结果(可以是存入HDFS,或者是其他存储介质)
Executor
Executor是一个Application运行在Worker节点上的一种进程,一个worker可以有多个Executor,一个Executor进程有且仅有一个executor对象。executor对象负责将Task包装成taskRunner,并从线程池抽取出一个空闲线程运行Task。每个进程能并行运行Task的个数就取决于分配给它的CPU core的数量。
Worker
Spark集群中可以用来运行Application的节点,在standalone模式下指的是slaves文件配置的worker节点,在spark on yarn模式下是NodeManager节点。
Task
在Excutor进程中执行任务的单元,执行相同代码段的多个Task组成一个Stage。
Job
由一个Action算子触发的一个调度。
Stage
Spark根据提交的作业代码划分出多个Stages,每个Stage有多个Tasks,这些Tasks负责并行处理他们所属的stage里面的代码。
DAGScheduler
根据Stage划分原则构建的DAG(有向无环图,理解为执行流程还行),并将Stage提交给Taskscheduler。
TaskScheduler
TaskScheduler将TaskSet提交给Worker运行。
RDD
弹性分布式数据集。
Resilient Distributed Dataset,是Spark中最基本的数据抽象,它代表一个不可变、可分区、元素可并行计算的集合。简单点说,从数据文件中获取到的数据会被放到RDD中。
它具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。它允许在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
一些疑问
如何定义一个Job
/*
* PageRank 即网页排名,又称网页级别,Google左侧排名,佩奇排名
* */
def pageRand():Unit={
val sc = getSparkContext("com.scala.RecommendSystem.PageRank")
val graph = GraphLoader.edgeListFile(sc, "E:\\Scala_TestData\\PageRank\\followers.txt")
val ranks = graph.pageRank(0.0001).vertices
val users = sc.textFile("E:\\Scala_TestData\\PageRank\\users.txt").filter(line=>line.length()>0)
.map(line=>{
val fields = line.split(",")
(fields(0).toLong,fields(1))
})
val ranksByUsers = users.join(ranks).map{
case(id,(username,rank))=>(username,rank)
}
ranksByUsers.foreach(println)
}
上面的foreach是一个action算子,这个算子会触发一个过程——从数据源(Data blocks)加载生成RDD,后将RDD经过一系列转换(包括基本类型转换和洗牌)最终得到计算结果(result),再将结果汇总到driver端。这个过程就是Job。Application每提交一个执行操作Spark就对应生成一个Job
Stage和task的划分
从后往前推算,遇到shuffleDependency就断开,遇到NarrowDependency就将其加入该stage。每个stage里面task的数目由该stage最后一个RDD中的partition个数决定。
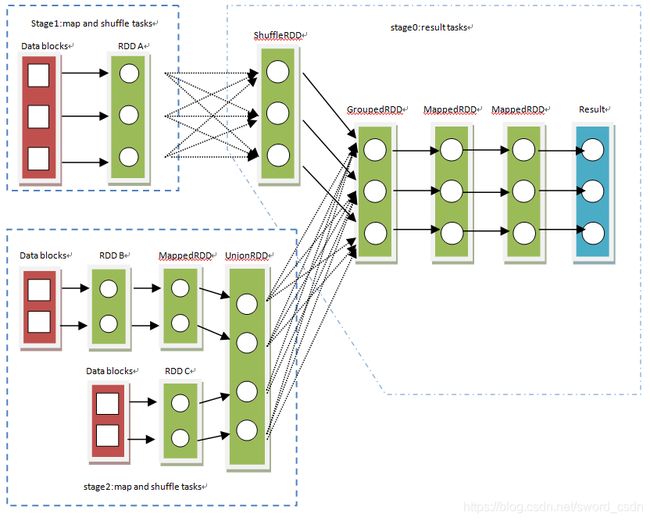
reduceByKey是个transformation算子,但是它有shuffle,所以程序中遇到reduceByKey时,也会划分stage。
一些结论
(1)stage是根据shuffle算子来划分的。每一次shuffle很有可能会有一次节点间数据传输的过程。会造成性能上的影响。
(2)同一个stage中的task执行一样的代码块。
(3)Executor的内存主要会分成三块:第一块是让task执行代码时使用,默认占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
(4)task的执行速度跟每个Executor进程的CPU core数量有直接关系。一个CPU core同一时间只能执行一个线程。而每个Executor进程分配到的tasks,都是以“每个task对应一个线程”的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么就可以快速高效地执行task