绪论
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。所以用python进行网络爬虫是简单且快捷的。
需求分析
本次的练习是为了爬取王者荣耀官网中高清壁纸。
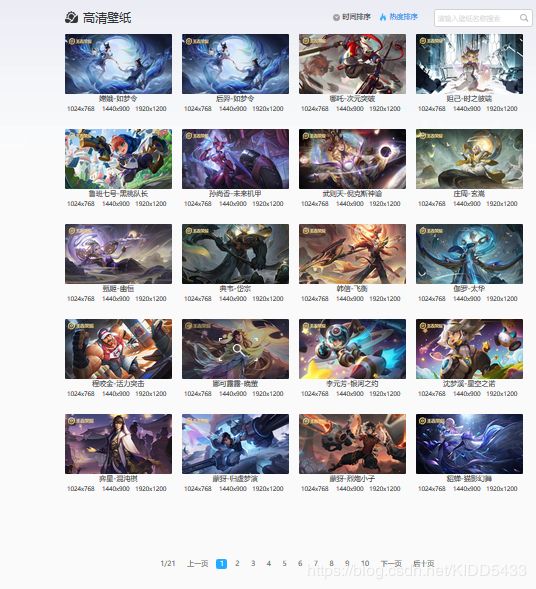
如截图所示,每页的高清图片有20张,一共有21页。目的就是将这21页工400多张高清图片利用python批量下载。
爬虫流程:
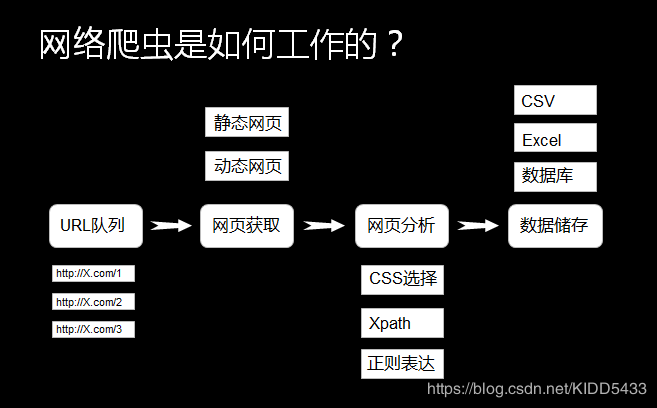
网页分析
在抓取图片前是对这些图片进行分析,目的就是为了获取图片的URL。
在王者荣耀官网,按下F12调出元素属性,我的浏览器是FIREfox。如下图所示,可以看到一张壁纸有不同的尺寸.
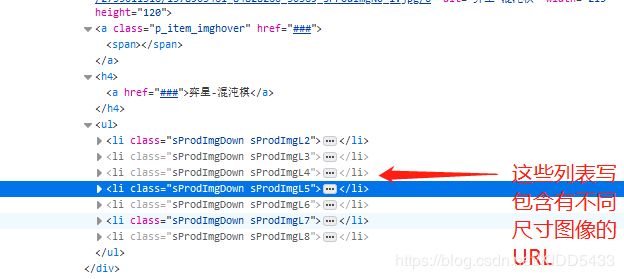
这些url都大同小异:
[图片上传失败...(image-e8c67d-1582181461614)]
列出两种尺度的url如下:
http://shp.qpic.cn/ishow/2735011316/1578903461_84828260_30369_sProdImgNo_3.jpg/0
http://shp.qpic.cn/ishow/2735011316/1578903461_84828260_30369_sProdImgNo_2.jpg/0
由此乐意看出其不同尺度图像的区别只有ProdImgNo_2和ProdImgNo_3的区别。王者荣耀官网提供了7种不同的尺度。
[图片上传失败...(image-41b6b9-1582181461614)]。
根据以往的爬取经验,网站的图片url不会放在源代码中,而是放在某个数据文件中,或者在某个文件中包含了构成url文件的信息,需要自己将这些文件组合起来构成完整的图片url。
所以,下一步就是查询图片的信息所包含的文件。在firefox中有一个网络选项,点击就可以查看图片相关信息。
[图片上传失败...(image-c0b060-1582181461614)]
在消息头中包含着图像请求网址,例如:
http://shp.qpic.cn/ishow/2735011316/1578903461_84828260_30369_sProdImgNo_2.jpg/0
[图片上传失败...(image-f4c3b5-1582181461614)]
每一张图片最特殊的就是最后如图蓝色线划出来的,每一张图都不一样。也就是
/2735011316/1578903461_84828260_30369_sProdImgNo_2.jpg/0
这样的图片名回报存在某个文件中,所以接下来就是找到这个文件。复制这个文件的某个数字如1578903461在调试器中搜索。
[图片上传失败...(image-b60842-1582181461614)]
包含图像url的文件,但是不方便查看,所以换种方式查兰
[图片上传失败...(image-b0b639-1582181461614)]
在搜索结果页面中点左键获取源地址网址如下:
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17102680533382681486_1582174063967&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1582174064247
这个网址的结果是:
[图片上传失败...(image-8d815f-1582181461614)]
这个网页中等于一页的20张图片,并且包含了7种不同的尺寸。但是这不能直接用,因为官方对其图片网址进行了编码,所有的特殊符号都变成了十六进制。所以对这些图片进行解码才能图片链接解码的python代码如下:
import urllib.parse
url='http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735092412%2F1569299550%5F84828260%5F31469%5FsProdImgNo%5F4%2Ejpg%2F200'
image_none=urllib.parse.unquote(url,'utf-8')#解码
#结果:
>>>'http://shp.qpic.cn/ishow/2735092412/1569299550_84828260_31469_sProdImgNo_4.jpg/200'
仔细观察这一个图像的URL,在浏览器中打开得到的图像很小,别提什么高清了。
[图片上传失败...(image-c384c0-1582181461614)]
经过对网页源代码的分析:
在网页源代码可以看到这样一段代码:
[图片上传失败...(image-1ba483-1582181461615)]
所以需要使用0代替掉图像url尾部的200结果就是正常的高清图片了。
'http://shp.qpic.cn/ishow/2735092412/1569299550_84828260_31469_sProdImgNo_4.jpg/200'
替换为
'http://shp.qpic.cn/ishow/2735092412/1569299550_84828260_31469_sProdImgNo_4.jpg/0'
就此,通过上述步骤可获取了一页中20张壁纸的url。可以写一个简单的代码去爬取这一页的壁纸如下:
#导入库
import requests
from bs4 import BeautifulSoup as BS
import re
import urllib.request
import urllib.parse
import os
import json
import csv
from datetime import datetime
import time
#下载链接
r=requests.get('https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=1&iOrder=0&iSortNumClose=1&jsoncallback=&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=').text
#网页解析出一张图片的url,这里我只下载尺寸为1920×120的图片。
image_ur=set()
image_list=re.compile('(http(%\w*)*)').findall(r)
for i in image_list:
image_none=urllib.parse.unquote(i[0],'utf-8')
image_none=re.sub('sProdImgNo_[0-9]','sProdImgNo_7',image_none)
image_ur.add(re.sub('200','0',image_none))
#保存图像
num=100
for i in image_ur:
with open('F://wz/'+str(num)+'.jpg','wb') as f:
r=requests.get(i)
if r.status_code==200:
f.write(r.content)
print('{}finish'.format(num))
num+=1
[图片上传失败...(image-380b9d-1582181461615)]
所以只要有一个图像源网址就能下载一页的壁纸
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17102680533382681486_1582174063967&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1582174064247
但是20页每次都得重新去获取,明显称不上自动,更别说20页还是有点麻烦。接下来的工作就是考虑如何生成源网址。
经过通过对多页源网址比较,并分析相关的js代码,找出的规律如下:
page_3=https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=3&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17109236554684578916_1581341758935&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1581342827129
page_8=https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=8&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17109236554684578916_1581341758931&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1581341852604
page_9=https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=9&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17109236554684578916_1581341758932&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1581341854233
有变化的参数有三个page、jsoncallback以及最后的。经过分析,page是对应每一页的序号。下划线是一个时间戳,jsoncallbac是一个随机产生数字。经过测试删掉_和jsoncallback参数依旧能正常访问源网址。所以只需亚搜修改page的值就能获得对应的页源网址如下:
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=1&iOrder=0&iSortNumClose=1&jsoncallback=&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_='
jsoncallback和_的值留空白就行。由此就能构建了完整的图像url。
使用正则表达式除了源网址获得url
获得了url后需要下载网页并对其进行分析。因为一个源网址中包含7种尺寸的图像,我只需要最大的即1920×1200.
再次之前需要安装一些python库:
requests库用于请求网址,并下载图片,相关库的用法请参考这里
上述的一页图片下载代码中:
#r是源网址使用requests模块下载
r=requests.get('https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=1&iOrder=0&iSortNumClose=1&jsoncallback=&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=').text
#提取出每一张图片的url
image_ur=set()#用于去重
image_list=re.compile('(http(%\w*)*)').findall(r)#用正则表达式提取出每一张图片。
for i in image_list:#遍历每一条url将所有的尺寸替换为sProdImgNo_7即1920×1200并去重
image_none=urllib.parse.unquote(i[0],'utf-8')
image_none=re.sub('sProdImgNo_[0-9]','sProdImgNo_7',image_none)
image_ur.add(re.sub('200','0',image_none))#将200用0替代。
如果不明白正则表达式的用法见此
保存图像
获得图像url后要下载并保存。因为requests.get().content是获得二进制模式,所以可以下载后直接保存为jpg格式,如果有好的方式也请多指教。
#保存图像
num=100
for i in image_ur:
with open('F://wz/'+str(num)+'.jpg','wb') as f:
r=requests.get(i)
if r.status_code==200:
f.write(r.content)
print('{}finish'.format(num))
num+=1
print('完成{}的下载'.format(i))
以上就完成了所有的王者荣耀高清壁纸的下载。完整的批量下载代码见此
代码