C#发现之旅第三讲 使用C#开发基于XSLT的代码生成器
袁永福 2008-5-15
系列课程说明
 为了让大家更深入的了解和使用C#,我们开始这一系列的主题为“C#发现之旅”的技术讲座。考虑到各位大多是进行WEB数据库开发的,而所谓发现就是发现我们所不熟悉的领域,因此本系列讲座内容将是C#在WEB数据库开发以外的应用。目前规划的主要内容是图形开发和XML开发,并计划编排了多个课程。在未来的C#发现之旅中,我们按照由浅入深,循序渐进的步骤,一起探索和发现C#的其他未知的领域,更深入的理解和掌握使用C#进行软件开发,拓宽我们的视野,增强我们的软件开发综合能力。
为了让大家更深入的了解和使用C#,我们开始这一系列的主题为“C#发现之旅”的技术讲座。考虑到各位大多是进行WEB数据库开发的,而所谓发现就是发现我们所不熟悉的领域,因此本系列讲座内容将是C#在WEB数据库开发以外的应用。目前规划的主要内容是图形开发和XML开发,并计划编排了多个课程。在未来的C#发现之旅中,我们按照由浅入深,循序渐进的步骤,一起探索和发现C#的其他未知的领域,更深入的理解和掌握使用C#进行软件开发,拓宽我们的视野,增强我们的软件开发综合能力。
本系列课程配套的演示代码下载地址为 http://files.cnblogs.com/xdesigner/cs_discovery.zip 。
本课程说明 经过以前的学习,我们大体上了解了XML/XSLT开发,在本课程中,我们将在ASP.NET中使用C#开发一个基于XSLT技术的代码生成器。
本系列课程已发布的文章有
C#发现之旅第一讲 C#-XML开发
C#发现之旅第二讲 C#-XSLT开发
C#发现之旅第三讲 使用C#开发基于XSLT的代码生成器
C#发现之旅第四讲 Windows图形开发入门
C#发现之旅第五讲 图形开发基础篇
C#发现之旅第六讲 C#图形开发中级篇
C#发现之旅第七讲 C#图形开发高级篇
C#发现之旅第八讲 ASP.NET图形开发带超链接的饼图
C#发现之旅第九讲 ASP.NET验证码技术
C#发现之旅第十讲 文档对象模型
首先说说什么是代码生成器。个人认为是一种工具软件,它能根据某种已经固定的信息,使用程序来机械的大批量的生成有结构上有比较简单规律的源代码,从而减少软件开发人员的编码量。
从广义上讲,我们写的WEB数据库程序都是代码生成器,它们能根据保存在数据库中的固定数据自动生成大量的HTML代码。在这里我们限制代码生成器为通用代码生成器。代码生成器主要功能是帮助程序员自动生成大量的底层代码,这种代码可以是C#或Java的程序源代码,也可以是SQL语句,或者HTML代码等等,是一种软件开发过程中的辅助工具软件。
我们最常用的代码生成器是根据数据库结构自动生成能操作数据库记录的程序源代码,SQL语句或其他文档等等。对于这种代码生成器,其数据信息来源就是数据库的表结构和字段属性等信息,我们可以分析遍历数据库的系统表来货的表结构和字段信息,也可以从PowerDesigner等数据结构设计器保存的文档中获得。
针对某个特定的项目,我们可以根据数据库结构临时写一个代码生成器,使用字符串拼凑来生成源代码,但这种代码生成器不通用,难于用于其他项目。因此我们更多的是使用通用的代码生成器。
很多通用代码生成器的原理如图
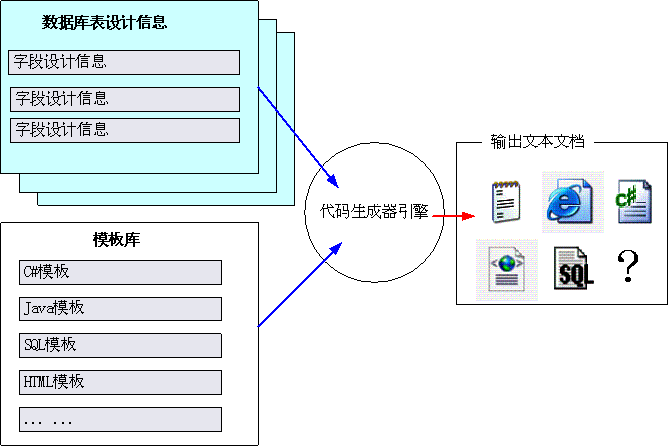
在这个图中,我们看到代码生成器包含了模板库和代码生成器处理引擎,模板库包含了若干个模板,一个模板一般是纯文本,其中可能包含了脚本代码,或者类似ASP的结构。生成器引擎加载一个或者多个数据库表结构设计信息,然后调用用户指定的模板,通过某种操作来自动生成另外一个文本文件,这个文本文件内容可以是纯文本,HTML代码,C#代码或者其他。
考察这个结构,可以发现这个原理和XSLT原理很相似。我们可以将数据库表结构设计信息保存在一个XML文档中,代码生成器模板就使用XSLT格式,代码生成器引擎就使用XSLT转换引擎,这样我们也可以达到代码生成器的功能,从而搞出基于XSLT的代码生成器。
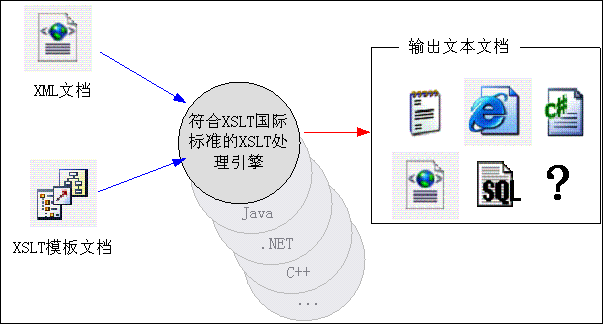
软件设计
根据基于XSLT来实现代码生成功能的思路,我们开始设计这个代码生成器。
数据来源这个代码生成器的数据来源就是数据库表结构设计信息。对于不同的数据库类型得使用不同的方法来获得其表结构设计信息。在此我们针对于Access2000,MSSQLServer和Oracle这三种数据库研究获得其表设计信息的方法,对于其他类型的数据库则以后再说。
对于MSSQLServer,数据库中有SysObjects和SysColumns这两个系统表,我们可以查询系统表来获得所有的表名称和字段名称以及格式,还有一个sp_helpindex 的系统预定义存储过程来获得指定表的字段索引信息。
对于Oracle,数据库有一个名为Col的系统预定义视图,我们可以查询这个视图获得所有的表名和字段定义信息。还有一个 user_ind_columns的系统预定义视图,我们可以关键字段信息。
对于Access2000数据库,没有这些系统表,因此我们使用。NET框架中的OleDB的数据连接对象的GetOleDbSchemaTable函数来获得数据库表和字段定义信息。
我们的代码生成器还应当从一下数据结构设计器生成的文档导入表结构设计信息,这里我们决定从PowerDesigner生成的PDM文件中导入表设计信息,因为PDM文件是XML格式的,处理方便。
代码生成模板这里的代码生成模板就采用XSLT格式。为了方便软件开发和维护,我们将模板保存在程序目录下的XSLT扩展名的文件中,并约定文件名使用下划线开头。
程序在这里使用ASP.NET中实现该代码生成器,使用.NET框架自带的XSLT转换对象来作为代码生成器处理引擎,并使用HTML格式来展示生成的源代码。
程序说明根据上述的软件设计,我们开发出了这个代码生成器,现对其源代码进行详细说明。
xslcreatecode.aspx 本代码生成器很简单,只有一个ASPX页面,打开该页面的设计界面,
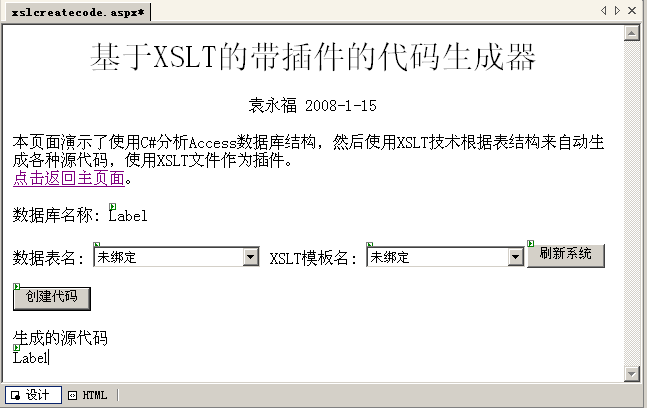
可以看到上面放置了一些简单的控件。其中比较重要的有
数据表名下拉列表,该列表列出了数据库中所有数据表的名称。
XSLT模板名称下拉列表,该列表列出了所有系统可用的XSLT模板文件的名称。
刷新系统按钮,用于刷新系统数据设置,重新填充数据表名列表和模板名列表。
创建代码,根据当前选择的数据表名和XSLT模板名称创建代码。
生成的源代码文本标签,使用HTML格式来显示生成的源代码。
打开这个页面的C#代码,可以看到其代码也不复杂。这个页面的Page_Load函数调用了刷新系统的方法RefreshSystem。
| /// <summary> /// 刷新系统 /// </summary> private void RefreshSystem( ) { DataBaseInfo info = this.GetInfo(); this.lblResult.Text = info.Name ; if( cboTable.Items.Count == 0 ) { cboTable.Items.Add( new ListItem("所有表" , "所有表" )); foreach( TableInfo table in info.Tables ) { cboTable.Items.Add( new ListItem( table.Name , table.Name )); } } if( cboXSLT.Items.Count == 0 ) { cboXSLT.Items.Add("XML代码"); string[] names = System.IO.Directory.GetFiles( this.MapPath(".") , "_*.xslt"); if( names != null && names.Length > 0 ) { foreach( string name in names ) { string name2 = System.IO.Path.GetFileNameWithoutExtension( name ); this.cboXSLT.Items.Add( new ListItem( name2 , name2 )); } } } }//private void RefreshSystem( ) /// <summary> /// 获得数据库结构信息对象 /// </summary> /// <returns>数据库结构信息对象</returns> private DataBaseInfo GetInfo( ) { DataBaseInfo info = this.Session["info"] as DataBaseInfo ; if( info == null ) { info = new DataBaseInfo(); info.LoadFromAccess2000( this.MapPath("demomdb.mdb")); this.Session["info"] = info ; } return info ; } |
在RefreshSystem方法中,首先获得数据库结构信息对象,遍历其中的表结构信息对象,向数据表名下列列表填充项目。
遍历网站目录下的所有以下划线开头的XSLT文件,将其文件名填充到XSLT模板下拉列表中。
这里使用了另外一个函数GetInfo,该函数就是获得系统使用的数据库结构信息对象,它是缓存在session中的对象,它使用了程序目录下的演示数据库作为数据结构信息来源。
页面代码中还有强制刷新系统按钮事件处理。
| /// <summary> /// 刷新系统按纽事件 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void cmdRefresh_Click(object sender, System.EventArgs e) { this.Session["info"] = null; this.cboTable.Items.Clear(); this.cboXSLT.Items.Clear(); RefreshSystem( ); }//private void cmdRefresh_Click(object sender, System.EventArgs e) |
这个处理过程比较简单,将缓存的数据结构信息对象删除掉,清空数据表名列表和模板列表,然后调用RefreshSystem方法刷新界面。
这个页面最重要的代码就是自动生成并显示代码的过程了。其C#代码为
| mmary> /// 创建代码按纽事件 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void cmdCreate_Click(object sender, System.EventArgs e) { DataBaseInfo info = this.GetInfo(); string xml = null ; if( cboTable.SelectedIndex == 0 ) { xml = GetXMLString( info ); } else { TableInfo table = info.Tables[ this.cboTable.SelectedValue ] ; if( table == null ) { this.lblResult.Text = "请选择一个表"; return ; } xml = GetXMLString( table ); } string html = ""; if( cboXSLT.SelectedIndex <= 0 ) { // 没有使用任何模板,直接显示XML源代码 html = @"<textarea wrap=off readonly style='border:1 solid black; overflow=visible; background-color:#dddddd'>" + xml + "</textarea>"; } else { // 启动了XSLT模板,执行XSLT转换 System.Xml.Xsl.XslTransform transform = new System.Xml.Xsl.XslTransform(); transform.Load( this.Server.MapPath( this.cboXSLT.SelectedValue ) + ".xslt" ); System.IO.StringWriter writer = new System.IO.StringWriter(); System.Xml.XmlDocument doc = new System.Xml.XmlDocument(); doc.LoadXml( xml ); transform.Transform( doc , null , writer , null ); writer.Close(); html = writer.ToString(); } this.lblResult.Text = "<b>共生成 " + html.Length + " 个字符</b><br />\r\n" + html ; } |
在生成代码按钮事件处理中,首先根据数据表名列表获得当前数据表结构信息对象,并生成XML字符串。若用户指定了某个数据表则调用GetXMLString函数来生成该数据表的XML字符串,否则对整个数据结构信息对象生成XML字符串。
若用户没有指定XSLT模板,则生成直接显示XML代码的HTML代码。这里使用textarea元素来显示XML代码,这样XML代码显示时不需要进行转义处理。
若用户指定了XSLT模板名称,则创建一个XslTransform对象,使用Load方法从程序目录中加载该名称的XSLT模板文件。这里可以看出我们的程序需要访问程序目录的权限,因此部署这个代码生成器时是需要配置权限的,使得程序能访问程序所在目录。
程序还创建一个XmlDocument对象,调用它的LoadXml方法来加载刚刚生成的XML字符串,然后执行XSLT转换,转换结果就当作HTML代码准备显示了。
最后程序根据生成的HTML代码设置到一个标签控件中。
代码中还定义了一个GetXMLString函数,该函数能将一个对象序列化成一个带缩进的XML字符串。其内部使用了XmlSerializer对象。使用XmlSerializer对象能很方便的将对象的公开属性导出为XML文档。
| /// <summary> /// 将指定对象序列化成XML文档,然后返回获得的XML字符串 /// </summary> /// <param name="obj">对象</param> /// <returns>XML字符串</returns> private string GetXMLString( object obj ) { System.IO.StringWriter myStr = new System.IO.StringWriter(); System.Xml.XmlTextWriter writer = new System.Xml.XmlTextWriter( myStr ); writer.Indentation = 3 ; writer.IndentChar = ' '; writer.Formatting = System.Xml.Formatting.Indented ; System.Xml.Serialization.XmlSerializer sc = new System.Xml.Serialization.XmlSerializer( obj.GetType() ); sc.Serialize( writer , obj ); writer.Close(); string xml = myStr.ToString(); int index = xml.IndexOf("?>"); if( index > 0 ) xml = xml.Substring( index + 2 ); return xml.Trim() ; } |
DataBaseInfo.cs
本代码生成器包括了DataBaseInfo.cs文件,其中就是比较底层的描述数据库表结构和字段设计信息的对象。这个文件中定义了多个类型,其中DataBaseInfo表示一个数据库,TableInfo表示数据表设计信息可,FieldInfo表示数据库字段设计信息。这三个类型构成了一个数据库-数据表-字段的三层对象树状结构。TableInfo和FieldInfo的代码不复杂。现在说一下DataBaseInfo类型中的一些代码。
首先看看LoadFromPDMXMLFile和LoadFromPDMXMLDocument函数,这个函数能分析PDM格式的XML文档,找出其中的数据表和字段设计信息并填充到内部结构中。某些版本的PowerDesigner生成的PDM文件是XML格式的,这方便其他程序能加载其中的数据结构设计信息。关于这个函数详细的处理过程,大家可以参考一个PDM的文件仔细分析。
| /// <summary> /// 从PDM数据结构定义XML文件中加载数据结构信息 /// </summary> /// <param name="doc">XML文档对象</param> /// <returns>加载的字段信息个数</returns> public int LoadFromPDMXMLDocument( XmlDocument doc ) { intFillStyle = FillStyleConst.PDM ; int RecordCount = 0 ; myTables.Clear(); XmlNamespaceManager nsm = new XmlNamespaceManager( doc.NameTable ); nsm.AddNamespace( "a" , "attribute" ); nsm.AddNamespace( "c" , "collection" ); nsm.AddNamespace( "o" , "object"); XmlNode RootNode = doc.SelectSingleNode("/Model/o:RootObject/c:Children/o:Model" , nsm ); if( RootNode == null ) return 0 ; strName = ReadXMLValue( RootNode , "a:Name" , nsm ); strDescription = strName ; // 数据表 foreach( XmlNode TableNode in RootNode.SelectNodes("c:Tables/o:Table" , nsm )) { TableInfo table = new TableInfo(); myTables.Add( table ); table.Name = ReadXMLValue( TableNode , "a:Code" , nsm ); table.Remark = ReadXMLValue( TableNode , "a:Name" , nsm ); string keyid = ReadXMLValue( TableNode , "c:PrimaryKey/o:Key/@Ref" , nsm ); System.Collections.Specialized.StringCollection Keys = new System.Collections.Specialized.StringCollection(); if( keyid != null ) { foreach( XmlNode KeyNode in TableNode.SelectNodes( "c:Keys/o:Key[@Id = '" + keyid + "']/c:Key.Columns/o:Column/@Ref" , nsm )) { Keys.Add( KeyNode.Value ); } } foreach( XmlNode FieldNode in TableNode.SelectNodes("c:Columns/o:Column" , nsm )) { RecordCount ++ ; string id = ( ( XmlElement ) FieldNode).GetAttribute("Id"); FieldInfo field = new FieldInfo(); table.Fields.Add( field ); field.Name = ReadXMLValue( FieldNode , "a:Code" , nsm ); field.Remark = ReadXMLValue( FieldNode , "a:Name" , nsm ); field.Description = ReadXMLValue( FieldNode , "a:Comment" , nsm ); string FieldType = ReadXMLValue( FieldNode , "a:DataType" , nsm ); if( FieldType != null ) { int index = FieldType.IndexOf("("); if( index > 0 ) FieldType = FieldType.Substring( 0 , index ); } field.FieldType = FieldType ; field.FieldWidth = ReadXMLValue( FieldNode , "a:Length" , nsm ); if( Keys.Contains( id )) field.PrimaryKey = true; } } return RecordCount ; } private string ReadXMLValue( System.Xml.XmlNode node , string path , System.Xml.XmlNamespaceManager nsm ) { System.Xml.XmlNode node2 = node.SelectSingleNode( path , nsm ); if( node2 == null ) return null ; else { if( node2 is System.Xml.XmlElement ) return ( ( System.Xml.XmlElement ) node2).InnerText ; else return node2.Value ; } } |
LoadFromAccess2000函数能从一个Access2000格式的数据库中加载数据结构设计信息。这个函数内部使用了OleDbConnection对象的GetOleDbSchemaTable方法可以获得数据库的一些信息,具体什么样式可以参考MSND中关于GetOleDbSchema方法的详细说明。对于不同的数据库其处理过程是不同的,在这里的使用方法是我经过反复测试得到的,而且只适用于Access2000数据库。在这里首先是获得所有的数据表名和字段设计信息,然后获得字段索引信息。
| /// <summary> /// 从 Jet40( Access2000 ) 的数据库中加载数据结构信息 /// </summary> /// <param name="myConn">数据库连接对象</param> /// <returns>加载的字段信息个数</returns> public int LoadFromAccess2000( OleDbConnection myConn ) { intFillStyle = FillStyleConst.Access2000 ; int RecordCount = 0 ; myTables.Clear(); string dbName = myConn.DataSource ; if( dbName != null ) strName = System.IO.Path.GetFileName( dbName ); using(System.Data.DataTable myDataTable = myConn.GetOleDbSchemaTable( System.Data.OleDb.OleDbSchemaGuid.Columns , null)) { foreach( System.Data.DataRow myRow in myDataTable.Rows ) { string strTable = Convert.ToString( myRow["TABLE_NAME"] ); if( ! strTable.StartsWith("MSys")) { TableInfo myTable = myTables[ strTable ] ; if( myTable == null ) { myTable = new TableInfo(); myTable.Name = strTable ; myTables.Add( myTable ); } FieldInfo myField = new FieldInfo(); myTable.Fields.Add( myField ); myField.Name = Convert.ToString( myRow["COLUMN_NAME"]); myField.Nullable = Convert.ToBoolean( myRow["IS_NULLABLE"]); System.Data.OleDb.OleDbType intType = (System.Data.OleDb.OleDbType) Convert.ToInt32( myRow["DATA_TYPE"]); if( System.DBNull.Value.Equals( myRow["DESCRIPTION"] ) == false ) { myField.Remark = Convert.ToString( myRow["DESCRIPTION"] ) ; } if( intType == System.Data.OleDb.OleDbType.WChar ) { myField.FieldType = "Char" ; } else { myField.FieldType = intType.ToString(); } myField.FieldWidth = Convert.ToString( myRow["CHARACTER_MAXIMUM_LENGTH"]); RecordCount ++ ; } }//foreach }//using using( System.Data.DataTable myDataTable = myConn.GetOleDbSchemaTable( System.Data.OleDb.OleDbSchemaGuid.Indexes , null)) { foreach( System.Data.DataRow myRow in myDataTable.Rows ) { string strTable = Convert.ToString( myRow["TABLE_NAME"] ); TableInfo myTable = myTables[ strTable ]; if( myTable != null ) { FieldInfo myField = myTable.Fields[ Convert.ToString( myRow["COLUMN_NAME"])]; if( myField != null) { myField.Indexed = true; myField.PrimaryKey = ( Convert.ToBoolean( myRow["PRIMARY_KEY"])); } } }//foreach }//using return RecordCount ; }//public int LoadFromAccess2000( OleDbConnection myConn ) |
LoadFromOracle函数用于分析Oracle数据库而获得表结构和字段设计信息。其代码如下。
在ORACLE数据库中,有一个名为COL的系统预定义视图,里面就是各个数据表名和字段定义信息,还有一个名为user_ind_columns的预定义视图,里面就保存着字段索引信息。
我们首先查询遍历COL视图,获得该视图中保存的数据表名,字段名,字段数据类型,字段长度等信息。建立起基本的表和字段信息结构,然后查询遍历user_ind_columns视图,获得其关键字段信息。
| /// <summary> /// 从 Oracle 加载数据库结构信息 /// </summary> /// <param name="myConn">数据库连接对象</param> /// <returns>加载的字段信息个数</returns> public int LoadFromOracle( IDbConnection myConn ) { intFillStyle = FillStyleConst.Oracle ; int RecordCount = 0 ; string strSQL = null; strSQL = "Select TName,CName,coltype,width From Col Order by TName,CName"; myTables.Clear(); if( myConn is OleDbConnection ) { strName = ( ( System.Data.OleDb.OleDbConnection ) myConn ).DataSource + " - " + myConn.Database ; } else strName = myConn.Database ; using( System.Data.IDbCommand myCmd = myConn.CreateCommand()) { myCmd.CommandText = strSQL ; IDataReader myReader = myCmd.ExecuteReader( CommandBehavior.SingleResult ); TableInfo LastTable = null; while( myReader.Read()) { string TableName = myReader.GetString(0).Trim(); if( LastTable == null || LastTable.Name != TableName ) { LastTable = new TableInfo(); myTables.Add( LastTable ); LastTable.Name = TableName ; } FieldInfo NewField = new FieldInfo(); LastTable.Fields.Add( NewField ); NewField.Name = myReader.GetString(1); NewField.FieldType = myReader.GetString(2); NewField.FieldWidth = myReader[3].ToString(); RecordCount ++ ; }//while myReader.Close(); myCmd.CommandText = @" select table_name , column_name , index_name from user_ind_columns order by table_name , column_name "; myReader = myCmd.ExecuteReader( CommandBehavior.SingleResult ); TableInfo myTable = null; while( myReader.Read()) { myTable = myTables[ myReader.GetString(0)]; if( myTable != null ) { string IDName = myReader.GetString(2); string FieldName = myReader.GetString(1); FieldInfo myField = myTable.Fields[ FieldName ]; if( myField != null ) { myField.Indexed = true ; if( IDName.StartsWith("PK") ) { myField.PrimaryKey = true; } } } }//while myReader.Close(); }//using return RecordCount ; }//public int LoadFromOracle( System.Data.IDbConnection myConn ) |
LoadFromSQLServer函数用于分析一个MSSQLServer数据库,加载其表和字段设计信息。其代码如下。在SQLSERVER中包含了一些系统表,比如SysObjects,SysColumns等等,里面就存储了系统中所有对象的信息,比如表,字段,存储过程,触发器等等。我们就可以从这些系统表中查询所有的表和字段定义信息。SQLSERVER中还有一个名为sp_helpindex的系统预定义存储过程,可用来查询指定表的索引信息。
在代码中我们首先使用一个比较复杂的SQL语句从系统表中查询数据库中所有的数据表名,字段名,字段类型和长度等信息。这里的SQL语句是我个人摸索的,相信大家可以写出更好更准确的SQL语句。我们读取查询结果就可以构造出基本的表和字段对象结构,然后针对每一个表对象,调用sp_helpindex存储过程,获得数据表中定义的关键字段信息。
| /// <summary> /// 从 SQLServer 中加载数据库结构信息 /// </summary> /// <param name="myConn">数据库连接对象</param> /// <returns>加载的字段信息个数</returns> public int LoadFromSQLServer( IDbConnection myConn ) { intFillStyle = FillStyleConst.SQLServer ; int RecordCount = 0 ; if( myConn is OleDbConnection ) strName = ( ( OleDbConnection ) myConn ).DataSource ; else if( myConn is System.Data.SqlClient.SqlConnection ) strName = ( ( System.Data.SqlClient.SqlConnection ) myConn ).DataSource ; strName = strName + " - " + myConn.Database ; string strSQL = null; strSQL = @" select sysobjects.name , syscolumns.name , systypes.name , syscolumns.length , syscolumns.isnullable , sysobjects.type from syscolumns, sysobjects, systypes where syscolumns.id=sysobjects.id and syscolumns.xusertype=systypes.xusertype and (sysobjects.type='U' or sysobjects.type='V' ) and systypes.name <>'_default_' and systypes.name<>'sysname' order by sysobjects.name, syscolumns.name"; myTables.Clear(); using( System.Data.IDbCommand myCmd = myConn.CreateCommand()) { myCmd.CommandText = strSQL ; IDataReader myReader = myCmd.ExecuteReader( CommandBehavior.SingleResult ); TableInfo LastTable = null; while( myReader.Read()) { string TableName = myReader.GetString(0).Trim(); if( LastTable == null || LastTable.Name != TableName ) { LastTable = new TableInfo(); myTables.Add( LastTable ); LastTable.Name = TableName ; LastTable.Tag = Convert.ToString( myReader.GetValue( 5 )); } FieldInfo NewField = new FieldInfo(); LastTable.Fields.Add( NewField ); NewField.Name = myReader.GetString(1); NewField.FieldType = myReader.GetString(2); NewField.FieldWidth = myReader[3].ToString(); if( myReader.IsDBNull( 4 ) == false) NewField.Nullable = (myReader.GetInt32(4) == 1); RecordCount ++ ; }//while myReader.Close(); // 加载主键信息 for( int iCount = myTables.Count - 1 ; iCount >= 0 ; iCount -- ) { TableInfo myTable = myTables[ iCount ] ; if( string.Compare( ( string ) myTable.Tag , "U" , true ) == 0 ) { try { myCmd.CommandText = "sp_helpindex \"" + myTable.Name + "\"" ; //myCmd.CommandType = System.Data.CommandType.Text ; myReader = myCmd.ExecuteReader( ); while( myReader.Read()) { string strKeyName = myReader.GetString(0); string strDesc = myReader.GetString(1); string strFields = myReader.GetString(2); bool bolPrimary = ( strDesc.ToLower().IndexOf("primary") >= 0 ); foreach( string strField in strFields.Split(',')) { FieldInfo myField = myTable.Fields[ strField.Trim()]; if( myField != null) { myField.Indexed = true; myField.PrimaryKey = bolPrimary ; } }//foreach }//while myReader.Close(); } catch( Exception ext ) { //this.List.Remove( myTable ); myTable.Name = myTable.Name + " " + ext.Message ; } } }//foreach }//using return RecordCount ; }//public int LoadFromSQLServer( System.Data.IDbConnection myConn ) |
目前DataBaseInfo对象只能分析Access2000,SQLSERVER和Oralce数据库,大家以后可以完善它,使得它能分析比如DB2,MYSQL等其他数据库类型。在未来的软件开发过程中,若需要分析数据库结构的,则只要调用这个DataBaseInfo就可以了。
在本演示程序中,我们只是用程序目录下的一个Access2000数据库作为例子,因此也只调用了LoadFromAccesss2000这个函数,其他的分析SQLSERVER和ORACLE的函数没用到。在未来当这个代码生成器经过改善而投入实际应用时,它就能分析SQLSERVER和ORACLE等企业级数据库了。
在主页面xslcreatecode.aspx中定义了一个GetXMLString函数,它能将一个对象序列化成一个XML文档。这里的DataBaseInfo,TableInfo和FieldInfo都能XML序列化。在执行XML序列化时,系统会分析对象类型,遍历对象所有的公开字段和可读写属性,然后将这些属性值输出到XML文档,若遇到对象树状结构,则会递归遍历这个树状结构,对对象中的每一个下属对象都会建立一个XML子元素进行输出。在这里DataBaseInfo,TableInfo和FieldInfo构成了三层的树状结构,因此生成的XML文档也是多层次的。
一般来说,序列化生成的XML文档中,XML元素的名称等于对象类型的名称和公开字段属性的名称,但可以通过添加特性来改变这种默认行为,在类型TableInfo的定义前面加上了特性XmlType,在这里指明了为类型TableInfo生成的XML元素名称不是对象类型名称TableInfo,而是Table。
| [System.Xml.Serialization.XmlType("Table")] public class TableInfo |
同样的方式,我们为类型FieldInfo指定了XML元素名称为Field,这里展示了特性在C#中的应用。关于特性在未来的某节课程中将讲到。
由于能执行XML序列化的属性必须是可读写的,因此在类型FieldInfo中的IsString,IsInteger等属性为了能执行XML序列化,因此定义了毫无作用的set方法。
XSLT模板说明程序目录下放置了一些以下划线开头的扩展名为XSLT的文件,这就是代码生成器使用的代码生成模板。在主界面中使用不同的模板就能生成不同的代码。在这里我们以_cshaprhashtable.xslt为例子进行说明。
_cshaprhashtable.xslt首先我们在界面中选择数据表Customers,可以生成它的XML代码为.
| <Table xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <Name>Customers</Name> <Fields> <Field> <Name>Address</Name> <Remark>地址</Remark> <FieldType>Char</FieldType> <IsString>true</IsString> <IsInteger>false</IsInteger> <IsBoolean>false</IsBoolean> <IsNumberic>false</IsNumberic> <IsDateTime>false</IsDateTime> <IsBinary>false</IsBinary> <ValueTypeName>System.String</ValueTypeName> <FieldWidth>60</FieldWidth> <Nullable>true</Nullable> <PrimaryKey>false</PrimaryKey> <Indexed>false</Indexed> </Field> <Field> <Name>City</Name> <Remark>城市</Remark> <FieldType>Char</FieldType> <IsString>true</IsString> <IsInteger>false</IsInteger> <IsBoolean>false</IsBoolean> <IsNumberic>false</IsNumberic> <IsDateTime>false</IsDateTime> <IsBinary>false</IsBinary> <ValueTypeName>System.String</ValueTypeName> <FieldWidth>15</FieldWidth> <Nullable>true</Nullable> <PrimaryKey>false</PrimaryKey> <Indexed>false</Indexed> </Field> <Field>其他字段....</Field> </Fields> </Table> |
而模板_cshaprhashtable.xslt的代码为
| <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <!-- 根据表结构XML文档创建影射数据库字段的 C# 代码,内部使用 Hashtable 来存储字段数据 编制 袁永福 2008-1-17 --> <xsl:template match="/*"> <xsl:if test="name(.) != 'Table' "> <font color="red">本模板只能用于单表</font> <br /> </xsl:if> <textarea wrap="off" readonly="1" style=" border:1 solid black; overflow=visible; background-color:#dddddd"> <xsl:variable name="classname"> <xsl:value-of select="concat('DB2_' , Name )" /> </xsl:variable> //***************************************************************************** // 文件名 <xsl:value-of select="Name" />.cs //***************************************************************************** /// <summary> /// 数据库表 <xsl:value-of select="Name" /> <xsl:if test="Remark!=''"> <xsl:value-of select="concat(' [',Remark,']')" /> </xsl:if> 操作对象 /// </summary> /// <remark> /// 该表有<xsl:value-of select="count(Fields/Field)" />个字段 /// 编制: 代码生成器 /// 时间: ///</remark> [System.Serializable()] public class <xsl:value-of select="$classname" /> { ///<summary>返回数据表名称 <xsl:value-of select="Name" /></summary> public static string TableName { get{ return "<xsl:value-of select="Name" />" ; } } ///<summary>返回所有字段的名称</summary> <xsl:text> public static string[]FieldNames { get { return new string[]{ </xsl:text> <xsl:for-each select="Fields/Field"> <xsl:if test="position()>1"> <xsl:text> ,</xsl:text> </xsl:if> <xsl:text>"</xsl:text> <xsl:value-of select="Name" /> <xsl:text>"</xsl:text> </xsl:for-each> <xsl:text> }; } } #region 定义数据库字段变量及属性 ////////////////////////////////////////// private System.Collections.Hashtable myValues = new System.Collections.Hashtable(); </xsl:text> ///<summary>包含所有字段值的列表</summary> <xsl:text> public System.Collections.Hashtable Values { get{ return myValues ;} } </xsl:text> <xsl:for-each select="Fields/Field"><!-- 开始循环遍历所有的字段定义信息 --> <xsl:variable name="remark"> <xsl:if test="string-length( Remark ) > 0 "> <xsl:value-of select="concat( '(' , Remark , ')')" /> </xsl:if> </xsl:variable> ///<summary>字段值 <xsl:value-of select="Name" /> <xsl:value-of select="$remark" /> <xsl:if test="PrimaryKey='true'">[关键字段]</xsl:if> </summary> public <xsl:value-of select="concat( ValueTypeName , ' ' , Name )" /> { get{ return <xsl:choose> <xsl:when test="ValueTypeName='System.Byte[]'"> <xsl:text>( </xsl:text> <xsl:value-of select="ValueTypeName" /> <xsl:text> ) myValues["</xsl:text> <xsl:value-of select="Name" /> <xsl:text>"]</xsl:text> </xsl:when> <xsl:otherwise> <xsl:text>Convert.To</xsl:text> <xsl:value-of select="substring-after( ValueTypeName , '.' )" /> <xsl:text>( myValues["</xsl:text> <xsl:value-of select="Name" /> <xsl:text>"] )</xsl:text> </xsl:otherwise> </xsl:choose> ;} set{ myValues["<xsl:value-of select="Name" />"] = value;} } </xsl:for-each> #endregion }// 数据库操作类 <xsl:value-of select="$classname" /> 定义结束 </textarea> </xsl:template> </xsl:stylesheet> |
则生成的代码文本为
| //***************************************************************************** // 文件名 Customers.cs //***************************************************************************** /// <summary> /// 数据库表 Customers 操作对象 /// </summary> /// <remark> /// 该表有13个字段 /// 编制: 代码生成器 /// 时间: ///</remark> [System.Serializable()] public class DB2_Customers { ///<summary>返回数据表名称 Customers</summary> public static string TableName { get{ return "Customers" ; } } ///<summary>返回所有字段的名称</summary> public static string[] FieldNames { get { return new string[]{ "Address" ,"City" ,"CompanyName" ,"ContactName" ,"ContactTitle" ,"Country" ,"CustomerID" ,"Email" ,"Fax" ,"Phone" ,"PostalCode" ,"Region" ,"WebSite" }; } } #region 定义数据库字段变量及属性 ////////////////////////////////////////// private System.Collections.Hashtable myValues = new System.Collections.Hashtable(); ///<summary>包含所有字段值的列表</summary> public System.Collections.Hashtable Values { get{ return myValues ;} } ///<summary>字段值 Address(地址)</summary> public System.String Address { get{ return Convert.ToString( myValues["Address"] ) ;} set{ myValues["Address"] = value;} } -------- 其他字段 --------------------- #endregion }// 数据库操作类 DB2_Customers 定义结束 |
现在我们根据前因后果来说明其中的过程。在XSLT文件中,唯一的一个xsl:template模板定义块命中XML文档的根节点,然后使用name函数来测试当前节点的名称是否为Table,若不是则输出“本模板只能用于单表”的提示信息。XSLT没有return语句,只能按顺序执行下去,因此不管XML文档是否正确还是继续输出。
接着输出textarea标签,由于使用HTML格式显示代码,而这里使用textarea元素,我们就不用做尖括号字符转义了。
这里有xsl:variable 元素,说明开始定义一个变量,该变量的名称是classname,也就是这个C#类的名称。XSLT变量不是真的变量,应当算是常量,其值是不能改变的。这里还用到了concat函数,这是XSLT中字符串连接函数,用于将多个字符串拼凑起来,这个函数的参数个数不固定,但必须等于或超过2个。函数里面可以使用XPath路径来引用某个XML节点,用单引号来定义固定的字符串。
然后XSLT输出代码开头的一些说明性的注释文本,这里是用了count函数来累计所有的字段个数。接着开始输出C#代码了,在输出类型定义中使用了xsl:value-of标记来输出类型名称,它是用$classname来引用刚才定义的名为classname的XSLT变量。然后我们输出静态属性TableName返回数据表的名称。
在输出FieldNames属性时,我们遍历输出了字段名称,这里有个判断,若position函数的值大于1则在字段名称前输出一个逗号,position函数用于返回当前处理的节点在整个要处理的节点列表中的从1开始的序号。若position值大于1,则表示不是输出第一个字段名称,由于这里是定义一个字符串数组的,因此需要添加逗号。
在这里我们使用xsl:text来输出纯文本数据,这里输出逗号时可以不需要使用xsl:text元素,可以直接输出,但使用xsl:text元素可以改善XSLT代码的可读性。而且xsl:text元素可以输出连续的空白字符。
接着我们输出myValues 变量和Values属性,然后又开始遍历字段输出各个字段的属性代码了。
首先我们定义了一个名为remark的变量,用于保存字段说明文本。然后输出字段属性的说明性注释,并判断PrimaryKey元素值,若该元素值为true则输出文本“关键字段”。然后输出public 属性数据类型 属性名称,这里是用concat函数来连接属性数据类型和字段名称,中间加了一个空格。
这里我们使用了xsl:choose结构,xsl:choose类似C#中的swith语句,下面的xsl:when 类似C#的case 语句,而xsl:otherwise 类似C#的default语句。Xsl:choose 可以包含若干个xsl:when,而且最多包含一个xsl:oterwise元素。每一个xsl:when都可以进行各自的判断,这点和switch不同,更像连续的if else ifelse 语句。
在这里,第一个xsl:when判断字段类型名称是否是System.Byte[],也就是字节数组,若是字节数组则输出字节数组强制转化的C#代码。剩余的情况使用xsl:otherwise来输出使用Convert.To函数进行类型转换的C#代码。
经过上述的XSLT转换处理,我们就能根据描述数据表和字段设计信息的XML文档来自动生成C#代码了。把这个C#代码复制到C#工程中就可以编译了。这段代码内部使用一个哈西表来保存字段的值,并使用一个个属性来影射数据库表的字段。
在程序目录下存在一些类似的模板,比如_cshapr.xslt就是生成另外一种的C#代码的模板,在生成的代码中不是用哈西列表保存数据,而是是用一个个变量来保存字段数据。_java.xslt是生成JAVA代码的,_VB6.xslt是生成VB6代码的。
_HTML.xslt程序目录下还有其他的代码生成器模板,例如_HTML.xslt能生成HTML代码,能是用表格的样式来展示多个表结构信息。该 模板有个特点就是既能生成单个表的信息,也能生成整个数据库中所有表的信息。该模板的XSLT代码为
| <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output indent='yes' /> <xsl:template match="/*"> <xsl:for-each select="//Table"> <xsl:call-template name="table" /> </xsl:for-each> </xsl:template> <xsl:template name="table"> <div> <span> <span>数据表 </span> <b> <xsl:value-of select="Name" /> </b> <span> 结构,共 </span> <xsl:value-of select="count( Fields/Field )" /> <span> 个字段 </span> <xsl:value-of select="concat(' ', Remark)" /> <xsl:if test="count( Fields/Field[PrimaryKey='true']) > 0 "> <span>关键字段:</span> <b> <xsl:for-each select="Fields/Field[PrimaryKey='true']"> <xsl:if test="position()> 1 ">,</xsl:if> <xsl:value-of select="Name" /> </xsl:for-each> </b> </xsl:if> </span> <table style="border: black 1 solid" border="0" width="100%" rules='all' cellspacing="0" cellpadding="0" bordercolor="#000000"> <tr bgcolor="#eeee99"> <td width="150">字段名</td> <td width="80">字段类型</td> <td width="50">长度</td> <td width="80">可否为空</td> <td width="80">是否索引</td> <td>说明</td> </tr> <xsl:for-each select="Fields/Field"> <xsl:sort select="Name" /> <tr valign="top"> <xsl:attribute name="bgcolor"> <xsl:iftest="position() mod 2 = 0">#eeeeee</xsl:if> </xsl:attribute> <td> <font> <xsl:if test="PrimaryKey='true'"> <xsl:attribute name="color">red</xsl:attribute> </xsl:if> <xsl:value-of select="concat(' ' , Name)" /> </font> </td> <td> <xsl:value-of select="FieldType" /> </td> <td> <xsl:value-of select="FieldWidth" /> </td> <td> <xsl:if test="Nullable='true'">是</xsl:if> </td> <td> <xsl:if test="Indexed='true'">是</xsl:if> </td> <td> <xsl:value-of select="Remark" /> <xsl:if test="Description !=''"> <br /> <xsl:value-of select="Description" /> </xsl:if> </td> </tr> </xsl:for-each> </table> </div> <p /> </xsl:template> </xsl:stylesheet> |
现对该模板进行详细说明。在这个模板中有两个xsl:template,也就定义了两个子模板,其中第一个直接使用match命中XML文档的根节点,而第二个xsl:template创建一个名为table的子模板。按照面向过程的软件开发思想,第一个模板就是主函数,而第二个模板就定义了一个名为table的函数,主函数内部调用了这个子函数。
在主模板中,首先是用XPath路径//Table来查找XML文档中所有的名为Table的节点。在XPath中使用两个斜线表示查找XML文档中的当前节点下的所有子孙节点。对于查到的每个Table元素都是用xsl:call-template来调用名为table的子模板。这很类似C语言中主函数调用子函数一样。
XSLT转换过程进入的了table的子模板中,首先输出DIV,输出一些数据表的说明文字。这里还是用count( Fields/Field[PrimaryKey='true']) > 0 来判断该表是否有关键字段,若有关键字段则输出关键字段的名称。
然后输出table标签,输出第一行表格,然后查找遍历所有的字段元素,对每一个字段XML元素,首先输出tr标签,这里还是用了xsl:attribute元素来设置TR元素的属性值。这里用了name属性来指明输出的是tr元素的名为bgcolor的属性值,也就是表格行的背景色。里面是用 xsl:if 来输出该属性值的内容,这里的判断条件是 position() mod 2 = 0 ,position()函数返回从1开始的当前节点的序号,mod 表示数学取模运算,因此若当前节点的序号是二的倍数则输出其内容,也就是#eeeeee ,这是一个浅灰色的颜色值。这样我们就可以让表格行每隔一行就设置bgcolor属性为#eeeeee,实现了表格行的颜色交替变化。
然后我们开始输出单元格,第一个单元格输出字段名,这里我们又是用了xsl:attribute,使得若字段为关键字段则使用红色显示字段名称。剩下的栏目则原样输出。
这样我们定义了两个子模板来输出HTML代码,能显示一个或全部的数据表的字段定义信息。
其实我们可以将两个子模板合并为一个模板,将子模板的XSLT代码复制到主模板的xsl:for-each里面,也也能用一个模板来输出一个或全部的数据表的代码。
类似的在模板_sql.语句.xslt也定义了两个模板,使得能输出一个或全部数据表的SQL语句。
从这些例子可以看出,XSLT代码有点类似面向过程的编程语言。其中有逻辑判断,循环,条件开关列表,主函数,子函数,可以说是用XML来书写的程序代码。XSLT只能根据另外一个XML文件输出纯文本文档。
运行程序大家获得程序源代码后,设置虚拟目录,并设置安全权限,使得程序能读取程序目录下的文件,也不用作其它配置即可运行。部属完毕后我们就可以在浏览器中查看这个代码生成器的运行结果了。
用户界面中列出了演示数据库中所有的数据表名称,并列出了可用的模板名。大家可以选择某个数据表名或整个数据库,然后再选择某个模板,点击“创建代码”按钮,即可在按钮下面看到生成的以HTML方式显示的自动生成的文档。
大家可以仿造已有的XSLT模板编制自己的代码生成模板,保存的文件名以下划线开头,XSLT为扩展名。放置到程序目录下,点击“刷新系统”按钮就可使用刚刚添加的代码生成模板。这也算做是一种热拔插系统了。
本代码生成器的特点是程序代码是少量的,功能是强大的,配置是灵活的,移植也是简单的。由于核心是采用XSLT的,因此很容易翻译到JAVA,VB.NET,PHP等其它B/S程序。添加和删除模板的操作也是很简单的。大家可以根据各自需要,将这个代码生成器进行一些扩展即可投入实际运用了。
小结在本课程中,我们使用了C#和XSLT技术开发了一个可投入实际运用的代码生成器了。该代码生成器结构简单,功能强大。使我们更深入的发现了XSLT技术的威力。建议大家以后多多学习多多应用.