自然语言处理(NLP,Natural Language Processing):利用计算机处理文本及声音。
李宏毅:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLSD15_2.html

应用领域:输入—输出;输入法; 拼写更正;机器翻译;evernote推荐系统; 英文写作助手;twitter重大事件分析;医疗诊断;体育赛事报道生成。
应用技术:语言模型,自动机,中文分词,文本对齐,模板匹配,分类器,相似度计算,local sensitive hashing,文本分类,关键词匹配,倒排索引,语法分析,找词根,社交网络,可信度分析,规则系统,深度学习,模板填充,同义词替换,文本对齐。
概率系统的工作方式:流程设计—收集训练数据—预处理—抽取特征—分类器—预测—评价。

语言模型
xx模型——对某个语句打分
概率语言模型:Statistical language model
核心:通过打分告诉机器怎么说话。
N-gram:

HMM假设:未来的事件,取决于有限的历史。

N-gram LM 符合马尔可夫假设,N个状态相关;
RNN LM 非马尔科夫假设 可计算无限多个假设。
OOV解决办法:
把没有出现过的词统计为unk,用unk替换oov进行概率计算。

最大似然估计:
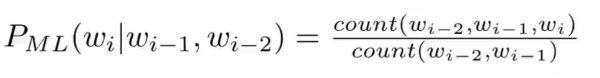

N-gram平滑:
back-up回退法:自己有钱自己出,没钱爸爸出,爸爸没钱爷爷出。
trigram没有——> bigram没有——> unigram
Interpolate插值法:自己 爸爸 爷爷各出一点钱。

Absolute discount 绝对折扣----劫富济贫,按爸爸的资产分配。
Kneser-Ney smoothing----有钱人交固定的税,按爸爸人脉分配。
Modified KN----有钱人交阶梯税,按爸爸人脉分配。

词向量:tf.nn.embedding_lookup
embedding_lookup(
params,
ids,
partition_strategy='mod',
name=None,
validate_indices=True,
max_norm=None)
embedding_lookup(params, ids)其实就是按照ids顺序返回params中的第ids行。
比如说,ids=[1,3,2],就是返回params中第1,3,2行。返回结果为由params的1,3,2行组成的tensor。
params:表示完整嵌入张量的单张量,或者除了第一维以外的P张量表,它们都是相同的形状,表示分片嵌入张量。 或者,通过沿着维度0进行分区创建一个PartitionedVariable。每个元素的大小必须适合给定的partition_strategy。
ids:类型为int32或int64的张量,包含要在参数中查找的id。
partition_strategy:指定分区策略的字符串,相关如果len(params)> 1.目前支持“div”和“mod”。 默认是“mod”。
name:操作的名称(可选)。
validate_indices:DEPRECATED。 如果将此操作分配给CPU,则索引中的值始终验证在范围内。 如果分配给GPU,超出边界的索引会导致安全但未指定的行为,其中可能包括引发错误。
max_norm:如果提供,嵌入值被归一化为max_norm的值。
自然语言处理

自然语言处理学习路线
数学基础
代数
关注矩阵处理相关的一些知识,比如矩阵的SVD、QR分解,矩阵逆的求解,正定矩阵、稀疏矩阵等特殊矩阵的一些处理方法和性质等等。
https://c.open.163.com/search/search.htm?query=线性代数#/search/all
概率论
在很多的自然语言处理场景中,我们都是算一个事件发生的概率。这其中既有特定场景的原因,比如要推断一个拼音可能的汉字,因为同音字的存在,我们能计算的只能是这个拼音到各个相同发音的汉字的条件概率。也有对问题的抽象处理,比如词性标注的问题,这个是因为我们没有很好的工具或者说能力去精准地判断各个词的词性,所以就构造了一个概率解决的办法。
对于概率论的学习,既要学习经典的概率统计理论,也要学习贝叶斯概率统计。相对来说,贝叶斯概率统计可能更重要一些,这个和贝叶斯统计的特性是相关的,因其提供了一种描述先验知识的方法。使得历史的经验使用成为了可能,而历史在现实生活中,也确实是很有用的。比如朴素贝叶斯模型、隐马尔卡模型、最大熵模型,这些我们在自然语言处理中耳熟能详的一些算法,都是贝叶斯模型的一种延伸和实例。
统计学导论:http://open.163.com/movie/2011/5/M/O/M807PLQMF_M80HQQGMO.html,
贝叶斯统计:https://www.springboard.com/blog/probability-bayes-theorem-data-science/。
信息论
信息论作为一种衡量样本纯净度的有效方法。对于刻画两个元素之间的习惯搭配程度非常有效。这个对于我们预测一个语素可能的成分(词性标注),成分的可能组成(短语搭配)非常有价值,所以这一部分知识在自然语言处理中也有非常重要的作用。
同时这部分知识也是很多机器学习算法的核心,比如决策树、随机森林等以信息熵作为决策桩的一些算法。对于这部分知识的学习,更多的是要理解各个熵的计算方法和优缺点,比如信息增益和信息增益率的区别,以及各自在业务场景中的优缺点。照例放上一个链接:http://open.163.com/special/opencourse/information.html。
数据结构与算法
重点关注链表、树结构和图结构(邻接矩阵)。包括各个结构的构建、操作、优化,以及各个结构在不同场景下的优缺点。当然大部分情况下,可能使用到的数据结构都不是单一的,而是有多种数据结构组合。比如在分词中有非常优秀表现的双数组有限状态机就使用树和链表的结构,但是实现上采用的是链表形式,提升了数据查询和匹配的速度。在熟练掌握各种数据结构之后,就是要设计良好的算法了。
多数场景下都要研发并行的算法。这里面又涉及到一些工具的应用,也就是编程技术的使用。例如基于Hadoop的MapReduce开发和Spark开发都是很好的并行化算法开发工具,但是实现机制却有很大的差别,同时编程的便利程度也不一样。
当然这里面没有绝对的孰好孰坏,更多的是个人使用的习惯和业务场景的不同而不同。比如两个都有比较成熟的机器学习库,一些常用的机器学习算法都可以调用库函数实现,编程语言上也都可以采用Java,不过Spark场景下使用Scala会更方便一些。因为这一部分是偏实操的,所以我的经验会建议实例学习的方法,也就是跟着具体的项目学习各种算法和数据结构。
最好能对学习过的算法和数据结构进行总结回顾,这样可以更好的得到这种方法的精髓。因为基础的元素,包括数据结构和计算规则都是有限的,所以多样的算法更多的是在不同的场景下,对于不同元素的一个排列组合,如果能够融会贯通各个基础元素的原理和使用,不管是对于新知识的学习还是对于新解决方案的构建都是非常有帮助的。
这里给出一个学习基础算法(包含排序、图、字符串处理等)的课程链接:https://algs4.cs.princeton.edu/home/。
语言学
这一部分就更多是语文相关的知识,比如一个句子的组成成分包括:主、谓、宾、定、状、补等。对于各个成分的组织形式也是多种多样。比如对于主、谓、宾,常规的顺序就是:主语→谓语→宾语。当然也会有:宾语→主语→宾语(饭我吃了)。在先期的研究中,基于规则的模型,大部分都是基于语言模型的规则进行研究和处理的。
深度学习
RNN ,在处理时序数据上的优势。同时新的学习框架,比如对抗学习、增强学习、对偶学习,也是需要关注的。其中对抗学习和对偶学习都可以显著降低对样本的需求,这个对于自然语言处理的价值是非常大的,因为在自然语言处理中,很重要的一个环节就是样本的标注,很多模型都是严重依赖于样本的好坏,而随着人工成本的上升,数据标注的成本越来越高。
现在还有一个事物正在如火如荼地进行着,就是知识图谱,对于这部分的学习可能更多的是要关注信息的链接、整合和推理的技术。这里的每一项技术都是非常大的一个领域,所以还是建议从业务实际需求出发去学习相应的环节和知识,满足自己的需求,链http://www.chinahadoop.cn/course/918。