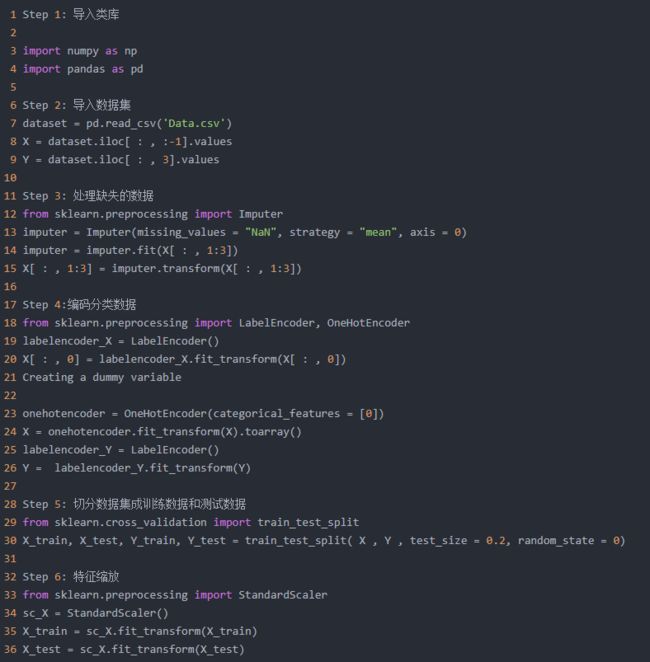
数据预处理分为6步:
第1步:导入NumPy和Pandas库。NumPy和Pandas是每次都要导入的库,其中Numpy包含了数学计算函数,Pnadas是一个用于导入和管理数据集(Data Sets)的类库。
第2步:导入数据集。数据集一般都是.csv格式,csv文件以文本形式存储数据。每一行数据是一条记录。我们使用pandas类库的read_csv方法读取本地的csv文件作为一个dataframe。然后从datafram中分别创建自变量和因变量的矩阵和向量。
第3步:处理缺失的数据。我们得到的数据很少是完整的。数据可能因为各种原因丢失,为了不降低机器学习模型的性能,需要处理数据。我们可以用整列的平均值或者中间值替换丢失的数据。我们用sklearn.preprocessing库中的Inputer类完成这项任务。
第4步:对分类数据进行编码。分类数据指的是含有标签值而不是数字值得变量。取值范围通常是固定的。例如“YES”和“NO”不能用于模型的数学计算,所以需要编码成数字。为数显这一功能,我们从sklearn.preprocessing库中导入LabelEncoder类。
第5步:拆分数据集为测试集合和训练集合。把数据集拆分成两个,一个是用来训练模型的训练集合,另一个是用来验证模型的测试集合。两种比例一般是80:20。我们导入sklearn.crossvalidation库中的train_test_split()方法。
第6步:特征缩放。大部分模型算法使用两点间的欧式近距离表示,但此特征在幅度、单位和范围姿态问题上变化很大。在距离计算中,高幅度的特征比低幅度特征权重大。可用特征标准化或Z值归一化解决。导入sklearn.preprocessing库的StandardScalar类。
代码如下: 视频教学QQ群 519970686
1Step1: 导入类库
2
3importnumpyasnp
4importpandasaspd
5
6Step2: 导入数据集
7dataset = pd.read_csv('Data.csv')
8X = dataset.iloc[ : , :-1].values
9Y = dataset.iloc[ : ,3].values
10
11Step3: 处理缺失的数据
12fromsklearn.preprocessingimportImputer
13imputer = Imputer(missing_values ="NaN", strategy ="mean", axis =0)
14imputer = imputer.fit(X[ : ,1:3])
15X[ : ,1:3] = imputer.transform(X[ : ,1:3])
16
17Step4:编码分类数据
18fromsklearn.preprocessingimportLabelEncoder, OneHotEncoder
19labelencoder_X = LabelEncoder()
20X[ : ,0] = labelencoder_X.fit_transform(X[ : ,0])
21Creating a dummy variable
22
23onehotencoder = OneHotEncoder(categorical_features = [0])
24X = onehotencoder.fit_transform(X).toarray()
25labelencoder_Y = LabelEncoder()
26Y = labelencoder_Y.fit_transform(Y)
27
28Step5: 切分数据集成训练数据和测试数据
29fromsklearn.cross_validationimporttrain_test_split
30X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size =0.2, random_state =0)
31
32Step6: 特征缩放
33fromsklearn.preprocessingimportStandardScaler
34sc_X = StandardScaler()
35X_train = sc_X.fit_transform(X_train)
36X_test = sc_X.fit_transform(X_test)