原文链接:The 5 Sampling Algorithms every Data Scientist need to know
简单随机采样
import pandas as pd
df = pd.DataFrame({'val': range(0, 9999)})
sample_df = df.sample(100)
print('df size: %d\nsample df size: %d' %(df.shape[0], sample_df.shape[0]))
df size: 9999
sample df size: 100
分层采样
假设有1000名学生,其中300名是男生,700名是女生。如果从中抽取出100名,可以对1000名随机采样,也可以从男生中选30名,女生中选70名,这就是分层采样。
import numpy as np
def stratified_sampling(data, column, sample_rate):
labels = np.unique(data[column])
print(labels)
sample_data = pd.DataFrame()
for label in labels:
data_with_label = data[data[column] == label]
sample_num = int(round(data_with_label.shape[0] * sample_rate))
sample_data_with_label = data_with_label.sample(sample_num)
sample_data = sample_data.append(sample_data_with_label)
return sample_data
gender = np.append(['male'] * 300, ['female'] * 700)
df = pd.DataFrame({'gender': gender, 'id': range(0, 1000)})
sample_df = stratified_sampling(df, 'gender', 0.1)
print('sample size: %d\nmale: %d\nfemale: %d' %(sample_df.shape[0]\
, sample_df[sample_df['gender'] == 'male'].shape[0]\
, sample_df[sample_df['gender'] == 'female'].shape[0]))
['female' 'male']
sample size: 100
male: 30
female: 70
水库采样
假设有一个未知长度的流数据,只能遍历一遍,如何从中等概率地选出n个元素
基本想法是维护一个n长的列表,在遍历流数据的过程中,以一定的概率将流数据中当前遍历到的元素添加到列表中,或者替换列表中已有的元素。
那么,问题就是,这个“一定的概率”需要是多少,才能保证每个选中的元素都是等概率的。
我们把问题简化一下,假设有一个长度为3的流数据,我们从中选择2个,那么每个元素被选中的概率都是2/3。采用如下的步骤:
- 将第1个元素放入列表元素放入列表
- 将第2个元素放入列表元素放入列表
- 对第3个元素,有2/3的概率被放入列表,并随机替换1或者2,有1/3的概率不被放进列表
第3个元素替换1的概率是1/3,替换2的概率也是1/3,这样,每个元素被选中的概率都是2/3。
import random
def generator(max):
number = 1
while number < max:
number += 1
yield number
# Create as stream generator
stream = generator(1000)
# Doing Reservoir Sampling from the stream
k=5
reservoir = []
for i, element in enumerate(stream):
if i+1<= k:
reservoir.append(element)
else:
probability = 1.0*k/(i+1)
if random.random() < probability:
# Select item in stream and remove one of the k items already selected
reservoir[random.choice(range(0,k))] = element
print(reservoir)
[213, 563, 164, 752, 607]
降采样和过采样
在处理高度不平衡的数据集的时候,经常会用户重采样方法,重采样有降采样和过采样两种。降采样是从样本多的类别中删除样本,过采样是向样本少的类别中添加样本。
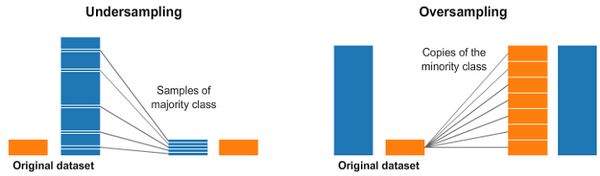
image.png
from sklearn.datasets import make_classification
# create a classifcation dataset
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.99, 0.01],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10
)
X = pd.DataFrame(X)
X['target'] = y
num_0 = len(X[X['target']==0])
num_1 = len(X[X['target']==1])
print(num_0,num_1)
# random undersample
undersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ])
print(len(undersampled_data))
# random oversample
oversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ])
print(len(oversampled_data))
(990, 10)
20
1980
使用 imbalanced-learn 进行降采样和过采样
imbalanced-learn(imblearn)是一个处理非平衡数据集的Python包。
a. 使用 Tomek Links 进行降采样
Tomek Links 是一组从属于不同类别的相邻样本对。我们可以将这些相邻的样本对都删除,来为分类器提供一个更清晰的分类边界。
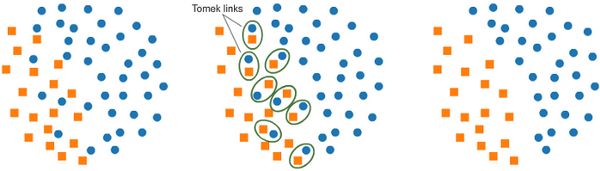
image.png
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. 使用 SMOTE 进行过采样
SMOTE (Synthetic Minority Oversampling Technique) 对样本少的类别合成样本,这些合成的样本位于已有样本的临近位置上。

image.png
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_sample(X, y)
在 imblearn 包中还有其他的算法,比如:
- 降采样:Cluster Centroids, NearMiss 等
- 过采样:ADASYN, bSMOTE 等