一、实验目的
实验对象:豆瓣图书 Top 250 (https://book.douban.com/top250)
实验内容:用scrapy框架编写爬虫,尝试用xpath和css两种方法采集豆瓣图书top250的图书信息,包括标题、作者、一句话短评、评分、图片地址等内容
二、实验过程
1.设计采集流程
采集工作只有一层链接,就是翻页。经过观察,豆瓣该网页翻页的url是有规律的,以25的倍数递增
"https://book.douban.com/top250?start=0"
"https://book.douban.com/top250?start=25"
因此url列表可以这样表示:
url = 'https://book.douban.com/top250?start={}'.format(a*25)
2.分析采集实体的路径
2.1 xpath方法
分析方法:用浏览器开发者工具,定位元素后直接 copy xpath
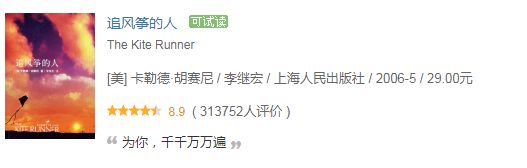
- 每本书的路径: "//[@id="content"]/div/div[1]/div/table"
令 book = response.xpath('//[@id="content"]/div/div[1]/div/table'),则后面的可以表示为: - 标题路径:book.xpath("./tr/td[2]/div[1]/a/@title")
- 评价人数路径:book.xpath("./tr/td[2]/p[2]/span/text()")
其他内容的路径同理,就不详细写了。
2.2 css方法
分析方法:用浏览器开发者工具,定位元素后观察它下方栏的css标签节点

- 每本书的路径:'tr.item'
令 book=response.css('tr.item'),则后面的可以表示为: - 标题路径:book.css('div.pl2 a::text')
- 图片路径:book.css('a.nbg img').xpath('@src')
其它的这里先不详细写。
3.编写爬虫文件 douban.py
先创建爬虫项目,然后在spyder文件夹中新建爬虫文件 douban.py,开始编写爬虫代码。
scrapy startproject douban
3.1 xpath 版本
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class geyan(scrapy.Spider):
name = "douban2"
def start_requests(self):
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
items = []
for book in response.xpath('//*[@id="content"]/div/div[1]/div/table'):
item = DoubanItem()
item['title']=book.xpath("./tr/td[2]/div[1]/a/@title").extract_first().replace('\n', '').strip()
item['score']=book.xpath("./tr/td[2]/div[2]/span[2]/text()").extract_first().replace('\n', '').strip()
item['scrible']=book.xpath("./tr/td[2]/p[2]/span/text()").extract_first().replace('\n', '').strip()
item['num']=book.xpath("./tr/td[2]/div[2]/span[3]/text()").extract_first().strip("(").strip(")").replace('\n', '').strip()
item['img']=book.xpath("./tr/td[1]/a/img/@src").extract_first().replace('\n', '').strip()
items.append(item)
print(items)
return items
3.2 css版本
除了parse函数内的具体采集路径不同,其他部分的代码都跟xpath版本的相同。
def parse(self,response):
items = []
for book in response.css('tr.item'):
item = DoubanItem()
item['title']=book.css('div.pl2 a::text').extract_first().replace('\n', '').strip()
item['score']=book.css('div.star.clearfix span.rating_nums::text').extract_first().replace('\n', '').strip()
item['scrible']=book.css('p.quote span.inq::text').extract_first().replace('\n', '').strip()
item['num']=book.css('div.star.clearfix span.pl::text').extract_first().strip("(").strip(")").replace('\n', '').strip()
item['img']=book.css('a.nbg img').xpath('@src').extract_first().replace('\n', '').strip()
items.append(item)
print(items)
return items
4.修改项目文件 setting.py 和 pipelines.py
4.1 修改setting.py
去掉文件中 ITEM_PIPELINES一行的注释,修改user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
4.2 修改 pipelines.py
在文件中自定义一个类
import codecs
import json
class JsonPipeline(object):
def __init__(self):
self.file = codecs.open('daa.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
5.运行代码
scrapy crawl douban
部分结果如图:

6.存储数据
scrapy crawl douban -o douban.json

三、遇到的问题
1. 403 forbidden:爬虫被禁止访问该网页
解决方案:在setting.py中修改user-agent,伪装成浏览器
谷歌浏览器user-agent的获取方法:在地址栏输入chrome:version,查看用户代理一栏
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
参考链接:http://30daydo.com/article/245
2. 列表越界 IndexError: list index out of range
解决方法:最开始在采集数据时,采集路径后面用的数据处理方法是.extract()[0],改成extract_first()即可
item['title']=book.css('div.pl2 a::text').extract_first()
3. 结果数据处理问题
3.1 采集到的数据带有大量空格、换行符和括号
比如在“num”这一个数据中,带有括号、空格和换行符,可以用replace('\n', '')或者strip()函数处理
item['num']=book.xpath("./tr/td[2]/div[2]/span[3]/text()").extract_first().strip("(").strip(")").replace('\n', '').strip()
3.1采集到的数据进行json格式化