1-2.使用paddlepaddle实现中文场景文字的识别
百度ai studio上常规赛:中文场景文字识别挑战赛经验分享。
比赛链接:常规赛:中文场景文字识别
数据集地址:中文场景文字识别技术创新大赛_数据集
如果想要更好的体验:可以一键运行的项目地址
原论文地址:crnn
对卷积池化这些基础概念不了解的小伙伴可以看之前这篇文章:1-1.使用paddle,构建经典图像分类网络。
说明:该比赛是百度ai studio平台上面的一个常规赛,需要使用飞桨(paddlepaddle)深度学习框架实现(笔者使用paddle1.6版本)。平台有提供gpu算力支持(v100,显存16g/32g),比赛有提供一个基线方案(baseline),选手可以在基线上进行优化。ai studio经常举办许多ai的线上比赛,欢迎小伙伴们去参加,最关键平台有提供丰厚的算力支持,在免费算力面前,框架优势变得可有可无了(手动滑稽)。笔者已经白嫖用了快2000小时算力了。笔者是在官方提供的基线基础上进行优化的,本文将讲解我的代码,在测试集上评分为81左右。

- 一.数据集和比赛介绍:
- 1.数据集介绍
- 2.比赛任务
- 3.评分标准
- 二.方法原理:
- 1.CNN层
- 2.LSTM层(递归层)
- 3.CTC层(转录层)
- 4.总结一下该模型的搭建
- 5.模型的paddle代码实现
- 三.项目实现:
- 1.数据预处理
- 2.定义相关参数
- 3.定义相关数据增强函数
- 4.定义数据读取器
- 5.开始训练
- 6.生成用于预测的模型
- 7.模型预测
一.数据集和比赛介绍:
1.数据集介绍:比赛数据集,共29万张图片,其中21万张图片为训练集(train_img),8万张为测试集(test_img),训练集标注(train.list)。所有图像经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片。
2.比赛任务:要求选手必须使用飞桨对图像区域中的文字行进行预测,返回文字行的内容。
3.评分标准:本任务采用 文字行级别准确率为评价标准只有当预测的文字行与标注文本行完全匹配时视为正确,公式如下:
acc= (hit_count) / (gt_count)
其中,hit_count为与标注文本行完全匹配的预测文字行的数目,gt_count为所有标注文本行的数目。评价指标只在测试集上进行评价。
二.方法原理:模型采用CRNN-CTC结构(CNN+RNN+CTC):先用CNN网络提取图像特征,转化为时间序列再传入RNN网络,最后输出使用CTC层(不同样本的标签序列长度可以不一致)。
结构图:
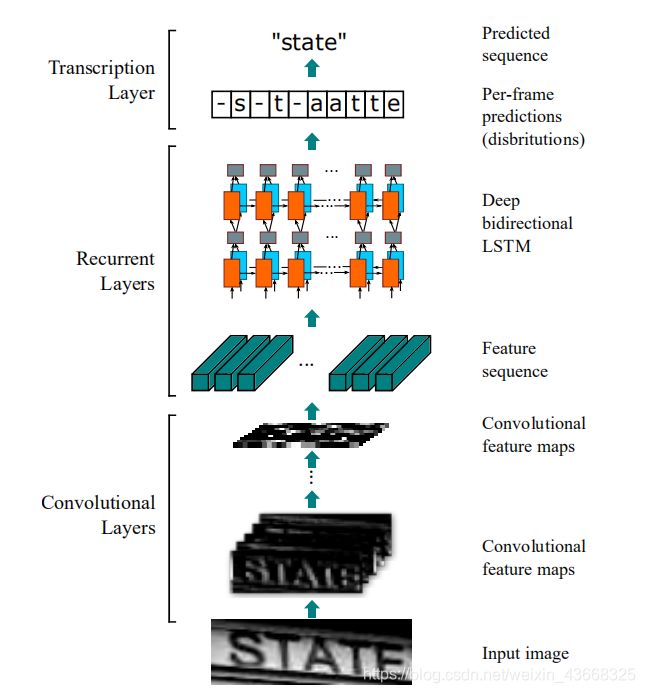
1.CNN层:卷积层的分量是通过从标准CNN模型中提取卷积层和最大池层来构造的(完全连接的层被移除)。 该组件用于从输入图像中提取序列特征表示。 在被输入到网络之前,所有的图像都需要缩放到相同的高度。 然后从卷积层分量产生的特征映射中提取一系列特征向量,这是递归层的输入。

#卷积层的paddle实现
paddle.fluid.layers.conv2d(input, num_filters, filter_size, stride=1, padding=0, dilation=1, groups=None, param_attr=None, bias_attr=None, use_cudnn=True, act=None, name=None, data_format="NCHW")
#最大池化层(最大下采样)的paddle实现
paddle.fluid.layers.pool2d(input, pool_size=-1, pool_type='max', pool_stride=1, pool_padding=0, global_pooling=False, use_cudnn=True, ceil_mode=False, name=None, exclusive=True, data_format="NCHW")
#全链接层的paddle实现
paddle.fluid.layers.fc(input, size, num_flatten_dims=1, param_attr=None, bias_attr=None, act=None, name=None)
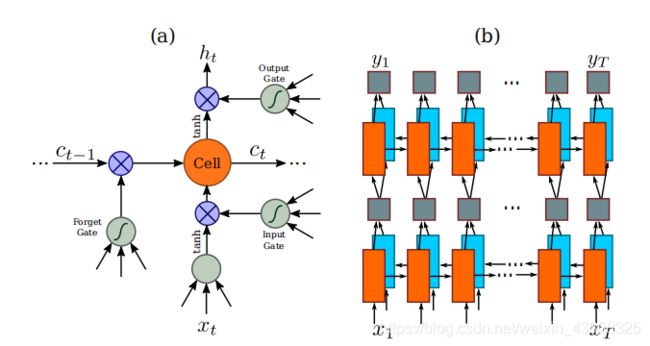
2.LSTM层(递归层):
(a)图是传统的LSTM结构:一个LSTM由一个单元模块和三个门组成,即输入门、输出门和忘记门。
(b)图是论文中使用的结构:深层双向LSTM的结构。 将前向(从左到右)和后向(从右到左)LSTM相结合构成双向LSTM。 堆叠2个双向LSTM构成深层双向LSTM。
我代码实现用的是双层GRU单元(改成LSTM效果可能会更好,可以继续上点分)
#使用GRU单元
paddle.fluid.layers.dynamic_gru(input, size, param_attr=None, bias_attr=None, is_reverse=False, gate_activation='sigmoid', candidate_activation='tanh', h_0=None, origin_mode=False)
#paddle1.6版本也提供了实现LSTM的方法
paddle.fluid.layers.dynamic_lstm(input, size, h_0=None, c_0=None, param_attr=None, bias_attr=None, use_peepholes=True, is_reverse=False, gate_activation='sigmoid', cell_activation='tanh', candidate_activation='tanh', dtype='float32', name=None)
3.CTC层(转录层):
原论文:Transcription is the process of converting the per-frame predictions made by RNN into a label sequence. Mathematically, transcription is to find the label sequence with the highest probability conditioned on the per-frame predictions. In practice, there exists two modes of transcription, namely the lexicon-free and lexicon-based transcriptions. A lexicon is a set of label sequences that prediction is constraint to, e.g. a spell checking dictionary. In lexiconfree mode, predictions are made without any lexicon. In lexicon-based mode, predictions are made by choosing the label sequence that has the highest probability
原论文:转录是将RNN所做的每帧预测转换为标签序列的过程。 从数学上讲,转录是找到基于每帧预测的概率最高的标签序列。 在实践中,存在两种转录模式,即无词典转录和基于词典的转录。 词汇是一组标签序列,预测是对的约束,例如。 拼写检查字典。 在无词汇模式下,预测是在没有任何词汇的情况下进行的。 在基于词汇的模式下,预测是通过选择概率最高的标签序列来进行的。
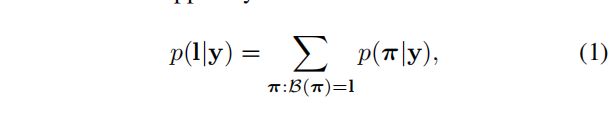
我们是使用第二种:预测通过选择概率最高的标签序列来进行(具体细节可以阅读原文)。
#paddle1.6提供了代码实现
paddle.fluid.layers.ctc_greedy_decoder(input, blank, name=None)
4.现在来总结一下该模型的搭建吧!
具体网络层:
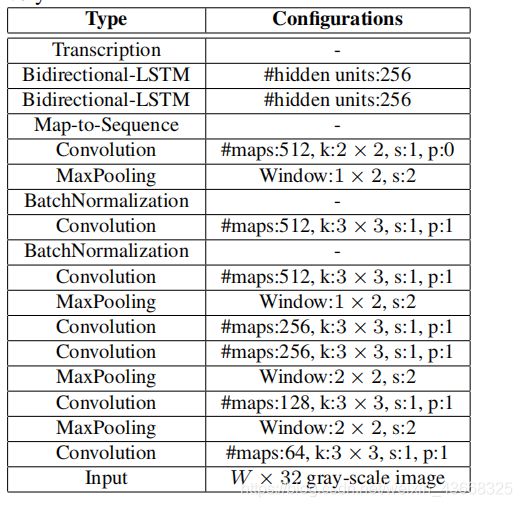
论文中提供的网络层和参数的图片已经很直观了,稍微解释一下(从下往上看):
- 第一层(卷积层):图片(input)经过1层步长为1(s表示),填充为1(p表示)的3x3卷积,过滤器数量为64.
- 第二层(最大池化层):第一层的输出进行2x2的最大池化,步长为2.,以此类推啦
- BatchNormalization表示批归一化:用batch_norm实现
#batch_norm的paddle实现
paddle.fluid.layers.batch_norm(input, act=None, is_test=False, momentum=0.9, epsilon=1e-05, param_attr=None, bias_attr=None, data_layout='NCHW', in_place=False, name=None, moving_mean_name=None, moving_variance_name=None, do_model_average_for_mean_and_var=False, use_global_stats=False)
- Bidirectional-LSTM在论文中为2层的双向LSTM。实现代码中我使用的是2层的GRU单元,读者可以尝试使用LSTM。
注:论文中卷积输出到LSTM输入有自定义了一个层,名为:Map-to-Sequence,我并没有实现。
原文:Back-Propagation Through Time (BPTT). At the bottom of the recurrent layers, the sequence of propagated differentials are concatenated into maps, inverting the operation of converting feature maps into feature sequences, and fed back to the convolutional layers. In practice, we create a custom network layer, called “Map-to-Sequence”, as the bridge between convolutional layers and recurrent layers.
原文:回溯时间(BPTT)。 在递归层的底部,将传播的差分序列连接成映射,将特征映射转换为特征序列的操作倒置,并反馈给卷积层。 在实践中,我们创建了一个自定义网络层,称为“映射到等”,作为卷积层和递归层之间的桥梁。
5.完整的CRNN-CTC模型的paddle代码实现:
import paddle.fluid as fluid
from paddle.fluid import ParamAttr
from paddle.fluid.clip import GradientClipByNorm
from paddle.fluid.regularizer import L2Decay
from paddle.fluid.initializer import MSRA, Normal
from paddle.fluid.layers import conv2d, conv2d_transpose, batch_norm, fc, dynamic_gru, im2sequence, elementwise_mul, \
pool2d, dropout, concat
class CRNN(object):
def __init__(self, num_classes, label_dict):
self.outputs = None
self.label_dict = label_dict
self.num_classes = num_classes#类别数
def name(self):
return 'crnn'
def conv_bn_pool(self, x, n_filters, n_ConvBN, pool_stride, w_conv, is_test):
w_bn = ParamAttr(regularizer=L2Decay(0.0005))#设置L2正则化,初始化权重
b_bn = ParamAttr(regularizer=L2Decay(0.0005), initializer=Normal(0.0, 0.0))
for _ in range(n_ConvBN):
x = conv2d(x, n_filters, 3, 1, 1, param_attr=w_conv)#定义卷积层
#批归一化
x = batch_norm(x, act='relu', param_attr=w_bn, bias_attr=b_bn, is_test=is_test)
assert pool_stride in [2, (2, 1), (3, 1)]#使用断言
if pool_stride == 2:
x = pool2d(x, 2, 'max', pool_stride, 0, ceil_mode=True)#定义池化层,最大池化
elif pool_stride == (2, 1):
x = pool2d(x, (2, 1), 'max', pool_stride, 0, ceil_mode=True)
elif pool_stride == (3, 1):
x = pool2d(x, (3, 1), 'max', pool_stride, 0, ceil_mode=True)
return x
def ocr_convs(self, x, is_test):
w_conv1 = ParamAttr(regularizer=L2Decay(0.0005))
w_conv2 = ParamAttr(regularizer=L2Decay(0.0005))
w_conv3 = ParamAttr(regularizer=L2Decay(0.0005))
x = self.conv_bn_pool(x, 128, 1, 2, w_conv1, is_test)
x = self.conv_bn_pool(x, 256, 1, 2, w_conv2, is_test)
x = self.conv_bn_pool(x, 512, 2, 2, w_conv2, is_test)
x = self.conv_bn_pool(x, 1024, 2, (2, 1), w_conv3, is_test)
return x
def net(self, images, rnn_hidden_size=750, is_test=False):
w_fc = ParamAttr(regularizer=L2Decay(0.0005))
b_fc1 = ParamAttr(regularizer=L2Decay(0.0005), initializer=Normal(0.0, 0.0))
b_fc2 = ParamAttr(regularizer=L2Decay(0.0005), initializer=Normal(0.0, 0.0), learning_rate=2.0)
b_fc3 = ParamAttr(regularizer=L2Decay(0.0005), initializer=Normal(0.0, 0.0))
x = self.ocr_convs(images, is_test)
x = im2sequence(x, (x.shape[2], 1), (1, 1))#用 filter 扫描输入的Tensor并将输入Tensor转换成序列
fc_1 = fc(x, rnn_hidden_size * 3, param_attr=w_fc, bias_attr=b_fc1)#定义全连接层,将cnn层输出处理成序列,用于代入RNN层
fc_2 = fc(x, rnn_hidden_size * 3, param_attr=w_fc, bias_attr=b_fc1)
gru_forward = dynamic_gru(fc_1, rnn_hidden_size, param_attr=w_fc, bias_attr=b_fc2, candidate_activation='relu')#用于在完整序列上逐个时间步的进行单层Gated Recurrent Unit(GRU)的计算
gru_backward = dynamic_gru(fc_2, rnn_hidden_size, param_attr=w_fc, bias_attr=b_fc2, candidate_activation='relu',
is_reverse=True)#使用2层结构
bigru = gru_forward + gru_backward
bigru = dropout(bigru, 0.5, is_test)#使用随机丢弃单元的正则化方法
fc_out = fc(bigru, self.num_classes + 1, param_attr=w_fc, bias_attr=b_fc3)#全连接层
self.outputs = fc_out
return fc_out
def get_infer(self, images):#CTC转录层
return fluid.layers.ctc_greedy_decoder(input=self.outputs, blank=self.num_classes)
三.项目实现:
1.数据预处理(baseline中提供,笔者对此做了微调):增加了2倍训练数据、色度、旋转角度等调整。
(1).定义将繁体字转化为简体字的类:
class Converter(object):
def __init__(self, to_encoding):
self.to_encoding = to_encoding
self.map = MAPS[to_encoding]
self.start()
def feed(self, char):
branches = []
for fsm in self.machines:
new = fsm.feed(char, self.map)
if new:
branches.append(new)
if branches:
self.machines.extend(branches)
self.machines = [fsm for fsm in self.machines if fsm.state != FAIL]
all_ok = True
for fsm in self.machines:
if fsm.state != END:
all_ok = False
if all_ok:
self._clean()
return self.get_result()
def _clean(self):
if len(self.machines):
self.machines.sort(key=lambda x: len(x))
# self.machines.sort(cmp=lambda x,y: cmp(len(x), len(y)))
self.final += self.machines[0].final
self.machines = [StatesMachine()]
def start(self):
self.machines = [StatesMachine()]
self.final = UEMPTY
def end(self):
self.machines = [fsm for fsm in self.machines
if fsm.state == FAIL or fsm.state == END]
self._clean()
def convert(self, string):
self.start()
for char in string:
self.feed(char)
self.end()
return self.get_result()
def get_result(self):
return self.final
(2).数据预处理:
import codecs
import random
import sys
from os.path import join as pjoin
#函数 read_ims_list:读取train.list文件,生成图片的信息字典
def read_ims_list(path_ims_list):
"""
读取 train.list 文件
"""
ims_info_dic = {}
with open(path_ims_list, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split(maxsplit=3)
w, h, file, label = parts[0], parts[1], parts[2], parts[3]
ims_info_dic[file] = {'label': label, 'w': int(w)}
return ims_info_dic
#函数 modify_ch:对标签label进行修改,进行四项操作,分别是“繁体->简体”、“大写->小写”、“删除空格”、“删除符号”。
def modify_ch(label):
# 繁体 -> 简体
label = Converter("zh-hans").convert(label)
# 大写 -> 小写
label = label.lower()
# 删除空格
label = label.replace(' ', '')
# 删除符号
for ch in label:
if (not '\u4e00' <= ch <= '\u9fff') and (not ch.isalnum()):
label = label.replace(ch, '')
return label
#函数 pipeline:调用定义的函数,对训练数据进行初步处理。
def pipeline(dataset_dir):
path_ims = pjoin(dataset_dir, "train_images")
path_ims_list = pjoin(dataset_dir, "train.list")
path_train_list = pjoin(dataset_dir, "train.txt")
path_label_list = pjoin(dataset_dir, "label_list.txt")
# 读取数据信息
file_info_dic = read_ims_list(path_ims_list)
# 创建 train.txt
class_set = set()
with codecs.open(path_train_list, 'w', encoding='utf-8') as f:
for file, info in file_info_dic.items():
label = info['label']
label = modify_ch(label)
# 异常: 标签为空
if label == '':
continue
for e in label:
class_set.add(e)
f.write("{0}\t{1}\n".format(pjoin(path_ims, file), label))
# 创建 label_list.txt
class_list = list(class_set)
class_list.sort()
print("class num: {0}".format(len(class_list)))
with codecs.open(path_label_list, "w", encoding='utf-8') as label_list:
for id, c in enumerate(class_list):
label_list.write("{0}\t{1}\n".format(c, id))
random.seed(0)
pipeline(dataset_dir="data/data10879")
2.设置后面需要用到的参数:
train_opt = {
"input_size": [1, 48, 256],#输入图片大小
"data_dir": "data/data10879",#图片路径
"train_dir": "train_images",#训练集位置
"train_list": "train.txt",#训练集list文件,内含具体图片文件名
"label_list": "label_list.txt",#训练集标注文件
"class_dim": -1,#分类数
"label_dic": {},
"n_im": -1,
"continue_train": True,#是否加载训练好的模型
#"continue_train": False,#是否加载训练好的模型
"save_model_dir": "work/crnn_model",#模型保存路径
"num_epochs": 80,#训练轮数
"train_batch_size": 256,#batch_size大小
"mean_color": 127.0,
"multi_data_reader_count": 8,
"apply_distort": True,
#数据增强参数配置
"image_distort_strategy": {
"expand_prob": 0.3,
"expand_max_ratio": 2.0,
"hue_prob": 0.5,
"hue_delta": 48,
"contrast_prob": 0.5,
"contrast_delta": 0.5,
"saturation_prob": 0.5,
"saturation_delta": 0.5,
"brightness_prob": 0.5,
"brightness_delta": 0.5,
},
#训练优化器配置
"optimizer_strategy": {
"learning_rate": 0.001,#学习率
"momentum": 0.9,
#"lr_epochs": [40, 80],#将学习率按训练轮数分段,0-40,40-80,80-120
#"lr_decay": [1, 0.5, 0.1],#按分段学习率乘以该比率
"lr_epochs": [20,40 ],#学习率衰减epoch的位置
"lr_decay": [1, 0.5, 0.1],#每一次衰减的步幅
},
}
3.定义相关的的数据增强函数:
import numpy as np
import random
import cv2 as cv
from PIL import Image, ImageEnhance, ImageDraw
def resize_img(img, input_size):#调整图片大小
target_size = input_size
percent_h = float(target_size[1]) / img.size[1]
percent_w = float(target_size[2]) / img.size[0]
percent = min(percent_h, percent_w)
resized_width = int(round(img.size[0] * percent))
resized_height = int(round(img.size[1] * percent))
w_off = (target_size[2] - resized_width) / 2
h_off = (target_size[1] - resized_height) / 2
img = img.resize((resized_width, resized_height), Image.ANTIALIAS)
array = np.ndarray((target_size[1], target_size[2], 3), np.uint8)
array[:, :, 0] = 127
array[:, :, 1] = 127
array[:, :, 2] = 127
ret = Image.fromarray(array)
ret.paste(img, (np.random.randint(0, w_off + 1), int(h_off)))
return ret
def random_brightness(img):#随机调整亮度,进行数据增强
prob = np.random.uniform(0, 1)
if prob < train_opt['image_distort_strategy']['brightness_prob']:
brightness_delta = train_opt['image_distort_strategy']['brightness_delta']
delta = np.random.uniform(-brightness_delta, brightness_delta) + 1
img = ImageEnhance.Brightness(img).enhance(delta)
return img
def random_contrast(img):#随机调整对比度,进行数据增强
prob = np.random.uniform(0, 1)
if prob < train_opt['image_distort_strategy']['contrast_prob']:
contrast_delta = train_opt['image_distort_strategy']['contrast_delta']
delta = np.random.uniform(-contrast_delta, contrast_delta) + 1
img = ImageEnhance.Contrast(img).enhance(delta)
return img
def random_saturation(img):#随机调整饱和度,进行数据增强
prob = np.random.uniform(0, 1)
if prob < train_opt['image_distort_strategy']['saturation_prob']:
saturation_delta = train_opt['image_distort_strategy']['saturation_delta']
delta = np.random.uniform(-saturation_delta, saturation_delta) + 1
img = ImageEnhance.Color(img).enhance(delta)
return img
def random_hue(img):#随机调整色相,进行数据增强
prob = np.random.uniform(0, 1)
if prob < train_opt['image_distort_strategy']['hue_prob']:
hue_delta = train_opt['image_distort_strategy']['hue_delta']
delta = np.random.uniform(-hue_delta, hue_delta)
img_hsv = np.array(img.convert('HSV'))
img_hsv[:, :, 0] = img_hsv[:, :, 0] + delta
img = Image.fromarray(img_hsv, mode='HSV').convert('RGB')
return img
def distort_image(img):#将上述数据增强手段整合,施加到训练样本上
prob = np.random.uniform(0, 1)
# Apply different distort order
if prob > 0.5:
img = random_brightness(img)
img = random_contrast(img)
img = random_saturation(img)
img = random_hue(img)
else:
img = random_brightness(img)
img = random_saturation(img)
img = random_hue(img)
img = random_contrast(img)
return img
def rotate_image(img):#随机旋转图片,进行数据增强
"""
图像增强,增加随机旋转角度
"""
prob = np.random.uniform(0, 1)
if prob > 0.:
angle = np.random.randint(-8, 8)
img = img.convert('RGBA')
img = img.rotate(angle, resample=Image.BILINEAR, expand=0)
fff = Image.new('RGBA', img.size, (127, 127, 127, 127))
img = Image.composite(img, fff, mask=img).convert('RGB')
return img
def rotate_image_0(img):
"""
图像增强,增加随机旋转角度
"""
prob = np.random.uniform(0, 1)
if prob > 0.:
angle = np.random.randint(-10, 10)
img = img.convert('RGBA')
img = img.rotate(angle, resample=Image.BILINEAR, expand=0)
fff = Image.new('RGBA', img.size, (127, 127, 127, 127))
img = Image.composite(img, fff, mask=img).convert('RGB')
return img
def random_expand(img, keep_ratio=True):#随机改变图片大小,进行数据增强
if np.random.uniform(0, 1) < train_opt['image_distort_strategy']['expand_prob']:
return img
max_ratio = 1.3 # train_opt['image_distort_strategy']['expand_max_ratio']
w, h = img.size#图像尺寸
c = 3
ratio_x = random.uniform(1, max_ratio)
if keep_ratio:
ratio_y = ratio_x
else:
ratio_y = random.uniform(1, max_ratio)
oh = int(h * ratio_y)
ow = int(w * ratio_x)
off_x = random.randint(0, ow - w)
off_y = random.randint(0, oh - h)
out_img = np.zeros((oh, ow, c), np.uint8)
for i in range(c):
out_img[:, :, i] = train_opt['mean_color']
out_img[off_y: off_y + h, off_x: off_x + w, :] = img
return Image.fromarray(out_img)
def random_expand_0(img,keep_ratio=True):
if np.random.uniform(0, 1) < 0 :#train_opt['image_distort_strategy']['expand_prob']:
return img
#max_ratio = train_opt['image_distort_strategy']['expand_max_ratio']
w, h = img.size
c = 3
ratio_x = random.uniform(1, 2)
if keep_ratio:
ratio_y = ratio_x
else:
ratio_y = random.uniform(1, 2)
oh = int(h * ratio_y)
ow = int(w * ratio_x)
off_x = random.randint(0, ow - w)
off_y = random.randint(0, oh - h)
out_img = np.zeros((oh, ow, c), np.uint8)
for i in range(c):
out_img[:, :, i] = train_opt['mean_color']
out_img[off_y: off_y + h, off_x: off_x + w, :] = img
return Image.fromarray(out_img)
def preprocess(img, input_size):
img_width, img_height = img.size
if train_opt['apply_distort']:
img = distort_image(img)
img_m = np.mean(img.convert('L'))
img_std = max(np.std(img.convert('L')), 1e-2)
img = resize_img(img, input_size)
img = img.convert('L')
img = (np.array(img).astype('float32') - img_m) / img_std
return img
def preprocess_0(img, input_size):
img_width, img_height = img.size
if train_opt['apply_distort']:
img = distort_image(img)
img_m = np.mean(img.convert('L'))
img_std = max(np.std(img.convert('L')), 1e-2)
if train_opt['apply_distort']:
img = random_expand_0(img)
img = rotate_image_0(img)
img = resize_img(img, input_size)
img = img.convert('L')
img = (np.array(img).astype('float32') - img_m) / img_std
return img
4.定义数据读取器,调用数据增强方法读取数据:
import math
import os
import paddle
import numpy as np
from PIL import Image, ImageEnhance, ImageDraw
#定义数据读取器
def custom_reader(file_list, input_size, mode):
def reader():
for i in [1,2]:
np.random.shuffle(file_list)
for line in file_list:
parts = line.split()
image_path = parts[0]
img = Image.open(image_path)
if img.mode != 'RGB':
img = img.convert('RGB')
label = [int(train_opt['label_dic'][c]) for c in parts[-1]]
if len(label) == 0:
continue
if i == 1:
img = preprocess(img, input_size)
else:
img = preprocess_0(img, input_size)
img = img[np.newaxis, ...]
yield img, label
return reader
#将custom_reader封装成多进程数据读取器,提高读取效率
def multi_process_custom_reader(file_path, data_dir, num_workers, input_size, mode):
file_path = os.path.join(data_dir, file_path)
readers = []
images = [line.strip() for line in open(file_path, encoding='utf-8')]
np.random.shuffle(images)#打乱序列,洗牌
n = int(math.ceil(len(images) / num_workers))#图片数/4,然后向上取整数
image_lists = [images[i: i + n] for i in range(0, len(images), n)]#将图片等分4份
#增加一倍的数据集
for l in image_lists:
reader = paddle.batch(custom_reader(l, input_size, mode),
batch_size=train_opt['train_batch_size'])#将每64个数据放到一个列表中
readers.append(paddle.reader.shuffle(reader, train_opt['train_batch_size']))
return paddle.reader.multiprocess_reader(readers, False)
5.训练模型:
- 函数 init_log_config:初始化日志记录功能
- 函数 init_train_parameters:初始化训练参数
- 函数 optimizer_setting:设置优化器,优化器采用Adam
- 函数 build_train_program_with_async_reader:创建训练程序
- 函数 load_pretrained_params:加载预训练模型
- 函数 train:开始训练
import os
import numpy as np
import time
import math
import random
import paddle.fluid as fluid
import logging
import codecs
import sys
from os.path import join as pjoin
from paddle.fluid.layers import piecewise_decay, ctc_greedy_decoder, cast, edit_distance, warpctc, reduce_sum, create_py_reader_by_data
from paddle.fluid.regularizer import L2Decay
from paddle.fluid.optimizer import ModelAverage, Momentum, Adam
logger = None
def init_log_config():
global logger
logger = logging.getLogger()
logger.setLevel(logging.INFO)
log_path = pjoin('work', 'logs')
if not os.path.exists(log_path):
os.makedirs(log_path)
log_name = pjoin(log_path, 'train.log')
sh = logging.StreamHandler()
fh = logging.FileHandler(log_name, mode='w')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
sh.setFormatter(formatter)
logger.addHandler(sh)
logger.addHandler(fh)
def init_train_parameters():
"""
初始化训练参数,主要是初始化图片数量,字典
"""
path_train_list = pjoin(train_opt['data_dir'], train_opt['train_list'])
path_label_list = pjoin(train_opt['data_dir'], train_opt['label_list'])
with codecs.open(path_train_list, encoding='utf-8') as f:
lines = [line.strip() for line in f]
train_opt['n_im'] = len(lines)#获取训练集长度,即图片张数
with codecs.open(path_label_list, encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
train_opt['label_dic'][parts[0]] = int(parts[1])#读取汉字、字符和对应的编号
train_opt['class_dim'] = len(train_opt['label_dic'])#存储汉字、字符长度
def optimizer_setting():
batch_size = train_opt["train_batch_size"]
iters = train_opt["n_im"] # batch_size
learning_strategy = train_opt['optimizer_strategy']
lr = learning_strategy['learning_rate']
boundaries = [i * iters for i in learning_strategy["lr_epochs"]]
values = [i * lr for i in learning_strategy["lr_decay"]]
optimizer = Adam(
learning_rate=piecewise_decay(boundaries, values),#对学习率分段衰减
regularization=L2Decay(0.1),#增加正则化参数缓解过拟合问题,原为0.1
beta1=0.9
)
return optimizer
def build_train_program_with_async_reader(main_prog, startup_prog):
with fluid.program_guard(main_prog, startup_prog):
img = fluid.layers.data(name='img', shape=train_opt['input_size'], dtype='float32')
gt_label = fluid.layers.data(name='gt_label', shape=[1], dtype='int32', lod_level=1)
data_reader = create_py_reader_by_data(capacity=train_opt['train_batch_size'],
feed_list=[img, gt_label],
name='train')
multi_reader = multi_process_custom_reader(train_opt['train_list'],
train_opt['data_dir'],
train_opt['multi_data_reader_count'],
train_opt['input_size'],
'train')
data_reader.decorate_paddle_reader(multi_reader)
with fluid.unique_name.guard():
img, gt_label = fluid.layers.read_file(data_reader)
model = CRNN(train_opt['class_dim'], train_opt['label_dic'])
fc_out = model.net(img)
cost = warpctc(fc_out, gt_label, blank=train_opt['class_dim'], norm_by_times=True)
loss = reduce_sum(cost)
optimizer = optimizer_setting()
optimizer.minimize(loss)
model_average = ModelAverage(0.15, 10000, 12500)
decoded_out = ctc_greedy_decoder(fc_out, blank=train_opt['class_dim'])
casted_label = cast(gt_label, dtype='int64')
distances, seq_num = edit_distance(decoded_out, casted_label)
return data_reader, loss, model_average, distances, seq_num, decoded_out
def load_pretrained_params(exe, program):
if train_opt['continue_train']:
logger.info('load param from retrain model')
#fluid.io.load_persistables(executor=exe, dirname=train_opt['save_model_dir'], main_program=program)#训练好的模型的参数w,b,用于分断训练,参数目前是false
#fluid.io.load_persistables(executor=exe, dirname='data/data10879/crnn_model', main_program=program)#训练好的模型的参数w,b,用于分断训练,参数目前是false
fluid.io.load_persistables(executor=exe, dirname='data/data42037/home/aistudio/work/crnn_model', main_program=program)#训练好的模型的参数w,b,用于分断训练,参数目前是false
def train():
logger.info("build network and program")
train_program = fluid.Program()
start_program = fluid.Program()
train_reader, loss, model_avg, distances, seq_num, decoded_out = build_train_program_with_async_reader(train_program, start_program)
logger.info("build executor and init params")
exe = fluid.Executor(fluid.CUDAPlace(0))
exe.run(start_program)
train_fetch_list = [loss.name, distances.name, seq_num.name, decoded_out.name]
load_pretrained_params(exe, train_program)
total_batch_count = 0
current_best_accuracy = 0.10
distance_evaluator = fluid.metrics.EditDistance("edit-distance")
for epoch in range(train_opt["num_epochs"]):
logger.info("current epoch: %d, start read image", epoch)
batch_id = 0
train_reader.start()
distance_evaluator.reset()
loss_mean = 0
try:
while True:
t1 = time.time()
loss, distances, seq_num, decoded_out = exe.run(train_program, fetch_list=train_fetch_list,
return_numpy=False)
loss = np.mean(np.array(loss))
distances = np.array(distances)
seq_num = np.array(seq_num)
distance_evaluator.update(distances, seq_num)
period = time.time() - t1
batch_id += 1
total_batch_count += 1
loss_mean = loss_mean + loss #loss平均值
if batch_id % 200 == 0:#打印训练结果
with model_avg.apply(exe):
distance, instance_error = distance_evaluator.eval()
logger.info("Epoch {0}, trainbatch {1}, loss {2} distance {3} instance error {4} time {5}"
.format(epoch, batch_id, loss, distance, instance_error, "%2.2f sec" % period))
except fluid.core.EOFException:
train_reader.reset()
with model_avg.apply(exe):
logger.info("loss_mean:{0}".format(loss_mean/batch_id))
distance, instance_error = distance_evaluator.eval()
logger.info("Epoch {0} distance {1} instance error {2}".format(epoch, distance, instance_error))
current_accuracy = 1.0 - instance_error
if current_accuracy >= current_best_accuracy:
with model_avg.apply(exe):
logger.info("temp save pass {0} train result, current bset accuracy {1}".format(epoch, 1.0 - instance_error))
current_best_accuracy = current_accuracy
fluid.io.save_persistables(dirname=train_opt['save_model_dir'], main_program=train_program, executor=exe)#训练好的模型存储位置
logger.info("training till last, end training")
init_log_config()
init_train_parameters()
train()
这是大约训练了50个epoch后,然后重新加载第50个epoch训练好的参数,继续训练。也就是训练50个epoch平均loss为900多,在单卡v100的gpu上训练,大概15个小时左右,基本上收敛,继续训练容易过拟合。(一开始的loss为9000多,batch_size为256)。

6.freeze模型:生成模型:
import os
import codecs
import paddle.fluid as fluid
# 读取 label_list.txt 文件获取类别数量
class_dim = -1
all_file_dir = "data/data10879"
with codecs.open(os.path.join(all_file_dir, "label_list.txt")) as label_list:
class_dim = len(label_list.readlines())
target_size = [1, 48, 1024]
save_freeze_dir = "work/crnn_model"#读取训练好的模型参数
def freeze_model():
exe = fluid.Executor(fluid.CPUPlace())
image = fluid.layers.data(name='image', shape=target_size, dtype='float32')
model = CRNN(class_dim, {})
pred = model.net(image)
out = model.get_infer(image)
freeze_program = fluid.default_main_program()
fluid.io.load_persistables(exe, save_freeze_dir, freeze_program)
freeze_program = freeze_program.clone(for_test=True)
fluid.io.save_inference_model("work/freeze_model", ['image'], out, exe, freeze_program)
freeze_model()
7.模型预测:
- 函数 init_eval_parameters:初始化预测参数
- 函数 resize_img:调整图片大小
- 函数 read_image:读取图片并做相应处理
- 函数 infer:对单张图片进行文字识别
- 函数 eval_all:对所有图片进行识别,并生成predict.txt
import os
from os.path import join as pjoin
import numpy as np
import time
import codecs
import shutil
import math
import cv2 as cv
import paddle.fluid as fluid
from functools import reduce
from tqdm import tqdm
from PIL import Image, ImageEnhance
from work.langconv import Converter
target_size = [1, 48, 512]
mean_rgb = 127.0
data_dir = 'data/data10879'
label_list = "label_list.txt"
use_gpu = True
label_dict = {}
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
exe = fluid.Executor(place)
save_freeze_dir = "work/freeze_model"
[inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(dirname=save_freeze_dir,
executor=exe)
def init_eval_parameters():
"""
初始化预测参数
"""
label_list_path = pjoin(data_dir, label_list)
with codecs.open(label_list_path, encoding='utf-8') as flist:
lines = [line.strip() for line in flist]
for line in lines:
parts = line.split()
label_dict[int(parts[1])] = parts[0]
def resize_img(img):
w, h = img.size
target_size[2] = math.ceil(w / 16) * 16
percent_h = float(target_size[1]) / img.size[1]
percent_w = float(target_size[2]) / img.size[0]
percent = min(percent_h, percent_w)
resized_width = int(round(img.size[0] * percent))
resized_height = int(round(img.size[1] * percent))
w_off = (target_size[2] - resized_width) / 2
h_off = (target_size[1] - resized_height) / 2
img = img.resize((resized_width, resized_height), Image.ANTIALIAS)
array = np.ndarray((target_size[1], target_size[2]), np.uint8)
array[:, :] = 127
ret = Image.fromarray(array)
ret.paste(img, (int(w_off), int(h_off)))
return ret
def read_image(img_path):
img = Image.open(img_path)
img = img.convert('L')
img_m = np.mean(img.convert('L'))
img_std = max(np.std(img.convert('L')), 1e-2)
img = resize_img(img)
img = (np.array(img).astype('float32') - img_m) / img_std
img = img[..., np.newaxis]
img = img.transpose((2, 0, 1))
img = img[np.newaxis, :]
return img
def infer(image_path):
tensor_img = read_image(image_path)
label = exe.run(inference_program, feed={feed_target_names[0]: tensor_img}, fetch_list=fetch_targets,
return_numpy=False)
label = np.array(label[0])
ret = ""
if label[0] != -1:
ret = ret.join([label_dict[int(c[0])] for c in label])
return ret
def eval_all():
predict = codecs.open(pjoin(data_dir, 'predict.txt'), 'w')
files = [file for file in os.listdir(pjoin(data_dir, 'test_images')) if file.endswith('.jpg')]
files = sorted(files)
for file in tqdm(files):
path_file = pjoin(data_dir, 'test_images', file)
result = infer(path_file)
predict.write('{0}\t{1}\n'.format(file, result))
init_eval_parameters()
eval_all()
训练结束后就可以预测结果啦!