因为我们发布或者推广的渠道不同,就造成了我们的Android App可能会有很多个,因为我们需要细分他们,才能针对不同的渠道做不同的处理,比如统计跟踪、是否升级、App名字是否一致等等。尤其在国内这个各种应用市场百家争鸣的时代,我们需要发布的App渠道甚至多个好几百个,而且各有各的特殊处理,所以这就更需要我们有一套自动的满足多渠道构建的工具来帮我们解决这个问题,有了Android Gradle的Flavor后,我们就可以完美的解决以上问题,并且可以实现批量自动化。这一章主要介绍多渠道构建的基本原理,然后使用Flurry和友盟这两个最常用的分析统计平台作为例子来演示多渠道构建,接着我们介绍下Flavor的每个配置的用法,让大家可以根据需求定制自己的每个渠道,最后我们会介绍一种快速打包上百个渠道的方法,以提高多渠道构建的效率。
11.1 多渠道构建的基本原理
在Android Gradle中,定义了一个叫Build Variant的概念,直译是构建变体,我喜欢叫它为构件-构建的产物(Apk),一个Build Variant=Build Type+Product Flavor,Build Type就是我们构建的类型,比如release和debug,Product Flavor就是我们构建的渠道,比如baidu,google等等,他们加起来就是baiduRelease,baiduDebug,googleRelease,googleDebug,共有这几种组合的构件产出,Product Flavor也就是我们多渠道构建的基础,下面我们看看如何新增一个Product Flavor。

Android Gradle为我们提供了productFlavors方法来添加不同的渠道,它接受域对象类型的ProductFlavor闭包作为其参数,前面章节我们在介绍Build Type的时候也介绍过域对象,所以我们可以为productFlavors{}闭包添加很多的渠道,每一个都是一个ProductFlavor类型的渠道,在NamedDomainObjectContainer中的名字就是渠道名,比如baidu,google等。

以上的渠道配置之后,Android Gradle就会生成很多Task,基本上都是基于Build Type+Product Flavor的方式生成的,比如assembleBaidu,assembleRelease,assembleBaiduRelease等等,assemble开头的负责生成构件产物(Apk),比如assembleBaidu运行之后会生成baidu渠道的release和debug包;assembleRelease运行后会生成所有渠道的release包;而assembleBaiduRelease运行后只会生成baidu的release包。除了assemble系列的,还有compile系列的、install系列的等等,大家可以通过运行./gradlew tasks来查看有哪些任务。除了生成的Task之外,每个ProductFlavor还可以有自己的SourceSet,还可以有自己的Dependencies依赖,这意味着什么,意味着我们可以为每个渠道定义他们自己的资源、代码以及依赖的第三方库,这为我们自定义每个渠道提供很大的便利和灵活性,后面的11.3小节的多渠道定制我们会详细介绍这部分内容。
11.2 Flurry多渠道和友盟多渠道构建
Flurry和友盟是我们常用的两个App统计分析工具,基本上所有的软件都会接入其中的一个。Flurry本身没有渠道的概念,它有Application,所以可以把一个Application当成一个渠道,这样就可以使用Flurry统计每个渠道的活跃新增等情况;友盟本身有渠道的概念,只要我们在AndroidManifest.xml配置标注即可,下面以这两种统计演示下多渠道的用法。
Flurry的统计是以Application划分渠道的,每个Application都有一个Key,我们称之为Flurry Key,这个当我们在Flurry上创建Application的时候就自动帮我们生成好了,现在我们要做的就是为每个渠道配置不同的Flurry Key,还记得我们在第九章讲的自动已BuildConfig吗,利用的就是这个功能。

这样每个渠道的BuildConfig类中都有会有名字为FLURRY_KEY常量定义,它的值是我们在渠道中使用buildConfigField指定的值,每个渠道都不一样,这样我们只需要在代码中使用这个常量即可,这样每个渠道的统计分析就可以做到了。
`Fluury.init(this, FLUURY_KEY);
友盟的话,本身是有渠道的概念,不过它不是在代码中指定的,而是在AndroidManifest.xml中配置的,通过配置meta-data标签来设置。`
示例中的Channel ID就是我们的渠道值,比如baidu,google等。如果我们就动态的改变的,就需要用到我们在9.5小结讲到的manifestPlaceholders,这一小节就是以友盟的多渠道为例进行讲解的,大家可以再回过头来看一下,这里不在进行详细讲了。
现在通过这两个例子我们可以发现,我们所做的其实就是对每个渠道,根据不同的业务进行不同的定制,这里是两个统计分析,以后可能还有其他监控、推送等业务,在定制的过程中我们用到了Android Gradle提供的不同的配置以及功能,最终来达到我们的目的,所以下一节我们就详细的讲下对渠道(ProductFlavor)的定制,然后大家根据这些Android Gradle提供的对渠道定制的功能,来实现自己不同渠道的业务需求。
11.3 多渠道构建定制
多渠道的定制,其实就是对Android Gradle插件的ProductFlavor的配置,通过配置ProductFlavor达到我们灵活细化的控制每一个渠道的目的。
Flavor这个单词比较有意思,看字面意思是气味、味道的意思,所以ProductFlavor也就是产品的气味或者味道,多种不同的产品味道,就是我们所说的多渠道了。多渠道这个国内特色,特别多的渠道,如果你的App不出海的话,所以针对国内这些渠道就好了,如果要出海,要再加上出海的国外的渠道。
11.3.1 applicationId
它是ProductFlavor的属性,用于设置该渠道的包名,如果你的App想为该渠道设置特别的包名,可以使用applicationId这个属性进行设置。

如上示例,就可以为google这个渠道设置其特有的包名,这样打包的时候google渠道使用的是org.flysnow.app.example112.google这个包名,而其他渠道使用的是org.flysnow.app.example112这个包名。看下它的方法原型实现

很明显可以看到是setter方法,接受一个字符串作为参数,作为该渠道的新包名。
11.3.2 consumerProguardFiles
即使一个属性,也有一个同名的方法,它只对Android库项目有用,当我们发布库项目生成一个AAR包的时候,使用consumerProguardFiles配置的混淆文件列表也会被打包到AAR里一起发布,这样当应用项目引用这个AAR包、并且启用混淆的时候,会自动的使用AAR包里的混淆文件对AAR包里的代码进行混淆,这样我们就不用对该AAR包进行混淆配置了,因为它自带了。

和我们前面讲的配置混淆是一样的方式,可以指定多个,使用逗号分开。

从源代码中也可可以看出有两种设置方式,一种是我们刚刚演示的方法,另外一种是属性设置,他们两个的区别在于:consumerProguardFiles方法是一直添加的,不会清空以前的混淆文件,而consumerProguardFiles属性配置的方式是每次都是新的混淆文件列表,以前配置的会先被清空。
11.3.3 manifestPlaceholders
这个属性已经在9.5节介绍过,这里不像细讲,大家可以再翻看9.5小节熟悉一下。
11.3.4 multiDexEnabled
这个属性用来启用多个dex的配置,主要用来突破65535方法的问题,大家可以参考9.11一节的介绍,这里不再详细表述。
11.3.5 proguardFiles
混淆使用的文件配置,可以参考8.3一节里关于混淆的讲解,这里不再详述。
11.3.6 signingConfig
签名配置,请参考8.2配置签名信息一节,这里不再详述。
11.3.7 testApplicationId
我们一般都会对Android进行单元测试,这个单元测试有自己的专门的Apk测试包,testApplicationId是用来适配测试包的包名的,它的使用方法和我们前面介绍的applicationId一样。

一般的testApplicationId的值为App的包名+.test,当然大家也可以设置其他的。

它是一个属性,自然也是有setter方法的,源代码可以看到,接受一个String类型的值作为参数。
11.3.8 testFunctionalTest和testHandleProfiling
也是和单元测试有关,Boolean型属性,testFunctionalTest表示是否是功能测试,testHandleProfiling表示是否启用分析功能。

Boolean型,true和false两个选择,示例表示作为功能测试并且启用了分析功能。

以上是这两个属性的源代码配置,他们主要用来控制测试包生成的AndroidManifest.xml,因为他们最终的配置还要体现在AndroidManifest.xml文件中的instrumentation标签的配置上。可以参考
http://developer.android.com/intl/zh-cn/guide/topics/manifest/instrumentation-element.html
11.3.9 testInstrumentationRunner
用来配置运行测试使用的Instrumentation Runner的类名,是一个全路径的类名,而且必须是android.app.Instrumentation的子类,一般情况下,我们使用android.test.InstrumentationTestRunner,当然也可以自定义,根据自己的需求。

和其他的属性的配置一样直接配置即可,接受一个字符串类型的参数,值为android.app.Instrumentation子类的全限定路径的类名。
11.3.10 testInstrumentationRunnerArguments
这个是配合着上一个属性用的,它用来配置Instrumentation Runner使用的参数,其实他们最终使用的都是adb shell am instrument这个命令,参数就是我们使用-e标记指定的那些,所以这里使用testInstrumentationRunnerArguments参数都会被转换传递给am instrument这个命令使用,也就是转为-e key value -e key value这种命令行的方式使用。

我们可以使用示例中的方法指定很多个参数,从使用上我们也可以看出,它是一个Map
http://developer.android.com/intl/zh-cn/tools/testing/testing_otheride.html

11.3.11 versionCode和versionName
配置渠道的版本号和版本名称,详情参考8.1.4和8.1.5两个小节。
11.3.12 useJack
Boolean类型的属性,用于标记是否启用Jack和Jill这个全新的、高性能的编译器。目前我们使用的是常规的成熟的Android编译框架,这个有个问题,就是太慢,所以Google他们又搞了一个全新的、高性能的编译器,这个就是Jack和Jill,目的就是简化编译的流程,提高编译的速度和性能,不过目前他们还处于实验阶段,有写特性还不支持,比如注解,比如JDK8的特性等等,大家可以自己测试用用,但是正式产品种还是不要使用。要启用Jack编译非常简单,只需要设置useJack为true即可,默认是false。

这样即可启用,如上示例其实调用的是useJack这个方法,我们看下它的源代码

如果你想使用属性setter的方式,可以直接用=赋值。

他们的结果是一样的,但是一般我们都是使用方法,这样看着比较优雅。关于Jack和Jill这种编译方式有兴趣的话,可以参考
http://tools.android.com/tech-docs/jackandjill。
11.3.13 dimension
有时候,我们想基于不同的标准来构建我们的App,比如免费版还是收费版、x86版还是arm版等等,在不考虑BuildType的情况下,这里有4种组合:x86的免费版、x86的收费版、arm的免费版、arm的收费版。对于这种情况,我们有两种方式来构建,第一种是通俗的用法,就是配置4个ProductFlavor,他们分别是x86free、x86paid、armfree、armpaid,然后针对这4个ProductFlavor配置,满足我们的需求即可。这种方式比较通俗易懂,但是有个问题,就是配置脚本的冗余,比如free的配置是有共性的,但是我们要在两个free里把共性的配置写两遍,同样x86这类也是,脚本冗余了,而且每次改动都要一个个去修改,也很麻烦,而且现在才有两个维度,每个维度的可选项都不会有很多,我们还可以忍受,如果有很多种维度呢?每个维度又有很多可选项呢?下面我们来介绍第二种方法,通过dimension多维度的方式来解决这个问题。
dimension是ProductFlavor的一个属性,接受一个字符串,作为该ProductFlavor的维度,其实我们可以简单的理解为对ProductFlavor进行分组,比如free和paid可以认为他们都是属于版本(version),而x86和arm是属于架构(abi),这样就把他们分成了两组,而dimension接受的参数就是我们分组的组名,也是维度名称。维度名称不是随便指定的,我们在使用他们之前,必须要先声明,这和我们Java的变量差不多,要先定义好才能使用,那么怎么定义的,这个就是使用android对象的flavorDimensions方法声明的。
flavorDimensions是我们使用的android{}里的方法,它和productFlavors{}是平级的,一定要先使用flavorDimensions声明维度,我们才能在ProductFlavor使用。

该方法可以接受一个可变的字符串类型的参数,所以我们可以 同时指定多个维度,但是一定要记住,这些维度是有顺序的,是有优先级的,第一个参数的优先级最大,其次是第二个,以此类推,所以声明之前一定要根据自己的需求指定好顺序。

如上例子所示,最后生成的variant(构建产物)会被如下几个ProductFlavor对象配置。
- android里的defaultConfig配置,我们前面讲过,它也是一个ProductFlavor。
- abi维度的ProductFlavor,被dimension配置标记为abi的ProductFlavor
- version维度的ProductFlavor,被dimension配置标记为version的ProductFlavor
维度的 优先级 非常重要,因为高优先级的flavor会替换掉低优先级的资源、代码、配置等,在例子中,优先级为abi>version>defaultConfig,因为abi的顺序在version之前。
声明了维度,我们就可以在ProductFlavor使用他们了。

通过dimension指定ProductFlavor所属的维度,非常方便,剩下的事情交给Android Gradle即可,它会帮我们生成相应的Task、SourceSet、Dependencies等。以前我们讲一个构建产物(variant)=BuildType+ProductFlavor,现在ProductFlavor这个维度又被我们通过dimension细化分组,所以就多了一些维度,比如示例中的abi和version,现在构建产物(variant)=BuildType+Abi+Version了,所以会生成如下的variant:
- ArmFreeDebug
- ArmFreeRelease
- ArmPaidDebug
- ArmPaidRelease
- X86FreeDebug
- X86FreeRelease
- X86PaidDebug
- X86PaidRelease
这种我们只用根据维度去分组、去配置,剩下的让Android Gradle帮我们组合可能结果的variant,实现了共性配置--也就是模块化编程,维护起来也很方便。
这一节节本上介绍了所有的ProductFlavor的配置,很多因为以前介绍过,所以这里就略过了,特意用一个标题来说说明是想让大家温故知新一下,除了上面列出的,还有一些方法配置,比如resConfig、resValue、targetSdkVersion、maxSdkVersion、minSdkVersion等,这些我们前面的章节都有讲过,这里就比一一介绍了,他们主要集中在第八章、和第九章,大家可以翻翻熟悉一下。
11.4 提高多渠道构建的效率
我们生成多个渠道包,主要是因为我们想跟踪每个每个渠道的情况,比如新增、活跃、留存等等,跟踪的工具一般是Flurry和友盟,所以除了根据渠道号来区分每个渠道外,大部门情况下,每个渠道并没有什么不同,他们唯一的区别是属于哪个渠道的。
对于这种情况,如果Android Gradle打包,几百个的情况下会非常慢,因为它对每个渠道包都要执行那些构建的过程,但是我们的每个渠道包只是因为渠道号不同而已,为什么要进行一个完成的构建呢,为此了打包效率,美团研究出了另外一个办法,利用了在Apk的META-INF目录下添加空文件不用重新签名的原理,非常高效,其大概就是:
- 利用Android Gradle打一个基本包(母包)
- 然后基于该包拷贝一个,文件名要能区分出来产品、打包时间、版本、渠道等。
- 然后对拷贝出来的Apk文件进行修改,在其META-INF目录下新增空文件,但是空文件的文件名要有意义,必须包含能区分渠道的名字比如mtchannel_google。
- 重复2、3生成我们所需的所有的渠道包Apk,这个可以使用Python这类脚本来做
- 这样就生成了我们所有发布渠道的Apk包了。
那么我们怎么使用呢,原理也非常简单,我们在Apk启动的时候(Application onCreate)的时候,读取我们写Apk中META-INF目录下的前缀为mtchannel_文件,如果找到的话,把文件名取出来,然后就可以拿到渠道标识(google)了,这里贴一个美团实现的代码,大家可以参考一下:
public static String getChannel(Context context) {
ApplicationInfo appinfo = context.getApplicationInfo();
String sourceDir = appinfo.sourceDir;
String ret = "";
ZipFile zipfile = null;
try {
zipfile = new ZipFile(sourceDir);
Enumeration entries = zipfile.entries();
while (entries.hasMoreElements()) {
ZipEntry entry = ((ZipEntry) entries.nextElement());
String entryName = entry.getName();
if (entryName.startsWith("mtchannel")) {
ret = entryName;
break;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (zipfile != null) {
try {
zipfile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
String[] split = ret.split("_");
if (split != null && split.length >= 2) {
return ret.substring(split[0].length() + 1);
} else {
return "";
}
}
以上代码逻辑我们可以再优化一下,比如为渠道做个缓存放在SharePreference里,不能总从Apk里读取吧,效率是个问题。
对于Python批处理也很简单,这里给出一段美团的Python代码,大家参考补充
import zipfile
zipped = zipfile.ZipFile(your_apk, 'a', zipfile.ZIP_DEFLATED)
empty_channel_file = "META-INF/mtchannel_{channel}".format(channel=your_channel)
zipped.write(your_empty_file, empty_channel_file)
添加完空渠道文件后的目录,META-INFO目录多了一个名为mtchannel_meituan的空文件:
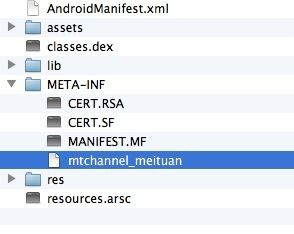
以上是核心实现,我们要做的就是保存一个渠道列表,可以用一个文本文件保存,一行一个渠道,然后使用Python读取,for循环生成不同渠道的Apk包,这个我就不写代码了,大家可以自己试一下,这里给出一个开元的美团方案实现,大家可以参考一下, https://github.com/GavinCT/AndroidMultiChannelBuildTool 。美团方案地址:
http://tech.meituan.com/mt-apk-packaging.html
11.5 小结
到这里多渠道构建这一章就结束了,多渠道构建利用的主要是对ProductFlavor的定制,所以我们重点讲了ProductFlavor的各个配置,让大家都熟悉一下,这样在碰到多渠道的需求时,可以对比参考一下能否满足你的要求,或者需要哪些组合可以做到。
此外我们要记得productFlavors是一个ProductFlavor集合,我们可以通过操纵它做很多批量处理的事情,比如9.5小节中的批量修改AndroidManifest.xml中友盟统计的渠道名等等,这个批处理的功能要合理的利用。
本文属自学历程, 仅供参考
详情请支持原书 Android Gradle权威指南