学习来源
流程:
- 输入图片集并贴上标签(label the training set)
Input: Our input consists of a set of N images, each labeled with one of K different classes. We refer to this data as the training set.
- 训练分类器(training a classifier)
Learning: Our task is to use the training set to learn what every one of the classes looks like. We refer to this step as training a classifier, or learning a model.
- 让训练器(classifier)判断一张全新图片并预测它的真正标签,看是否和真正标签一致。(大量一致的话,我们称之为ground truth)
Evaluation: In the end, we evaluate the quality of the classifier by asking it to predict labels for a new set of images that it has never seen before. We will then compare the true labels of these images to the ones predicted by the classifier. Intuitively, we’re hoping that a lot of the predictions match up with the true answers (which we call the ground truth).
比较相似的方法
L1 distance
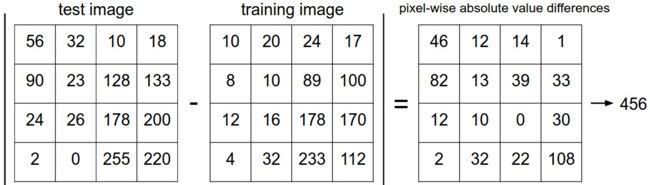
An example of using pixel-wise differences to compare two images with L1 distance (for one color channel in this example). Two images are subtracted elementwise and then all differences are added up to a single number. If two images are identical the result will be zero. But if the images are very different the result will be large.
(就是减了以后取绝对值再把所有的元素加起来看大不大,太大就不是了。暴力方法。)
最初的代码
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide
# flatten out all images to be one-dimensional
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print ('accuracy: %f' % ( np.mean(Yte_predict == Yte) ))```
这里可以看出,train步骤仅仅是简单地读入,而预测`testSet`(即Xte)中一张图片的label的方法就是找到和它的L1distance之和最小的一张`trainingSet`(即Xtr)中的图片的label。
###代码优化
#####使用L2 distance 代替L1 distance
>` distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))`
不过根据文章所说,可以抛弃平方根运算。
(即使如此精准度仍然略比原始的代码低)
#####k - Nearest Neighbor Classifier
并不是找最近的一个,而是找最近的k个,并依据这k个trainningSet中的标签的情况对当前图片的标签进行预测。
#####动用validation set对Hyperparameters进行调整
(Hyperparameters,这里暂时指上文中的k)
k的取值会影响精度,并且这个值需要调整。
文章里强力反对我们根据`test set`进行对hyperparameters 的调整,否则很可能导致overfit
>You might be tempted to suggest that we should try out many different values and see what works best. That is a fine idea and that’s indeed what we will do, but this must be done very carefully. In particular, we cannot use the test set for the purpose of tweaking hyperparameters. Whenever you’re designing Machine Learning algorithms, you should think of the test set as a very precious resource that should ideally never be touched until one time at the very end. Otherwise, the very real danger is that you may tune your hyperparameters to work well on the test set, but if you were to deploy your model you could see a significantly reduced performance. In practice, we would say that you overfit to the test set. Another way of looking at it is that if you tune your hyperparameters on the test set, you are effectively using the test set as the training set, and therefore the performance you achieve on it will be too optimistic with respect to what you might actually observe when you deploy your model. But if you only use the test set once at end, it remains a good proxy for measuring the generalization of your classifier (we will see much more discussion surrounding generalization later in the class).
文章中建议直接从`training set `中分离一部分作为`validation set`,并在不同的k值之下进行预测,将所得的精确度压入结果数组,再从中提取精确度最好的k值。
assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
keep track of what works on the validation set
validation_accuracies.append((k, acc))
#####training set不足时使用Cross-validation
文章里所用的思想是将trainingSet分割成5个folds,然后遍历这五个fold,依次选取一个fold作为validation set,最后取平均值,然后再总的根据K来看。文章里说虽然Cross-validation可以取到更好的hyperparameters ,然而因为开销过大,人们会避免使用它。(sad)
最后贴出的使立忻的参考code(它有使用Cross-validation
)。我的环境有问题,读取不了数据集,怀疑是因为python版本问题,因为我使用xrange和导入cPickle 类的时候都会报错,改正了以后仍然无法运行。这几天我尝试在Linux下把python环境配置一下,再重新写一些代码。
coding=utf-8
import numpy as np
import cPickle as pickle
import os
from scipy.misc import imread
from collections import Counter
从源码copy过来的两个读文件函数,示例这样写真的比较好
def load_CIFAR_batch(filename):
""" load single batch of cifar """
#rb二进制读文件
with open(filename, 'rb') as f:
datadict = pickle.load(f)
X = datadict['data']
Y = datadict['labels']
# 生成一个四维数组X,并用transpose对维度进行排序
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
return X, Y
def load_CIFAR10(ROOT):
""" load all of cifar """
xs = []
ys = []
for b in range(1,6):
f = os.path.join(ROOT, 'data_batch_%d' % (b, ))
X, Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
#用concatenate(array,axis=0)对xs的第一维度(即axis=0)进行合并处理,生成总数组Xtr
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
del X, Y
#处理test文件
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
return Xtr, Ytr, Xte, Yte
class KNearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X, k=1, num_loops=1):
"""
Predict labels for test data using this classifier.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k)
def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in xrange(num_test):
for j in xrange(num_train):
dict[i, j] = np.sqrt(np.sum(np.square(self.X_train[j, :] - X[i, :]), axis=1));
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
def compute_distances_one_loop(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in xrange(num_test):
dists[i, :] = np.sqrt(np.sum(np.square(self.X_train - X[i, :]), axis=1));
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
def compute_distances_no_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
dists = np.multiply(np.dot(X,self.X_train.T),-2)#利用(x1-x2)^2=x1^2-2x1x2+x2^2
distssqx=np.sum(np.square(X),axis=1)
distssqxtr = np.sum(np.square(self.X_train), axis=1)
dists=np.add(dists, distssqx)
dists = np.add(dists, distssqxtr)
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in xrange(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
# self.y_train[np.argsort(dists[i, :])[:k]]是个嵌套列表用flatten()转为列表
closest_y = self.y_train[np.argsort(dists[i, :])[:k]].flatten()
#计数器函数
c = Counter(closest_y)
y_pred[i]=c.most_common(1)[0][0]
#########################################################################
# END OF YOUR CODE #
#########################################################################
return y_pred
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/')
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3)
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3)
Xval_rows = Xtr_rows[:1000, :]
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :]
Ytr = Ytr[1000:]
validation_accuracies = []
for k in [1, 5, 20, 100]:
nn = KNearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yval_predict = nn.predict(Xval_rows, k=k)
acc = np.mean(Yval_predict == Yval)
print 'Acc: %f' % (acc,)
validation_accuracies.append((k, acc))
print validation_accuracies