本文主要用于介绍一种用于图像分割领域的,专门针对边缘分割质量差的问题的一种方法。同时本文也是恺明团队最新的研究成果。本笔记主要为方便初学者快速入门,以及自我回顾。
论文链接:https://arxiv.org/pdf/1912.08193.pdf
源码链接:https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend.
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
本文提出了一种新的方法用于有效的从高质量的图像中进行物体和场景的分割。通过类比传统的计算图形学用于渲染高清图片的处理办法,我们借鉴了其渲染(rendering)的思路用于图像的分割。为此,我们提出了一种新的神经网络模块,PointRend,该模块能够通过一种不断迭代的算法来自适应的挑选出有问题的区域,并对该区域的像素点进行精细化的调整预测。PointRend模块能够很灵活的被嵌套加载运用于现今存在的各个实例和语义分割模型上。定性的讲,PointRend能够对物体的边缘进行更好的分割(crisp object boundaries);定量的讲,在COCO相关的数据集上均取得了长足的进步,并且其显存的高效利用使得其输出的分辨率是其他现有模型所不能做到的。
------------------第二菇 - 核心思想------------------
2.1 分割问题概述
图像分割任务通常都涉及到将像素点映射到规则的网格上,然后据此生成一个标签网格或多个标签网格(label maps)。对于语义分割来说,每组标签网格就代表了每一个像素点的类别。而对于实例分割来说,一个二分的前景和背景的标签网格就可以用于每一个目标的检测。现阶段用的比较多的模型那肯定都是CNN网络这一流派的了。
用于图像分割的CNNs网络通常都是在规则的网格上进行操作的,输入的图片会被表征成规则的像素网格,它们的隐藏特征也就是每一个网格点的特征向量,它们的输出就是每一个网格的预测标签结果。常规的网格均匀采样法肯定是最方便有效的,但是对于图像分割问题来说,就不一定是理想的计算方式了。因为该种表征方法,最后生成的标签往往都是已经被平滑处理过了的,比如,相邻的像素点更有可能是相同的标签。因此,从这个角度来看,常规的均匀采样法往往会导致对目标边缘区域的轮廓表述不清晰,而对平滑区域进行了不必要的过度采样,从而导致的结果就是,在分割的边界区域会较为模糊,如下图所示,

图像分割处理往往都是在低分辨率上进行低,比如对于语义分割来说,可能只有输入图像的1/8,对于实例分割来说,可能就是,这种处理办法也是在过度采样和欠采样之间做的一种妥协。
因此,很明显,如果我们希望在分割图的边界区域更加准确,那可能我们首先就要改变我们的采样策略,即我们应该更关注于那些处在图像边界区域的点,而不是传统方法中的均匀采样。因此,作者也是借鉴了在计算机图形学的一种图像渲染方法(其实就是类似的采样问题),就是在图像平面内自适应的采样一些点产生计算集合再去进行计算。因此,说白了,本文的核心思想就是设计了一种新的难点(分割问题上的话,可以默认为就是边缘点)采样方法,只不过借鉴了一点“渲染”的思路罢了,所以最后也就取名为了PointRend。而从最终的效果上来看,应该也是非常喜人的,达到了一定的目标,如论文开篇所展示的那样,

2.2 PointRend模块解析
理解到了作者的核心思想以后,我们再来细看一下作者的实现逻辑。
整套PointRend模块包含3个部分,
1)一种选择少量合适像素点的策略。这种策略能帮助模型尽可能少的去选择那些真正需要去进一步判断的点,从而避免计算量过大的问题。
2)对于每一个被选出来的点,如何对该点构建特征向量(point-wise feature representation)。
3)根据每一个点提取出的特征,去预测该点所属的类别。
接下来我们跟着论文的节奏逐一来看看。
2.2.1 Point Selection for Inference and Training
直观上来讲,我们肯定是希望专门去选择那些处于目标边缘的点的,整套逻辑我们将分成推理和训练两部分。
2.2.1.1 Inference
对于每一个区域,我们都要用一种从粗糙到精细(coarse-to-fine)的迭代式方法,来“渲染”输出的蒙版(mask)。该“渲染”方法就是从常规的网络的最后一层输出开始(意思就是从网络的最深层,即感受野最大的那层开始上采样迭代),在每一次迭代的过程中,PointRend都会用双线性差值(bilinear interpolation)的办法进行上采样,并且从中选取N个不确定的点(比如那些在二分蒙版的情况下概率接近0.5的),生产该点的特征,并预测它们的标签。这一方法将被迭代使用,直到达到输出的分辨率大小。这一处理的示意图如下所示,
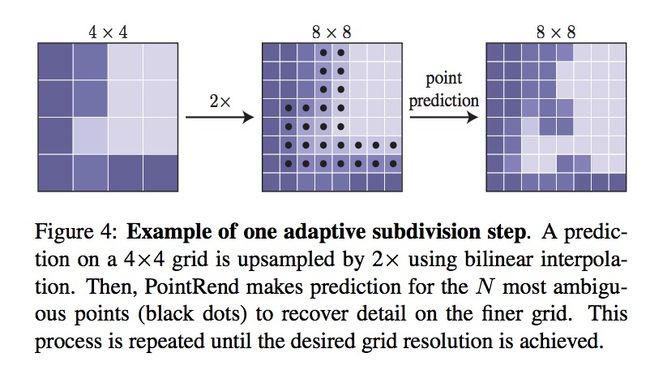
这一过程其实也比较好理解啦,我们可以在考量一下时效性。假如我们输出的大小是,那如果我们要对每一个像素点都进行预测,那就是次操作,而现在,我们总共需要的预测操作是,远远小于
2.2.1.2 Training
在训练阶段,就无法进行迭代式的渲染操作了,因此需要采用一种基于随机采样的非迭代式策略。而该策略的实行目标就是在特征图上选取N点,但是呢这N个点又要倾向于那种不确定性高的区域(也就是边界),同时还得保证一定的均匀覆盖。因此,作者提出了3种基本原则,
1)Over generation:从均匀分布中随机选取kN个候选点。
2)Importance sampling:通过插值计算出选中的kN个点,对该任务的不确定性估计,再从中选择个点。
3)Coverage:剩下的个点就从剩下的候选点均匀采样。
上述的过程示意图如下,

至此,整一套选择点的方法已经讲清楚了。
2.2.2 Point-wise Representation and Point Head
PointRend的输入特征有两种来源,fine-grained和coarse prediction。
这里直接上一张原论文中的模块架构示意图,

其实就是将两种不同的特征(细粒度特征和粗粒度特征)进行拼接,作为每一个点的特征表示。两者的作用分别是提供目标的细节信息以及全局的上下文信息。
对于细粒度特征,其来源应该就是在粗粒度特征上选取的点通过双线性插值的办法又映射回原图尺寸,从而得到对应点的细粒度特征。而粗粒度特征对于实例分割来说是从RoI特征经过预测得到的K类别Mask中进行插值提取。粗预测特征提供更多的上下文信息,同时表达语义类别。【1】
而最后就是Point Head,比较容易理解,就是给定每个点的特征表示,采用MLP(multi-layer perceptron)进行分割预测,预测点的类别标签。
至此,整一套有关PointRend的模块架构思路已经讲完了。至于具体的实验结果,有兴趣的同学可以自行参考原论文,或者最好自己拿来试一试哈哈~
------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想已经说清楚了。本论文主要是提出了一种新的用于提高图像分割领域的边缘分割准确率的方法PointRend,并做了详细的介绍和实验论证,为后续发展奠定了基础。
简单总结一下本文就是先罗列了一下该论文的摘要,再具体介绍了一下本文作者的思路,也简单表述了一下,自己对整个PointRend模块的理解。希望大家读完本文后能进一步加深对该论文的理解。有说的不对的地方也请大家指出,多多交流,大家一起进步~
参考文献:
【1】https://www.cnblogs.com/QuintinLiu/p/12084699.html
【2】