键值对的创建方式:
1.从文件加载:
val line=sc.textFile("path")
2.通过并行数据集合(数组)创建RDD
val list=list("a","b","c")
val rdd=sc.paralelize(list)
常用的键值对转换操作
常用的键值对转换操作包括reduceByKey() ,groupByKey(),sortByKey(),join(),cogroup()
reduceByKey(func):
=====================================================
使函数func 合并具有相同键的值,比如reduceBykey((a,b)=>a+b),有四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),对具有相同key的键值对进行合并后的结果就是:("spark",3)、("hadoop",8)。
从上面结果可以看出,(a,b)=>a+b这个Lamda 表达式中a和b都是指value,比如,对于两个具有相同key的键值对("spark",1)、("spark",2),a就是1,b就是2。
groupByKey():
==========================================================
groupByKey()的功能是,对具有相同键的值进行分组。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))。

keys:
========================================================
keys只会把键值对RDD中的key返回形成一个新的RDD。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的RDD,采用keys后得到的结果是一个RDD[Int],内容是{"spark","spark","hadoop","hadoop"}。

values:
=========================================================
values只会把键值对RDD中的value返回形成一个新的RDD。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的RDD,采用keys后得到的结果是一个RDD[Int],内容是{1,2,3,5}。

sortByKey():
=========================================================
sortByKey()的功能是返回一个根据键排序的RDD。

mapValues(func):
======================================================
们只想对键值对RDD的value部分进行处理,而不是同时对key和value进行处理。对于这种情形,Spark提供了mapValues(func)
它的功能是,对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的pairRDD,如果执行pairRDD.mapValues(x=>x+1),就会得到一个新的键值对RDD,它包含下面四个键值对("spark",2)、("spark",3)、("hadoop",4)和("hadoop",6)。
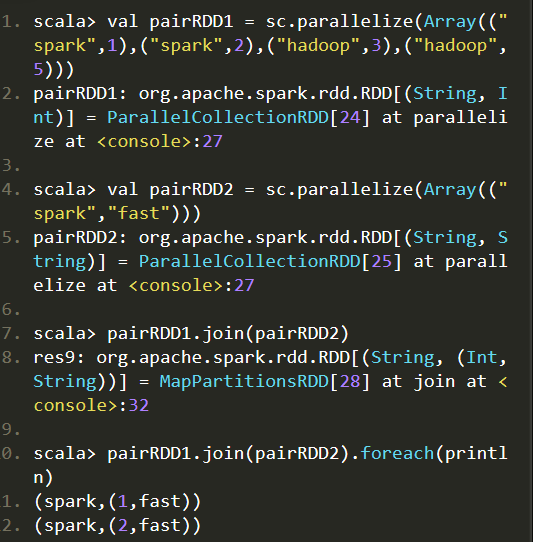
join:
=========================================================
join(连接)操作是键值对常用的操作。“连接”(join)这个概念来自于关系数据库领域,因此,join的类型也和关系数据库中的join一样,包括内连接(join)、左外连接(leftOuterJoin)、右外连接(rightOuterJoin)等。最常用的情形是内连接,所以,join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
比如,pairRDD1是一个键值对集合{("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)},pairRDD2是一个键值对集合{("spark","fast")},那么,pairRDD1.join(pairRDD2)的结果就是一个新的RDD,这个新的RDD是键值对集合{("spark",1,"fast"),("spark",2,"fast")}。