上一篇介绍了几个品牌的奶茶店数据可视化,由于时间原因没有附上数据和完整代码教程,这里将通过几个简单的图表,介绍如何使用pyecharts做数据可视化。
数据方面选择了几个主流的奶茶门店:
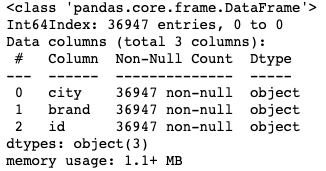
数据整理清洗后,有36948条数据,如果需要样本数据,可以关注公众号并在后台回复:**奶茶数据 **,即可获取。
奶茶品牌列表以及该品牌全国的总门店数量:
#奶茶品牌列表
brand_list = ['1点点',
'益禾堂',
'CoCo都可',
'贡茶',
'蜜雪冰城',
'奈雪の茶',
'书亦烧仙草',
'瑞幸咖啡',
'喜茶',
'古茗',
'茶颜悦色']
02
分析思路
样本数据中主要有两个维度:城市和品牌,我们做可视化的目的是给读者多角度展示数据背后的信息或者规律。一般我们可以通过两个维度做二维表,也可以通过品牌数量来增加一个维度做热力图,也可以通过城市位置属性做地理图。下面我们通过几个不同类型的图表,手把手教大家如何使用pyecharts进行数据可视化。
03
可视化教程
3.1 柱状图Bar
先介绍Pyecharts的构图原理:
1)选择图表:每一种类型的图表,都需要声明不同的对象,比如柱状图是Bar;
2)调整参数:创建好这个对象后,有几个必须添加的函数比如x轴 add_xaxis 和y轴 add_yaxis,全局配置项set_global_options 和系列配置项set_series_opts 将数据和我们想要的参数设置好;
3)最后选择渲染到notebook中render_notebook 还是渲染到html文件render("grid_geo_bar.html")。
柱状图是数据分析中非常常见的,其构造原理非常简单,我们只需要将X轴和Y的数据填好即可。
比如横向比较不同品牌奶茶店在三个城市的门店数量:
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK, width='1000px', height='500px'))
.add_xaxis(['1点点','益禾堂','CoCo都可','贡茶','蜜雪冰城','奈雪の茶','书亦烧仙草','瑞幸咖啡','喜茶'])
.add_yaxis("上海市", [(len(df_new[(df_new['city']=='上海市') & (df_new['brand']==brand_array[j])])) for j in range(10)])
.add_yaxis("广州市", [(len(df_new[(df_new['city']=='广州市') & (df_new['brand']==brand_array[j])])) for j in range(10)])
.add_yaxis("深圳市", [(len(df_new[(df_new['city']=='深圳市') & (df_new['brand']==brand_array[j])])) for j in range(10)])
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="10%"))
)
bar.render_notebook()
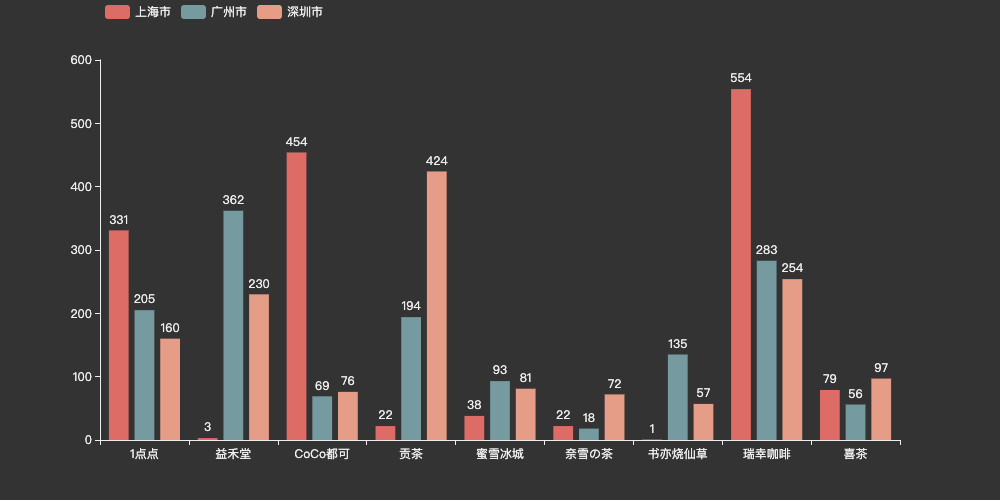
这里三个Y轴的数据都是一个list,也可以通过直接填入数字代替,比如上海市的:
.add_yaxis("上海市", [331, 3, 454, 22, 38, 22, 1, 554, 79, 0])
3.2 地理坐标图Geo
pyecharts 所有方法均支持上一个例子中的链式调用,也支持分步骤调用,这里我们演示另一种调用方法。
并在这个例子中介绍如何使用初始化配置项init_opts和调整几个常见的参数。
如下图中的theme和width、height可以调整主题和图表尺寸;
add_schema(maptype="china") 设置地图类型,具体参考 pyecharts.datasets.map_filenames.json 文件;
type_=ChartType.HEATMAP 设置图表类型,这里是热力图,Geo 图类型,有 scatter, effectScatter, heatmap, lines 4 种;
VisualMapOpts(is_piecewise=False, min_=10,max_=1500) 视觉选项,设置热力图颜色对应的数值大小。
heytea_map = df_new.groupby(by='city').count().sort_values(by='id',ascending=False)['id']
g = Geo(init_opts=opts.InitOpts(theme=ThemeType.DARK, width='1000px', height='700px'))
g.add_schema(maptype="china")
# 使用数据分析大都需要使用 numpy/pandas,但是 numpy 的 numpy.int64/numpy.int32/... 等数据类型并不继承自 Python.int
g.add("热力图",
[list(z) for z in zip(heytea_map.index, heytea_map.values.tolist())],
type_=ChartType.HEATMAP,)
g.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
g.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=False, min_=10,max_=1500),
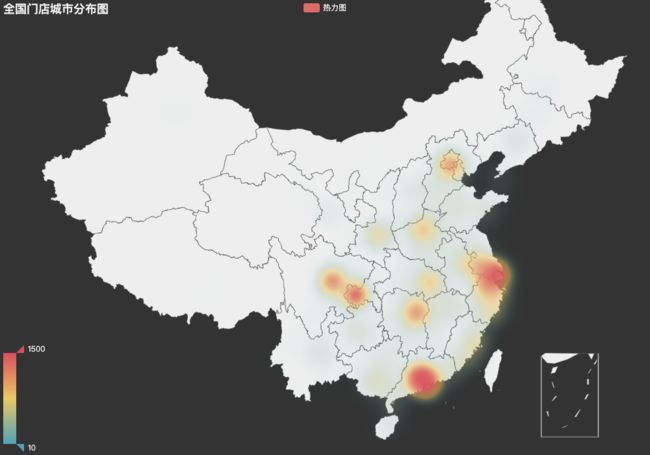
title_opts=opts.TitleOpts(title="全国门店城市分布图"),
)
g.render_notebook()
3.3 组合图Grid
介绍完两种不同的类型,我们就可以做一个组合图,原理是在原来Bar和Geo的基础上,增加一个Grid,把Bar和Geo的作为配置项添加进去,并设置好位置参数。
bar = (
Bar()
.add_xaxis(city_array)
.add_yaxis("", [len(df_new[(df_new['city']==city_array[i])]) for i in range(9)])
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="10%"))
)
geo = (
Geo()
.add_schema(maptype="china")
.add("", [list(z) for z in zip(city_array, [len(df_new[(df_new['city']==city_array[i])]) for i in range(9)])])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True),
title_opts=opts.TitleOpts(title="几大城市不同10种门店数量地理分布图"),
)
)
grid = (
Grid(init_opts=opts.InitOpts(theme=ThemeType.ESSOS, width='1000px', height='700px'))
.add(bar, grid_opts=opts.GridOpts(pos_top="50%", pos_right="45%"))
.add(geo, grid_opts=opts.GridOpts(pos_left="50%"))
.render("grid_geo_bar.html")
)
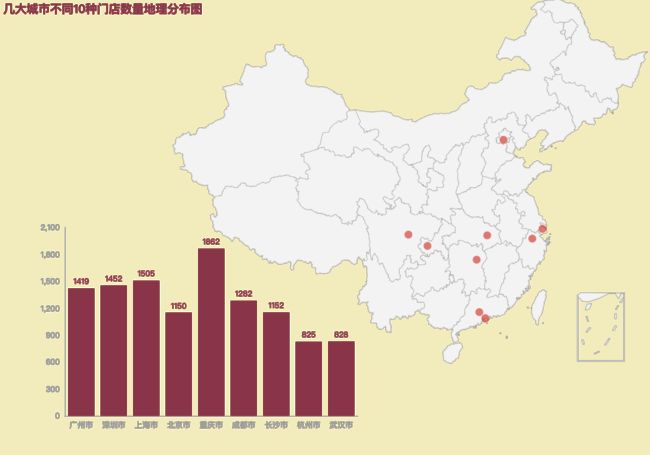
3.4 热力图
根据样本数据,为了更直观查看多个主流城市对应奶茶门店的数量,这里推荐使用热力图,既有城市和品牌的维度,又有不同颜色区分门店数量的大小,能更好的为读者展示数据,更容易看懂。
city_array = ['广州市','深圳市','上海市','北京市','重庆市','成都市','长沙市','杭州市','武汉市']
brand_array = ['1点点','益禾堂','CoCo都可','贡茶','蜜雪冰城','奈雪の茶','书亦烧仙草','瑞幸咖啡','喜茶','古茗']
value = [[i, j, len(df_new[(df_new['city']==city_array[i]) & (df_new['brand']==brand_array[j])])] for i in range(9) for j in range(10)]
c = (
HeatMap(init_opts=opts.InitOpts(theme=ThemeType.DARK, width='1000px', height='700px'))
.add_xaxis(city_array)
.add_yaxis(
"",
brand_array,
value,
label_opts=opts.LabelOpts(is_show=True, position="inside"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="几大城市不同品牌门店数量热力图"),
#visualmap_opts=opts.VisualMapOpts(),
visualmap_opts=opts.VisualMapOpts(is_piecewise=False, min_=0,max_=550),
)
.render("heatmap_with_label_show.html")
)
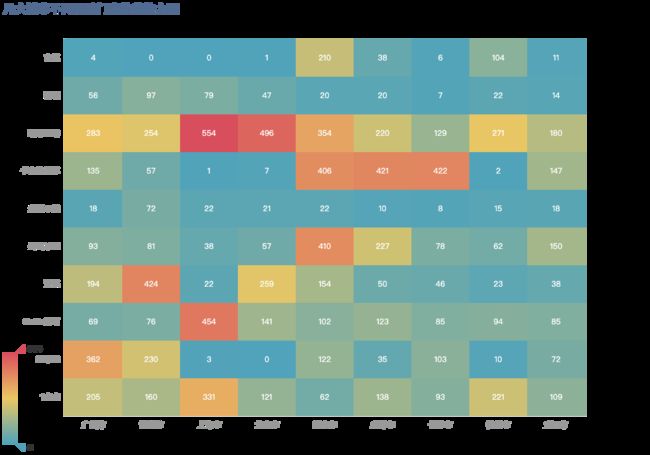
3.5 桑基图
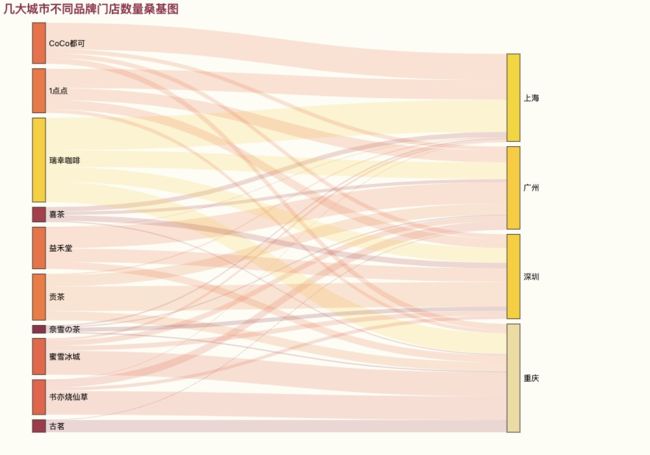
当然还有另外一种图可以用于展示,但这里不太合适,就把图显示出来就好。为什么介绍热力图和桑基图呢,这里涉及到pyecharts绘图的一个难点,就是数据格式的问题。不同的图表,要求的数据格式不一样,比如柱状图只需要xy轴填入list列表即可,有的图需要在列表中嵌套多个dict字典,在数据量比较少的时候,可以直接声明数据:

但是数据量多则需要我们根据要求去讲dataframe中的数据转化好,并且注意数值必须是int,而不能是pandas中的int64,否则出来的图表是空白的,但是不会报错,这个新手入门比较难debug。
到这里,学完这些,就可以算对pyecharts的入门基础有一些了解,如果需要绘制出更多炫酷效果的图表,则需要用到一些前端开发的知识,后续进阶我们再介绍。
如果需要样本数据,可以关注公众号(迷途小球迷)并在后台回复:**奶茶数据 **,即可获取。