本文是对Adventure Works Cycle业务分析可视化案例分析的总结。
目录如下:
项目背景
项目任务
分析过程
分析报告:Adventure业务分析可视化
一.项目背景
Adventure Works Cycle是国内一家制造公司,该公司生产和销售金属和复合材料自行车在全国各个市场。销售方式主要有两种,前期主要是分销商模式,但是2018年公司实现财政收入目标后,2019就开始通过公司自有网站获取线上商户进一步扩大市场。
二.项目任务
随着线上业务的开展,需要增强公司数据化方面的治理,让前线的业务同学能够实现自主分析从而能实现对市场的快速判断。
业务需求:查看最新的销量,销售额趋势以及自行车的占比,获取当天,前一天,当月,当季,当年的各区域各城市销量销售额,以及同比数据
三.分析过程
要实现用户自主分析,必须具备两点:
(1).用户具有可视化操作页面
(2).数据能自动更新
Power BI可以实现用户的可视化操作,只要把相关的表聚合后展示需要的信息到Power BI上即可。但聚合后的数据是固定的,所以要把聚合表的代码部署到linux服务器上,让系统自动去运行聚合表的代码,更新数据,从而实现自主分析。
整体分析流程如下图所示:

准备工作:mysql 数据源,Hive数据库,工具:Sqoop,Power BI 服务器:linux
1.mysql数据源中观察数据
数据库中一共有26张表,根据业务需求,梳理出要使用到的三张表:
ods_sales_orders(订单明细表):时间_地区_产品聚合表——用于从整体、地域和产品维度反映销售概况。
dim_date_df(日期维度表):每日新增用户表——用于形成用户画像。
ods_customer(每日新增用户表):订单明细表——用于用户行为分析。
数据字典含义梳理如下:


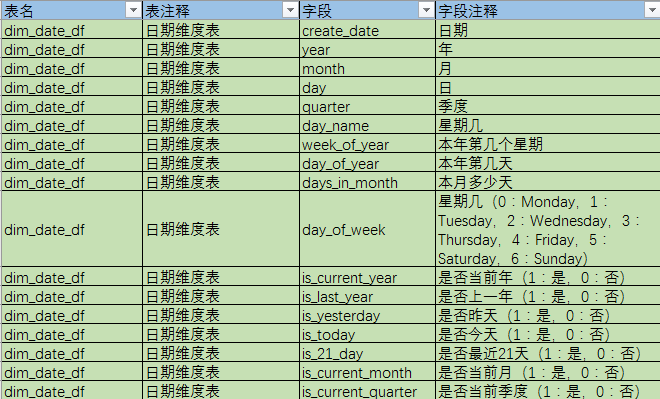
2.数据指标分析
指标拆解:
(1)从整体的角度:销量,销售额,平均金额,同比值
(2)从地域的角度:城市,区域
(3)从产品的角度:热销产品,产品占比
(4)时间的角度:今天,昨天,当月,当季,当年
数据源和指标的对应关系梳理如下:

3.Sqoop抽取Mysql数据到Hive
Sqoop:SQL-to-Hadoop,Sqoop是连接传统关系型数据库和分布式数据库Hadoop之间的的工具,用于在关系型数据库与Hive等之间进行数据转换。
(1)脚本解释
--hive-import : import工具从RDBMS向Hive 的HDFS导入单独的表
--connect:告诉jdbc,连接mysql的url
--driver: 指定要使用的JDBC驱动程序类
--username: 连接mysql的用户名
--password: 连接mysql的密码
--query : 构建sql语句 执行
--fetch-size n:一次从数据库读取 n 个实例,即n条数据
--hive-table:导入到Hive时要使用的表名
--hive-drop-import-delims: 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--delete-target-dir : 如果目标文件已存在就把它删除
--target-dir:目标HDFS目录
-m 1 ## 迁移过程使用1个map(开启一个线程)
(2)将日期维度表,订单明细表,每日新增用户表中的数据抽取到Hive数据库中
下面将演示如何导入ods_customer表(每日新增用户表),其它两张表同样操作。

导入成功后,查看表在位置和数据

4.建立数据仓库,做聚合数据处理
聚合流程如下:

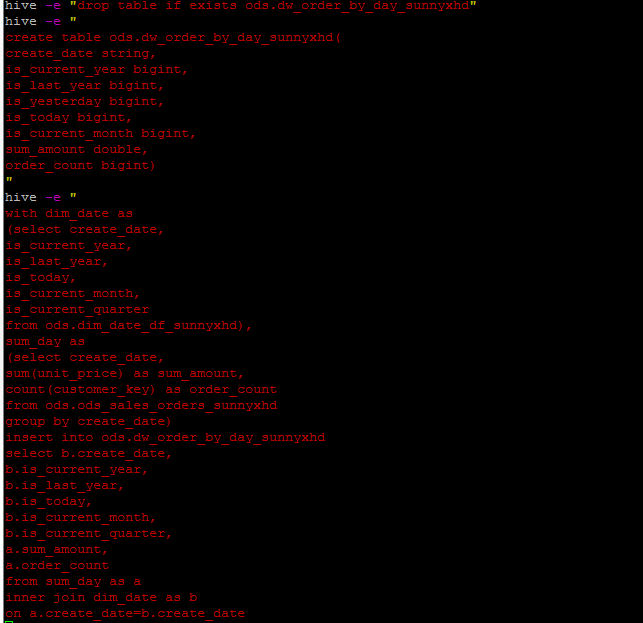
(1)编写Hive SQL,放到shell脚本中,聚合生成上述图中的dw_order_by_day,dw_amount_diff,dw_customer_order表。
下面展示dw_order_by_day表的聚合过程:
这里使用的是with as 创建一个临时表,后面的查询可以多次使用,简化操作。
检查聚合后表的位置和数据:

5.Sqoop从Hive导出数据到mysql
(1)导出步骤
- 步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
- 步骤2:并行导入数据:
- 将Hadoop上文件划分成若干个split;
- 每个split由一个Map Task进行数据导入
(2)脚本解释
sqoop export :将数据从Hadoop(如hive等)导入关系型数据库导中
--connect :
--username:数据库账号
--password :密码
--table dw_order_by_day:数据库建好的表
--export-dir /user/hive/warehouse/ods.db/dw_order_by_day :hive数据库数据路径,这个用show create table ods.dw_order_by_day 查hive表的路径
--columns:抽取的列
--fields-terminated-by '\001' :hive中被导出的文件字段的分隔符
(3)将dw_order_by_day,dw_amount_diff,dw_customer_order抽取回Mysql数据库。
下面展示的是dw_order_by_day的抽取代码,其它两张表同此操作。

6.linux上做定时部署
linux的定时任务使用crontab文件来实现
(1)编写shedule.sh文件,按执行顺序添加文件

(2)添加定时任务,设定每天早上6点执行
编辑crontab 文件 :vi /etc/crontab
添加定时任务:0 6 * * * /home/frog005/adventure_sunnyxhd/schedule.sh
7.Power Bi展示,部署上线
连接mysql数据源中聚合后的三张表,制作Power BI报表。在Power BI制作部分,要使用到多种图形,例如切片器,卡片图,地图,环形图,柱状图等。尤其切片器的使用,让业务人员自行选择需要查看的区域或产品的相关数据。
四.分析报告
可视化报表链接:Adventure业务分析可视化
将Power BI做成的报表发布到web中,报表基本结构如下:
主页: 基本销售指标情况
(1) 时间维度下的基本指标情况(总销售额、目标达成金额、总订单量,平均交易金额)
(2) 不同地区下的销售情况
(3)产品分类下的销售情况

趋势:销售金额,销量与目标达成金额的比较

区域:按地区划分的销售金额、目标金额、订单量,用户数
