登陆:mysql -uroot -p密码
显示与使用数据库: show databases; use 库名;
显示所有的数据表: show tables;
查看表结构: desc 表名;
一. 检查数据表
检查表: check table 表名; #可查看表是否损坏。
分析表: analyze table 表名;
修复表: repair table 表名; #修复被破坏的表
优化表: optimize table 表名;#回收闲置的数据库空间。
1. 优化表 与 表大小碎片相关
注:当表上的数据行被删除时,所占据的磁盘空间并没有立即被回收,使用了OPTIMIZE TABLE
命令后这些空间将被回收,并且对磁盘上的数据行进行重排(注意:是磁盘上,而非数据库)。
使用点:在批量删除数据行之后,或定期(每周/每月一次)进行一次数据表优化操作即可。
试用范围:OPTIMIZE TABLE只对MyISAM, BDB和InnoDB表起作用.
注意点:optimize在对表进行操作的时候,会加锁,所以不宜经常在程序中调用。
看到数据碎片:
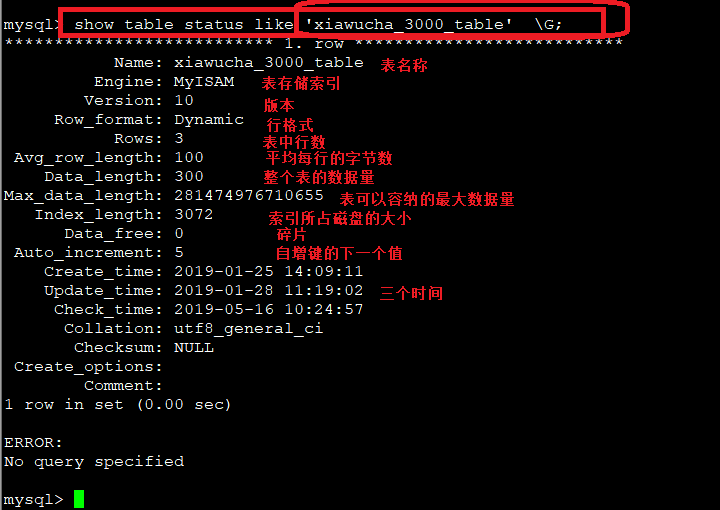
show table status; #获取表信息
show table status like ‘表名’ ; #获取某个表的详细信息
show table status like ‘表名’ \G; #获取某个表的详细信息 #加 \G 可以格式化输出
数据总大小: DATA_LENGTH + INDEX_LENGTH #表的数据量+索引占大小
实际表空间大小:TABLE_ROWS * AVG_ROW_LENGTH #行数*每行的实平均字节数
碎片大小:( DATA_LENGTH+INDEX_LENGTH-TABLE_ROWS*AVG_ROW_LENGTH)/1024/1024/
所以:实际表的大小另一种算法:DATA_LENGTH + INDEX_LENGTH -Data_free;

xiawucha2.png
2. 修复表(先介绍下mysql三文件)
- 创建表时会发生如下结果:
(1)MYSQL创建一个磁盘文件,扩展名为.frm, 用于保护表格式。
(2)存储引擎会为表再创建几个特定的文件, 用于存储表内容。
存储引擎:InnoDB 磁盘文件 .idb
存储引擎:MyISAM 数据.MYD , 索引 .MYI
存储引擎:CSV 数据.CSV, 元数据 .CSM
存储引擎:MEMORY 存储引擎把表放在内存里,而非磁盘上。
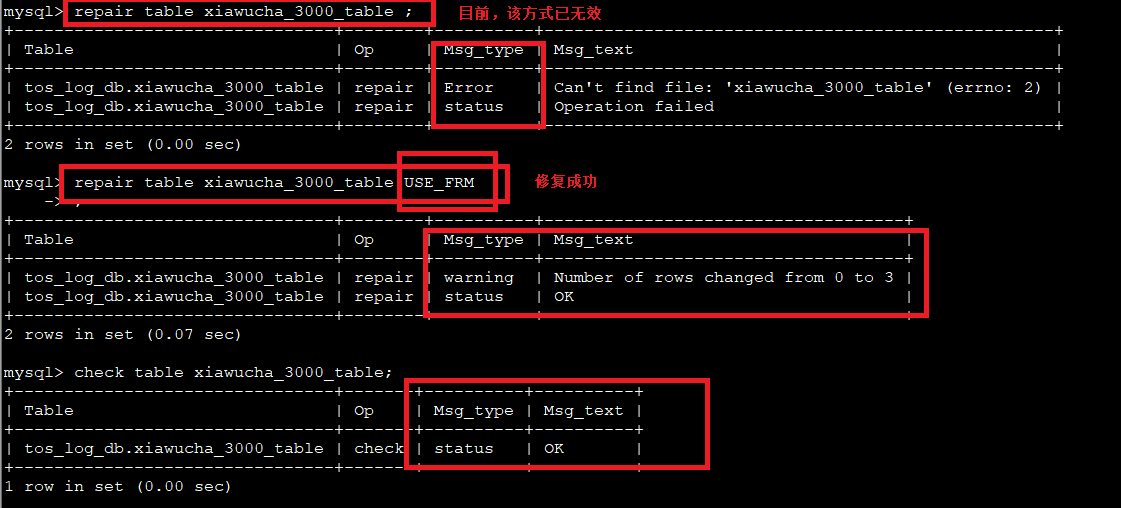
- 格式 : repair table 表名 [选项]
选项如下:
QUICK : 用在数据表还没被修改的情况下,速度最快
EXTENDED :试图去恢复每个数据行,会产生一些垃圾数据行,万般无奈的情况下用
USE_FRM :用在.MYI文件丢失或者头部受到破坏的情况下。
即利用.frm的定义来重建索引
注: 当.MYI文件丢失或头部受到破坏时, repair table 表名 命令将无效,需要加上选项3。
注:对于MyISAM引擎,想损坏表直接删除索引文件(.MYI)即可。
- 格式2: 用mysql内建命令mysqlcheck来修复表, 优化表。 先略
例子:/SE/MYSQL/库名/ 有所有数据表的三种文件。
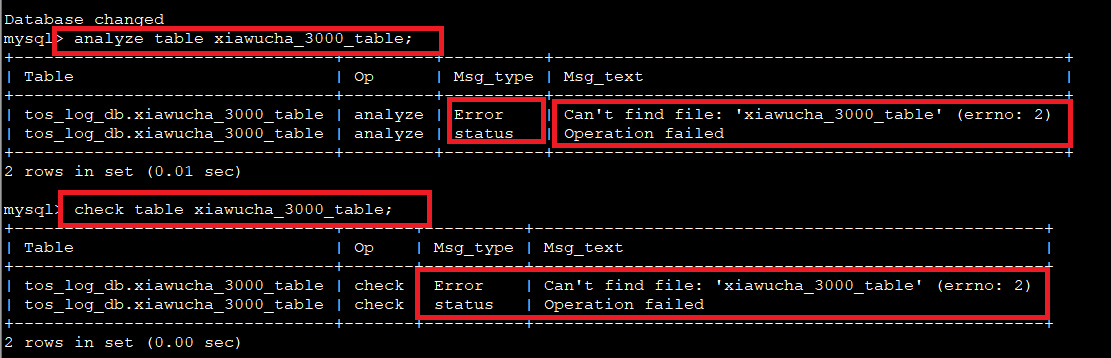
首先: 删除xiawucha_3000_table.MYI 索引文件;
然后: 检查数据表是否损坏: check table xiawucha_3000_table
最后: 修复表。
xiawucha3.png
xiawucha4.png
二. 创建表选项
方式1: 直接创建
create table 表名(\
serial_num 类型 unsigned primary key auto_increment ,\
id 类型 NOT NULL ,\
Version 类型 NOT NULL ,\
time 类型 ,\
dev 类型 NOT NULL ,\
....
vsid 类型 NOT NULL,\
INDEX vsid_id(vsid) \
) engine=MyISAM default charset=utf8;
注: serial_num列--》 主键 且 自增;
注: 存储引擎:engine=MyISAM
注: 默认编码:default charset=utf8
方式2:create table 表2 like 表1;
例子1: create table t2 as select * from t1 where 1=2; 或者 limit 0;
特点:as赋值表的方式,只复制表结构,没有复制索引。复制数据。
例子2: create table t2 like t1 ;
特点:like 创建出来的新表包含源表的完整表结构和索引信息。
特点:与原表区别: 表名不同, 没有源表的数据。
二者的用途:
as: 用来创建相同表结构并复制源表数据。
like:用来创建完整表结构和全部索引(并不复制数据)。
方式3:mysql使用MRG_MyISAM(MERGE)实现水平分表
比如在方式1的最后一句替换如下:
ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8 INSERT_METHOD=NO UNION=(‘表1’,`表2`)
其中:INSERT_METHOD属性说明:
0 /no不允许插入(最好用NO) #即:该表不可以插入数据。
FIRST 插入到UNION中的第一个表
LAST 插入到UNION中的最后一个表
其中:MRG_MYISAM用来实现分表(读写分离)
其中:UNION 用于把多个表的查询结果组合到一个结果集合中。
即:该表为主表,是其余多个表的集合,该表只可查询,不可以插入。
该例子来源于网络
1.首先:创建3张子表
CREATE TABLE `customer1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8; #创建表1
create table customer2 like customer1; #创建表2
create table customer3 like customer1; #创建表3
2. 然后:创建主表,ENGINE指定为MRG_MyISAM( INSERT_METHOD设置为NO 只读)
CREATE TABLE `customer` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
KEY `id` (`id`)
) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8
INSERT_METHOD=NO UNION=(`customer1`,`customer2`,`customer3`);
3. 最后插入数据:
只能往三个子表插入数据,不可往主表插入数据。
注:三个子表的数据,都可以从主表中查询。
水平分表可能存在的问题:
1. 自增建的问题 AUTO_INCREMENT:
首先:AUTO_INCREMENT 是对一张表而言的,后插入该表的日志该建的值会连续增大。
然后: 当分表后,从一张表到另一张表,两者的自增建是独立的,所以需要获取前张表的
自增建的值最大值作为下一张表的初始值。
2. 表的切换问题:
情景1: 当前一张子表达到一定大小/一定时间,会换另一张表;如果表的数量没有限制,
只需要保证 重启后,还能将最新的数据存入重启前的当前表 (或存入一张新表)。
情景2: 当对表的数量(或大小)有限制时,需要记录当前存储的表,并保障重启后还能存入
当前表;且在存入下一张表前,需要先将下一张表清空。
三. 删除表
方式1: drop table 表名; 或者 drop table if exists `表名`;
特点: drop将表格直接删除,没有办法找回。删除内容和定义,释放空间。
方式2:truncate table 表名;
特点: 删除表中的所有数据,不能与where一起使用。
truncate是DDL语言, 操作立即生效,自动提交,原数据不放到 rollback segment中,
不能回滚。删除内容、释放空间但不删除表的结构(定义)。
方式3:
删除整张表数据: delete from 表名;
删除表的部分数据:delete from 表名 where ....;
特点: 属于DML语言,每次删除一行,都在事务日志中为所删除的每行记录一项;
删除表中数据而不删除表的结构(定义),同时也不释放空间。
区别:对于“事务”--》truncate是不可以rollback的,但是delete是可以:
因为:truncate删除整表数据隐式提交),delete是一行一行的删除。
执行速度: drop > truncate > delete。 其中:
drop删除数据,结构,释放空间;
Truncate 并不删除结构(表和索引所占用的空间会恢复到初始大小);
delete只删除数据(表和索引所占用的空间不变)。