- 一、前言
- 1.为什么要学kotlin?
- 2.准备工作 - 二、kotlin基础语法
- 2、函数
- 3、条件控制
- 4、循环 - 三、kotlin面向对象
- 1、类与对象
- 2、继承与构造函数
- 3、接口
- 4、数据类和单例类
- 5、Lambda表达式
- 6、java函数式api的使用
- 7、空指针检查
- 8、函数的默认参数值 - 三、kotlin标准函数和静态方法
- 1、标准函数
- 2、静态方法 - 四、延迟初始化和密封类
- 1、延迟初始化
- 2、密封类 - 五、扩展函数和运算符重载
- 1、扩展函数
- 2、运算符重载 - 六、高阶函数
- 1、高阶函数
- 2、内联函数
- 3、noinline和crossinline - 七、泛型和委托
- 1、泛型的基本用法
- 2、泛型实化
- 3、泛型的协变和逆变
- 4、类委托
- 5、属性委托 - 八、infix函数增强代码可读性
- 九、协程
- 1、协程的基本用法
- 2、作用域构造器
- 3、使用协程简化回调
一、前言
1.为什么要学kotlin?
作为一篇好文章,还是得知道自己学习的目的:google现在将kotlin作为了编写Android的官方语言,另外kotlin跟java相比,有许多更加优秀的设计,和java代码实现同样的功能,往往更加简介明了,这里单独和java语言作比较,也是因为kotlin和java都是编译成相同的.class文件,有许多互通的地方。(此处省略1001字,我们直接上手。。。)
2.准备工作
工欲善其事必先利其器,我们至少有一个能编写kotlin代码的工具吧。我这里使用的是Android Studio,直接用AS创建一个Android 工程,然后在这个工程下,找到和MainActivity同级的位置。新建一个learn.kt文件,在里面编写一个main方法,如图所示,点击左边的“三角按钮”,就可以直接运行起来了:
二、kotlin基础语法
1.变量
val a = 10
val b:Int = 20
var c = "hello"
println("a= $a ,b = $b,c = $c")
我们可以直接把这段代码写道前面的learn.kt文件里面的main()方法中,这几行代码涵盖了kotlin的变量声明:
- val即英文“value”的意思,申明的是一个不可变变量,对应的java里面的final,这样做的好处我就不说了,实际上任何一个变量,都应该优先考虑声明成不可变的。
- var即英文“variable”的意思,声明成一个可变变量。(这里如果有疑惑的朋友,可以尝试修改一下变量a和c的值,就会发现变与不变的区别)
- kotlin中有优秀的类推导机制,实际上写出了上述代码之后,kotlin可以自动判断出a是整型、c是字符串,当让我们也可以像变量b一样,在后面写上“:Int”强制表明这个变量是整型,注意“Int”是大写,类似的还有“Long”、“Float”、“Double”,总之全部大写就完事儿了
- kotlin中,代码不需要再以“;”结尾,回车就代表结束了
- println()函数中,
$a、$b、$c表示的是字符串拼接
2、函数
fun main() {
println("largeNumber is " + largeNumber(11, 12))
}
fun largeNumber(num1: Int, num2: Int): Int {
return max(num1,num2)
}
kotlin中,标准的函数写法就如同largeNumber一样,这里跟java的区别,主要是将返回值写到了函数声明的最后":Int",表示返回一个整数型的值,如果不返回值,可以去掉“:Int”
另外,如果一个函数只有一行代码时,kotlin允许我们直接这样写,直接省略函数体
fun largeNumber(num1: Int, num2: Int): Int = max(num1,num2)
这里由于max返回的是整数型,配合上kotlin优秀的类型推导机制,我们还可以进一步简化
fun largeNumber(num1: Int, num2: Int) = max(num1,num2)
3、条件控制
kotlin中的条件控制主要有if和when,他们在kotlin中都有一个特点,就是分支里的最后一句,可以作为分支的返回值(注意不是函数的返回值)
- if语句如下列代码所示
fun largeNumber1(num1: Int, num2: Int): Int { return if (num1 > num2) { num1 } else { num2 } } fun largeNumber2(num1: Int, num2: Int) = if (num1 > num2) { println("hahahaha") num1 } else num2 - when语句如下列代码所示
fun getScore1(name:String):Int{ return when(name){ "xiao hua" -> { print("lalala") 89 } "xiao ming" -> 98 else -> 60 } } fun getScore2(name: String) = when { name.startsWith("xiao") -> { print("lalala") 89 } name == "xiao ming" -> 98 else -> 60 }
这里需要对getScore2函数做一个说明,其中的when语句后面没有跟参数,而是直接在when语句内部进行判断,满足条件再走具体分支。
4、循环
kotlin中弱化了其他循环,加强了java中的foreach循环。同样也可以类比java。这里首先介绍一下,kotlin中有区间的概念,如val range = 1..10,表示变量range是一个[1,10]的区间。kotlin的循坏代码有如下几种写法
fun main() {
//表示区间[1,5]
for (num in 1..5 step 1) println("xixixi")
//表示区间[1,5) 注意区间是左闭右开
for (num in 1 until 5 step 2) println("hahaha")
//表示区间[5,1]
for (num in 5 downTo 1 step 3) println("lalala")
}
上面的代码中,step 表示步长(默认是1,当为1的时候可以不写step 1)。步长的含义是这样:例如第一个循环是1、2、3、4、5这样循环,第二个循环说是1、3这样循环
三、kotlin面向对象
1、类与对象
kotlin中的类,也是用class声明的,类里面同样有字段和方法。对象的创建跟java比,少了new关键字,直接写就行
fun main() {
val a = Man()
a.name = "xixi"
a.tellYou()
}
class Man{
//这里需要把name声明成可变变量,否则main方法中不能对name重新赋值
var name = "haha"
var age = 30
fun tellYou(){
print("i am $name,age is $age")
}
}
2、继承与构造函数
先说继承,当一个类加上关键字open之后,说明这个类是可以被继承的
open class Man{
//这里需要把name声明成可变变量,否则main方法中不能对name重新赋值
var name = "haha"
var age = 30
fun tellYou(){
print("i am $name,age is $age")
}
}
//Student 继承Man,Student类也有了相应的字段和方法
class Student():Man()
接着,我们再来看一下kotlin中的构造函数。这个相对复杂一点,kotlin中的构造函数分为主构造函数和次构造函数
先回顾一下我们创建对象的代码,val student = Student() ,后面是有一对括号的,其实这里的括号的含义就是调用构造函数。
-
主构造函数:和java不同,主构造函数不会写在类里面,而是直接以类名后面的括号表示,例如上面的代码class Student():Man() ,不管是Student后面的括号还是Man后面的括号,都表示主构造函数,这里表示Student的主构造函数去调用Man的主构造函数。任何类的主构造函数只能有一个,如果没有显式声明出来,就会有一个默认的不带参数的主构造函数(就像类Man一样),所以class Student():Man() 实际上可以直接写成class Student :Man(),注意Man() 后面的括号不能去掉,因为这儿不是声明它,而是调用它。主构造函数是没有方法体的(没有大括号),这样就没办法在主构造函数调用的时机,去做想做的事啦?当然可以,kotlin提供了我们init关键字,可以在类调用主构造函数的时候调用。最后,在主构造函数中,你可以直接向主构造函数传入参数,就代表这个类声明了相应的变量
class Student2(val height:Int): Man() -
次构造函数:次构造函数可以有多个,而且是直接写在类里面的。在主构造函数和次构造函数都存在的情况下,所有的次构造函数都是直接或者间接地调用主构造函数的,如果是自身的主构造函数,用关键字this,如果是父类的主构造函数,用关键字super,次构造函数是通过constructor关键字声明的
open class Man (val name: String,val age:Int){ fun tellYou(){ print("i am $name,age is $age") } } class Student3(val height:Int,name:String,age: Int): Man(name,age){ constructor(name: String):this(3,name,20){ } constructor():this("ht"){ } }
注意看这里的类Student3,他的主构造函数里面,height变量是重新用val定义了的,name和age没有,是直接写入的,因为name和age已经在类Man里面声明了,Student3继承了类Man,自然已经有了这两个变量,所以不用再次定义,写在主函数里面仅仅是为了构造Student3的对象的时候,直接初始化这两个变量
3、接口
kotlin也是单继承的,只能继承一个类,但可以实现多个接口。接口的申明也是用interface声明,如下
interface Study {
fun readBooks()
fun doHomework()
}
class Student5 : Study{
override fun readBooks() {
println("student read books")
}
override fun doHomework() {
println("student doHomework")
}
}
不过kotlin中的接口,允许有自己的默认实现,如果接口的某个方法已经有了默认实现,那么实现他的类就可以不写相应的方法
interface Study {
fun readBooks()
fun doHomework(){
println("interface doHomework")
}
}
class Student6 : Study{
override fun readBooks() {
println("student read books")
}
}
4、数据类和单例类
- 数据类:简单地说就是java里面的java bean、MVC模式里面的modle,数据类主要是业务层面衍生出来的类。一般在定义数据类的时候,我们需要手动实现这个类的equals()、hashcode()、toString()等方法,这些方法是必要的,但同时也是繁琐的,所以kotlin提供了关键字data将一个类声明成数据类,加上此关键字的数据类,内部会自动生成上述方法,从而简化我们的代码:
data class Car(val speed:Int, val price:Int) - 单例类:单例模式也编程中的一个技巧,如果对单例模式不是很清楚的同学,可以参考我的另一篇文章。简单的来说,就是一个类它只实例化唯一的一个,所有地方访问这个实例的时候,都是同一个。我们在定义单例模式的时候,就算是最简单的静态内部类,也要写上三四行代码,并且还要定义一个静态类,这其实是有点冗余的。但
是在kotlin中,声明一个单例类同样非常简单,只需要将class替换成object就可以了
这里我们就定义了一个单例类,其中在里面还写了一个方法。这个单例类不像java一样有getInstance()方法来获得唯一实例,而是直接用类名就行了,内部会帮我们创建一个单例的实例。所以调用此方法就是object Singleton { fun singletonTest(){ println("this is singletonTest hahahaah") } }
Singleton.singletonTest()
跟java中的Singleton.getInstance().singletonTest()是一样的含义
5、Lambda表达式
Lambda是一段可以作为参数传递的一小段代码。它的语法结构如下:
{参数名1 : 参数类型1 , 参数名2 : 参数类型2 -> 函数体 }
有点类似于一个函数,有参数,有函数体,有返回值(返回值是函数体的最后一行代码)。一般情况下,我们在使用lambda表达式的时候,不会将lambda表达式完完整整地按照格式写出来,而是采用的精简写法:
fun main() {
val list = listOf("adsd","2da2","3fsddf3")
val maxRule = { num: String -> num.length}
val maxMember1 = list.maxBy (maxRule)
val maxMember2 = list.maxBy({ num: String -> num.length})
val maxMember3 = list.maxBy(){ num: String -> num.length}
val maxMember4 = list.maxBy{ num: String -> num.length}
val maxMember5 = list.maxBy{ it.length}
}
其中,变量maxMember1到变量maxMember5的赋值代码,就是lambda表达式的精简过程。这里要先解释一下maxBy函数,他接收一个lambda表达式,会将list函数进行遍历,将list的每个元素传入其中,得到其返回规则的最大值。接下来maxMember2到maxMember3是因为如果lambda表达式是函数的最后一个形参,可以将lambda表达式写在外面;maxMember3到maxMember4是因为lambda表达式是唯一一个形参时,可以省略括号;maxMember4到maxMember5是因为lambda表达式只有一个参数时,可以直接fi用it关键字代替,就不用写lambda表达式的参数了。
上面的代码我们看到了maxBy这个函数式api,类似的api还有map、filter、any、all,这里我简单解释一下,首先这几个都是传入的lambda表达式,map用户将list根据条件转换成另外的list,filter用于对list根据条件进行筛选,返回新的list。any和all分别表示list是不是任意元素或者所有元素都满足条件。
6、java函数式api的使用
在kotlin中,除了使用自身的函数式api之外,kotlin调用java方法的时候,也可以使用函数式api。不过这需要一定的条件:kotlin调用一个java方法,并且该方法接收一个java单抽象方法接口参数。这个单抽象方法接口有很多,例如
public interface Runnable{
void run();
}
现在我们依次看一下java函数式api调用的简化过程:
//1
Thread(object : Runnable {
override fun run() {
TODO("Not yet implemented")
}
}).start()
//2
Thread(Runnable {
TODO("Not yet implemented")
}).start()
//3
Thread({
TODO("Not yet implemented")
}).start()
//4
Thread{
TODO("Not yet implemented")
}.start()
其中第一个写法是最标准的创建线程的方法,并没有利用java函数式api做简化,这里的object关键字表示创建一个匿名类实例(因为kotlin里面没有new关键字)
1 -> 2 :java函数式api只接收一个java单抽象方法接口参数,可以直接省略方法名
2 -> 3 :java方法的参数列表只存在一个java单抽象方法接口参数,可以省略接口名
3 -> 4 :lambda表达式是最后一个参数时,可以将lambda表达式写在外面;lambda表达时是唯一一个参数时,可以省略方法的括号
7、空指针检查
kotlin编译时会判断变量是否为空,前面我们申明变量的方式,都含有变量不为空的含义在里面,所以我们也不用判空
fun doStudy(student:Student){
student.doHomework()
student.readBooks()
}
例如这个地方没有判断student != null 。但是有些场景我们希望我们的变量是可以为空的,如果我们希望此时的student变量可以为空,又该怎么做呢?实际上,这里只需要将变量声明Student换成Student? 就可以了,换成Stundet?之后,由于变量student现在可以为空,所以我们需要有对空指针进行检查,第一个检查方式是student调用函数的时候,直接将.替换成?.就可以了
fun doStudy(student:Student?){
student?.doHomework()
student?.readBooks()
}
如果student为空,调用函数doHomework和readBooks也不会报空指针异常,它将什么都不做。
第二个检查方式是let函数,?.当然能解决大部分问题,但是student每使用一次?.相当于都加上了代码if(student != null),实际上在同一个函数中(上下文环境中),我们只需要做一次非空判断就行了,这就是我们的let函数的作用
fun doStudy(student: Student?) {
student?.let {
it.readBooks()
it.doHomework()
}
}
因为调用let也是一次函数调用,所以我们用?.判断调用let的变量student是否为空,如果不为空,那let函数里面的it关键字都不会为空,还记得it关键字是什么意思吗?当lambda表达式只有一个参数时,可以直接省略该参数,用it关键字代替
kotlin里面的非空检查,基本上都是这两种方式。另外还有一个辅助非空检查的工具?:
例如代码val c = a ?: b 表示a如果不为空那么c = a,a如果为空那么c = b,?:操作符可以省略大量的if代码,在平时的工作中我们也可以多采用这种方式。
8、函数的默认参数值
还记得我们前面讲的次构造函数吗,次构造函数是为了实现参数个数不一样,去调用主构造函数,来达到实例化变量的时候可以传入某些参数的效果。实际上我们平时用到次构造函数的地方不多,因为函数的默认参数就可以达到同样的效果
fun pintSomething(something1 : Int , something2:String = "hahaha"){
println("pintSomethong $something1 and $something2")
}
当调用函数pintSomething时,就可以只传入一个Int形的参数,somethong2等于默认值"hahaha"。这里有两个地方需要注意一下:
- 如果我们将somethong1和somethong2参数的位置互换一下,也就是函数的第一个参数时String类型,并且默认值是"hahaha",第二个参数是Int类型,这个时候去调用函数pintSomething的时候,你只想传入一个Int型的参数,即第二个参数somethong1,这个时候会报类型不匹配的错误,因为函数默认是按照参数的顺序来匹配的,虽然第一个参数已经有默认值,这个时候我们就可以用直接显示说明我们要传入的参数是匹配函数的第几个参数
fun main() { pintSomething(something1 = 111) } fun pintSomething( something2:String = "hahaha",something1 : Int){ println("pintSomethong $something1 and $something2") } - 注意println里面直接使用的是
$something1和$something2,这里实际上是kotlin对字符串内嵌表达式的支持,可以直接将变量融合到字符串中
三、kotlin标准函数和静态方法
1、标准函数
kotlin的标准函数,指的是Standard.kt文件中定义的函数,前面我们学的let函数就是标准函数。接下来我们看看另外三个标准函数with、run、apply
fun main() {
val list = listOf("1","2","3","4","5")
val builder1 = with(StringBuffer()){
for (member in list){
append(member)
}
toString()
}
val builder2 = StringBuffer().run {
for (member in list){
append(member)
}
toString()
}
val builder3 = StringBuffer().apply {
for (member in list){
append(member)
}
}
println(builder1)
println(builder2)
println(builder3.toString())
}
这里我们分别用builder1、builder2、builder3演示了with、run、apply的用法,他们三个的功能是类似的,都会接收一个lambda表达式,并且在lambda表达式里面拥有StringBuffer的环境。区别在于:
- with是接收的两个参数,第一个参数StringBuffer作为初始变量,第二个参数书lambda表达式;run和apply只有一个参数lambda表达式,并且需要StringBuffer去主动调用
- with和run都是lambda表达式的最后一句,作为整个函数调用的返回值,apply默认是将构造完成的本身StringBuffer作为返回值
2、静态方法
kotlin弱化了静态方法。因为单例类的调用方式就如同java里的静态方法的调用方式一样,但是单例类会将里面的所有方法都转换为"静态方法"的调用方式,能不能只对其中的某个方法做调整呢,其实也是可以的,我们可以采用companion object,先声明一个伴生类,然后在里面创建对应的方法,伴生类保证他在某个类里面所创建的对象是唯一的
class Student {
fun leanSomething(){
}
companion object {
fun doHomeWork(){
}
}
}
这样我们就可以直接调用Student.doHomeWork()方法了,而learnSomething方法仍然需要Student的实例来调用。
单例类和companion object都只是语法上模仿了静态方法,实际上他们都不是真正的静态方法,如果你在java代码里面以静态方法的方式去调用,会发现这两种方式都没法实现。在kotlin中,如果你想实现真正的静态方法,可以使用这两种方式:注解和顶层方法
- 注解@JvmStatic:当我们给单例类或者companion object中的方法加上@JvmStatic注解,kotlin就会将这些方法变成真正的静态方法
- 顶层方法:例如我们在Hello.kt文件里面直接写的一个方法fun helloworld(){},这就是一个顶层方法,没有包含在任何类中,那么编译器在编译的时候,就会将他编译成静态方法。但是java静态方法的调用方式必须是类名.静态方法名,这里没有类名怎么调用呢,实际上kotlin会自动根据文件名创建一个java类,这里就是HelloKt.java类了,因此我们在java代码里面,我们可以通过HelloKt.helloworld的方式来调用
四、延迟初始化和密封类
1、延迟初始化
我们直接上代码
class MainActivity : AppCompatActivity() {
private var button :Button? = null
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
button = findViewById(R.id.btn_hello_world)
}
fun callOnClick(){
button?.callOnClick()
}
}
这里我们有一个全局变量button,并且是可为空的,而且我们的callOnClick方法我们会手动控制在调用了onCreate方法之后再调用,但是在callOnClick方法里面并不知道button是否为空,所以必须判空。这也就是全局可为空变量的弊端,不管什么时候,只要用到了此变量,都要进行判空(就算你最开始声明的时候,直接进行了赋值private var button :Button? = findViewById(R.id.btn_hello_world)),仅仅是为了满足kotlin的语法。所以我们可以用延迟初始化关键字latrinit,此关键字的作用是我们之后会对变量进行初始化,所以它之后就不会为空(这里只是让编译器认为它不会为空,不用做判空条件,实际上也是可能为空的,我们编写代码的时候就应该判断为不为空)
class MainActivity : AppCompatActivity() {
private lateinit var button :Button
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
button = findViewById(R.id.btn_hello_world)
}
fun callOnClick(){
button.callOnClick()
}
}
注意看这里,callOnClick方法里面,button就不用做非空判断了,这就是lateinit的作用,但是lateinit不能保证变量是否为空,只有我们通过认为控制判断时机才能确定,例如以下场景,我们在button还没有初始化的时候调用callOnClick,那么此时的button就还是为空(只是编译器认为不为空,可以不做判空条件)
class MainActivity : AppCompatActivity() {
private lateinit var button :Button
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
callOnClick()
button = findViewById(R.id.btn_hello_world)
}
fun callOnClick(){
//这里的::button.isInitialized是固定写法,用于判断button是否初始化
if (::button.isInitialized){
button.callOnClick()
}
}
}
2、密封类
当我们使用when语句作为返回值时,必须加上else分支,才能通过编译,如下例代码
interface Result
class Success(val msg: String) : Result
class Failure(val error: Exception) : Result
fun getResult(result: Result) =
when (result) {
is Success -> println("Success")
is Failure -> println("Failure")
else -> println("else")
}
这里我们将整个when语句作为返回值,就必须加上else分支,否则编译器会认为考虑不够充分,但实际上这里的result只可能时Success类或者Failure类,else根本就不会走到,else分支只是为了满足编译器而已。
所以我们用到了密封类sealed,将密封类作为参数传入when语句时,默认的条件只会是他的所有子类,而且必须判断所有子类分支,否则编译器会报错,这种情况就不需要再添加else分支了,这就是密封类的作用,如下例代码
sealed class Result
class Success(val msg: String) : Result()
class Failure(val error: Exception) : Result()
fun getResult(result: Result) =
when (result) {
is Success -> println("Success")
is Failure -> println("Failure")
}
五、扩展函数和运算符重载
1、扩展函数
扩展函数表示即使在不修改某个类的源码的情况下,我们仍然可以对某个类添加方法,进行扩展。例如我们对String类新增一个方法letterCount(),返回String字符串里面的字母的个数
fun main() {
val a = "asfu232u&fd2,4nfjh".letterCount()
println("字符串中字母的个数为 $a")
}
fun String.letterCount() : Int {
var letterNum = 0;
for(char in this){
if(char.isLetter()){
letterNum++
}
}
return letterNum
}
可以看到,扩展函数的主要写法就是在定义方法名的时候,通过Class.直接声明是在哪个类中。
2、运算符重载
kotlin允许对运算符进行重载,每种运算符都对应一个函数名+(plus)、-(minus)、*(times)、/(div)、%(rem),然后我们用关键字operation声明方法,就能对运算符进行重载了,例如下面实现对两个类相加
fun main() {
val appleA = Apple(3)
val appleB = Apple(4)
val appleAll = appleA + appleB
println(appleAll.weight)
}
class Apple(val weight: Int){
operator fun plus(apple: Apple) : Apple{
return Apple(weight + apple.weight)
}
}
这样就实现了两个苹果相加,其中operator 关键字和plus是必须的,plus就是运算符+的简写形式,每个运算符都有相对应的简写,需要用到的时候网上查一下就行了
六、高阶函数
1、高阶函数
如果一个函数接收另一个函数作为参数,或者返回类型是一个函数,那么这个函数我们就称之为高阶函数。例如我们前面提到的maxBy、map、filter、any、all,这些函数都是高阶函数,我们传入的lambda表达式,实际上就是传入的一个具体的函数。接下来我们看一下高阶函数的定义,以及如何使用高阶函数。
在这之前,我们先要了解函数类型,我们都知道变量可以声明成Int型、String型、Double型等等,那么函数类型是什么呢,它的定义如下:
(String , int ) -> Unit
这就是一个函数类型,括号里面表示函数的参数,-> 右边表示函数的返回值。通过这个表达式就能完整地表明一个函数了。
接下来就直接上代码,看看高阶函数式怎样的
fun main() {
operation(3,2,::add)
operation(5,10, ::minus)
}
fun operation(num1:Int , num2:Int , func:(Int,Int)-> Int){
val a = func(num1,num2)
println("num1和num2根据函数变换之后的值为$a")
}
fun add(a : Int , b : Int) : Int{
return a+b
}
fun minus(a : Int , b : Int) : Int{
return a-b
}
这就比较直观了,我们首先定义了一个高阶函数,他传入三个参数,两个Int型的值和一个函数类型的值,在方法内部调用“函数类型的值”,因为它本身是函数,所以可以直接调用,并且将前两个Int型作为形参传了进去。接下来我们定义了两个函数add和minus,这两个函数实现他们本身的逻辑,最后在main函数里面调用了此高阶函数,其中::add和::minus是固定写法,表示函数的引用。
以上就是高阶函数的完整用法,但是如果每次调用高阶函数,都要带上一个函数名::add、::minus,未免有点太过麻烦。kotlin当然有他的办法,还记得我们前面调用高阶函数maxBy的代码吗,当时我们是传入的lambda表达式来表示的一个函数。当然所有的高阶函数都可以用lambda表达式作为函数类型参数传进去,除了lambda表达式,我们也可以用匿名函数、成员引用等,但是最常用的还是lambda表达式了,以下是他的简写代码
fun main() {
operation(2,6){n1 :Int , n2 :Int -> n1 * n2}
operation(3,5){n1 , n2 -> n1 * n2}
}
fun operation(num1:Int , num2:Int , func:(Int,Int)-> Int){
val a = func(num1,num2)
println("num1和num2根据函数变换之后的值为$a")
}
这就是高阶函数的基本用法了。接下来我们再定义一个高阶函数
fun StringBuffer.add(func : StringBuffer.() -> Unit) : StringBuffer{
func()
return this
}
这个高阶函数明显是StringBuffer的一个扩展函数,函数名是add,但是函数类型,为什么多了一个StringBuffer.呢,实际上这才是高阶函数的完整定义,可以理解成传入的这个函数类型,也是在StringBuffer里面的一个扩展函数,拥有StringBuffer的上下文,所以在传入lambda表达式的时候,可以直接像下面这样写
fun main() {
val stringBuffer = StringBuffer()
stringBuffer.add {
append("hahaha")
append("lalala")
}
println(stringBuffer.toString())
}
2、内联函数
我们知道,kotlin代码最终还是会编译成java字节码的,但是java中没有高阶函数的概念,那他是怎么做转换的呢。实际上,上述的kotlin代码会转换为如下java代码
interface Function{
int times(int a,int b);
}
public static void operation(int num1,int num2,Function function){
int sum = function.times(num1 , num2);
System.out.println("num1和num2根据函数变换之后的值为 "+ sum);
}
public static void main(String[] args) {
operation(3, 5, new Function() {
@Override
public int times(int a, int b) {
return a * b;
}
});
}
这其实就是高阶函数底层的实现原理,原本我们传入的lambda表达式,实际上是一个匿名类的实现,每调用一次lambda表达式,都会创建一个匿名类的实例,这就会带来性能上的开销,于是我们的内联函数inline登场了,内联函数在编译的时候,会自动替换到调用他的地方,这样就不存在开销了。如上述java代码,函数operation会直接取消第三个参数Function接口,然后将函数内部的function.times直接换成main函数里面的实现,即renturn a * b相关部分,相当于此时的operation方法内部是 int sum = num1 * num2 ,这样就没有匿名类的定义了,也就减小了开销。同理,kotlin也是采用的同样的方式做了相应的替换。注意:内联函数的使用场景,主要是减小高阶函数中,lambda表达式带来的开销。
将高阶函数声明成内联函数,也很简单,就是加上内联函数的关键字inline就行了
fun main() {
operation(2,6){n1 :Int , n2 :Int -> n1 * n2}
operation(3,5){n1 , n2 -> n1 * n2}
}
inline fun operation(num1:Int , num2:Int , func:(Int,Int)-> Int){
val a = func(num1,num2)
println("num1和num2根据函数变换之后的值为$a")
}
3、noinline和crossinline
在解释着两个关键字之前,我们先得了解一些概念:内联函数会将所有参数内联,内联函数因为底层实现是替换代码的原因,所以可以直接在内联函数所引用的lambda表达式中,使用return语句进行函数返回(直接将调用他的函数返回),当然也可以使用return@函数名进行局部返回;非内联函数(普通高阶函数),只能用return@函数名进行局部返回,即在非内联函数中,lambda表达式里面不能有return语句,只能有局部return@函数名语句
fun main() {
operation1(2, 6) { n1: Int, n2: Int ->
println("1111111")
return@operation1 310
println("2222222")
n1 * n2
}
operation2(3, 5) { n1, n2 ->
return
n1 * n2
}
}
fun operation1(num1: Int, num2: Int, func: (Int, Int) -> Int) {
val a = func(num1, num2)
println("num1和num2根据函数变换之后的值为$a")
}
inline fun operation2(num1: Int, num2: Int, func: (Int, Int) -> Int) {
val a = func(num1, num2)
println("num1和num2根据函数变换之后的值为$a")
}
- noinline:当一个 inline 函数中,有多个 lambda 作为参数时,可以在不想内联的 lambda 表达式前使用 noinline 声明
- crossinline:这里说明一下,lambda表达式和匿名类里面不能有return语句,只能有局部
return@函数名语句。但是声明了inline的函数可以有return语句。这里我们看一种场景
上述代码其实是有问题的。在Runnable中,我们是不能有return语句,但是函数operation3是内联函数,他的函数类型参数func所传入的lambda表达式内部是允许有return语句的,如果这里我们传入的lambda表达式里面有return语句,因为是内联函数,lambda表达式的内容会完全替换到func(num1,num2)所在的位置,同时里面所带有的return语句也带过去了,这个时候就和“lambda表达式里面不能有return语句”冲突了。所以这个地方会报错,但是我们可以将inline换成crossinline,表示我不会在传入的lambda表达式中调用return语句,这样就可以通过编译了。inline fun operation3(num1: Int, num2: Int, func: (Int, Int) -> Int) { val runnable = Runnable { val a = func(num1, num2) println("num1和num2根据函数变换之后的值为$a") } }
七、泛型和委托
1、泛型的基本用法
泛型主要有两种方式,泛型类和泛型方法。使用的语法结构是在类名后面或者方法名前面加上
fun main() {
val a = TestClass()
val b = a.test1("haha")
val c = a.test2(333)
println(b + c)
}
class TestClass{
fun test1(param : T):T{
return param
}
fun test2(param : B):B{
return param
}
}
这里的TestClass就是一个泛型类,其中有两个方法test1和test2,test1是一个普通方法,不过其中的参数和返回值,都用到了TestClass声明的参数类型T,test2是一个泛型方法,它将接收一个参数B,并返回这个参数。
kotlin还有允许我们对泛型的类型进行限制
fun test3(param : B):B{
return param
}
这里我们新增了一个泛型方法test3,并且对它接收的参数B做了限制,必须是Number的子类型,于是test3可以传入Int、Float、Double之类的,但是不能传入String。
另外,像test2这种泛型方法,没有对B进行限制,其实默认是,Any是kotlin中的超类,任何类型都是继承的它,由于后面有?,所以是可为空的,如果我们不想泛型参数可为空的话,可以手动写上
2、泛型实化
我们知道,kotlin也是基于jvm的语言,所有基于jvm的语言,他们的泛型功能都是通过类型擦除机制来实现的,例如我们创建了一个List
不过kotlin提供了内联函数的概念,内联函数的代码可以在编译的时候自动替换到调用它的地方
fun test1(){
test2("xixixi")
}
inline fun test2(a : T){
println("test2() print $a")
}
如上述代码,在函数test1中调用了内联函数test2,这个时候实际上就会把 println("test2() print xixixi")替换过去,所以在内联函数test2中实际上是可以知道T的类型的。但是仅仅这样还不够,我们在test2中添加代码T::class.java,这个时候会报错,因为编译期间还是不知道T类型实际上是一个实化的类型(例如test1函数也是一个带泛型参数的函数,并且把参数传递给test2),这个时候我们再加上reified关键字声明T就可以了,这就是告诉编译器,T是一个实化后的具体类型
inline fun test2(a : T){
println("test2() print $a")
//如果不用reified修饰T,编译器依然通不过,因为传进来的a的类型,可能也是一个泛型类型
T::class.java
}
最后,我们再品一品泛型实化的应用
inline fun myStartActivity(context: Context,bloc:Intent.()->Unit){
val intent = Intent(context , T::class.java)
intent.bloc()
context.startActivity(intent)
}
fun test3(context: Context){
myStartActivity(context){
putExtra("patame1","haha1")
putExtra("patame2","haha2")
}
}
3、泛型的协变和逆变
我们约定,在一个泛型类或者泛型接口的方法中,它的参数列表是接收数据的地方,就称为in位置,他的返回值是输出数据的地方,就称为out位置
fun test(param: T):T {
return param
}
例如在方法test中,传入的泛型T的位置,就是in位置,返回的泛型T的位置,就是out位置。
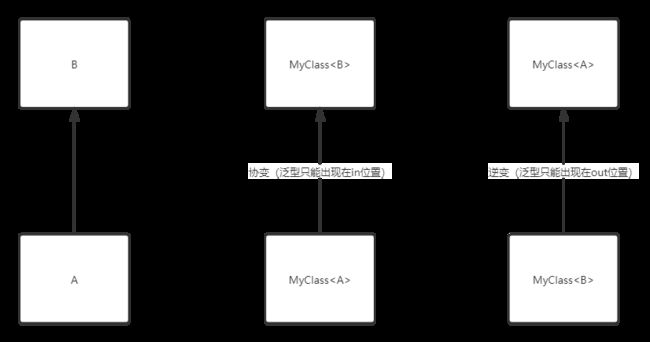
泛型的协变和逆变都是根据两个有继承关系的类型A、B,关系延申到MyClass、MyClass的。我们分别看一下他们的具体定义
- 泛型的协变:假如定义了一个MyClass
的泛型类,其中A是B的子类型,同时MyClass又是MyClass的子类型,我们就可以称MyClass在T这个泛型是协变的。如果泛型都是只读的(泛型加上out关键字),就能实现MyClass是MyClass的子类型 - 泛型的逆变:假如定义了一个MyClass
的泛型类,其中A是B的子类型,同时MyClass又是MyClass的子类型,我们就可以称MyClass在T这个泛型是逆变的。如果泛型都是只写的(泛型加上in关键字),就能实现MyClass是MyClass的子类型
泛型的协变和逆变定义就是这样,要归咎起底层原因,主要就是MyClass、MyClass的相互继承关系,需要将泛型申明成in或者out才能安全的转换,声明了in、out关键字之后,理论上泛型就只能出现在in、out位置,但也可以用注解@unsafeVariance打破这一规定,但始终要记住,加上该注解之后只是为了通过编译,依然不能去随意读写。具体就不深入展开了,我们大概了解到这儿就行。最后在用一张图总结下协变和逆变的区别。
4、类委托
委托顾名思义就是将自己要做的事,委托给别人来做。我在另一篇文章——代理模式,里面的静态代理本质上就是用的委托。这里我们也简单看一下代码
fun main() {
val mySet = MySet(HashSet())
}
class MySet(val delegateSet : HashSet): Set{
override val size: Int
get() = delegateSet.size
override fun contains(element: T) = delegateSet.contains(element)
override fun containsAll(elements: Collection) = delegateSet.containsAll(elements)
override fun isEmpty() = delegateSet.isEmpty()
override fun iterator() = delegateSet.iterator()
}
我们定义了一个MySet类,在他的主构造函数中,传入了一个具体的HashSet类的实例delegateSet,并且MySet类也是继承了Set类的,所以我们也需要在MySet类中实现Set类的所有抽象方法,这里在各个抽象方法实现的过程中,实际上又是通过delegateSet来实现的(这个过程就相当于委托给delegateSet了),我们可以将所有抽象方法都委托给delegateSet,也可以自己真的去实现某些抽象方法。
通过类的委托,我们可以轻松实现一个类,当然我们也可以在MySet的主构造函数中,传入其他实例List
kotlin的类委托通过关键字by来实现,后面接一个类的实例(这个实例一般是通过主构造函数传入的同一父类的其他子类的实例),代码如下
//将MySet的具体实现委托给HashSet是可以的
class MySet1(val delegateSet : HashSet): Set by delegateSet{
override fun contains(element: T) = true
}
//将MySet的具体实现委托给List是不行的
class MySet2(val delegateSet : List): Set by delegateSet
MySet1就是类委托的标准实现了,他其实和上面的MySet类是一个意思,不过这里自己另外实现了contains方法(没有去委托)。
5、属性委托
属性委托跟类委托差不多,是将属性的具体实现,委托给另一个类的实例来完成。而且也是用的by关键字
class MyClass(){
val parame by Delegate()
}
class Delegate(){
var propValue : Any? = null
operator fun getValue(myClass: MyClass , prop : KProperty<*> ): Any?{
return propValue
}
operator fun setValue(myClass: MyClass , prop : KProperty<*>,any: Any?){
propValue = any
}
}
这里我们将MyClass类中的属性parame委托给了Delegate类,之后调用patame的时候,实际上就会走到Delegate类里面的getValue和setValue方法,这两个方法是标准写法,都必须用operator进行声明(operator关键字在我们重载操作符的时候有用到,这里相当于重载get、set方法),getValue和setValue里面的参数也数固定的,getValue的第一个参数表示Delegate的委托功能可以在哪个类中使用,第二个参数KProperty<*>是Kotlin中的一个属性操作类,可以获得各种属性相关的操作,当前场景用不上,它的泛型<*>表示不知道或者不关心泛型的具体类型,只是为了通过语法编译。返回值可以声明成任意类型,不过需要和seValue的第三个参数保持一致。
八、infix函数增强代码可读性
在kotlin里面,我们创建map集合,可以用mapOf()函数和mutableMapOf()函数,两个函数用法差不多,只不过前者创建的集合不可修改,后者可修改。
fun main() {
//public fun mapOf(vararg pairs: Pair): Map
val map = mapOf(1 to "haha",2 to "xixi" , 2 to "lala")
}
这里我们用mapOf()函数创建了一个map集合,可以看到mapOf接收的参数用vararg声明了,表示是一个可变数组,可以是1、2、3、...、无数个Pari
public infix fun A.to(that: B): Pair = Pair(this, that)
如果把infix去掉,我们用mapOf()创建map集合就可以这样写
fun main() {
val map = mapOf(1.to1("haha"),2.to1("xixi") , 3.to1("lala"))
}
fun A.to1(that: B): Pair = Pair(this, that)
这里我们实现了一个to1()函数,他和to()函数的作用仅仅只是to()函数加上了infix声明,这就是infix的作用。
这里需要注意的是,infix函数有个比较严格的限制:就是infix函数必须接收且只能接收一个参数,即A.to(B)的形式。
九、协程
1、协程的基本用法
协程允许我们在单线程中模拟多线程的效果,代码执行时的挂起与恢复完全是由编程语言来控制的,和操作系统无关。
我们想要引入协程功能,需要在app/build.gradle文件中添加如下依赖库:
//引入协程需要添加如下依赖
implementation'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.2.1'
//在Android中引入协程,还需添加如下依赖
implementation'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1'
接下来就是开启协程了,其中最简单的方式如下:
fun main() {
GlobalScope.launch {
println("thread.name1 = "+Thread.currentThread().name)
}
}
GlobalScope.launch就可以创建一个协程的作用域,但是我们发现,运行上面的代码,并没有任何打印,这是因为GlobalScope.launch创建的是一个顶层协程,这种协程会在应用程序结束的时候跟着结束。main方法所在的线程没有其他代码,所以main很快就结束了,于是协程也跟着结束了,我们可以将main方法暂时阻塞住,看一下打印
fun main() {
GlobalScope.launch {
println("thread.name1 = "+Thread.currentThread().name)
}
Thread.sleep(1000)
println("thread.name2 = "+Thread.currentThread().name)
}
它的打印如下
thread.name1 = DefaultDispatcher-worker-1
thread.name2 = main
很明显打印出来了,并且我们可以看到,这里的协程单独开了线程,当然也有不开线程的情况,这取决于开启协程的方法。大家可以尝试下,将Thread.sleep(1000)放在开启协程之前,看一下协程里的打印是否还有,并思考下为什么。
接着我们再看一下另一种开启协程的方式
fun main() {
runBlocking {
println("thread.name1 = "+Thread.currentThread().name)
delay(1000)
println("thread.name2 = "+Thread.currentThread().name)
}
println("thread.name3 = "+Thread.currentThread().name)
}
这里没有对main线程阻塞,那runBloking里面的协程作用域,会有打印吗?
答案是有的,我们看一下打印是什么
thread.name1 = main
thread.name2 = main
thread.name3 = main
这就是runBloking函数创建协程的作用,它可以保证协程作用域内的所有代码和子协程没有执行完之前,一直阻塞当前线程,所以我们是可以看到协程内的打印的,并且我们发现runBloking创建的协程作用域也是直接运行在它所在的线程的。也正是因为runBloking的特点,会阻塞当前线程,所以在Android中一般也只是用来作为测试代码,因为在Android中阻塞了UI线程,可是一件很可怕的事。
上述代码还有一个delay函数也值得提一下,它是挂起函数,会挂起当前协程,有点类似于线程挂起,但是作用域小得多。并且挂起函数只能在协程作用域或者其他挂起函数中调用。
我们有必要再来看一下launch函数,它必须在协程作用域下才能使用,是用来创建子协程的,子协程的特点是如果外层作用域的协程结束了,那么该作用域下的子协程也会跟着结束。
刚才提到,delay函数只能在协程作用域或者其他挂起函数中调用,launch函数只能在协程作用域中调用,那么,我们如何创建协程作用域(不使用协程创建函数GlobalScope.launch、runBlocking 之类的),创建挂起函数呢?
-
创建协程作用域
用coroutineScope函数,他是一个挂起函数,会继承外部的协程作用域并创建一个子作用域,于是我们可以给任意挂起函数提供协程作用域了。coroutineScope函数其实和runBlocking 函数类似,它也可以保证协程内的代码全部执行完,不过它阻塞的是当前协程,而runBlocking阻塞的是当前线程。fun main() { runBlocking { test1() } } suspend fun test1(){ coroutineScope { launch { println("hehehe") } } } -
创建挂起函数
fun main() { runBlocking { test() } } suspend fun test(){ println("xixixi") delay(1000) println("hahaha") }我们可以看到,在函数前面加上suspend关键字,就能将一个函数变成挂起函数
2、作用域构造器
前面已经学习了GlobalScope.launch、runBlocking、launch、coroutineScope四种作用域构造器,但是他们都有一定的局限性:GlobalScope.launch作为顶层协程,不太好控制它生命周期,runBlocking会阻塞线程、launch必须在协程作用域下才能执行、coroutineScope必须在协程作用域或者挂起函数中才能执行。
我们再来认识一种作用域构造器
fun main() {
val job = Job()
val scope = CoroutineScope(job)
scope.launch {
for (num in 1..100){
println("thread.name1 = "+Thread.currentThread().name+" $num")
}
}
job.cancel()
println("thread.name2 = "+Thread.currentThread().name)
}
实际上,GlobalScope.launch、launch函数都会返回job对象,通过job对象,我们就可以掌控协程作用域的生命周期,但前面也提到GlobalScope.launch的一个劣势就是不好控制协程作用域的生命周期,因为他作为顶层协程,每次调用都要记录它的job对象,但是如果我们用CoroutineScope函数,就可以统一成一个job对象,达到统一管理,这也是项目中常用的方法。
仔细观察,上述提到的所有协程作用域,都是在作用域内执行我们的逻辑代码,但是好像都不能返回这些代码的执行结果。async函数就可以获取协程作用域内的执行结果,它必须在协程作用域内调用,会创建一个新的子协程并返回一个Deferred对象,我们调用Deferred对像的await方法就能获取async创建的子协程的执行结果,执行结果是这个子协程内的最后一句
fun main() {
runBlocking {
val result = async {
println("thread.name1 = "+Thread.currentThread().name)
3+3
}.await()
println("thread.name2 = "+Thread.currentThread().name + " "+ result)
}
}
实际上在调用async函数之后,会立即执行它内部的代码。但是如果调用了await方法还没有执行完(没获取到子协程的执行结果),就会阻塞当前协程。
最后我们再来学习一下另一种创建协程作用域的方法withContext,他其实是async、await函数合并的写法,只是它必须指定子协程运行的线程
fun main() {
runBlocking {
val result = withContext(Dispatchers.Default) {
println("thread.name1 = "+Thread.currentThread().name)
3+3
}
println("thread.name2 = "+Thread.currentThread().name + " "+ result)
}
}
上面的代码和async、await一起调用的写法是一样的,唯一的区别是必须指定子协程所在线程:Dispatchers.Default用于运算密集场景,Dispatchers.Main表示不会开启子线程,Dispatchers.IO用于高并发场景
3、使用协程简化回调
在kotlin中,我们可以使用suspendCoroutine函数来简化回调,suspendCoroutine必须在协程作用域或者挂起函数中才能调用,调用此函数会将当前协程挂起,然后在一个普通线程中执行带Continuation参数的lambda表达式,通过lambda表达式的Continuation参数,我们可以让协程恢复执行。
接下来我们分别看下普通的回调代码和用suspendCoroutine函数精简的回调代码
HttpUtil.sendOkHttpRequest("https://www.baidu.com",object : Callback{
override fun onFailure(call: Call, e: IOException) {
TODO("Not yet implemented")
}
override fun onResponse(call: Call, response: Response) {
TODO("Not yet implemented")
}
})
suspend fun request(address: String):Response{
return suspendCoroutine { continuation ->
HttpUtil.sendOkHttpRequest("https://www.baidu.com",object : Callback{
override fun onFailure(call: Call, e: IOException) {
continuation.resumeWithException(e)
}
override fun onResponse(call: Call, response: Response) {
continuation.resume(response)
}
})
}
}
这样精简的好处就是,以后不管再发起多少次网络请求,都可以直接调用方法了,避免了重复写回调。
THE END...