好久没有更新点东西了,就把工作中灵感突发得到得小模块分享给大家吧。
需求分析
首先,气象观测数据因为有很多很多所以时不时的会有缺省值,就是说通常的数据非常的不干净,几乎每个时次同一区域不同站点总有几个或一堆缺测值,简单的求平均或者NAN=0,会破坏观测数据的分布结构,这样代表性就变小了,但是直接扔掉又会造成数据量骤减。
所以,资料的预处理很重要,这里分享一个实际使用中的简单小模块。
方法简述
核心思路是将不同的站点按照“粗一些”的网格区域分类,每类分别求取自己的平均值,然后替代掉自己类里面含有的缺省值,达到data clean的功能。
然后重复迭代更粗一丢丢的网格直到消灭所有缺省值。
代码
def lon_lat_web_cleanup(df,rect=1):
"""
按照经纬度以及给定的网格分配距离分组求平均值,以求填补缺省值
#design by wenqiushi 2018/5/21
"""
lonW = df['longitude'].min() - rect
lonE = df['longitude'].max() + rect
latS = df['latitude'].min() - rect
latN = df['latitude'].max() + rect
lon_web = np.arange(lonW,lonE,rect)
lat_web = np.arange(latS,latN,rect)
lon_grib,lat_grib=np.meshgrid(lon_web,lat_web)
kind_dict = {}
kind_num = 0
for key in list(zip(lon_grib.reshape(-1),lat_grib.reshape(-1))):
kind_dict[key] = kind_num
kind_num+=1
kind_list = []
for idx in list(df.index):
idx_lon = df.loc[idx,'longitude']
idx_lat = df.loc[idx,'latitude']
lon_flag = lon_web[np.where(np.abs(lon_web - idx_lon)==np.abs(lon_web - idx_lon).min())][0]
lat_flag = lat_web[np.where(np.abs(lat_web - idx_lat)==np.abs(lat_web - idx_lat).min())][0]
kind_list.append(kind_dict[(lon_flag,lat_flag)])
res = df.copy()
var_df=df.iloc[:,3:]
res.insert(0,'kind',kind_list)
res_mean=res.groupby('kind').mean()
rc_num=np.where(var_df.isna())
for row,col in list(zip(var_df.index[rc_num[0]],var_df.columns[rc_num[1]])):
df.loc[row,col] = res_mean.loc[res.loc[row,'kind'],col]
主要实现过程
这个小模块很简单,只有两个输入:
一个是dataframe 可以是各种观测资料的时间,站点序列,以风速为例可以长成这样:
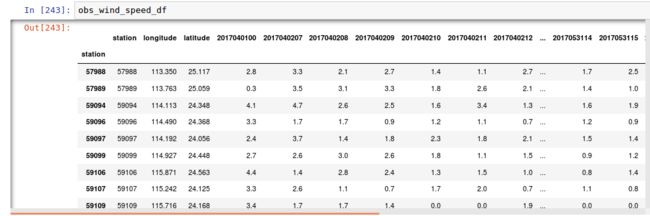
image.png
这个数据帧里面(行:966*列:1105)缺省值总共有:

image.png
8624个!基本随机的分布于整个数据帧,那么枪打出头鸟,我们提取单列缺省最多的一列来看看分布情况吧

image.png

image.png
这一列是缺值最多的一列,一共只有828个有效的数据点!
下面简单介绍模块的执行:
先从数据帧里获取经纬度的最大最小值,根据设定的网格分辨率(度)建立网格,然后建立一个以经纬度元组位key的字典kind_dict,存放分类ID,大概长这样,这里需要注意python的字典是没有顺序可言的。

image.png
然后根据kind_dict使用groupby方法对数据帧进行分类,之后就能求取各个分类的平均值了。之后的工作就是获取数据帧缺省值对应的站号(行)及其时间(列)标记,进而得到分类号,然后索引出对应的平均值赋值给对应的缺省值。

image.png
进过一次处理后得到的结果数据帧内缺省值减少近9成!

image.png
再回头对比以下缺省值最多了那个时次处理以后的分布情况:

image.png
两者几乎没有变化说明我们的数据清理工作还是比较成功的。
之后的事情就只需要迭代用更粗一点点的分辨率去填补仍然缺省的1217个点了,针对这次的数据迭代到第五步,5度格距的时候缺省值就全部处理完毕了。